Customized Generative AI Agent for Transportation Engineering Practice: A Development and Continued Pre-training Guideline
Pith reviewed 2026-06-30 09:23 UTC · model grok-4.3
The pith
LoRA-based continued pretraining on U.S. transportation documents improves LLM performance on technical interpretation and context-specific reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
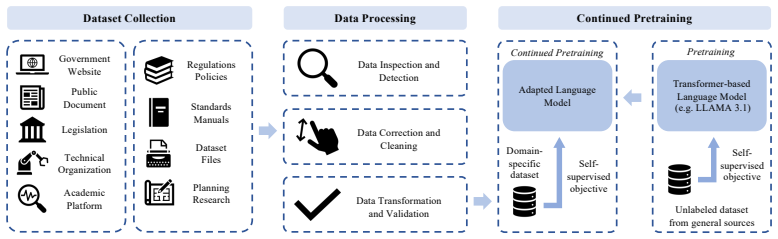
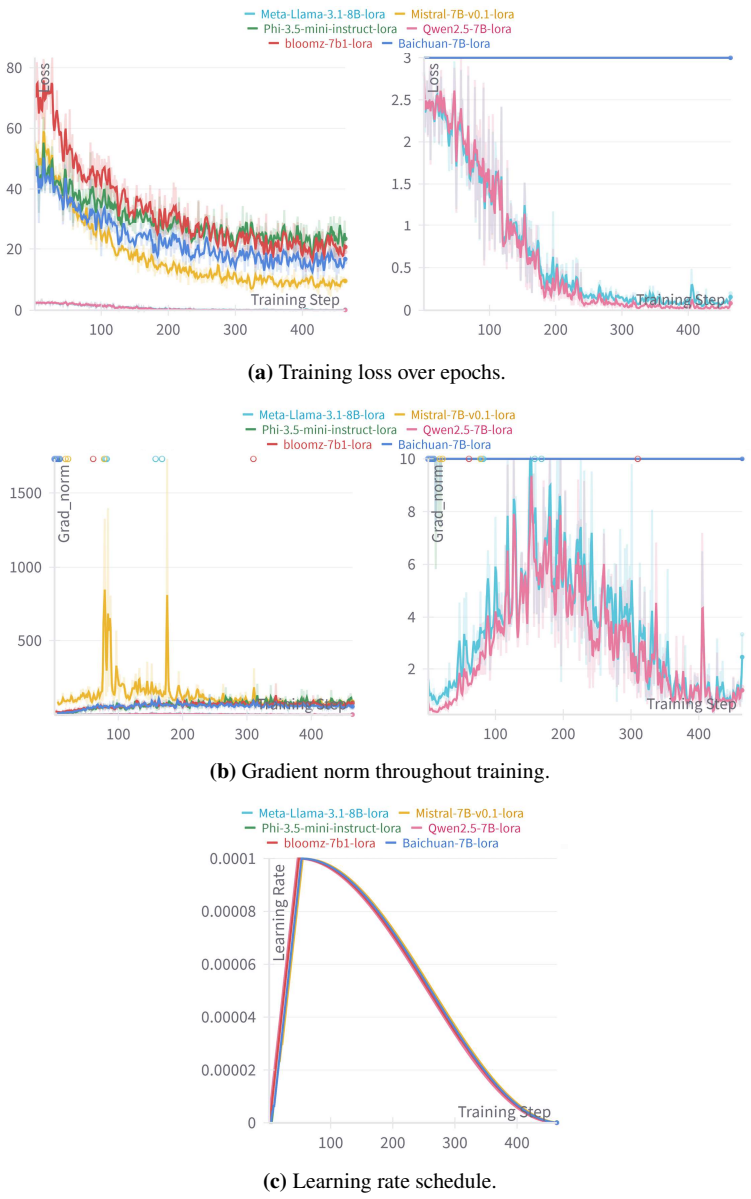
The authors establish that continued pretraining of six state-of-the-art LLMs through a unified LoRA framework on a curated corpus of U.S. transportation manuals, design guidelines, and regulatory documents produces measurable gains in technical content interpretation and context-specific reasoning, with Qwen2.5-7B and LLaMA-3.1-8B recording the highest domain alignment and response quality under BLEU-4 and ROUGE evaluation.
What carries the argument
The unified LoRA framework applied to continued pretraining on the curated corpus of transportation documents, which aligns model parameters to domain terminology and standards while preserving stability.
If this is right
- Qwen2.5-7B and LLaMA-3.1-8B achieve the strongest domain alignment among the six tested models.
- The training process can be monitored to confirm convergence and avoid instability.
- The resulting agents support tasks in transportation research, design, planning, and policy analysis.
- The method supplies a reusable template for building other domain-specialized generative agents.
Where Pith is reading between the lines
- The same corpus-plus-LoRA recipe could be tried on other engineering fields to check whether similar gains appear.
- The adapted models might be combined with retrieval systems that pull from live transportation databases.
- Longer-term testing could measure whether the improvements hold when the models answer questions that require integrating multiple guidelines at once.
Load-bearing premise
The curated set of U.S. transportation manuals and guidelines is representative of the full domain and large enough to create genuine alignment during pretraining.
What would settle it
Evaluation of the adapted models on a held-out set of new transportation engineering questions or documents shows no gain over the original base LLMs on BLEU-4, ROUGE, or direct expert judgment of reasoning accuracy.
Figures

read the original abstract
Recent advancements in generative artificial intelligence (AI) and large language models (LLMs) have shown significant promise in automating complex reasoning, summarization, and question-answering tasks. However, the effectiveness of general-purpose LLMs in specialized engineering domains remains limited due to insufficient exposure to technical standards, engineering terminology, and domain-specific semantics. This study proposes a systematic approach to developing a customized generative AI agent for transportation engineering applications. A curated corpus of U.S. transportation manuals, design guidelines, and regulatory documents is used to conduct continued pretraining of six state-of-the-art LLMs through a unified low-rank adaptation (LoRA) framework. The training process is monitored to ensure convergence and model stability. Performance is evaluated using standard natural language processing metrics, including BLEU-4 and ROUGE, with Qwen2.5-7B and LLaMA-3.1-8B demonstrating the highest domain alignment and response quality. Results validate the effectiveness of LoRA-based adaptation in improving LLM performance on technical content interpretation and context-specific reasoning. This work contributes a reproducible development framework for constructing domain-specialized generative AI agents, supporting broader deployment in transportation research, design, planning, and policy analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a systematic framework for creating domain-specialized generative AI agents in transportation engineering. It curates a corpus of U.S. transportation manuals, design guidelines, and regulatory documents, then applies continued pretraining via a unified LoRA framework to six state-of-the-art LLMs. Training convergence is monitored, and performance is assessed with BLEU-4 and ROUGE; Qwen2.5-7B and LLaMA-3.1-8B are identified as best-performing. The work concludes that LoRA adaptation improves LLM performance on technical content interpretation and context-specific reasoning and supplies a reproducible development guideline.
Significance. If the central claims were supported by appropriate evidence, the paper would supply a practical, reproducible recipe for domain adaptation of LLMs in a regulated engineering field, with potential utility for research, design, and policy tasks. The contribution is primarily methodological rather than theoretical; its value hinges on whether the reported metric gains translate to improved factual correctness and engineering reasoning.
major comments (2)
- [Abstract] Abstract: the claim that BLEU-4 and ROUGE results 'validate the effectiveness of LoRA-based adaptation in improving LLM performance on technical content interpretation and context-specific reasoning' is unsupported. These metrics quantify surface n-gram overlap with reference texts and do not measure factual accuracy against standards, logical soundness of engineering inferences, or handling of regulatory edge cases.
- [Evaluation] Evaluation (implied by abstract description): no data volume, training details (learning rate, epochs, rank, alpha), baseline comparisons against the unmodified base models, statistical tests, or description of the held-out test set are supplied, rendering the reported superiority of Qwen2.5-7B and LLaMA-3.1-8B impossible to interpret or reproduce.
minor comments (1)
- The manuscript should clarify whether the continued pretraining corpus overlaps with the evaluation references, as any overlap would inflate BLEU/ROUGE scores by construction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting limitations in our evaluation approach and missing methodological details. We agree that revisions are needed to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that BLEU-4 and ROUGE results 'validate the effectiveness of LoRA-based adaptation in improving LLM performance on technical content interpretation and context-specific reasoning' is unsupported. These metrics quantify surface n-gram overlap with reference texts and do not measure factual accuracy against standards, logical soundness of engineering inferences, or handling of regulatory edge cases.
Authors: We agree that BLEU-4 and ROUGE are n-gram overlap metrics and cannot directly validate factual accuracy, logical soundness of inferences, or handling of regulatory edge cases. The abstract claim overstated the implications of these results. We will revise the abstract to state that the metrics indicate improved lexical and stylistic alignment with domain texts after LoRA adaptation, while explicitly noting their limitations for assessing deeper technical reasoning or factual correctness. A similar clarification will be added to the evaluation discussion. revision: yes
-
Referee: [Evaluation] Evaluation (implied by abstract description): no data volume, training details (learning rate, epochs, rank, alpha), baseline comparisons against the unmodified base models, statistical tests, or description of the held-out test set are supplied, rendering the reported superiority of Qwen2.5-7B and LLaMA-3.1-8B impossible to interpret or reproduce.
Authors: The referee correctly identifies that the manuscript omits key details required for reproducibility and interpretation, including corpus volume, training hyperparameters (learning rate, epochs, LoRA rank and alpha), direct comparisons to unmodified base models, statistical tests, and held-out test set description. We will add these in a revised experiments section, including corpus statistics, full training configuration, baseline results on the six unmodified models, any statistical comparisons, and details on test set construction and size. revision: yes
Circularity Check
No circularity in adaptation and evaluation pipeline
full rationale
The paper describes curating a domain corpus, applying continued pretraining via a standard LoRA framework to base LLMs, monitoring convergence, and evaluating outputs with independent NLP metrics (BLEU-4, ROUGE). No equations, self-definitional mappings, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The workflow is a conventional empirical domain-adaptation procedure whose performance claims rest on external metrics rather than reducing to the training inputs by construction. This is a self-contained experimental report with no enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Amalina, R., Sardi, I., Fikriansvah, M., et al.\@ (2024). ``Public transportation ontology-based question answering system in bandung city using na \" ve bayes via telegram bot.''\ 2024 International Conference on Data Science and Its Applications (ICoDSA) , IEEE, 260--265
2024
-
[3]
Association, A. P. (2006). Planning and urban design standards . John Wiley & Sons
2006
-
[4]
and Lethier, V
Buhler, T. and Lethier, V. (2020). ``Analysing urban policy discourses using textometry: An application to french urban transport plans (2000--2015).''\ Urban Studies , 57(10), 2181--2197
2020
-
[5]
and Feinstein, Z
Cao, Z. and Feinstein, Z. (2024). ``Large language model in financial regulatory interpretation.''\ 2024 IEEE Symposium on Computational Intelligence for Financial Engineering and Economics (CIFEr) , IEEE, 1--7
2024
-
[6]
Cascella, M., Montomoli, J., Bellini, V., and Bignami, E. (2023). ``Evaluating the feasibility of chatgpt in healthcare: an analysis of multiple clinical and research scenarios.''\ Journal of medical systems , 47(1), 33
2023
-
[8]
O zg \"u ner, \
Chen, D., Yurtsever, E., Redmill, K. A., and \"O zg \"u ner, \"U . (2023). ``Using collision momentum in deep reinforcement learning based adversarial pedestrian modeling.''\ 2023 IEEE Intelligent Vehicles Symposium (IV) , IEEE, 1--6
2023
-
[9]
Chen, D., Zhang, Z., Liu, Y., and Yang, X. T. (2025). ``Insight: Enhancing autonomous driving safety through vision-language models on context-aware hazard detection and edge case evaluation.''\ arXiv e-prints , arXiv--2502
2025
-
[10]
DoT, U. (2018). ``Preparing for the future of transportation: Automated vehicles 3.0.''\ US https://www. transportation. gov/av/3
2018
-
[15]
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. (2021). ``Measuring massive multitask language understanding, < https://arxiv.org/abs/2009.03300 >
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.-A., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E. (2023). ``Mistral 7b, < https://arxiv.org/abs/2310.06825 >
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
D., and Huang, V
Karapantelakis, A., Thakur, M., Nikou, A., Moradi, F., Olrog, C., Gaim, F., Holm, H., Nimara, D. D., and Huang, V. (2024). ``Using large language models to understand telecom standards.''\ 2024 IEEE International Conference on Machine Learning for Communication and Networking (ICMLCN) , IEEE, 440--446
2024
-
[18]
H., Matthee, M
Kroeze, J. H., Matthee, M. C., and Bothma, T. J. (2003). ``Differentiating data-and text-mining terminology.''\ Proceedings of the 2003 annual research conference of the South African institute of computer scientists and information technologists on Enablement through technology , 93--101
2003
-
[19]
Laskar, M. T. R., Alqahtani, S., Bari, M. S., Rahman, M., Khan, M. A. M., Khan, H., Jahan, I., Bhuiyan, A., Tan, C. W., Parvez, M. R., et al.\@ (2024). ``A systematic survey and critical review on evaluating large language models: Challenges, limitations, and recommendations.''\ Proceedings of the 2024 Conference on Empirical Methods in Natural Language P...
2024
-
[20]
F., Messous, A., Sekiya, M., Suga, J., Hikichi, K., and Unno, Y
Lavi, O., Manor, O., Schwartz, T., Murillo, A. F., Messous, A., Sekiya, M., Suga, J., Hikichi, K., and Unno, Y. (2024). ``Fine-tuning large language models for network traffic analysis in cyber security.''\ 2024 IEEE Conference on Dependable and Secure Computing (DSC) , IEEE, 45--50
2024
-
[23]
K., Eisenstein, J., Ant \'o n, A
Massey, A. K., Eisenstein, J., Ant \'o n, A. I., and Swire, P. P. (2013). ``Automated text mining for requirements analysis of policy documents.''\ 2013 21st IEEE International Requirements Engineering Conference (RE) , IEEE, 4--13
2013
-
[24]
Mavrogiorgos, K., Kiourtis, A., Mavrogiorgou, A., Manias, G., and Kyriazis, D. (2023). ``A question answering software for assessing ai policies of oecd countries.''\ Proceedings of the 4th European Symposium on Software Engineering , 31--36
2023
-
[25]
D., Tandon, N., and Clark, P
Mishra, B. D., Tandon, N., and Clark, P. (2017). ``Domain-targeted, high precision knowledge extraction.''\ Transactions of the Association for Computational Linguistics , 5, 233--246
2017
-
[26]
Moroni, S., Buitelaar, E., Sorel, N., and Cozzolino, S. (2020). ``Simple planning rules for complex urban problems: Toward legal certainty for spatial flexibility.''\ Journal of Planning Education and Research , 40(3), 320--331
2020
-
[29]
NSTC, U. (2020). ``Ensuring american leadership in automated vehicle technologies: Automated vehicles 4.0.''\ NSTC, USDOT: Washington, DC, USA
2020
-
[30]
and Stead, D
Pojani, D. and Stead, D. (2015). ``Sustainable urban transport in the developing world: beyond megacities.''\ Sustainability , 7(6), 7784--7805
2015
-
[31]
S., and de Melo, G
Puri, M., Varde, A. S., and de Melo, G. (2023). ``Commonsense based text mining on urban policy.''\ Language Resources and Evaluation , 57(2), 733--763
2023
-
[32]
Ramaraj, V., Swamy, M. V. A., Prince, E. E., and Kumar, C. ``Improving the bert model for long text sequences in question answering domain.''\ Int J Adv Appl Sci ISSN , 2252(8814), 8814
-
[34]
Smetana, M., Salles de Salles, L., Sukharev, I., and Khazanovich, L. (2024). ``Highway construction safety analysis using large language models.''\ Applied Sciences , 14(4), 1352
2024
-
[36]
Tsuji, S., Yagahara, A., Fukuda, A., Tanikawa, T., Kawamata, M., Nishimoto, N., Shimai, K., Hoshino, S., and Ogasawara, K. (2018). ``Appling text-mining to extracting technical terms from textbooks-toward updating the terminology in the field of radiology technology.''\ Nihon Hoshasen Gijutsu Gakkai Zasshi , 74(8), 757--768
2018
-
[37]
Department of Transportation, Federal Highway Administration (2023)
U.S. Department of Transportation, Federal Highway Administration (2023). ``Manual on uniform traffic control devices for streets and highways.''\ Technical Report 11th Edition , Federal Highway Administration, Washington, DC, < https://rosap.ntl.bts.gov/view/dot/73253/dot\_73253\_DS1.pdf > \ (December). Published December 19, 2023; effective January 18, 2024
2023
-
[38]
Veena, G., Gupta, D., Anil, A., and Akhil, S. (2019). ``An ontology driven question answering system for legal documents.''\ 2019 2nd international conference on intelligent computing, instrumentation and control technologies (ICICICT) , Vol. 1, IEEE, 947--951
2019
-
[39]
Vuchic, V. (2017). Transportation for livable cities . Routledge
2017
-
[40]
Waltl, B., Bonczek, G., and Matthes, F. (2018). ``Rule-based information extraction: Advantages, limitations, and perspectives.''\ Jusletter IT (02 2018) , 4
2018
-
[41]
Wandelt, S., Zheng, C., Wang, S., Liu, Y., and Sun, X. (2024). ``Large language models for intelligent transportation: A review of the state of the art and challenges.''\ Applied Sciences , 14(17), 7455
2024
-
[42]
Weiner, E. (2016). Urban transportation planning in the United States: history, policy, and practice . Springer
2016
-
[43]
Winter, K., Rinderle-Ma, S., Grossmann, W., Feinerer, I., and Ma, Z. (2017). ``Characterizing regulatory documents and guidelines based on text mining.''\ On the Move to Meaningful Internet Systems. OTM 2017 Conferences: Confederated International Conferences: CoopIS, C&TC, and ODBASE 2017, Rhodes, Greece, October 23-27, 2017, Proceedings, Part I , Spring...
2017
-
[47]
Zhang, Z., Liu, Y., Peng, Z., Chen, M., Xu, D., and Cui, S. (2024). ``Digital twin-assisted data-driven optimization for reliable edge caching in wireless networks.''\ IEEE Journal on Selected Areas in Communications
2024
-
[49]
Standard practice for the use of the international system of units ( SI ) (the modernized metric system)
ASTM. Standard practice for the use of the international system of units ( SI ) (the modernized metric system). E 380-91a
-
[50]
Burka, L. P. , title =. MUD history , year =
-
[51]
Stiffness matrix from isoparametric closed form shape functions using exact integration
Dasgupta, G. Stiffness matrix from isoparametric closed form shape functions using exact integration. J. Aerosp. Eng
-
[52]
and Loh, J
Duan, L. and Loh, J. T. and Chen, W. F. M- P -f-based analysis of dented tubular members
-
[53]
and Lions, J
Duvant, G. and Lions, J. L. Les in \' e quations en m \' e chanique et en physique
-
[54]
Chang, T. C. Network resource allocation using an expert system with fuzzy logic reasoning
-
[55]
Eshenaur, S. R. and Kulicki, J. M. and Mertz, D. R. Retrofitting distortion-induced fatigue cracking of non-composite steel girder-floorbeam-stringer bridges. Proc., 8th Annual Int. Bridge Conf
-
[56]
Garrett, D. L. Coupled analysis of floating production systems. Proc., Int. Symp. on Deep Mooring Systems
-
[57]
and Koenders, M
Gaspar, N. and Koenders, M. A. Micromechanic formulation of macroscopic structures in a granular medium. J. Engrg. Mech
-
[58]
and Koenders, M
Gaspar, N. and Koenders, M. A. Estimates of the shear modulus of a granular assembly using heterogeneous media techniques. Powders and Grains 2001
2001
-
[59]
Evaluating scour at bridges
-
[60]
Frater, G. S. and Packer, J. A. Weldment design for RHS truss connections. I : Applications. J. Struct. Engrg
-
[61]
Frater, G. S. and Packer, J. A. Weldment design for RHS truss connections. II : Experimentation. J. Struct. Engrg
-
[62]
and Mittlebach, F
Goossens, M. and Mittlebach, F. and Samarin, A. The \ Companion
-
[63]
Transportation Research Part D , year =
Yue Huang and Roger Bird and Margaret Bell , title =. Transportation Research Part D , year =
-
[64]
Journal of Cleaner Production , year =
Yue Huang and Roger Bird and Oliver Hendrich , title =. Journal of Cleaner Production , year =
-
[65]
Uniform building code
-
[66]
Ireland, H. O. Stability analysis of C ongress S treet open cut in C hicago. G \' e otechnique
-
[67]
Kuhn, M. R. , title =. ascelike , year =
-
[68]
: A Document Prepartation System User's Guide and Reference Manual
Lamport, L. : A Document Prepartation System User's Guide and Reference Manual
-
[69]
Liggett, J. A. and Caughey, D. A. , title =. Fluid mechanics , year =
-
[70]
Lotus 1-2-3 reference manual; release 2.01
-
[71]
Theory of arches and suspension bridges
Melan, J. Theory of arches and suspension bridges
-
[72]
Moody's municipal & government manual
-
[73]
Pennoni, C. R. Visioning: the future of civil engineering. J. Profl. Issues in Engrg. Education and Practice
-
[74]
Das Vorspannen von Bewehrung auf Druck: Grundsaetzliches und Anwendungsmoeglichkeiten [prestressing of reinforcing in compression: fundamentals and application possibilities]
Reiffenstuhl, H. Das Vorspannen von Bewehrung auf Druck: Grundsaetzliches und Anwendungsmoeglichkeiten [prestressing of reinforcing in compression: fundamentals and application possibilities]. Beton-und Stahlbetonbau
-
[75]
Sotiropulos, S. N. Static response of bridge superstructures made of fiber reinforced plastic
-
[76]
Stahl, D. C. and Wolfe, R. W. and Begel, M. Improved analysis of timber rivet connections. J. Struct. Eng
-
[77]
Vesilind, P. A. Discussion of ` G uidance for engineering-design-class lectures on ethics,' by R ichard H . M c C uen. J. Profl. Issues in Engrg. Education and Practice
-
[78]
Zadeh, L. A. Possibility theory and soft data analysis. Mathematical frontiers of the social and policy sciences
-
[79]
Explicit accumulation model for non-cohesive soils under cyclic loading
Wichtmann, T. Explicit accumulation model for non-cohesive soils under cyclic loading
-
[80]
2024 IEEE International Conference on Machine Learning for Communication and Networking (ICMLCN) , pages=
Using large language models to understand telecom standards , author=. 2024 IEEE International Conference on Machine Learning for Communication and Networking (ICMLCN) , pages=. 2024 , organization=
2024
-
[81]
arXiv preprint arXiv:2309.10238 , year=
PolicyGPT: Automated analysis of privacy policies with large language models , author=. arXiv preprint arXiv:2309.10238 , year=
-
[82]
arXiv preprint arXiv:2310.08167 , year=
Multiclass classification of policy documents with large language models , author=. arXiv preprint arXiv:2310.08167 , year=
-
[83]
arXiv preprint arXiv:2402.01386 , year=
Can large language models serve as data analysts? A multi-agent assisted approach for qualitative data analysis , author=. arXiv preprint arXiv:2402.01386 , year=
-
[84]
arXiv preprint arXiv:2406.01768 , year=
Tspec-llm: An open-source dataset for llm understanding of 3gpp specifications , author=. arXiv preprint arXiv:2406.01768 , year=
-
[85]
2024 IEEE 24th International Conference on Software Quality, Reliability and Security (QRS) , pages=
Evaluating OpenAI Large Language Models for Generating Logical Abstractions of Technical Requirements Documents , author=. 2024 IEEE 24th International Conference on Software Quality, Reliability and Security (QRS) , pages=. 2024 , organization=
2024
-
[86]
arXiv preprint arXiv:2408.11775 , year=
Leveraging Fine-Tuned Retrieval-Augmented Generation with Long-Context Support: For 3GPP Standards , author=. arXiv preprint arXiv:2408.11775 , year=
-
[87]
arXiv preprint arXiv:2406.13558 , year=
Enhancing Travel Choice Modeling with Large Language Models: A Prompt-Learning Approach , author=. arXiv preprint arXiv:2406.13558 , year=
-
[88]
2016 , publisher=
Urban transportation planning in the United States: history, policy, and practice , author=. 2016 , publisher=
2016
-
[89]
Language Resources and Evaluation , volume=
Commonsense based text mining on urban policy , author=. Language Resources and Evaluation , volume=. 2023 , publisher=
2023
-
[90]
Proceedings of the 2003 annual research conference of the South African institute of computer scientists and information technologists on Enablement through technology , pages=
Differentiating data-and text-mining terminology , author=. Proceedings of the 2003 annual research conference of the South African institute of computer scientists and information technologists on Enablement through technology , pages=
2003
-
[91]
Nihon Hoshasen Gijutsu Gakkai Zasshi , volume=
Appling Text-mining to Extracting Technical Terms from Textbooks-Toward Updating the Terminology in the Field of Radiology Technology , author=. Nihon Hoshasen Gijutsu Gakkai Zasshi , volume=
-
[92]
Transactions of the Association for Computational Linguistics , volume=
Domain-targeted, high precision knowledge extraction , author=. Transactions of the Association for Computational Linguistics , volume=. 2017 , publisher=
2017
-
[93]
On the Move to Meaningful Internet Systems
Characterizing regulatory documents and guidelines based on text mining , author=. On the Move to Meaningful Internet Systems. OTM 2017 Conferences: Confederated International Conferences: CoopIS, C&TC, and ODBASE 2017, Rhodes, Greece, October 23-27, 2017, Proceedings, Part I , pages=. 2017 , organization=
2017
-
[94]
2013 21st IEEE International Requirements Engineering Conference (RE) , pages=
Automated text mining for requirements analysis of policy documents , author=. 2013 21st IEEE International Requirements Engineering Conference (RE) , pages=. 2013 , organization=
2013
-
[95]
Urban Studies , volume=
Analysing urban policy discourses using textometry: An application to French urban transport plans (2000--2015) , author=. Urban Studies , volume=. 2020 , publisher=
2000
-
[96]
2019 15th International Conference on Computational Intelligence and Security (CIS) , pages=
Policy text analysis based on text mining and fuzzy cognitive map , author=. 2019 15th International Conference on Computational Intelligence and Security (CIS) , pages=. 2019 , organization=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.