Using Text-Based Causal Inference to Disentangle Factors Influencing Online Review Ratings
Pith reviewed 2026-06-28 09:40 UTC · model grok-4.3
The pith
An enhanced CausalBERT model isolates the effects of correlated aspects mentioned in school reviews on overall ratings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
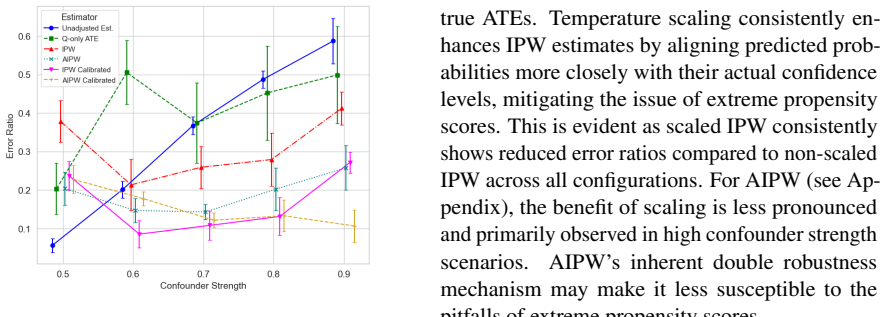
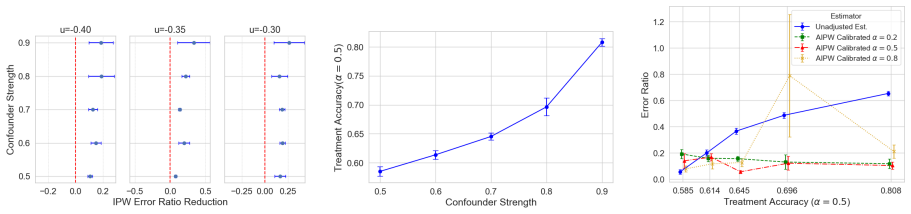
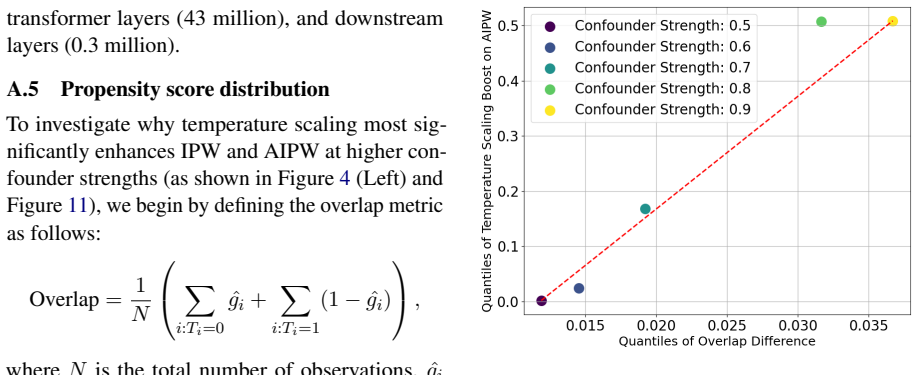
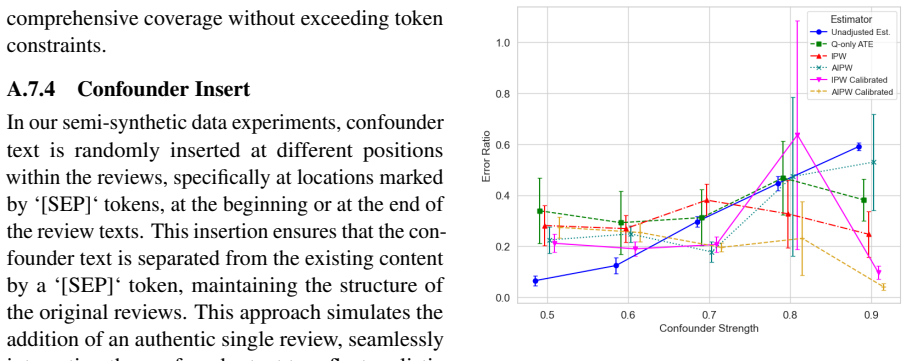
We enhance CausalBERT with temperature scaling for calibrated treatment assignment estimates, hyperparameter optimization to reduce confound overadjustment, and interpretability methods to characterize discovered confounds. Treating textual mentions in reviews as proxies for real-world attributes, we validate the approach on real and semi-synthetic data from over 600K reviews of U.S. K-12 schools. The enhancements produce more reliable estimates, and perception of school administration and performance on benchmarks emerge as significant drivers of overall school ratings.
What carries the argument
Enhanced CausalBERT that adds temperature scaling, hyperparameter optimization, and interpretability methods to perform causal disentanglement when textual mentions serve as proxies for attributes.
If this is right
- The method yields more reliable causal estimates than the unenhanced baseline on both real and semi-synthetic review data.
- Perception of school administration is a significant driver of overall school ratings.
- Performance on benchmarks is a significant driver of overall school ratings.
- The three enhancements together reduce calibration error and limit overadjustment for confounds in text-based causal settings.
Where Pith is reading between the lines
- The same proxy-and-causal pipeline could be tested on product or restaurant reviews where multiple correlated attributes are discussed.
- If the proxy assumption holds across domains, large observational review corpora become usable for answering causal questions that would otherwise require experiments.
- The added interpretability step may surface previously unnoticed confounds that affect rating models in other review platforms.
Load-bearing premise
Textual mentions in reviews serve as valid proxies for real-world attributes.
What would settle it
A controlled study that independently varies school administration quality and benchmark performance while measuring resulting changes in overall ratings; if the observational estimates from the enhanced model do not match the experimental effects, the central claim is falsified.
Figures




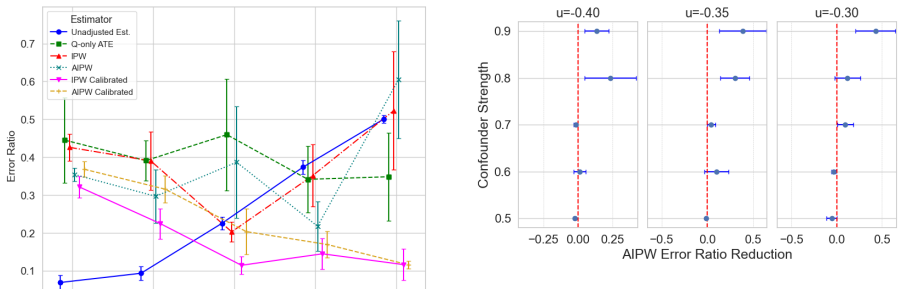
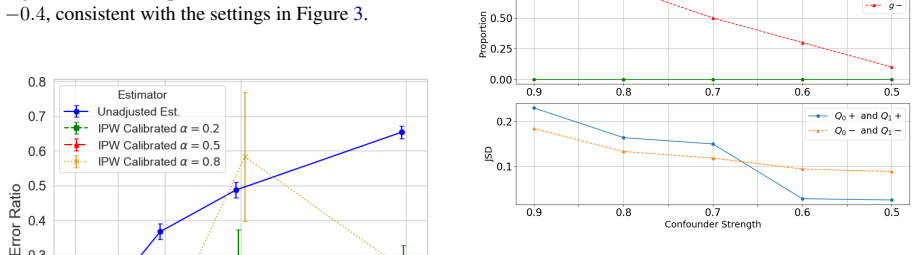
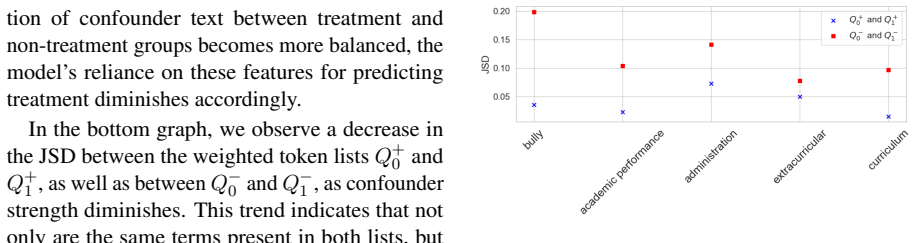
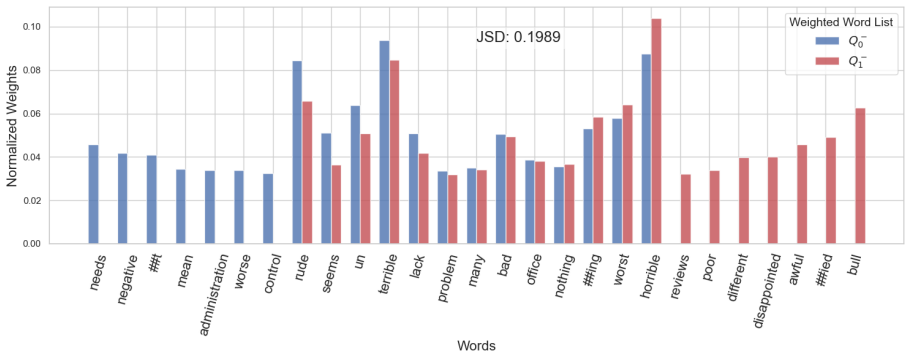
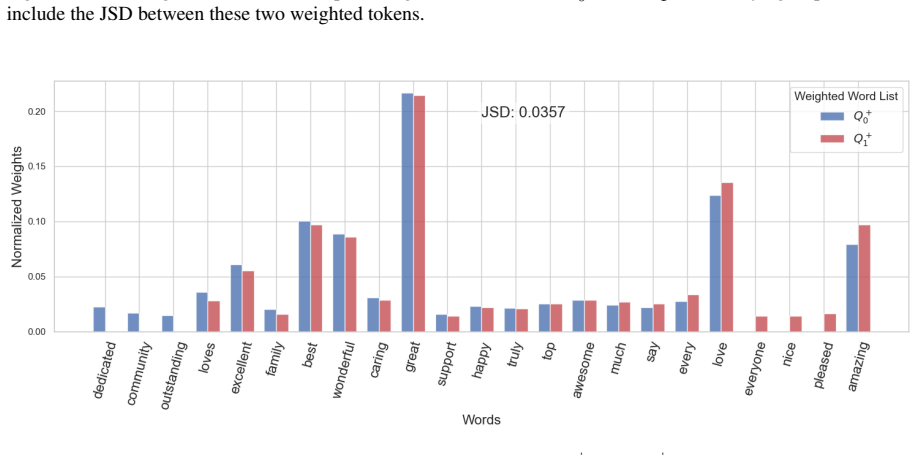
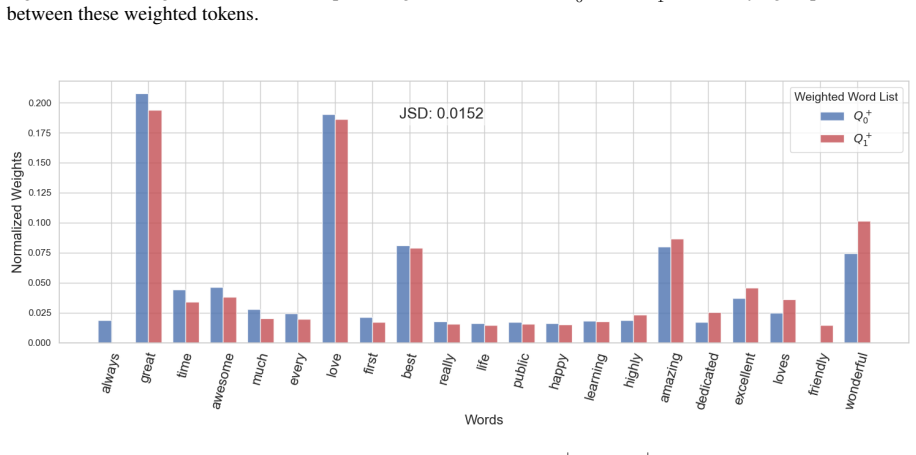
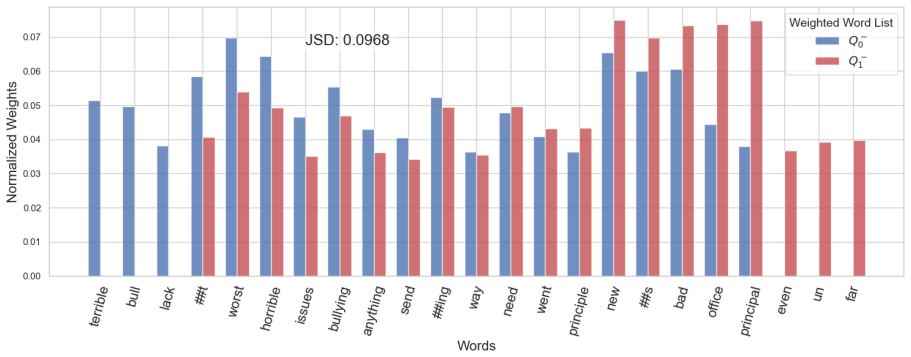
read the original abstract
Online reviews provide valuable insights into the perceived quality of facets of a product or service. While aspect-based sentiment analysis has focused on extracting these facets from reviews, there is less work understanding the impact of each aspect on overall perception. This is particularly challenging given correlations among aspects, making it difficult to isolate the effects of each. This paper introduces a methodology based on recent advances in text-based causal analysis, specifically CausalBERT, to disentangle the effect of each factor on overall review ratings. We enhance CausalBERT with three key improvements: temperature scaling for better calibrated treatment assignment estimates; hyperparameter optimization to reduce confound overadjustment; and interpretability methods to characterize discovered confounds. In this work, we treat the textual mentions in reviews as proxies for real-world attributes. We validate our approach on real and semi-synthetic data from over 600K reviews of U.S. K-12 schools. We find that the proposed enhancements result in more reliable estimates, and that perception of school administration and performance on benchmarks are significant drivers of overall school ratings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the CausalBERT framework with three enhancements—temperature scaling for calibrated treatment estimates, hyperparameter optimization to mitigate confound overadjustment, and interpretability tools for discovered confounds—to perform text-based causal inference that isolates the effects of individual aspects on overall review ratings. Treating textual mentions in reviews as proxies for real-world attributes, the approach is validated on real and semi-synthetic data drawn from over 600K U.S. K-12 school reviews; the authors report that the enhancements yield more reliable estimates and that perceptions of school administration and benchmark performance are significant drivers of ratings.
Significance. If the proxy assumption and causal identification hold, the work strengthens text-based causal methods by addressing calibration and overadjustment issues in high-dimensional text settings and supplies a scalable approach for disentangling correlated aspects in large review corpora. The combination of real-world scale and semi-synthetic validation provides concrete evidence of improved reliability, which could support applications in opinion mining and policy analysis.
major comments (2)
- [Abstract] Abstract: The headline claim that administration perception and benchmark performance are significant drivers of ratings rests on the explicit modeling choice to treat textual mentions as faithful proxies for the underlying attributes. No external validation of this proxy (e.g., correlation with administrative records or benchmark scores), sensitivity analysis for measurement error, selection into mentioning, or reverse causation from overall rating is reported, rendering the substantive interpretation of the recovered effects unsupported.
- [Validation and results sections] Validation and results sections: The reported improvements from the three CausalBERT enhancements are assessed only under the maintained proxy assumption; because the enhancements target estimation mechanics rather than proxy validity, any bias or noise in the mention-to-attribute mapping remains unquantified and directly affects the driver conclusions.
minor comments (2)
- [Results section] Results section: Estimated effects lack reported standard errors, confidence intervals, or robustness checks across different hyperparameter settings; inclusion of these would strengthen assessment of reliability.
- [Abstract and methodology] Abstract and methodology: The semi-synthetic data generation process and exclusion criteria for the 600K reviews are not fully detailed, limiting reproducibility of the validation experiments.
Simulated Author's Rebuttal
We thank the referee for highlighting the central role of the proxy assumption. We respond to each major comment below and will revise the manuscript to clarify assumptions, qualify claims, and add a dedicated limitations discussion. The work focuses on methodological enhancements under the stated modeling choice.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that administration perception and benchmark performance are significant drivers of ratings rests on the explicit modeling choice to treat textual mentions as faithful proxies for the underlying attributes. No external validation of this proxy (e.g., correlation with administrative records or benchmark scores), sensitivity analysis for measurement error, selection into mentioning, or reverse causation from overall rating is reported, rendering the substantive interpretation of the recovered effects unsupported.
Authors: We agree the substantive interpretation depends on the proxy assumption, which the manuscript states explicitly. Semi-synthetic validation tests the method where the proxy holds by construction, but no external validation, sensitivity for measurement error, selection, or reverse causation is performed. This is a limitation. In revision we will qualify the abstract claims as conditional on the assumption, add a limitations subsection discussing these issues, and include feasible sensitivity checks such as varying mention thresholds. revision: yes
-
Referee: [Validation and results sections] Validation and results sections: The reported improvements from the three CausalBERT enhancements are assessed only under the maintained proxy assumption; because the enhancements target estimation mechanics rather than proxy validity, any bias or noise in the mention-to-attribute mapping remains unquantified and directly affects the driver conclusions.
Authors: We concur that the enhancements improve estimation mechanics under the proxy assumption and do not address proxy validity. Validation quantifies gains conditional on that assumption. We will revise the validation and results sections to state explicitly that improvements and driver conclusions hold under the maintained proxy, with cross-reference to the new limitations discussion. revision: yes
- External validation of the proxy (correlation with administrative records or benchmark scores) cannot be performed without new data sources unavailable to the current study.
Circularity Check
Minor self-citation in CausalBERT extension; derivation remains independent via external validation
full rationale
The paper extends the existing CausalBERT framework by adding three enhancements (temperature scaling, hyperparameter optimization against overadjustment, and confound interpretability) and validates on external real and semi-synthetic data from over 600K school reviews. It explicitly states the proxy assumption for textual mentions rather than deriving it. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citation chains appear in the provided text or abstract. The central claims about drivers of ratings rest on the applied causal method and data rather than reducing to the paper's own fitted parameters by construction. This warrants a low score of 2 for a non-load-bearing self-citation at most.
Axiom & Free-Parameter Ledger
free parameters (2)
- temperature scaling parameter
- hyperparameters for confound adjustment
axioms (2)
- domain assumption Textual mentions in reviews serve as valid proxies for real-world attributes
- domain assumption Causal inference assumptions hold after the proposed adjustments (no unmeasured confounding)
Reference graph
Works this paper leans on
-
[1]
Causal Effects of Linguistic Properties , url =
Pryzant, Reid and Card, Dallas and Jurafsky, Dan and Veitch, Victor and Sridhar, Dhanya , booktitle =. Causal Effects of Linguistic Properties , url =
-
[2]
Essay on principles , author=
On the application of probability theory to agricultural experiments. Essay on principles , author=. Ann. Agricultural Sciences , pages=
-
[3]
Conference on uncertainty in artificial intelligence , pages=
Adapting text embeddings for causal inference , author=. Conference on uncertainty in artificial intelligence , pages=. 2020 , organization=
2020
-
[4]
Proceedings of the international AAAI conference on web and social media , volume=
Adjusting for confounders with text: Challenges and an empirical evaluation framework for causal inference , author=. Proceedings of the international AAAI conference on web and social media , volume=
-
[5]
arXiv preprint arXiv:1810.04805 , year=
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. arXiv preprint arXiv:1810.04805 , year=
-
[6]
Journal of the american statistical association , volume=
Analysis of semiparametric regression models for repeated outcomes in the presence of missing data , author=. Journal of the american statistical association , volume=. 1995 , publisher=
1995
-
[7]
Statistics in medicine , volume=
Moving towards best practice when using inverse probability of treatment weighting (IPTW) using the propensity score to estimate causal treatment effects in observational studies , author=. Statistics in medicine , volume=. 2015 , publisher=
2015
-
[8]
Health Services and Outcomes Research Methodology , volume=
Using propensity scores to help design observational studies: application to the tobacco litigation , author=. Health Services and Outcomes Research Methodology , volume=. 2001 , publisher=
2001
-
[9]
Advances in neural information processing systems , volume=
Adapting neural networks for the estimation of treatment effects , author=. Advances in neural information processing systems , volume=
-
[10]
International conference on machine learning , pages=
On calibration of modern neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[11]
Annals of statistics , pages=
Greedy function approximation: a gradient boosting machine , author=. Annals of statistics , pages=. 2001 , publisher=
2001
-
[12]
International conference on machine learning , pages=
Axiomatic attribution for deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[13]
arXiv preprint arXiv:1910.01108 , year=
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter , author=. arXiv preprint arXiv:1910.01108 , year=
Pith/arXiv arXiv 1910
-
[14]
Proceedings of the international multiconference of engineers and computer scientists , volume=
Using of Jaccard coefficient for keywords similarity , author=. Proceedings of the international multiconference of engineers and computer scientists , volume=
-
[15]
Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
Mining and summarizing customer reviews , author=. Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
-
[16]
Document Modeling with Gated Recurrent Neural Network for Sentiment Classification
Tang, Duyu and Qin, Bing and Liu, Ting. Document Modeling with Gated Recurrent Neural Network for Sentiment Classification. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 2015. doi:10.18653/v1/D15-1167
-
[17]
A Hierarchical Model of Reviews for Aspect-based Sentiment Analysis
Ruder, Sebastian and Ghaffari, Parsa and Breslin, John G. A Hierarchical Model of Reviews for Aspect-based Sentiment Analysis. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1103
-
[18]
American Journal of Political Science , volume=
Adjusting for confounding with text matching , author=. American Journal of Political Science , volume=. 2020 , publisher=
2020
-
[19]
arXiv preprint arXiv:1906.04177 , year=
Estimating causal effects of tone in online debates , author=. arXiv preprint arXiv:1906.04177 , year=
Pith/arXiv arXiv 1906
-
[20]
Political Analysis , volume=
Matching with text data: An experimental evaluation of methods for matching documents and of measuring match quality , author=. Political Analysis , volume=. 2020 , publisher=
2020
-
[21]
Anesthesia & analgesia , volume=
Correlation coefficients: appropriate use and interpretation , author=. Anesthesia & analgesia , volume=. 2018 , publisher=
2018
-
[22]
arXiv preprint arXiv:2005.00649 , year=
Text and causal inference: A review of using text to remove confounding from causal estimates , author=. arXiv preprint arXiv:2005.00649 , year=
arXiv 2005
-
[23]
Computational Linguistics , volume=
Causalm: Causal model explanation through counterfactual language models , author=. Computational Linguistics , volume=. 2021 , publisher=
2021
-
[24]
arXiv preprint arXiv:2307.15176 , year=
RCT rejection sampling for causal estimation evaluation , author=. arXiv preprint arXiv:2307.15176 , year=
-
[25]
M.L. Menéndez and J.A. Pardo and L. Pardo and M.C. Pardo , abstract =. The Jensen-Shannon divergence , journal =. 1997 , issn =. doi:https://doi.org/10.1016/S0016-0032(96)00063-4 , url =
-
[26]
IEEE Transactions on Knowledge and Data Engineering , volume=
A survey on aspect-based sentiment analysis: Tasks, methods, and challenges , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2022 , publisher=
2022
-
[27]
Knowledge and Information Systems , pages=
Exploring aspect-based sentiment analysis: an in-depth review of current methods and prospects for advancement , author=. Knowledge and Information Systems , pages=. 2024 , publisher=
2024
-
[28]
Tourism Management , volume=
Relationship between customer sentiment and online customer ratings for hotels-An empirical analysis , author=. Tourism Management , volume=. 2017 , publisher=
2017
-
[29]
Harris and Debbie Kim and Nicholas Mattei and Srihari Korrapati and Olivia Carr , booktitle=
Douglas N. Harris and Debbie Kim and Nicholas Mattei and Srihari Korrapati and Olivia Carr , booktitle=. A Picture Is Worth 51,930,274 Words:
-
[30]
arXiv preprint arXiv:1906.04341 , year=
What does bert look at? an analysis of bert's attention , author=. arXiv preprint arXiv:1906.04341 , year=
Pith/arXiv arXiv 1906
-
[31]
Proceedings of the 30th IEEE/ACM International Conference on Program Comprehension , pages=
An exploratory study on code attention in BERT , author=. Proceedings of the 30th IEEE/ACM International Conference on Program Comprehension , pages=
-
[32]
2021 , publisher=
Regression and other stories , author=. 2021 , publisher=
2021
-
[33]
Epidemiology , volume=
On the relative nature of overadjustment and unnecessary adjustment , author=. Epidemiology , volume=. 2009 , publisher=
2009
-
[34]
AERA Open , volume=
Parents’ online school reviews reflect several racial and socioeconomic disparities in K--12 education , author=. AERA Open , volume=. 2021 , publisher=
2021
-
[35]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
DoubleLingo: Causal Estimation with Large Language Models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.