iTryOn: Mastering Interactive Video Virtual Try-On with Spatial-Semantic Guidance
Pith reviewed 2026-05-21 05:08 UTC · model grok-4.3
The pith
A framework called iTryOn uses 3D hand guidance and timed action descriptions to enable realistic virtual garment changes in videos where people interact with their clothes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
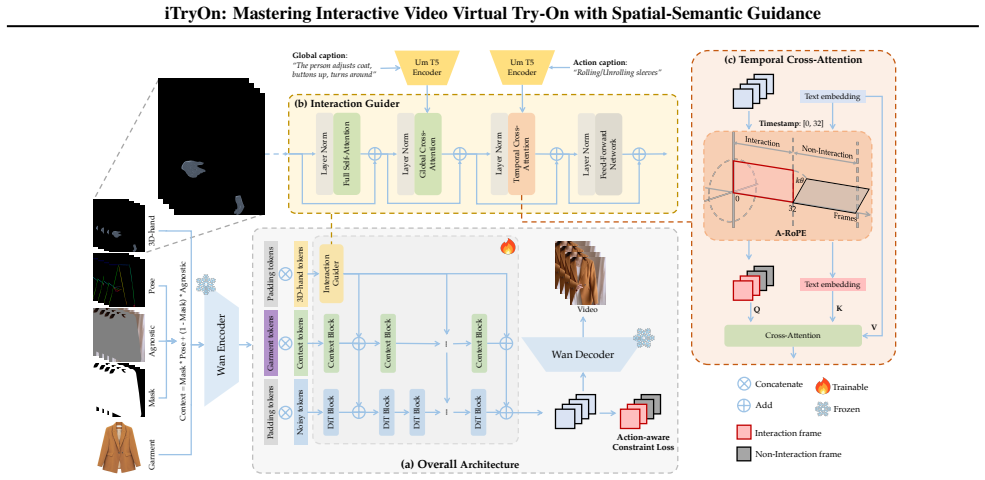
iTryOn pioneers a multi-level interaction injection mechanism within a large-scale video diffusion Transformer to guide the generation of complex garment dynamics in interactive scenarios. At the spatial level, a garment-agnostic 3D hand prior provides fine-grained guidance for precise hand-garment contact. At the semantic level, global captions and time-stamped action captions are synchronized via Action-aware Rotational Position Embedding (A-RoPE) to resolve ambiguities and learn deformations from brief interactive moments.
What carries the argument
The multi-level interaction injection mechanism, which combines a garment-agnostic 3D hand prior for spatial guidance and Action-aware Rotational Position Embedding (A-RoPE) for synchronizing time-stamped action captions.
If this is right
- iTryOn achieves state-of-the-art performance on traditional non-interactive VVT benchmarks.
- iTryOn establishes a commanding lead in the new interactive VVT setting.
- The framework enables more dynamic and controllable virtual try-on experiences.
- Resolves semantic ambiguity of interactions and complex garment deformations in videos with sparse interactive moments.
Where Pith is reading between the lines
- Extending this to real-time applications could allow live virtual try-on during video calls or social media.
- Similar spatial-semantic guidance might apply to other video editing tasks involving human-object interactions, such as object manipulation in augmented reality.
- Future work could test if the hand prior generalizes to different garment types without additional training.
- Integration with user-controlled inputs might enable personalized interaction styles in try-on videos.
Load-bearing premise
That combining a garment-agnostic 3D hand prior with time-stamped action captions can sufficiently resolve semantic ambiguity and complex deformations even when interactive moments are sparse and brief in training videos.
What would settle it
A test video sequence with complex hand-garment interactions that are not captured well by 3D hand priors or action captions, where the generated output shows incorrect deformations or misplaced contacts compared to ground truth.
Figures






read the original abstract
Video Virtual Try-On (VVT) aims to seamlessly replace a garment on a person in a video with a new one. While existing methods have made significant strides in maintaining temporal consistency, they are predominantly confined to non-interactive scenarios where models merely showcase garments. This limitation overlooks a crucial aspect of real-world apparel presentation: active human-garment interaction. To bridge this gap, we introduce and formalize a new challenging task: Interactive Video Virtual Try-On (Interactive VVT), where subjects in the video actively engage with their clothing. This task introduces unique challenges beyond simple texture preservation, including: (1) resolving the semantic ambiguity of interactions from standard pose information, and (2) learning complex garment deformations from video where interactive moments are sparse and brief. To address these challenges, we propose iTryOn, a novel framework built upon a large-scale video diffusion Transformer. iTryOn pioneers a multi-level interaction injection mechanism to guide the generation of complex dynamics. At the spatial level, we introduce a garment-agnostic 3D hand prior to provide fine-grained guidance for precise hand-garment contact, effectively resolving spatial ambiguity. At the semantic level, iTryOn leverages global captions for overall context and time-stamped action captions for localized interactions, synchronized via our novel Action-aware Rotational Position Embedding (A-RoPE). Extensive experiments demonstrate that iTryOn not only achieves state-of-the-art performance on traditional VVT benchmarks but also establishes a commanding lead in the new interactive setting, marking a significant step towards more dynamic and controllable virtual try-on experiences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formalizes the new task of Interactive Video Virtual Try-On (Interactive VVT), where subjects actively interact with garments in video, and proposes iTryOn, a video diffusion Transformer framework. It introduces multi-level interaction injection: a garment-agnostic 3D hand prior at the spatial level for hand-garment contact and time-stamped action captions synchronized via Action-aware Rotational Position Embedding (A-RoPE) at the semantic level. The work claims SOTA performance on standard VVT benchmarks and a commanding lead on the interactive setting.
Significance. If the results hold, the formalization of Interactive VVT and the spatial-semantic guidance mechanism represent a meaningful advance toward controllable, dynamic virtual try-on for real-world apparel scenarios. The integration of 3D hand priors with action-aware embeddings in a diffusion Transformer is a targeted contribution to handling sparse interactions and deformations in video generation.
major comments (1)
- [Method description and abstract] The central claim of a commanding lead on Interactive VVT (abstract) rests on the multi-level injection resolving semantic ambiguity and complex deformations. The garment-agnostic 3D hand prior supplies pose/contact geometry independent of garment material or topology, yet the manuscript provides no explicit mechanism (e.g., garment-conditioned deformation field or per-frame contact loss) to enable learning of garment-specific folding/stretching at contact points during sparse, brief interactions. This leaves open whether reported gains derive from the base diffusion Transformer rather than the proposed guidance.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from explicit dataset names, evaluation metrics, and a brief summary of ablation studies to support the SOTA and commanding-lead claims.
- [Method] Notation for A-RoPE and the precise injection points into the diffusion Transformer could be clarified with a diagram or pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comment raises an important point about the mechanisms underlying garment-specific deformations, which we address below with clarifications from our experiments and revisions to the text.
read point-by-point responses
-
Referee: The central claim of a commanding lead on Interactive VVT (abstract) rests on the multi-level injection resolving semantic ambiguity and complex deformations. The garment-agnostic 3D hand prior supplies pose/contact geometry independent of garment material or topology, yet the manuscript provides no explicit mechanism (e.g., garment-conditioned deformation field or per-frame contact loss) to enable learning of garment-specific folding/stretching at contact points during sparse, brief interactions. This leaves open whether reported gains derive from the base diffusion Transformer rather than the proposed guidance.
Authors: We thank the referee for this observation. The 3D hand prior is deliberately garment-agnostic to supply robust, topology-independent contact geometry that generalizes across clothing types. Garment-specific folding and stretching are learned implicitly because the diffusion Transformer is conditioned on the target garment image at every step; the spatial hand guidance localizes where deformations must occur, while the time-stamped action captions (via A-RoPE) disambiguate the interaction semantics that dictate deformation style. Ablation experiments (Section 4.3 and supplementary material) show that removing the hand prior or A-RoPE produces statistically significant drops in contact accuracy and perceptual deformation quality on interactive sequences, indicating that the reported gains are not attributable to the base model alone. We have revised the method section to explicitly describe this conditioning pathway and added a paragraph clarifying the role of the diffusion process in learning deformations from the provided guidance. We agree that an explicit garment-conditioned deformation field or auxiliary contact loss would constitute a valuable extension and note this as future work. revision: partial
Circularity Check
No circularity in iTryOn derivation chain
full rationale
The paper formalizes a new Interactive VVT task and presents iTryOn as an independent framework built on a video diffusion Transformer, injecting a garment-agnostic 3D hand prior at the spatial level and time-stamped action captions via A-RoPE at the semantic level. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or description; the multi-level guidance is introduced as a novel mechanism rather than derived from or reducing to prior results by construction. Empirical SOTA claims rest on experiments, not tautological re-derivation of inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost.leanJcost_pos_of_ne_one unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-level interaction injection mechanism... garment-agnostic 3D hand prior... Action-aware Rotational Position Embedding (A-RoPE)... action-aware constraint loss
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A-RoPE... scaled 1D-RoPE... k=4 separation scale
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Patricia S. Abril and Robert Plant. The patent holder's dilemma: Buy, sell, or troll?. Communications of the ACM. 2007. doi:10.1145/1188913.1188915
-
[2]
Digital Image Processing, 4th Edition , author=
-
[3]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
VITON: An Image-Based Virtual Try-on Network , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[4]
Proceedings of the European Conference on Computer Vision , pages=
Toward Characteristic-Preserving Image-Based Virtual Try-On Network , author=. Proceedings of the European Conference on Computer Vision , pages=
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Towards Photo-Realistic Virtual Try-On by Adaptively Generating-Preserving Image Content , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[6]
VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization , year=
Choi, Seunghwan and Park, Sunghyun and Lee, Minsoo and Choo, Jaegul , booktitle=. VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization , year=
-
[7]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
VTNFP: An Image-Based Virtual Try-On Network With Body and Clothing Feature Preservation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[8]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Parser-Free Virtual Try-on via Distilling Appearance Flows , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[9]
Proceedings of the European Conference on Computer Vision , year=
View Synthesis by Appearance Flow , author=. Proceedings of the European Conference on Computer Vision , year=
-
[10]
IEEE Transactions on pattern analysis and machine intelligence , volume=
Principal warps: Thin-plate splines and the decomposition of deformations , author=. IEEE Transactions on pattern analysis and machine intelligence , volume=. 1989 , publisher=
work page 1989
-
[11]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Deep Image Spatial Transformation for Person Image Generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[12]
ACM transactions on graphics (TOG) , volume=
SMPL: A skinned multi-person linear model , author=. ACM transactions on graphics (TOG) , volume=. 2015 , publisher=
work page 2015
-
[13]
DensePose: Dense Human Pose Estimation in the Wild , year=
Güler, Riza Alp and Neverova, Natalia and Kokkinos, Iasonas , booktitle=. DensePose: Dense Human Pose Estimation in the Wild , year=
-
[14]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Cross-Domain Correspondence Learning for Exemplar-Based Image Translation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[16]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Effective whole-body pose estimation with two-stages distillation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Dense Intrinsic Appearance Flow for Human Pose Transfer , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[18]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer and Novel View Synthesis , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[19]
ACM Transactions on Graphics , volume=
Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN , author=. ACM Transactions on Graphics , volume=
-
[20]
Dressing in the Wild by Watching Dance Videos , author=. 2022 , booktitle=
work page 2022
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Ke Gong and Yiming Gao and Xiaodan Liang and Xiaohui Shen and Meng Wang and Liang Lin , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[22]
Zhou Wang and Bovik, A.C. and Sheikh, H.R. and Simoncelli, E.P. , journal=. Image quality assessment: from error visibility to structural similarity , year=
-
[23]
arXiv preprint arXiv:2104.11222 , year=
On Buggy Resizing Libraries and Surprising Subtleties in FID Calculation , author=. arXiv preprint arXiv:2104.11222 , year=
-
[24]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Liu, Ziwei and Luo, Ping and Qiu, Shi and Wang, Xiaogang and Tang, Xiaoou , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[25]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year =
Rıza Alp Güler and Natalia Neverova and Iasonas Kokkinos , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year =
-
[26]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Semantic Image Synthesis With Spatially-Adaptive Normalization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Analyzing and Improving the Image Quality of StyleGAN , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[29]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Towards Multi-pose Guided Virtual Try-on Network , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[30]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
FrankMocap: A Monocular 3D Whole-Body Pose Estimation System via Regression and Integration , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Controllable Person Image Synthesis With Attribute-Decomposed GAN , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
Dressing in Order: Recurrent Person Image Generation for Pose Transfer, Virtual Try-on and Outfit Editing , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
- [33]
-
[34]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
ZFlow: Gated Appearance Flow-based Virtual Try-on with 3D Priors , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[35]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Clothflow: A flow-based model for clothed person generation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[36]
Advances in neural information processing systems , volume=
Understanding the effective receptive field in deep convolutional neural networks , author=. Advances in neural information processing systems , volume=
-
[37]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Learning dense correspondence via 3d-guided cycle consistency , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[38]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Flownet: Learning optical flow with convolutional networks , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[39]
and Shechtman, Eli and Wang, Oliver , booktitle=
Zhang, Richard and Isola, Phillip and Efros, Alexei A. and Shechtman, Eli and Wang, Oliver , booktitle=. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric , year=
-
[40]
Xie, Zhenyu and Huang, Zaiyu and Zhao, Fuwei and Dong, Haoye and Kampffmeyer, Michael and Liang, Xiaodan , title =. Proceedings of the 35th International Conference on Neural Information Processing Systems , articleno =. 2021 , isbn =
work page 2021
-
[41]
Advances in Neural Information Processing Systems , volume=
3d multi-bodies: Fitting sets of plausible 3d human models to ambiguous image data , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Advances in Neural Information Processing Systems , volume=
3D Pose Transfer with Correspondence Learning and Mesh Refinement , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Per-Pixel Classification is Not All You Need for Semantic Segmentation , author=. NeurIPS , year=
-
[44]
HunyuanVideo: A Systematic Framework For Large Video Generative Models , author=. 2025 , eprint=
work page 2025
-
[45]
Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model , author=. 2025 , eprint=
work page 2025
-
[46]
Do not mask what you do not need to mask: a parser-free virtual try-on , author=. Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part XX 16 , pages=. 2020 , organization=
work page 2020
-
[47]
Style-Based Global Appearance Flow for Virtual Try-On , year=
He, Sen and Song, Yi-Zhe and Xiang, Tao , booktitle=. Style-Based Global Appearance Flow for Virtual Try-On , year=
-
[48]
arXiv: Computer Vision and Pattern Recognition , year=
ZFlow: Gated Appearance Flow-based Virtual Try-on with 3D Priors , author=. arXiv: Computer Vision and Pattern Recognition , year=
-
[49]
ACM Transactions on Graphics (TOG) , volume=
Low-light image enhancement with wavelet-based diffusion models , author=. ACM Transactions on Graphics (TOG) , volume=
-
[50]
NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation , author=. 2023 , eprint=
work page 2023
-
[51]
PixArt- : Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis , author=. ArXiv , year=
-
[52]
FW-GAN: Flow-Navigated Warping GAN for Video Virtual Try-On , year=
Dong, Haoye and Liang, Xiaodan and Shen, Xiaohui and Wu, Bowen and Chen, Bing-Cheng and Yin, Jian , booktitle=. FW-GAN: Flow-Navigated Warping GAN for Video Virtual Try-On , year=
-
[53]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
ClothFormer: Taming Video Virtual Try-on in All Module , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[54]
Xu, Zhengze and Chen, Mengting and Wang, Zhao and Xing, Linyu and Zhai, Zhonghua and Sang, Nong and Lan, Jinsong and Xiao, Shuai and Gao, Changxin , title =. 2024 , isbn =. doi:10.1145/3664647.3680836 , booktitle =
-
[55]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Align Your Latents: High-Resolution Video Synthesis with Latent Diffusion Models , author=. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
work page 2023
-
[56]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C
Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bjorn , year=. High-Resolution Image Synthesis with Latent Diffusion Models , url=. doi:10.1109/cvpr52688.2022.01042 , booktitle=
-
[57]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Adding conditional control to text-to-image diffusion models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[58]
T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models , author=. arXiv preprint arXiv:2302.08453 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
arXiv preprint arXiv:2211.13227 , year=
Paint by Example: Exemplar-based Image Editing with Diffusion Models , author=. arXiv preprint arXiv:2211.13227 , year=
-
[60]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis , author=. 2024 , eprint=
work page 2024
-
[61]
MV-TON: Memory-based Video Virtual Try-on network , url=
Zhong, Xiaojing and Wu, Zhonghua and Tan, Taizhe and Lin, Guosheng and Wu, Qingyao , year=. MV-TON: Memory-based Video Virtual Try-on network , url=. doi:10.1145/3474085.3475269 , booktitle=
-
[62]
ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on , url=
Kuppa, Gaurav and Jong, Andrew and Liu, Xin and Liu, Ziwei and Moh, Teng-Sheng , year=. ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on , url=. doi:10.1109/wacvw52041.2021.00025 , booktitle=
-
[63]
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models , author=. arXiv preprint arXiv:2311.04145 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
arXiv preprint arXiv:2306.02018 , year=
VideoComposer: Compositional Video Synthesis with Motion Controllability , author=. arXiv preprint arXiv:2306.02018 , year=
-
[65]
International Conference on Learning Representations , year=
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning , author=. International Conference on Learning Representations , year=
-
[66]
arXiv preprint arXiv:2311.16933 , year=
SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models , author=. arXiv preprint arXiv:2311.16933 , year=
-
[67]
Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers , author=. arXiv preprint arXiv:2405.05945 , year=
-
[68]
Latte: Latent Diffusion Transformer for Video Generation
Latte: Latent Diffusion Transformer for Video Generation , author=. arXiv preprint arXiv:2401.03048 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
PKU-Yuan Lab and Tuzhan AI etc. , title =. doi:10.5281/zenodo.10948109 , url =
-
[70]
Proceedings of the European Conference on Computer Vision (ECCV) , pages=
Toward Characteristic-Preserving Image-based Virtual Try-On Network , author=. Proceedings of the European Conference on Computer Vision (ECCV) , pages=
-
[71]
Scalable Diffusion Models with Transformers , author=. 2022 , journal=
work page 2022
- [72]
-
[73]
U-Net: Convolutional Networks for Biomedical Image Segmentation
Ronneberger, Olaf and Fischer, Philipp and Brox, Thomas. U-Net: Convolutional Networks for Biomedical Image Segmentation. Medical Image Computing and Computer-Assisted Intervention -- MICCAI 2015. 2015
work page 2015
-
[74]
Neural Information Processing Systems , year=
Attention is All you Need , author=. Neural Information Processing Systems , year=
-
[75]
In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Esser, Patrick and Rombach, Robin and Ommer, Bjorn , year=. Taming Transformers for High-Resolution Image Synthesis , url=. doi:10.1109/cvpr46437.2021.01268 , booktitle=
-
[76]
International conference on machine learning , pages=
Perceiver: General perception with iterative attention , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[77]
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author=. J. Mach. Learn. Res. , year=
-
[78]
arXiv preprint arXiv:2311.17117 , website=
Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation , author=. arXiv preprint arXiv:2311.17117 , website=
-
[79]
StableGarment: Garment-Centric Generation via Stable Diffusion , author=. 2024 , eprint=
work page 2024
-
[80]
Xu, Yuhao and Gu, Tao and Chen, Weifeng and Chen, Arlene , title =. 2025 , isbn =. doi:10.1609/aaai.v39i9.32973 , booktitle =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.