DeMix: Debugging Training Data with Mixed Data Error Types by Investigating Influence Vectors
Pith reviewed 2026-06-27 10:20 UTC · model grok-4.3
The pith
DeMix identifies both erroneous training samples and their specific error types from influence vectors that track prediction effects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DeMix captures error-specific patterns by influence vectors that characterize how each training sample affects model predictions across all validation samples. We formulate training data debugging as a multi-label classification problem where a classifier is developed to predict error types directly from influence vectors. We further introduce an intervention-based learning strategy that guides the classifier to capture invariant rationales specific to each error type, ensuring the learned classifier generalizes effectively.
What carries the argument
Influence vectors that characterize how each training sample affects model predictions across all validation samples, used as input to a multi-label classifier trained with an intervention-based learning strategy.
If this is right
- Targeted repair of only the diagnosed error type becomes possible instead of blanket removal of flagged samples.
- The same influence-vector classifier can be applied to tabular prediction, recommendation systems, and LLM alignment without changing the core representation.
- Model performance after repair improves because repairs address the actual cause rather than treating all errors uniformly.
- Debugging shifts from binary detection to multi-label diagnosis, raising F1 scores on mixed-error data sets.
Where Pith is reading between the lines
- If influence vectors remain separable when the base model is swapped for a different architecture, DeMix could serve as a model-agnostic debugging layer.
- The approach might extend to streaming data settings where influence vectors are updated incrementally rather than recomputed from scratch.
- Neighboring problems such as detecting distribution shift could reuse the same vector representation if shifts also imprint distinct influence signatures.
Load-bearing premise
Different error types produce distinct patterns in influence vectors that stay invariant under the intervention strategy used to train the classifier.
What would settle it
Construct a synthetic data set with known label errors, feature errors, and spurious correlations, compute influence vectors for each training sample, and check whether a simple linear probe or the DeMix classifier can separate the three error classes above chance level.
Figures

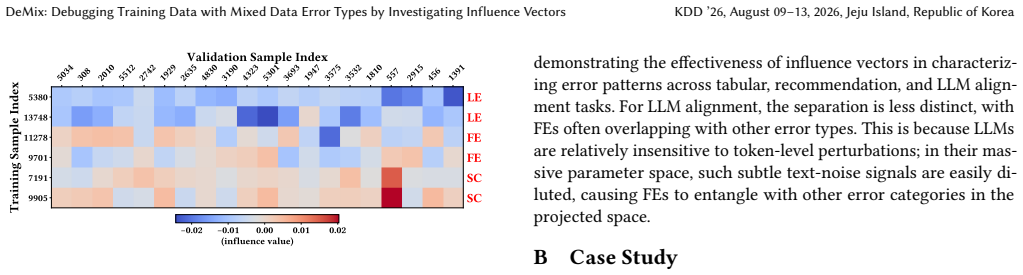
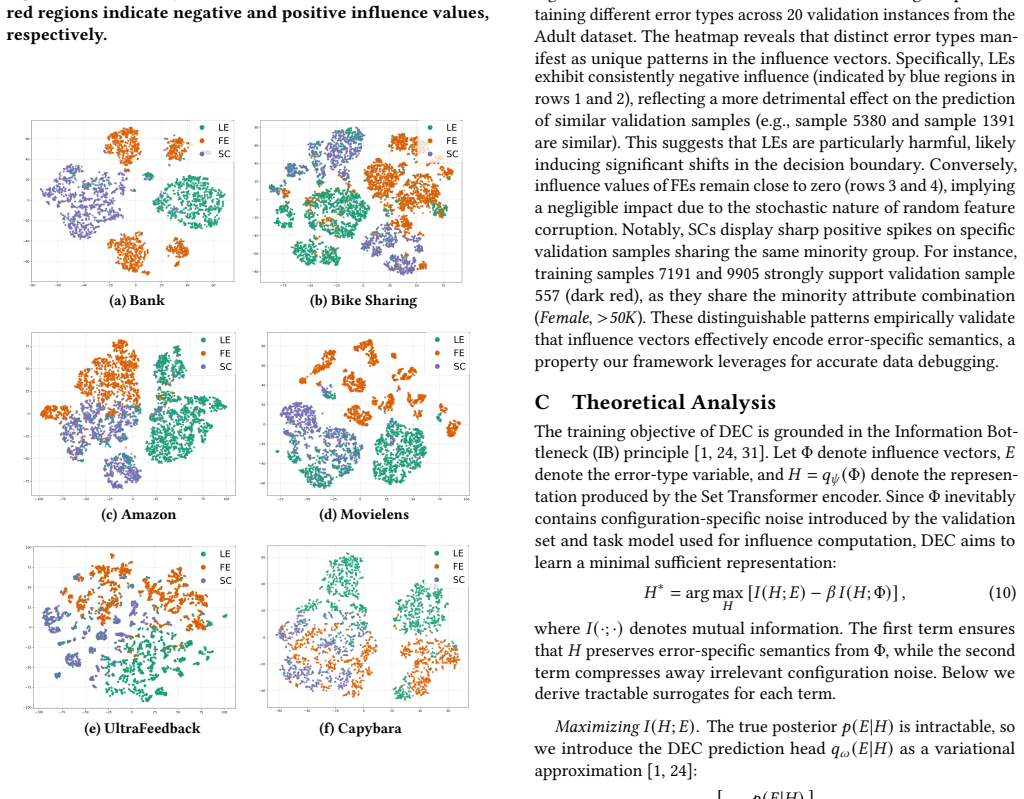
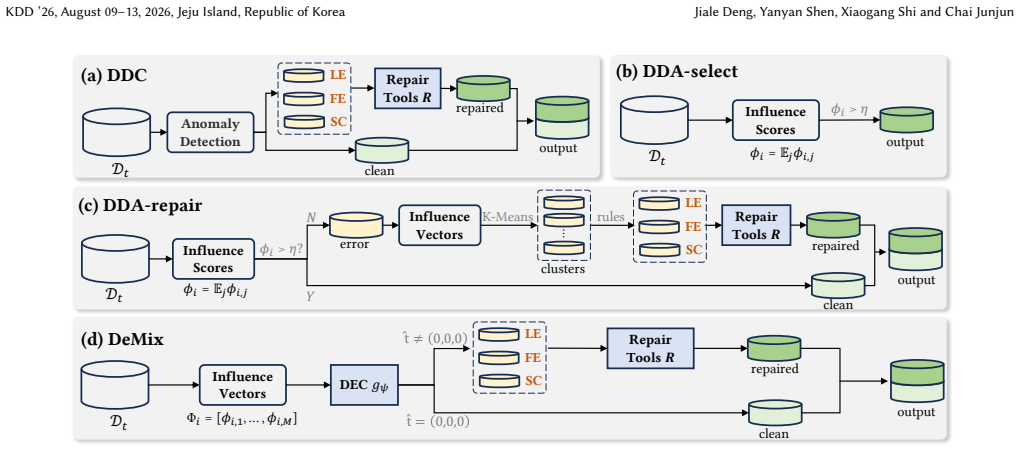
read the original abstract
High-quality training data is essential for the success of machine learning models. However, real-world datasets often contain mixed types of errors arising from systematic flaws in data preparation pipelines, including label errors, feature errors, and spurious correlations. Effective debugging of training data requires both detecting erroneous samples and identifying their specific error types to enable targeted repair, yet existing data cleaning and attribution methods fail to adequately address this dual requirement. In this paper, we propose DeMix, a novel framework that simultaneously diagnoses erroneous samples and their error types. Our key insight is that different error types produce distinct patterns on model behavior. DeMix captures such error-specific patterns by influence vectors that characterize how each training sample affects model predictions across all validation samples. We formulate training data debugging as a multi-label classification problem where a classifier is developed to predict error types directly from influence vectors. We further introduce an intervention-based learning strategy that guides the classifier to capture invariant rationales specific to each error type, ensuring the learned classifier generalizes effectively. Empirical evaluations on 11 tasks across tabular data prediction, recommendation systems, and LLM alignment demonstrate that DeMix significantly outperforms state-of-the-art approaches, achieving a 22.61% improvement in data debugging F1-score and a 9.32% gain in task model performance after data repair. Code is available at: https://github.com/SJTU-DMTai/DeMix.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DeMix, a framework for debugging training data containing mixed error types (label errors, feature errors, spurious correlations). It computes influence vectors from a trained model to characterize sample effects on validation predictions, then trains a multi-label classifier on these vectors with an intervention-based learning strategy to identify error types and enable targeted repair. Empirical results on 11 tasks across tabular prediction, recommendation systems, and LLM alignment report a 22.61% F1-score gain in data debugging and 9.32% improvement in downstream task performance, with code released.
Significance. If the empirical results hold under rigorous controls, the work addresses a practical gap in data cleaning by jointly detecting errors and classifying their types, which could improve repair efficiency and model robustness in real-world pipelines. The open-sourced code is a positive factor for reproducibility.
major comments (2)
- [§5 (Experiments)] §5 (Experiments): The reported numerical gains (22.61% F1, 9.32% task performance) are presented without details on experimental controls, baseline re-implementations, statistical significance testing, or the precise procedure for computing influence vectors, which are central to validating the outperformance claim.
- [§4 (Method)] §4 (Method): The intervention-based learning strategy is described only at a high level as guiding the classifier toward invariant rationales; a formal definition, loss function, or algorithmic pseudocode is needed to assess whether it actually enforces error-type-specific invariance rather than fitting to spurious patterns.
minor comments (1)
- Clarify notation for influence vectors (e.g., dimension, normalization) in the main text rather than deferring entirely to supplementary material.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and commit to revisions that strengthen the paper without altering its core claims.
read point-by-point responses
-
Referee: [§5 (Experiments)] The reported numerical gains (22.61% F1, 9.32% task performance) are presented without details on experimental controls, baseline re-implementations, statistical significance testing, or the precise procedure for computing influence vectors, which are central to validating the outperformance claim.
Authors: We agree that the current experimental section lacks sufficient detail to fully substantiate the reported gains. In the revised manuscript we will expand §5 to include: (i) explicit descriptions of all experimental controls and data splits, (ii) precise re-implementation steps and hyper-parameters for each baseline, (iii) results of statistical significance tests (e.g., paired t-tests or Wilcoxon tests with p-values across the 11 tasks), and (iv) the exact procedure, hyper-parameters, and implementation details used to compute influence vectors. These additions will be placed in both the main text and an expanded appendix. revision: yes
-
Referee: [§4 (Method)] The intervention-based learning strategy is described only at a high level as guiding the classifier toward invariant rationales; a formal definition, loss function, or algorithmic pseudocode is needed to assess whether it actually enforces error-type-specific invariance rather than fitting to spurious patterns.
Authors: We acknowledge that the intervention strategy is currently presented at a conceptual level. In the revision we will augment §4 with: (i) a formal mathematical definition of the intervention operator and the resulting invariance objective, (ii) the complete loss function (including the intervention term and any regularization), and (iii) pseudocode for the full training procedure of the multi-label classifier. This will allow readers to verify that the method targets error-type-specific invariant rationales. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical pipeline: train a model, compute influence vectors on validation samples, train a separate multi-label classifier on those vectors with an intervention-based strategy, then evaluate F1 and downstream performance on 11 tasks. No derivation chain, equation, or claim reduces a result to its inputs by construction. Influence vectors are computed from a trained model rather than defined in terms of the error-type labels they predict. The intervention strategy is a training technique, not a definitional equivalence. No self-citation is invoked as a uniqueness theorem or load-bearing premise. Claims rest on empirical gains, not on renaming or fitting that forces the outcome.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Different error types produce distinct patterns on model behavior.
Reference graph
Works this paper leans on
-
[1]
Alexander A Alemi, Ian Fischer, Joshua V Dillon, and Kevin Murphy. 2017. Deep Variational Information Bottleneck. InInternational Conference on Learning Rep- resentations
2017
-
[2]
Xianchun Bao, Zian Bao, Bie Binbin, QingSong Duan, Wenfei Fan, Hui Lei, Daji Li, Wei Lin, Peng Liu, Zhicong Lv, et al. 2024. Rock: Cleaning Data by Embedding ML in Logic Rules. InCompanion of the 2024 International Conference on Management of Data. 106–119
2024
-
[4]
Lichang Chen, Chen Zhu, Jiuhai Chen, Davit Soselia, Tianyi Zhou, Tom Gold- stein, Heng Huang, Mohammad Shoeybi, and Bryan Catanzaro. 2024. ODIN: Disentangled Reward Mitigates Hacking in RLHF. InInternational Conference on Machine Learning. PMLR, 7935–7952
2024
-
[5]
Sang Keun Choe, Hwijeen Ahn, Juhan Bae, Kewen Zhao, Minsoo Kang, Youngseog Chung, Adithya Pratapa, Willie Neiswanger, Emma Strubell, Teruko Mitamura, et al. 2024. What is your data worth to gpt? llm-scale data valuation with influence functions.arXiv preprint arXiv:2405.13954(2024)
-
[6]
Xu Chu, Ihab F Ilyas, Sanjay Krishnan, and Jiannan Wang. 2016. Data clean- ing: Overview and emerging challenges. InProceedings of the 2016 international conference on management of data. 2201–2206
2016
-
[7]
Junwei Deng, Yuzheng Hu, Pingbang Hu, Ting-Wei Li, Shixuan Liu, Jiachen T Wang, Dan Ley, Qirun Dai, Benhao Huang, Jin Huang, et al. 2025. A Survey of Data Attribution: Methods, Applications, and Evaluation in the Era of Generative AI. (2025)
2025
-
[8]
Jiale Deng, Yanyan Shen, Ziyuan Pei, Youmin Chen, and Linpeng Huang. [n. d.]. Influence Guided Context Selection for Effective Retrieval-Augmented Gener- ation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[9]
Yuhao Deng, Chengliang Chai, Lei Cao, Nan Tang, Jiayi Wang, Ju Fan, Ye Yuan, and Guoren Wang. 2024. MisDetect: Iterative Mislabel Detection using Early Loss.Proceedings of the VLDB Endowment17, 6 (2024), 1159–1172
2024
-
[10]
Xiaoou Ding, Zekai Qian, Hongzhi Wang, Siying Chen, Yafeng Tang, Hongbin Su, Huan Hu, and Chen Wang. 2025. UniClean: A Scalable Data Cleaning Solution for Mixed Errors based on Unified Cleaners and Optimized Cleaning Workflow. Proceedings of the VLDB Endowment18, 11 (2025), 4117–4130
2025
-
[11]
Xinyi Gao, Dongting Xie, Yihang Zhang, Zhengren Wang, Chong Chen, Con- ghui He, Hongzhi Yin, and Wentao Zhang. 2026. A comprehensive survey on imbalanced data learning.Frontiers of Computer Science20, 11 (2026), 2011622
2026
-
[12]
Zayd Hammoudeh and Daniel Lowd. 2024. Training data influence analysis and estimation: A survey.Machine Learning113, 5 (2024), 2351–2403
2024
-
[13]
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. [n. d.]. TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second. InThe Eleventh International Conference on Learning Representations
- [14]
-
[15]
Kevin Jiang, Weixin Liang, James Y Zou, and Yongchan Kwon. 2023. Opendataval: a unified benchmark for data valuation.Advances in Neural Information Processing Systems36 (2023), 28624–28647
2023
-
[16]
Barrie Kersbergen, Olivier Sprangers, Bojan Karlaš, Maarten de Rijke, and Se- bastian Schelter. 2025. Scalable Data Debugging for Neighborhood-based Rec- ommendation with Data Shapley Values. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 441–450
2025
-
[17]
Pang Wei Koh and Percy Liang. 2017. Understanding black-box predictions via influence functions. InInternational conference on machine learning. PMLR, 1885–1894
2017
-
[18]
Shuming Kong, Yanyan Shen, and Linpeng Huang. 2021. Resolving training biases via influence-based data relabeling. InInternational Conference on Learning Representations
2021
-
[19]
Johnson Kuan and Jonas Mueller. 2022. Back to the Basics: Revisiting Out-of- Distribution Detection Baselines. InICML Workshop on Principles of Distribution Shift
2022
-
[20]
Johnson Kuan and Jonas Mueller. 2022. Model-agnostic label quality scoring to detect real-world label errors. InICML DataPerf Workshop
2022
-
[21]
Juho Lee, Yoonho Lee, Jungtaek Kim, Adam Kosiorek, Seungjin Choi, and Yee Whye Teh. 2019. Set transformer: A framework for attention-based permutation-invariant neural networks. InInternational conference on machine learning. PMLR, 3744–3753
2019
-
[22]
Weixin Liang, Girmaw Abebe Tadesse, Daniel Ho, Li Fei-Fei, Matei Zaharia, Ce Zhang, and James Zou. 2022. Advances, challenges and opportunities in creating data for trustworthy AI.Nature Machine Intelligence4, 8 (2022), 669–677
2022
-
[23]
Evan Z Liu, Behzad Haghgoo, Annie S Chen, Aditi Raghunathan, Pang Wei Koh, Shiori Sagawa, Percy Liang, and Chelsea Finn. 2021. Just train twice: Improving group robustness without training group information. InInternational Conference on Machine Learning. PMLR, 6781–6792
2021
-
[24]
Siqi Miao, Mia Liu, and Pan Li. 2022. Interpretable and generalizable graph learn- ing via stochastic attention mechanism. InInternational conference on machine learning. PMLR, 15524–15543
2022
-
[25]
Nikolaos Myrtakis, Ioannis Tsamardinos, and Vassilis Christophides. 2025. Data Glitches Discovery using Influence-based Model Explanations. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1. 1068–1079
2025
-
[26]
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Ru Peng, Kexin Yang, Yawen Zeng, Junyang Lin, Dayiheng Liu, and Junbo Zhao. [n. d.]. DataMan: Data Manager for Pre-training Large Language Models. InThe Thirteenth International Conference on Learning Representations
-
[28]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
2023
-
[29]
Shafaq Siddiqi, Roman Kern, and Matthias Boehm. 2023. SAGA: A scalable frame- work for optimizing data cleaning pipelines for machine learning applications. Proceedings of the ACM on Management of Data1, 3 (2023), 1–26
2023
-
[30]
Qwen Team. 2024. Qwen2.5: A Party of Foundation Models. https://qwenlm. github.io/blog/qwen2.5/
2024
-
[31]
Naftali Tishby, Fernando C Pereira, and William Bialek. 2000. The information bottleneck method.arXiv preprint physics/0004057(2000)
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[32]
Yunze Tong, Fengda Zhang, Zihao Tang, Kaifeng Gao, Kai Huang, Pengfei Lyu, Jun Xiao, and Kun Kuang. [n. d.]. Latent Score-Based Reweighting for Robust Clas- sification on Imbalanced Tabular Data. InForty-second International Conference on Machine Learning
-
[33]
Fulton Wang, Julius Adebayo, Sarah Tan, Diego Garcia-Olano, and Narine Kokhlikyan. 2023. Error discovery by clustering influence embeddings.Ad- vances in Neural Information Processing Systems36 (2023), 41765–41777
2023
-
[34]
Shihao Weng, Yang Feng, Yining Yin, Zhenlun Zhang, and Baowen Xu. 2026. Data preparation and quality for code-centric generative software engineering tasks: a systematic literature review.Frontiers of Computer Science20, 9 (2026), 2009203
2026
-
[35]
Shirley Wu, Mert Yuksekgonul, Linjun Zhang, and James Zou. 2023. Discover and cure: Concept-aware mitigation of spurious correlation. InInternational Conference on Machine Learning. PMLR, 37765–37786
2023
-
[36]
Ying-Xin Wu, Xiang Wang, An Zhang, Xiangnan He, and Tat seng Chua. 2022. Discovering Invariant Rationales for Graph Neural Networks. InICLR
2022
-
[37]
Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen. 2024. LESS: Selecting Influential Data for Targeted Instruction Tuning. In International Conference on Machine Learning. PMLR, 54104–54132
2024
-
[38]
Wenqian Ye, Guangtao Zheng, and Aidong Zhang. 2025. Improving group ro- bustness on spurious correlation via evidential alignment. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 3610–3621
2025
-
[39]
Mingjia Yin, Hao Wang, Wei Guo, Yong Liu, Suojuan Zhang, Sirui Zhao, Defu Lian, and Enhong Chen. 2024. Dataset regeneration for sequential recommendation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3954–3965
2024
- [40]
-
[41]
Xuanchang Zhang, Wei Xiong, Lichang Chen, Tianyi Zhou, Heng Huang, and Tong Zhang. 2025. From lists to emojis: How format bias affects model alignment. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 26940–26961
2025
-
[42]
Yansen Zhang, Xiaokun Zhang, Ziqiang Cui, and Chen Ma. 2025. Shapley value- driven data pruning for recommender systems. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 3879–3888
2025
-
[43]
Weixiang Zhao, Yulin Hu, Xingyu Sui, Zhuojun Li, Yang Deng, Yanyan Zhao, Bing Qin, and Wanxiang Che. 2026. The gains do not make up for the losses: a comprehensive evaluation for safety alignment of large language models via machine unlearning.Frontiers of Computer Science20, 2 (2026), 2002319
2026
-
[44]
Kaiping Zheng, Horng-Ruey Chua, Melanie Herschel, HV Jagadish, Beng Chin Ooi, and James Wei Luen Yip. 2024. Exploiting negative samples: a catalyst for cohort discovery in healthcare analytics. InForty-first International Conference on Machine Learning
2024
-
[45]
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep interest evolution network for click-through rate prediction. InProceedings of the AAAI conference on artificial intelligence, Vol. 33. 5941–5948
2019
-
[46]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068. DeMix: Debugging Training Data with Mixed Data Error Types by Investi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.