Beyond Next-Observation Prediction: Agent-Authored World Modeling for Sequential Decision Making
Pith reviewed 2026-06-25 21:09 UTC · model grok-4.3
The pith
World models for agents learn more effectively when supervision targets are built from the policy's own decision needs rather than next observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
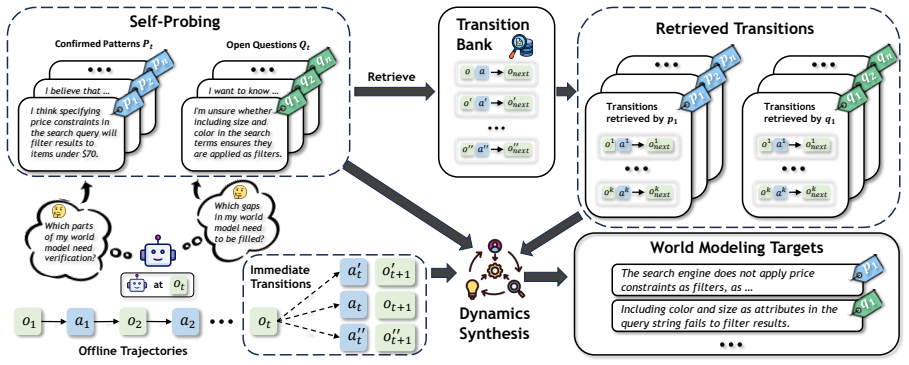
At each state the agent identifies its information needs, retrieves relevant transition evidence across trajectories, and synthesizes that evidence into training targets that capture decision-oriented dynamics; these targets supply a more effective learning signal for the world model than next-observation prediction.
What carries the argument
Agent-Authored World Modeling (AAWM), the procedure that derives supervision from the policy's self-identified decision needs at each state and synthesizes retrieved transitions into decision-oriented targets.
If this is right
- Training objectives for world models can be decoupled from next-observation reconstruction and aligned with policy decision requirements.
- Retrieved transition evidence can be repurposed as decision-specific supervision rather than used only for observation prediction.
- The resulting world models support more effective sequential decision making across multiple environments and training settings.
- Supervision signals become independent of the incidental contents of the next observation.
Where Pith is reading between the lines
- The same need-identification step could be tested in non-language-based reinforcement-learning agents to see whether the benefit generalizes beyond LLMs.
- Focusing retrieval on decision needs might reduce the volume of trajectory data required to reach a given performance level.
- If agents reliably self-diagnose information gaps, the method points toward iterative, self-directed improvement of world models during deployment.
- The approach may be especially useful in partially observable settings where next observations contain substantial irrelevant information.
Load-bearing premise
The agent can correctly name its own decision needs and the synthesis step can combine retrieved transitions into targets that reflect the relevant dynamics without introducing bias.
What would settle it
A controlled comparison in which AAWM-trained world models produce equal or lower downstream policy performance than next-observation baselines on the same environments and evaluation metrics.
Figures

read the original abstract
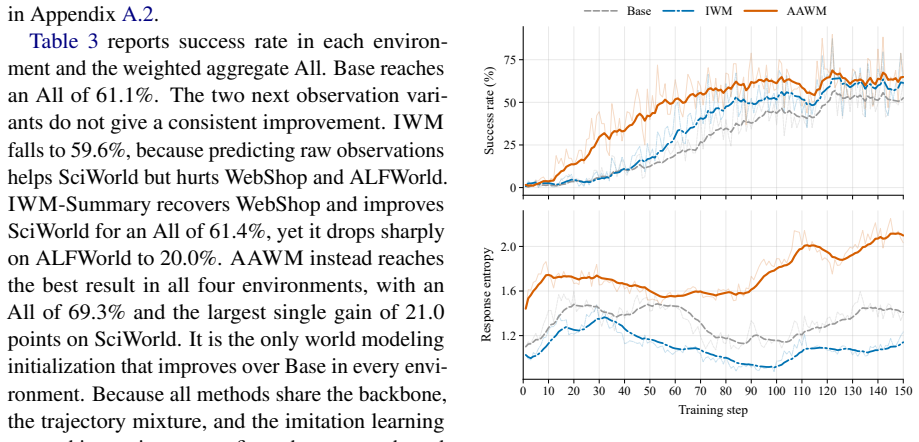
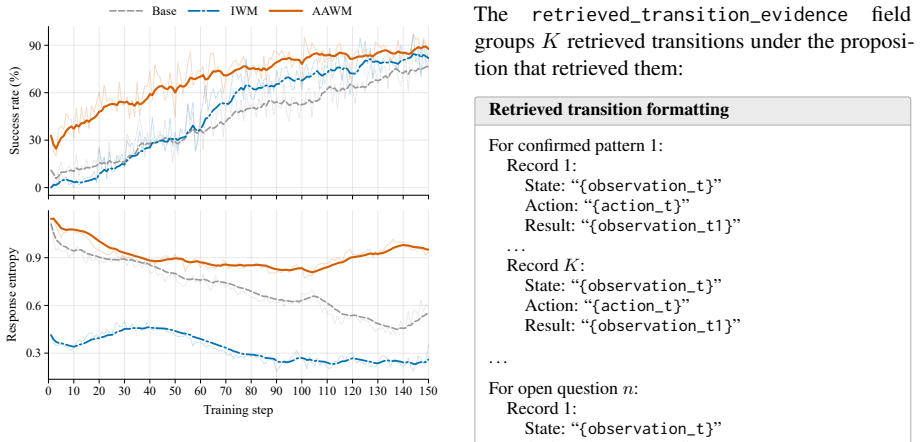
Recent studies on world modeling for Large Language Model (LLM) agents typically formulate the learning objective as next-observation prediction. However, this objective ties supervision to what a transition happens to reveal, which may omit the dynamics most relevant to the agent's current decision. To bridge this gap, we propose Agent-Authored World Modeling (AAWM), a training procedure that constructs supervision from the policy's own decision needs. Specifically, at each state, the agent identifies what it needs to understand about the environment before acting. These needs drive the retrieval of relevant transition evidence across trajectories, which is then synthesized into training targets that capture decision-oriented dynamics instead of reconstructing the next observation. This aligns the training objective with the dynamics the policy needs before acting, not with the contents of the next observation. Experimental results validate the effectiveness of AAWM across multiple environments and training settings. These results show that decision-aware world-model targets provide a more effective learning signal than next-observation prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that next-observation prediction for world modeling in LLM agents may omit dynamics most relevant to the agent's current decision. It proposes Agent-Authored World Modeling (AAWM), in which the policy identifies its decision needs at each state; these needs drive retrieval of relevant transitions across trajectories, which are then synthesized into training targets. The resulting objective is said to align supervision with decision-oriented dynamics rather than next-observation reconstruction, and the abstract states that experimental results across multiple environments and training settings validate that decision-aware targets provide a more effective learning signal.
Significance. If the method can be shown to avoid circular dependency between the identification step and the world model being learned, and if the (currently undescribed) experiments are sound, AAWM could offer a principled alternative to standard next-observation objectives for agent world modeling, potentially improving sample efficiency and decision quality in sequential settings.
major comments (2)
- [Abstract] Abstract: the claim that 'Experimental results validate the effectiveness of AAWM across multiple environments and training settings' is made without any description of environments, metrics, baselines, data, or quantitative outcomes, rendering it impossible to assess whether the evidence supports the central claim that decision-aware targets outperform next-observation prediction.
- [Abstract] Abstract: the method states that 'at each state, the agent identifies what it needs to understand about the environment before acting' and that 'these needs drive the retrieval of relevant transition evidence', yet supplies no mechanism, auxiliary model, or independence argument demonstrating that this identification step is independent of the current policy or the world model under training; this leaves the claimed advantage vulnerable to the circular-dependency risk highlighted in the stress-test note.
minor comments (1)
- [Abstract] Abstract: the single-paragraph format interleaves motivation, method description, and experimental claim without clear demarcation, reducing readability.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We respond to each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'Experimental results validate the effectiveness of AAWM across multiple environments and training settings' is made without any description of environments, metrics, baselines, data, or quantitative outcomes, rendering it impossible to assess whether the evidence supports the central claim that decision-aware targets outperform next-observation prediction.
Authors: We agree that the abstract summarizes the experimental validation at a high level without enumerating specific details. The full manuscript describes the environments, metrics, baselines, data sources, and quantitative outcomes in the Experiments section. To address the concern, we will revise the abstract to include a brief qualifier such as 'across grid-world navigation and text-based decision tasks' while preserving length constraints. revision: yes
-
Referee: [Abstract] Abstract: the method states that 'at each state, the agent identifies what it needs to understand about the environment before acting' and that 'these needs drive the retrieval of relevant transition evidence', yet supplies no mechanism, auxiliary model, or independence argument demonstrating that this identification step is independent of the current policy or the world model under training; this leaves the claimed advantage vulnerable to the circular-dependency risk highlighted in the stress-test note.
Authors: The identification of decision needs occurs via the policy's internal reasoning over its current state representation and action-selection logic; it does not invoke or depend on parameters of the world model under training. Retrieved transitions are drawn from a fixed corpus of prior trajectories. This separation ensures the identification step remains independent of the world-model parameters. We will expand the method section with an explicit independence argument and a short discussion of circularity risks. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract describes AAWM as constructing supervision targets from the policy's identified decision needs at each state, with retrieval and synthesis steps presented as procedural components of the new method. No equations, fitted parameters, or self-citations are quoted that reduce the targets or the claimed advantage over next-observation prediction to the inputs by construction. The central claim rests on experimental validation across environments rather than a self-referential derivation. The noted dependency concern pertains to implementation assumptions rather than a definitional or fitted-input reduction in the paper's stated chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The agent can accurately identify what it needs to understand about the environment before acting.
- domain assumption Retrieved transitions can be synthesized into training targets that capture decision-oriented dynamics.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.08558 , year=
Agent learning via early experience , author=. arXiv preprint arXiv:2510.08558 , year=
-
[2]
arXiv preprint arXiv:2512.18832 , year=
From word to world: Can large language models be implicit text-based world models? , author=. arXiv preprint arXiv:2512.18832 , year=
-
[3]
arXiv preprint arXiv:2506.02918 , year=
World modelling improves language model agents , author=. arXiv preprint arXiv:2506.02918 , year=
-
[4]
arXiv preprint arXiv:2510.19818 , year=
Semantic world models , author=. arXiv preprint arXiv:2510.19818 , year=
-
[5]
acting: A trade-off between world modeling & agent modeling , author=
Predicting vs. acting: A trade-off between world modeling & agent modeling , author=. arXiv preprint arXiv:2407.02446 , year=
-
[6]
Transactions on Machine Learning Research , year=
LLM-Based World Models Can Make Decisions Solely, But Rigorous Evaluations are Needed , author=. Transactions on Machine Learning Research , year=
-
[7]
arXiv preprint arXiv:2602.05842 , year=
Reinforcement World Model Learning for LLM-based Agents , author=. arXiv preprint arXiv:2602.05842 , year=
-
[8]
International Conference on Learning Representations , volume=
Web agents with world models: Learning and leveraging environment dynamics in web navigation , author=. International Conference on Learning Representations , volume=
-
[9]
arXiv preprint arXiv:2510.11892 , year=
R-wom: Retrieval-augmented world model for computer-use agents , author=. arXiv preprint arXiv:2510.11892 , year=
-
[10]
arXiv preprint arXiv:2506.00320 , year=
Dyna-Think: Synergizing Reasoning, Acting, and World Model Simulation in AI Agents , author=. arXiv preprint arXiv:2506.00320 , year=
-
[11]
arXiv preprint arXiv:2510.15047 , year=
Internalizing world models via self-play finetuning for agentic rl , author=. arXiv preprint arXiv:2510.15047 , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
Rlvr-world: Training world models with reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
arXiv preprint arXiv:2512.22336 , year=
Agent2World: Learning to Generate Symbolic World Models via Adaptive Multi-Agent Feedback , author=. arXiv preprint arXiv:2512.22336 , year=
-
[14]
arXiv preprint arXiv:2506.06725 , year=
WorldLLM: Improving LLMs' world modeling using curiosity-driven theory-making , author=. arXiv preprint arXiv:2506.06725 , year=
-
[15]
Advances in Neural Information Processing Systems , volume=
Agent planning with world knowledge model , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
arXiv preprint arXiv:2601.13247 , year=
Aligning Agentic World Models via Knowledgeable Experience Learning , author=. arXiv preprint arXiv:2601.13247 , year=
-
[17]
arXiv preprint arXiv:2601.03905 , year=
Current Agents Fail to Leverage World Model as Tool for Foresight , author=. arXiv preprint arXiv:2601.03905 , year=
-
[18]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Agent-flan: Designing data and methods of effective agent tuning for large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[19]
arXiv 2024 , author=
Agentgym: Evolving large language model-based agents across diverse environments. arXiv 2024 , author=
2024
-
[20]
Advances in Neural Information Processing Systems , volume=
Group-in-group policy optimization for llm agent training , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Artificial Intelligence and Statistics , pages=
Value-aware loss function for model-based reinforcement learning , author=. Artificial Intelligence and Statistics , pages=. 2017 , organization=
2017
-
[22]
Advances in neural information processing systems , volume=
The value equivalence principle for model-based reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[23]
Nature , volume=
Mastering atari, go, chess and shogi by planning with a learned model , author=. Nature , volume=. 2020 , publisher=
2020
-
[24]
arXiv preprint arXiv:2006.10742 , year=
Learning invariant representations for reinforcement learning without reconstruction , author=. arXiv preprint arXiv:2006.10742 , year=
arXiv 2006
-
[25]
International Conference on Machine Learning , pages=
Learning task informed abstractions , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[26]
International Conference on Machine Learning , pages=
Goal-aware prediction: Learning to model what matters , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[27]
arXiv preprint arXiv:2410.07484 , year=
Wall-e: World alignment by rule learning improves world model-based llm agents , author=. arXiv preprint arXiv:2410.07484 , year=
-
[28]
Advances in Neural Information Processing Systems , volume=
WALL-E: World Alignment by NeuroSymbolic Learning improves World Model-based LLM Agents , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval , pages=
The use of MMR, diversity-based reranking for reordering documents and producing summaries , author=. Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval , pages=
-
[30]
Advances in Neural Information Processing Systems , volume=
Vagen: Reinforcing world model reasoning for multi-turn vlm agents , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[32]
Claude-3 Model Card , volume=
The claude 3 model family: Opus, sonnet, haiku , author=. Claude-3 Model Card , volume=
-
[33]
arXiv preprint arXiv:2412.19437 , year=
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
-
[34]
arXiv preprint arXiv:2406.12793 , year=
Chatglm: A family of large language models from glm-130b to glm-4 all tools , author=. arXiv preprint arXiv:2406.12793 , year=
-
[35]
arXiv preprint arXiv:2507.20534 , year=
Kimi k2: Open agentic intelligence , author=. arXiv preprint arXiv:2507.20534 , year=
-
[36]
Advances in Neural Information Processing Systems , volume=
Swe-agent: Agent-computer interfaces enable automated software engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
You only look at screens: Multimodal chain-of-action agents , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[38]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Cogagent: A visual language model for gui agents , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[39]
International Conference on Learning Representations , volume=
A real-world webagent with planning, long context understanding, and program synthesis , author=. International Conference on Learning Representations , volume=
-
[40]
arXiv preprint arXiv:2210.03629 , year=
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
-
[41]
arXiv preprint arXiv:2305.16291 , year=
Voyager: An open-ended embodied agent with large language models , author=. arXiv preprint arXiv:2305.16291 , year=
-
[42]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[43]
International Conference on Learning Representations , volume=
Tora: A tool-integrated reasoning agent for mathematical problem solving , author=. International Conference on Learning Representations , volume=
-
[44]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[45]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[46]
arXiv preprint arXiv:2112.09332 , year=
Webgpt: Browser-assisted question-answering with human feedback , author=. arXiv preprint arXiv:2112.09332 , year=
-
[47]
arXiv preprint arXiv:2010.03768 , year=
Alfworld: Aligning text and embodied environments for interactive learning , author=. arXiv preprint arXiv:2010.03768 , year=
Pith/arXiv arXiv 2010
-
[48]
Advances in Neural Information Processing Systems , volume=
Webshop: Towards scalable real-world web interaction with grounded language agents , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[50]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[51]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[52]
arXiv preprint arXiv:2312.11805 , year=
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
-
[53]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Agentgym: Evaluating and training large language model-based agents across diverse environments , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.