When Sample Selection Bias Precipitates Model Collapse
Pith reviewed 2026-07-03 23:55 UTC · model grok-4.3
The pith
Siloed selection turns data curation into an accelerator of model collapse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
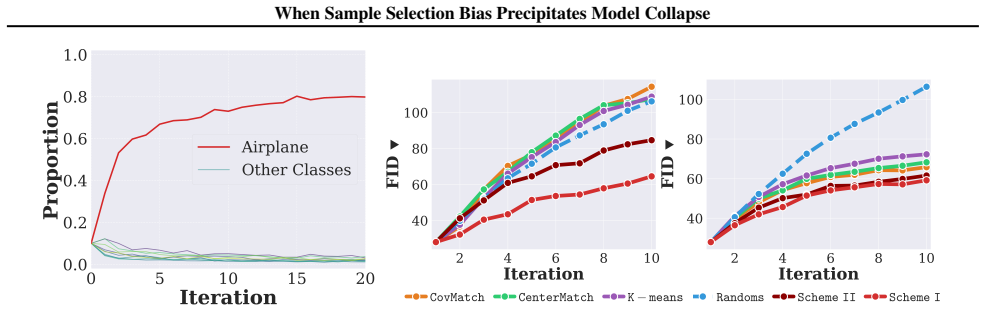
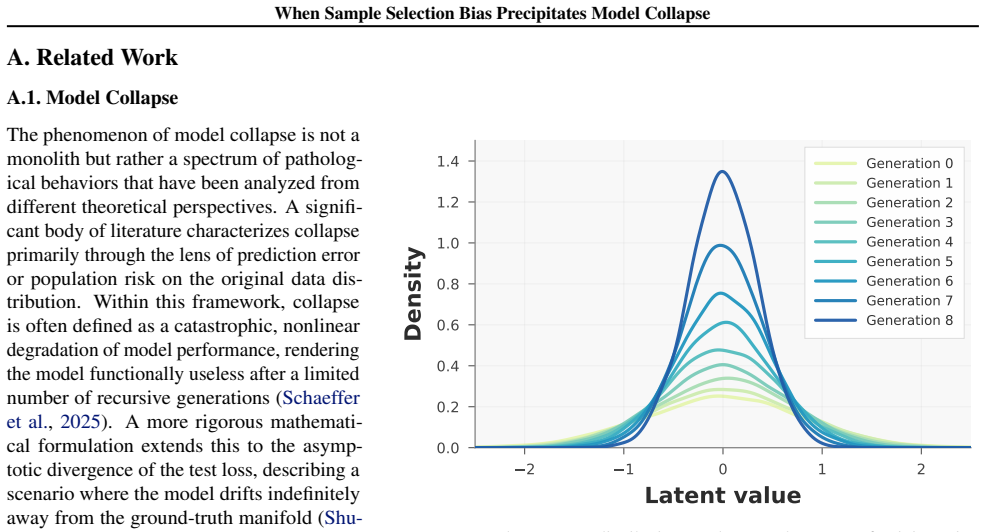
In low-resource verification regimes where each verifier observes only a small, fragmented, and biased slice of the target manifold, selection itself becomes biased, preferentially retaining samples aligned with the local manifold while pruning globally relevant tail modes, which accelerates model collapse and induces power-law diversity decay.
What carries the argument
Biased sample selection under siloed local references that prunes tail modes from the target manifold.
If this is right
- Local-reference selection fails on skewed distributions.
- Collaborative proxy references mitigate diversity degradation without sharing raw data.
- Recursive synthetic-data pipelines require caution when real-data coverage is fragmented or scarce.
Where Pith is reading between the lines
- Similar selection bias may appear in any decentralized training setup that relies on local verifiers.
- Methods for constructing unbiased proxies across silos could extend the usable lifetime of synthetic data pipelines.
- The power-law form of diversity loss implies that collapse becomes progressively harder to reverse once siloed selection begins.
Load-bearing premise
Each verifier observes only a small, fragmented, and biased slice of the target manifold.
What would settle it
Run a controlled recursive training loop on a known skewed distribution and measure whether diversity metrics decay faster under siloed local selection than under a single global reference.
Figures


read the original abstract
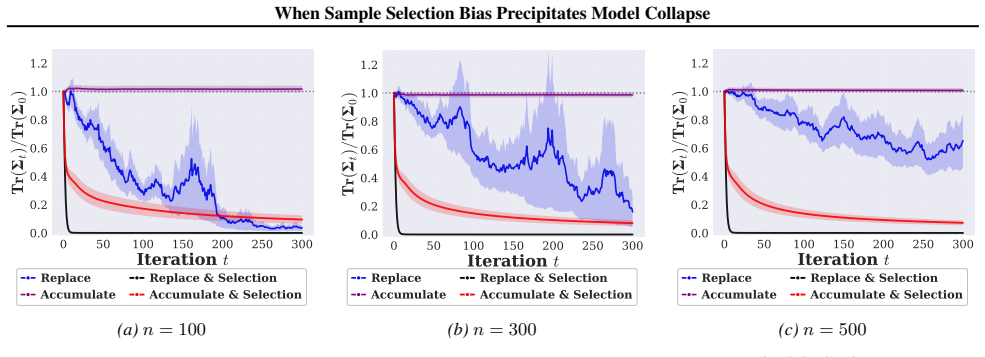
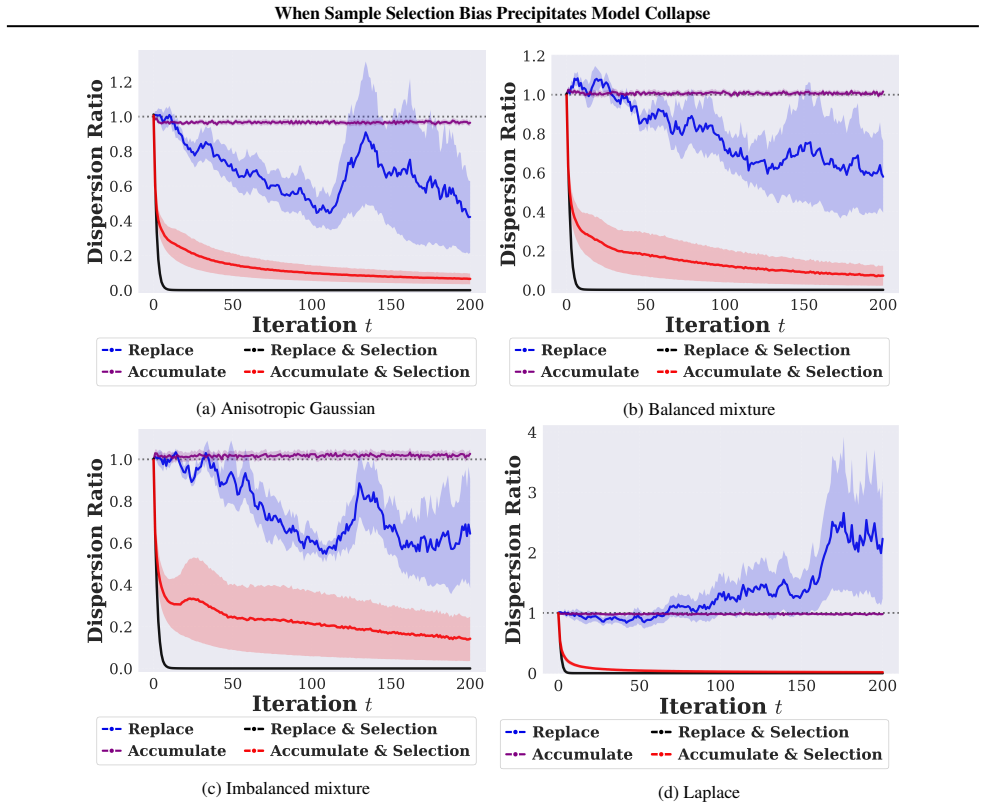
The proliferation of recursive training on synthetic data can alleviate data scarcity but risks model collapse, where repeated training erodes distributional tails and homogenizes outputs. Data selection is widely viewed as a remedy, yet its reliability depends critically on the reference distribution used by the verifier. We show that in low-resource verification regimes, where each verifier observes only a small, fragmented, and biased slice of the target manifold, selection itself becomes biased. This situation naturally arises in low-resource data silos such as healthcare consortia or proprietary financial institutions, where raw data cannot be pooled and local references are inherently incomplete. As a result, selection preferentially retains samples aligned with the local manifold while pruning globally relevant tail modes, turning from a safeguard against collapse into a mechanism that precipitates it. We theoretically prove that such siloed selection accelerates collapse and induces power-law diversity decay. As an initial mitigation, we construct Wasserstein proxy references from multiple silos without sharing raw data. Empirical results confirm that local-reference selection fails on skewed distributions, whereas collaborative proxy references mitigate diversity degradation, suggesting that recursive synthetic-data pipelines require particular caution when real-data coverage is fragmented or scarce.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
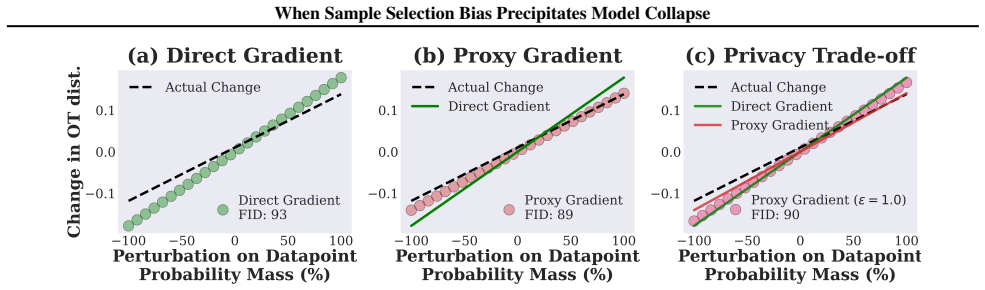
Summary. The paper claims that in low-resource siloed verification regimes—where each verifier sees only a small, fragmented, biased slice of the target manifold—data selection based on local references ceases to mitigate model collapse during recursive synthetic-data training and instead accelerates it, producing power-law diversity decay. It provides a theoretical proof of this effect, constructs Wasserstein proxy references across silos without raw-data sharing as mitigation, and reports empirical confirmation that local-reference selection fails on skewed distributions while collaborative proxies reduce diversity degradation.
Significance. If the central theoretical result holds, the work identifies a previously under-appreciated failure mode for selection-based safeguards in distributed or privacy-constrained settings (healthcare consortia, financial institutions). The Wasserstein-proxy construction is a constructive, non-sharing mitigation that directly addresses the identified bias; the empirical results on skewed distributions provide a falsifiable test of the local-vs-collaborative distinction.
major comments (1)
- [Theoretical section] Theoretical section (proof of accelerated collapse and power-law diversity decay): the derivation models selection as a biased projection onto static local manifolds. It is unclear whether the recursive feedback—where retained synthetic samples become the new training distribution and thereby shift the effective support observed by each silo on the next iteration—is incorporated into the power-law exponent or the acceleration claim. This feedback loop is load-bearing for the headline result that siloed selection precipitates rather than prevents collapse.
minor comments (1)
- [Abstract and introduction] Abstract and §1: the precise definition of 'low-resource verification regime' (sample size per silo, fragmentation measure) is stated qualitatively; a short formal definition or parameter range would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a point that requires clarification in the theoretical section. The comment concerns whether the recursive feedback loop is captured in the proof of accelerated collapse and power-law decay; we address this directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Theoretical section] Theoretical section (proof of accelerated collapse and power-law diversity decay): the derivation models selection as a biased projection onto static local manifolds. It is unclear whether the recursive feedback—where retained synthetic samples become the new training distribution and thereby shift the effective support observed by each silo on the next iteration—is incorporated into the power-law exponent or the acceleration claim. This feedback loop is load-bearing for the headline result that siloed selection precipitates rather than prevents collapse.
Authors: The derivation models the process as an iterated operator. At each generation t the current empirical distribution (produced by training on the samples retained at t-1) defines the support seen by each silo; the biased projection is then applied to this updated distribution. The power-law exponent is obtained by analyzing the contraction rate of the iterated biased operator, which compounds the local truncation of tail modes across steps. The acceleration claim follows from comparing the spectral radius of the siloed operator to that of the global-reference operator; the former is strictly larger because the bias prevents re-introduction of pruned modes. We will insert a short paragraph after the statement of the main theorem that explicitly writes the recursion and shows how the exponent depends on the per-iteration bias factor. revision: yes
Circularity Check
No circularity: theoretical proof and external Wasserstein metric remain independent of fitted inputs
full rationale
The provided abstract and context describe a theoretical proof that siloed selection accelerates collapse with power-law diversity decay, plus mitigation via Wasserstein proxy references constructed without raw data sharing. No equations, self-citations, or fitted parameters are exhibited that would reduce the claimed acceleration or power-law result to a definition, renaming, or input by construction. The central derivation is presented as self-contained against external benchmarks and does not rely on load-bearing self-citation chains or ansatzes smuggled from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption each verifier observes only a small, fragmented, and biased slice of the target manifold
Reference graph
Works this paper leans on
-
[1]
Learning with submodular functions: A convex optimization perspective.Foundations and Trends® in Machine Learning, 6(2-3):145–373, 2013
6 Bach, F. Learning with submodular functions: A convex optimization perspective.Foundations and Trends® in Machine Learning, 6(2-3):145–373, 2013. 7 Bertrand, Q., Bose, J., Duplessis, A., Jiralerspong, M., and Gidel, G. On the stability of iterative retraining of generative models on their own data. InThe Twelfth International Conference on Learning Repr...
2013
-
[2]
URL https://openreview.net/forum? id=JORAfH2xFd. 1, 2, 8 Bertsekas, D. P. Nonlinear programming.Journal of the Operational Research Society, 48(3):334–334, 1997. 5 Chen, D., Yu, N., Zhang, Y ., and Fritz, M. Gan-leaks: A taxonomy of membership inference attacks against gener- ative models. InProceedings of the 2020 ACM SIGSAC Conference on Computer and Co...
-
[3]
JMLR Workshop and Conference Proceedings,
-
[4]
8 Courty, N., Flamary, R., Habrard, A., and Rakotomamonjy, A
URL http://proceedings.mlr.press/ v15/coates11a.html. 8 Courty, N., Flamary, R., Habrard, A., and Rakotomamonjy, A. Joint distribution optimal transportation for domain adaptation. In Guyon, I., Luxburg, U. V ., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R. (eds.),Advances in Neural Information Processing Systems, volume 30. Curra...
-
[5]
cc/paper_files/paper/2017/file/ 0070d23b06b1486a538c0eaa45dd167a-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2017/file/ 0070d23b06b1486a538c0eaa45dd167a-Paper. pdf. 5 Courty, N., Flamary, R., and Ducoffe, M. Learning wasserstein embeddings. InInternational Conference on Learning Representations, 2018. URL https:// openreview.net/forum?id=SJyEH91A-. 6 10 When Sample Selection Bias Precipitates Model Collapse C...
-
[6]
2, 4 Fu, S., Wang, Y ., Chen, Y ., Shen, L., and Tao, D
URL https://openreview.net/forum? id=cyv0LkIaoH. 2, 4 Fu, S., Wang, Y ., Chen, Y ., Shen, L., and Tao, D. Self- verification provably prevents model collapse in recur- sive synthetic training. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[7]
truly anonymous
URL https://openreview.net/forum? id=X5Hk8aMs6w. 1 Ganev, G. and De Cristofaro, E. The inadequacy of similarity-based privacy metrics: Privacy attacks against “truly anonymous” synthetic datasets. In2025 IEEE Sym- posium on Security and Privacy (SP), pp. 4007–4025. IEEE, 2025. 5 Gerstgrasser, M., Schaeffer, R., Dey, A., Rafailov, R., Kor- bak, T., Sleight...
2025
-
[8]
16 Grover, A., Song, J., Kapoor, A., Tran, K., Agarwal, A., Horvitz, E
URL https://openreview.net/forum? id=5B2K4LRgmz. 16 Grover, A., Song, J., Kapoor, A., Tran, K., Agarwal, A., Horvitz, E. J., and Ermon, S. Bias correction of learned generative models using likelihood-free importance weighting. InAdvances in Neural Information Pro- cessing Systems, volume 32. Curran Associates, Inc.,
-
[9]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision
URL https://proceedings.neurips. cc/paper_files/paper/2019/file/ d76d8deea9c19cc9aaf2237d2bf2f785-Paper. pdf. 5 Gui, L., Garbacea, C., and Veitch, V . BoNBon alignment for large language models and the sweetness of best-of-n sam- pling. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https:// openreview.net/forum?...
-
[10]
5 Kazdan, J., Schaeffer, R., Dey, A., Gerstgrasser, M., Rafailov, R., Donoho, D
URL https://openreview.net/forum? id=JJuP86nBl4q. 5 Kazdan, J., Schaeffer, R., Dey, A., Gerstgrasser, M., Rafailov, R., Donoho, D. L., and Koyejo, S. Collapse or thrive: Perils and promises of synthetic data in a self- generating world. InForty-second International Confer- ence on Machine Learning, 2025. 1, 2, 3, 4, 16, 21 Kenthapadi, K., Korolova, A., Mi...
2025
-
[11]
5 Koh, P
URL https://openreview.net/forum? id=0UCoWxPhQ4. 5 Koh, P. W. and Liang, P. Understanding black-box pre- dictions via influence functions. In Precup, D. and Teh, Y . W. (eds.),Proceedings of the 34th International Confer- ence on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pp. 1885–1894. PMLR, 06– 11 Aug 2017. URL https://proce...
2017
-
[12]
38 Kynkäänniemi, T., Karras, T., Laine, S., Lehtinen, J., and Aila, T. Improved precision and recall metric for assess- ing generative models.Advances in neural information processing systems, 32, 2019. 8, 39 Lê Tien, N., Habrard, A., and Sebban, M. Differentially pri- vate optimal transport: Application to domain adaptation. InIJCAI, pp. 2852–2858, 2019....
-
[13]
cc/paper_files/paper/2020/file/ 2288f691b58edecadcc9a8691762b4fd-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2020/file/ 2288f691b58edecadcc9a8691762b4fd-Paper. pdf. 16 Nemhauser, G. L., Wolsey, L. A., and Fisher, M. L. An analysis of approximations for maximizing submodular set functions—i.Mathematical programming, 14(1):265– 294, 1978. 7 Peyré, G., Cuturi, M., et al. Computational optimal trans- port: With a...
2020
-
[14]
17 Qiao, X., Ding, N., Cheng, Y ., and Zhang, M
URL https://openreview.net/forum? id=C3TrHWanh5. 17 Qiao, X., Ding, N., Cheng, Y ., and Zhang, M. Beyond binary erasure: Soft-weighted unlearning for fairness and robustness. InProceedings of the AAAI Confer- ence on Artificial Intelligence, volume 40, pp. 24936– 24944, 2026. URL https://ojs.aaai.org/ index.php/AAAI/article/view/39681. 17 Rakotomamonjy, A...
2026
-
[15]
6, 7, 17, 34, 35, 38 Redko, I., Habrard, A., and Sebban, M
URL https://openreview.net/forum? id=rsg1mvUahT. 6, 7, 17, 34, 35, 38 Redko, I., Habrard, A., and Sebban, M. Theoretical analysis of domain adaptation with optimal transport. In Ceci, M., Hollmén, J., Todorovski, L., Vens, C., and Džeroski, S. (eds.),Machine Learning and Knowledge Discovery in Databases, pp. 737–753, Cham, 2017. Springer Interna- tional P...
2017
-
[16]
40 Ruhe, A. Perturbation bounds for means of eigenvalues and invariant subspaces.BIT Numerical Mathematics, 10(3): 343–354, 1970. 19 Schaeffer, R., Kazdan, J., Arulandu, A. C., and Koyejo, S. Position: Model collapse does not mean what you think. arXiv preprint arXiv:2503.03150, 2025. 1, 16 Shi, L., Wu, M., Zhang, H., Zhang, Z., Tao, M., and Qu, Q. A clos...
-
[17]
1, 2, 3, 8, 16, 17, 40 Shidani, A., Farghly, T., Sun, Y ., Ganjgahi, H., and Deligian- nidis, G
URL https://openreview.net/forum? id=6xCcjYa97j. 1, 2, 3, 8, 16, 17, 40 Shidani, A., Farghly, T., Sun, Y ., Ganjgahi, H., and Deligian- nidis, G. Beyond real data: Synthetic data through the lens of regularization.arXiv preprint arXiv:2510.08095,
-
[18]
The Curse of Recursion: Training on Generated Data Makes Models Forget
1, 8 13 When Sample Selection Bias Precipitates Model Collapse Shoshan, A., Bhonker, N., Kviatkovsky, I., Fintz, M., and Medioni, G. Synthetic data for model selection. InIn- ternational Conference on Machine Learning, pp. 31633– 31656. PMLR, 2023. 17 Shumailov, I., Shumaylov, Z., Zhao, Y ., Gal, Y ., Paper- not, N., and Anderson, R. J. The curse of recur...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Llama 2: Open Foundation and Fine-Tuned Chat Models
1, 2, 3, 4, 16, 20 Song, J., Meng, C., and Ermon, S. Denoising diffusion implicit models. InInternational Conference on Learning Representations, 2021. URL https://openreview. net/forum?id=St1giarCHLP. 40 Sorscher, B., Geirhos, R., Shekhar, S., Ganguli, S., and Morcos, A. S. Beyond neural scaling laws: beating power law scaling via data pruning. In Oh, A....
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Membership inference attacks against synthetic data through overfitting detection
46 van Breugel, B., Sun, H., Qian, Z., and van der Schaar, M. Membership inference attacks against synthetic data through overfitting detection. In Ruiz, F., Dy, J., and van de Meent, J.-W. (eds.),Proceedings of The 26th International Conference on Artificial Intelligence and Statistics, volume 206 ofProceedings of Machine Learning Research, pp. 3493–3514...
-
[21]
5 Villani, C
URL https://proceedings.mlr.press/ v206/breugel23a.html. 5 Villani, C. et al.Optimal transport: old and new, volume
-
[22]
17, 38 Wei, X
Springer, 2008. 17, 38 Wei, X. and Zhang, X. Self-consuming generative models with adversarially curated data. InForty- second International Conference on Machine Learning,
2008
-
[23]
2, 4, 5 Wyllie, S., Shumailov, I., and Papernot, N
URL https://openreview.net/forum? id=UWWNxyIT1h. 2, 4, 5 Wyllie, S., Shumailov, I., and Papernot, N. Fairness feed- back loops: training on synthetic data amplifies bias. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pp. 2113–2147, 2024. 1 Yi, B., Liu, Q., Cheng, Y ., and Xu, H. Escaping model col- lapse via synt...
2024
-
[24]
1, 2 Zhou, Y ., Liang, Z., Liu, H., Yu, W., Panaganti, K., Song, L., Yu, D., Zhang, X., Mi, H., and Yu, D
URL https://openreview.net/forum? id=yfk6c39omW. 1, 2 Zhou, Y ., Liang, Z., Liu, H., Yu, W., Panaganti, K., Song, L., Yu, D., Zhang, X., Mi, H., and Yu, D. On the evolution of language models without labels: Majority drives selec- tion, novelty promotes variation. InThe 5th Workshop on Mathematical Reasoning and AI at NeurIPS 2025,
2025
-
[25]
long tail
URL https://openreview.net/forum? id=eU9fZMrrAL. 1 14 When Sample Selection Bias Precipitates Model Collapse Table of Contents A Related Work· · · · · · · · · · · · · · · · · · · · · · · · · · · · · · ·16 A.1 Model Collapse· · · · · · · · · · · · · · · · · · · · · · · · · · · ·16 A.2 Data Selection· · · · · · · · · · · · · · · · · · · · · · · · · · · ·17 ...
2025
-
[26]
ground truth
explore using generative models to synthesize validation sets for model selection, contingent on the ability to calibrate synthetic error against real-domain risk. Under this framework, the efficacy of selection is strictly bounded by the precision and recall of the external supervisor relative to the ground truth. Research Gap: The Absence of Global Veri...
2022
-
[27]
The selection region Rcorresponds to a regionD(c)in the standardized space, wherec=Σ −1/2(µ−u ∗)is the standardized error vector
Transformation to Standardized Space:Let z=Σ −1/2(x−µ) be the whitening transformation. The selection region Rcorresponds to a regionD(c)in the standardized space, wherec=Σ −1/2(µ−u ∗)is the standardized error vector. The mean drift vector in the parameter space is given by ∆=Σ 1/2a(c), where a(c) =E[z|z∈ D(c)] is the drift in the standardized frame. We a...
-
[28]
By applying the Brascamp- Lieb inequality (or properties of log-concave measures), the conditional covariance is strictly contracted relative to the identity matrix
Gradient Analysis (Strict Contraction):The Jacobian of the standardized drift is related to the conditional covariance: ∇ca(c) =Cov(z|z∈ D(c))−I d.(28) Since the utility function U(x) is locally concave, the selection induces a log-concave constraint. By applying the Brascamp- Lieb inequality (or properties of log-concave measures), the conditional covari...
-
[29]
Note thata(0) =0due to the local symmetry around the optimum
Inner Product Bound:Instead of approximating the vector a(c), we apply the Mean Value Theorem directly to the inner productc ⊤a(c). Note thata(0) =0due to the local symmetry around the optimum. c⊤a(c) =c ⊤ Z 1 0 ∇a(tc)dt c.(30) Since the Jacobian is uniformly bounded by−κI d, the quadratic form is bounded as: c⊤a(c)≤ −κ∥c∥ 2.(31)
-
[30]
Mapping back to Parameter Space:We substitute the standardized variables back into the Mahalanobis inner product: (µ−u ∗)⊤Σ−1∆= (Σ 1/2c)⊤Σ−1(Σ1/2a(c))(32) =c ⊤Σ1/2Σ−1Σ1/2a(c)(33) =c ⊤a(c)(34) ≤ −κ∥c∥2 (35) =−κ∥µ−u ∗∥2 Σ−1 .(36) This confirms that the drift acts as a restoring force in the natural geometry induced by the covarianceΣ. 18 When Sample Selecti...
1971
-
[31]
Lemma 3(Special Case of equation RS, Liu et al
P∞ n=0 yn <∞a.s. Lemma 3(Special Case of equation RS, Liu et al. (2025)).Maintain the setting and notation of Lemma 2. Let {Tn}n≥0 be a deterministic sequence with 0< T n <1 for all n. Let α >0 and η >0 be constants and suppose the sequences are identified asa n = 0, x n =ηT 2 n, y n =αT nzn. This yields the following recursion: En[zn+1 | F n]≤(1−αT n)z n...
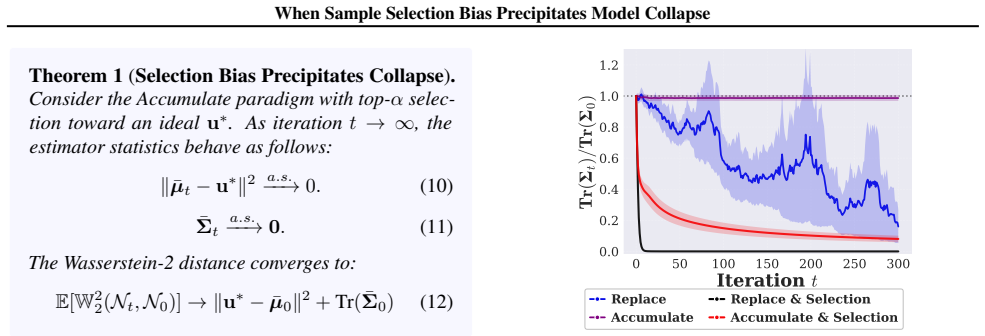
2025
-
[32]
Wasserstein Divergence (E[W2 2]→ ∞ ).First, observe that the Wasserstein-2 distance between the approximation N( ¯µt, ¯Σt)and the true distributionN 0 is lower-bounded by the Euclidean distance of their means: W2 2(N( ¯µt, ¯Σt),N 0)≥ ∥ ¯µt − ¯µ0∥2.(42) Let ˆµ0 and ˆΣ0 be the empirical mean and covariance estimated from the initial samples ofN 0. By the tr...
2024
-
[33]
Within" terms plus the historical
Variance Collapse (¯Σt a.s. − − →0).The proof relies on the martingale properties of the covariance trace. Consider the recursive update step where samples are generated asX i,t = ¯Σ1/2 t−1zi,t + ¯µt−1 withz i,t ∼ N(0,I d). The trace of the covariance matrix, Tr(¯Σt), forms a lower-bounded supermartingale. By Doob’s Martingale Convergence Theorem, it must...
2024
-
[34]
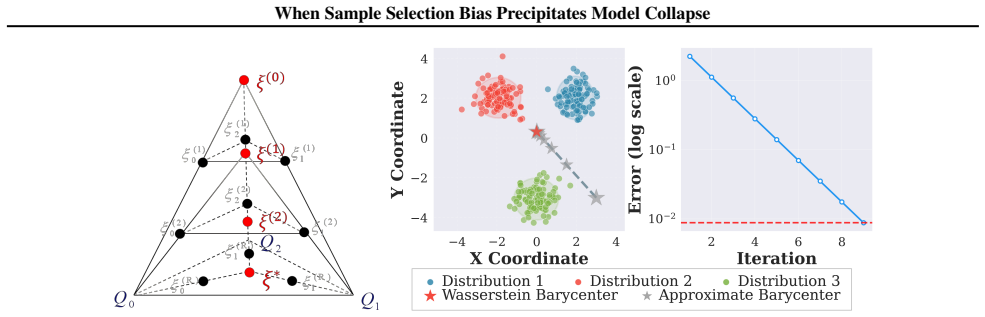
Decomposition via Geodesic Interpolants.In the interpolation step, ξ(r) P is computed as the interpolating measure between P and the current proxy ξ(r) k , and ξ(r) Qk is the interpolating measure between Qk and ξ(r) k . According to Property 3 and the definition of interpolating measures in (Rakotomamonjy et al., 2024), these points satisfy the equality ...
2024
-
[35]
The new proxy ξ(r+1) k is constructed as the interpolating measure between the intermediatesξ (r) P andξ (r) Qk
Monotonicity Analysis.Consider the next iteration r+ 1 . The new proxy ξ(r+1) k is constructed as the interpolating measure between the intermediatesξ (r) P andξ (r) Qk. We start by applying the triangle inequality to the new terms inE (r+1) k : Wp(P, ξ(r+1) k )≤ W p(P, ξ(r) P ) +W p(ξ(r) P , ξ(r+1) k ),(173) Wp(Qk, ξ(r+1) k )≤ W p(Qk, ξ(r) Qk) +W p(ξ(r) ...
-
[36]
Convergence.By the triangle inequality, for any ξ, we have Wp(P,Q k)≤ W p(P, ξ) +W p(ξ,Q k). Therefore, the sequence is bounded below by the true transport cost: E(r) k ≥ W p(P,Q k).(180) Since {E(r) k } is non-increasing and bounded below, it converges to its infimum by the Monotone Convergence Theorem. As shown in (Rakotomamonjy et al., 2024), as r→ ∞ ,...
2024
-
[37]
Notation and Sequence Definition.The objective function to minimize is the weighted Fréchet variance, defined in the continuous space as: E(ξ) = KX k=1 λkW2 2(Qk, ξ) = KX k=1 λk inf πk∈Π(Qk,ξ) Z X ×X ∥x−y∥ 2 dπk(x,y),(182) where K is the total number of target clients, andλk >0 denotes the aggregation weight for clientk such thatPK k=1 λk = 1. To ensure a...
-
[38]
The element P (r−1) k,ij explicitly represents the probability mass transported from yi to xk,j
Step 1: Majorization via Fixed Transport Plans.Let P(r−1) k denote the optimal coupling matrix between the current proxy ξ(r−1) and the client data Qk. The element P (r−1) k,ij explicitly represents the probability mass transported from yi to xk,j. Mass conservation dictates the marginal constraintPMk j=1 P (r−1) k,ij =w i. For any candidate distribution ...
-
[39]
Step 2: Minimization via Barycentric Interpolation.To isolate the optimization variables zi, we define the barycentric projectionˆ xk,i. This represents the weighted center of the target data inQ k that is mapped to thei-th proxy point: ˆ xk,i = 1 wi MkX j=1 P (r−1) k,ij xk,j .(185) 36 When Sample Selection Bias Precipitates Model Collapse To reveal the s...
-
[40]
realistic
Monotonicity and Convergence.Chaining the majorization property (Equation (184)), the minimization descent (Equation (190)), and the tight bound at the previous step, we establish the descent property: E(ξ (r))≤ U(ξ (r), ξ(r−1))≤ U(ξ (r−1), ξ(r−1)) =E(ξ (r−1)).(191) Since the sequence {E(r)} is non-increasing and bounded below by 0, it converges to its in...
2019
-
[41]
memory anchor,
framework utilizing a standard U-Net (Ronneberger et al., 2015) architecture. The diffusion process is trained over T= 1000 timesteps employing a linear variance schedule. For efficient inference, we use the Denoising Diffusion Implicit Models (DDIM) (Song et al., 2021) algorithm with 50 sampling steps. In each generation cycle, we synthesize a candidate ...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.