GeoNatureAgent Benchmark: Benchmarking LLM Agents for Environmental Geospatial Analysis Across Frontier and Open-Weight Foundation Models
Pith reviewed 2026-06-27 07:16 UTC · model grok-4.3
The pith
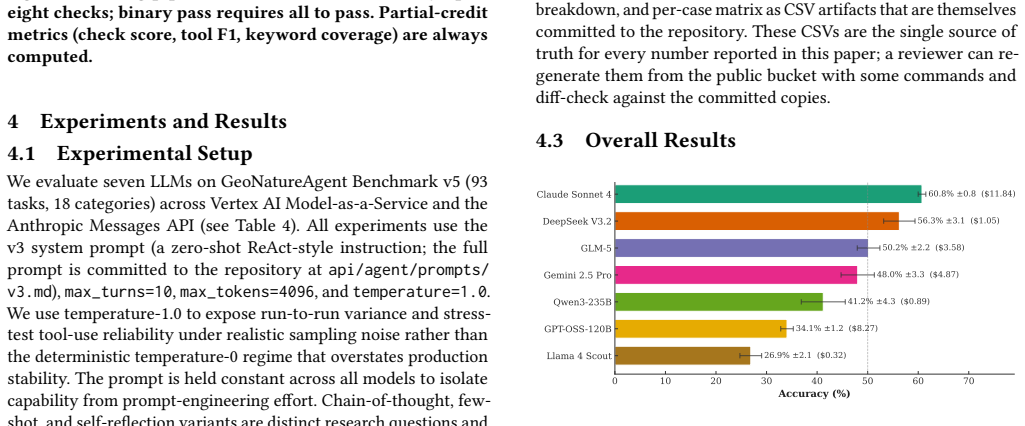
Claude Sonnet 4 reaches 60.8% success on the first benchmark of LLM agents using real geospatial APIs, while all models score 0% on close-value comparisons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
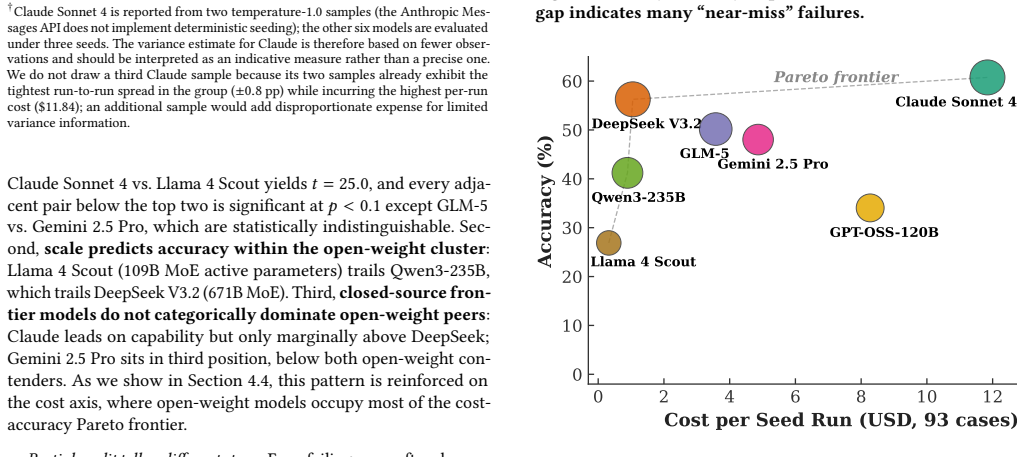
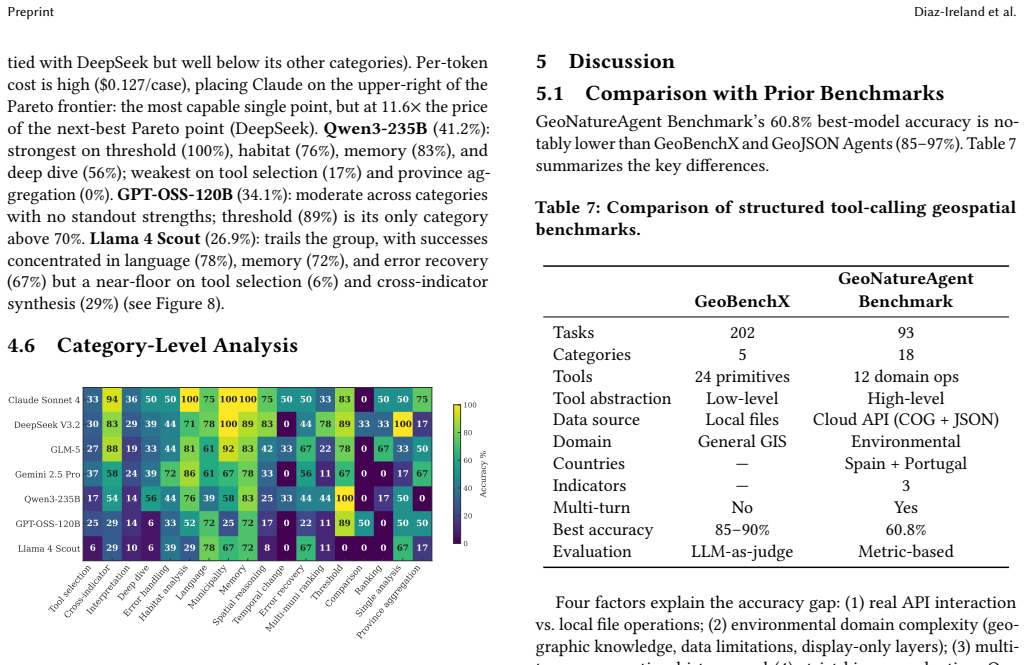
The GeoNatureAgent Benchmark shows that current LLM agents operating through structured tool calls against a real environmental API achieve at most 60.8 percent success across 93 tasks, with open-weight models occupying most of the cost-accuracy frontier and every model failing entirely on close-value comparison problems.
What carries the argument
A 93-task benchmark that drives agents through sixteen production tools against a self-hostable API serving CO2, erosion, and land-cover indicators across Spain and Portugal.
If this is right
- Open-weight models can deliver 93 percent of the top model's accuracy at roughly one-eleventh the cost per task.
- Comparison and ranking tasks that involve near-identical values remain unsolved by all current agents.
- Structured tool calling on a real API produces lower and more differentiated scores than general-purpose GIS benchmarks.
- The benchmark framework can be extended by adding new indicator layers without changing the task or evaluation design.
Where Pith is reading between the lines
- Specialized numerical-comparison modules may be required before agents can handle the ranking and difference tasks that currently block all models.
- Environmental analysis pipelines could combine LLM agents with separate deterministic comparison tools to bypass the observed zero-success regime.
- Lower-cost open models become practical for routine municipal and habitat queries once the hardest comparison cases are routed elsewhere.
- The performance gap between real-API tool use and synthetic benchmarks suggests that future agent training should prioritize production-style error handling and multi-turn recovery.
Load-bearing premise
The 93 tasks and sixteen tools accurately represent the data-wrangling and analysis challenges that environmental scientists actually face.
What would settle it
An agent that scores above 50 percent on the close-value comparison subset or that maintains high success when the same tasks are replaced by logs of actual scientist workflows.
Figures



read the original abstract
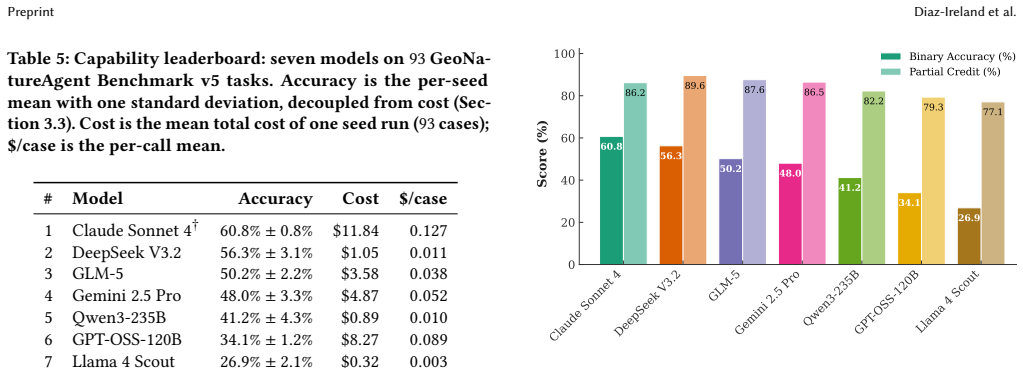
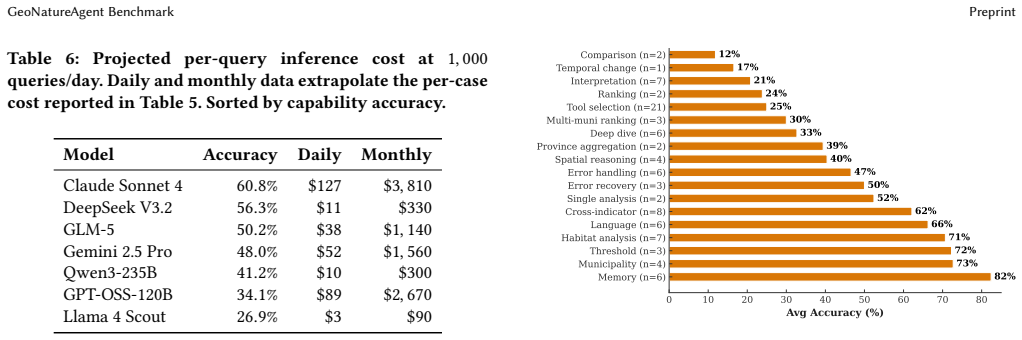
Environmental scientists spend disproportionate effort on data wrangling rather than analysis, and AI agents that automate geospatial workflows remain unvalidated: no benchmark evaluates agents operating through structured tool calling against real APIs. We introduce the GeoNatureAgent Benchmark, the first benchmark for environmental analysis agents that operate via structured tool calls to a production-style geospatial API. It comprises 93 tasks across 18 categories, covering municipality analysis, multi-turn conversation, spatial reasoning, cross-indicator synthesis, error handling and recovery, ranking, comparison, multilingual understanding, habitat analysis, and task rejection. Tasks are evaluated against an open, self-hostable API serving three environmental indicators across Spain and Portugal via sixteen tools. We evaluate seven LLMs (Claude Sonnet 4, DeepSeek V3.2, GLM-5, Gemini 2.5 Pro, Qwen3-235B, GPT-OSS-120B, Llama 4 Scout) under three temperature-1.0 seeds, reporting capability and per-case cost as orthogonal axes. We find: (1) Claude Sonnet 4 leads at 60.8% +/- 0.8%, followed by DeepSeek V3.2 at 56.3% +/- 3.1%, with no other model above 51%; (2) the cost-accuracy Pareto frontier is occupied mostly by open-weight models, with DeepSeek V3.2 offering 93% of Claude's capability at 11x lower cost ($0.011/case); (3) comparison tasks remain universally unsolved (0% on close-value comparisons), exposing systematic reasoning limits; and (4) structured tool calling against a real API is more discriminative than general-purpose GIS benchmarks, with accuracies 25-35 points lower. We further show extensibility by integrating BigEarthNet V2 land cover for Portugal alongside Spanish CO2 and erosion indicators. The benchmark, harness, and self-hostable API are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the GeoNatureAgent Benchmark, the first benchmark for LLM agents performing environmental geospatial analysis via structured tool calls to a production-style API serving three indicators across Spain and Portugal. It comprises 93 tasks across 18 categories (municipality analysis, multi-turn conversation, spatial reasoning, cross-indicator synthesis, error handling, ranking, comparison, multilingual understanding, habitat analysis, task rejection) and evaluates seven models (Claude Sonnet 4, DeepSeek V3.2, GLM-5, Gemini 2.5 Pro, Qwen3-235B, GPT-OSS-120B, Llama 4 Scout) over three temperature-1.0 seeds. Key findings include Claude Sonnet 4 at 60.8% ± 0.8% success, DeepSeek V3.2 at 56.3% ± 3.1% (11x lower cost), no other model above 51%, universal 0% on close-value comparisons, and the claim that the benchmark is 25-35 points more discriminative than general GIS benchmarks. The benchmark, harness, and self-hostable API are released publicly, with an extensibility demonstration using BigEarthNet V2.
Significance. If the task set and API faithfully represent real environmental workflows, the work supplies a reproducible, domain-specific benchmark that isolates systematic LLM limitations (especially in comparison reasoning) and demonstrates cost-accuracy trade-offs favoring open-weight models. The public release of the benchmark, harness, and API is a concrete strength that enables community follow-up and extensibility experiments.
major comments (2)
- [Benchmark construction] Benchmark construction section: No description is given of how the 93 tasks were selected, whether they underwent expert review by environmental scientists, or how their distribution (e.g., municipality analysis, error recovery) was validated against published case studies or logged workflows; this directly undermines the central claim that the benchmark 'faithfully capture[s] the data-wrangling and analysis challenges environmental scientists actually face' and that it is more discriminative than general GIS benchmarks.
- [Evaluation methodology] Evaluation methodology: The manuscript supplies no details on ground-truthing of API responses, precise success criteria for multi-turn or error-recovery tasks, or controls for selection bias in the 93-task set; without these, the headline percentages (Claude Sonnet 4 at 60.8% ± 0.8%, 0% on close-value comparisons) cannot be confidently interpreted as measures of agent capability.
minor comments (2)
- [Results] Clarify whether the three seeds were run for every model or only a subset, and report per-model variance consistently.
- [Discussion] The abstract states 'structured tool calling against a real API is more discriminative... with accuracies 25-35 points lower'; ensure the main text supplies the exact baseline benchmark, models, and task overlap used for this comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on benchmark construction and evaluation methodology. We agree that the manuscript would benefit from expanded details in these areas to better support our claims of faithful representation of environmental workflows and reliable performance metrics. We will revise accordingly.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: No description is given of how the 93 tasks were selected, whether they underwent expert review by environmental scientists, or how their distribution (e.g., municipality analysis, error recovery) was validated against published case studies or logged workflows; this directly undermines the central claim that the benchmark 'faithfully capture[s] the data-wrangling and analysis challenges environmental scientists actually face' and that it is more discriminative than general GIS benchmarks.
Authors: We acknowledge the omission in the current manuscript. In the revision we will add a new subsection under Benchmark Construction that describes the task selection process: the 93 tasks were derived from representative environmental geospatial workflows documented in peer-reviewed literature on ecological indicator analysis and remote sensing applications across the Iberian Peninsula; the author team (which includes environmental scientists) performed internal expert review for ecological plausibility and category balance; and category distribution was cross-checked against common analysis patterns in published case studies. This addition will directly support the claim of faithful capture and explain the observed discriminativeness relative to general GIS benchmarks. revision: yes
-
Referee: [Evaluation methodology] Evaluation methodology: The manuscript supplies no details on ground-truthing of API responses, precise success criteria for multi-turn or error-recovery tasks, or controls for selection bias in the 93-task set; without these, the headline percentages (Claude Sonnet 4 at 60.8% ± 0.8%, 0% on close-value comparisons) cannot be confidently interpreted as measures of agent capability.
Authors: We agree these details are required for confident interpretation. The revised manuscript will expand the Evaluation Methodology section to specify: ground-truth responses were generated by executing each task against the self-hostable API with manually verified correct outputs; success criteria are defined per category (e.g., for multi-turn tasks, all required tool calls must be issued correctly and the final synthesized answer must match the ground truth within tolerance; for error-recovery, the agent must issue a valid corrective tool call without fabricating data); and selection bias was mitigated by exhaustive category coverage with uniform sampling within categories. These clarifications will enable readers to interpret the reported accuracies, including the 0% on close-value comparisons, as reliable measures of agent capability. revision: yes
Circularity Check
No circularity: results are direct empirical measurements on fixed external tasks and API
full rationale
The paper defines a benchmark of 93 tasks and 16 tools against a production-style API, then reports measured success rates (e.g., Claude Sonnet 4 at 60.8%) for seven LLMs. No equations, fitted parameters, predictions, or derivations exist that could reduce to inputs by construction. No self-citations are invoked as load-bearing premises for uniqueness or ansatzes. All claims rest on direct evaluation against the stated task set and API, making the work self-contained and non-circular by the enumerated criteria.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Success rate on a fixed task set with multiple temperature-1.0 seeds provides a stable measure of agent capability.
Reference graph
Works this paper leans on
-
[1]
Temitope Akinboyewa, Zhenlong Li, Huan Ning, and M. Naser Lessani. 2025. GIS Copilot: Towards an Autonomous GIS Agent for Spatial Analysis. International Journal of Digital Earth 18, 1 (2025), 2497489. doi:10.1080/17538947.2025.2497489 2https://github.com/gabrielireland/GeoNatureAgent_Benchmark Preprint Diaz-Ireland et al
-
[2]
Feenstra, Conner Arnold, Jan DeWitt, Natalie C
Christian Michael Arnold, Andrew Alini, Jonathan Wang, Pieter M. Feenstra, Conner Arnold, Jan DeWitt, Natalie C. Ritsema, Jung Hyun Yae, Gary C. Bor- chardt, Boris Katz, Andrei Barbu, and Brian Cheung. 2026. MapQA: A Map- Question-Answering Benchmark for Visual Language Model Reasoning. https: //openreview.net/forum?id=dOISCbmkmG
2026
-
[3]
Rishi Bommasani, Percy Liang, and Tony Lee. 2023. Holistic Evaluation of Language Models. Annals of the New York Academy of Sciences 1525, 1 (2023), 140–
2023
-
[4]
arXiv:https://nyaspubs.onlinelibrary.wiley.com/doi/pdf/10.1111/nyas.15007 doi:10.1111/nyas.15007
-
[5]
Kai Norman Clasen, Leonard Hackel, Tom Burgert, Gencer Sumbul, Begüm Demir, and Volker Markl. 2025. reBen: Refined BigEarthNet Dataset for Remote Sensing Image Analysis. In IGARSS 2025 – 2025 IEEE International Geoscience and Remote Sensing Symposium. 1264–1268. doi:10.1109/IGARSS55030.2025.11242834
-
[6]
Gabriel Diaz-Ireland, Diego Prieto-Herráez, Mario García Peces, Javier Velázquez, and Devika Jain. 2026. GeoNatureAgent Benchmark — Dataset (tasks, results, derived environmental indicators). doi:10.5281/zenodo.20450995 Concept DOI; resolves to the latest version
-
[7]
Gabriel Diaz-Ireland, Diego Prieto-Herráez, Mario García Peces, Javier Velázquez, and Devika Jain. 2026. GeoNatureAgent Benchmark — Evaluation Harness, Agent and Self-Hostable Geospatial API. doi:10.5281/zenodo.20450997 Concept DOI; resolves to the latest version
-
[8]
Mahir Labib Dihan, Md Tanvir Hassan, Md Tanvir Parvez, Md Hasebul Hasan, Md Almash Alam, Muhammad Aamir Cheema, Mohammed Eunus Ali, and Md Rizwan Parvez. 2025. MapEval: A Map-Based Evaluation of Geo-Spatial Reasoning in Foundation Models. In Proceedings of the 42nd International Confer- ence on Machine Learning (Vancouver, Canada) (ICML’25). JMLR.org, Art...
2025
-
[9]
Google Research. 2025. Google Earth AI: Unlocking Geospatial Insights with Foundation Models and Cross-Modal Reasoning. Google Research Blog. https://research.google/blog/google-earth-ai-unlocking-geospatial- insights-with-foundation-models-and-cross-modal-reasoning/
2025
-
[10]
Yu Huang, Liang Guo, Wanqian Guo, Zhe Tao, Yang Lv, Zhihao Sun, and Dongfang Zhao. 2024. EnviroExam: Benchmarking Environmental Science Knowledge of Large Language Models. arXiv:2405.11265 [cs.CL] doi:10.48550/arXiv.2405.11265
-
[11]
Chia Hsiang Kao, Wenting Zhao, Shreelekha Revankar, Samuel Speas, Snehal Bhagat, Rajeev Datta, Cheng Perng Phoo, Utkarsh Mall, Carl Vondrick, Kavita Bala, and Bharath Hariharan. 2025. Towards LLM Agents for Earth Observation. arXiv:2504.12110 [cs.AI] doi:10.48550/arXiv.2504.12110
-
[12]
Kingdom of Spain. 2025. Real Decreto 214/2025 on the Regulation of the Carbon Footprint Register. Boletín Oficial del Estado. https://www.boe.es/buscar/doc. php?id=BOE-A-2025-7439
2025
-
[13]
Varvara Krechetova and Denis Kochedykov. 2025. GeoBenchX: Benchmarking LLMs in Agent Solving Multistep Geospatial Tasks. In Proceedings of the 1st ACM SIGSPATIAL International Workshop on Generative and Agentic AI for Multi- Modality Space-Time Intelligence (GeoGenAgent ’25). Association for Computing Machinery, New York, NY, USA, 27–35. doi:10.1145/37649...
-
[14]
Alexandre Lacoste, Nils Lehmann, Pau Rodriguez, Evan David Sherwin, Hannah Kerner, Björn Lütjens, Jeremy Irvin, David Dao, Hamed Alemohammad, Alexan- dre Drouin, Mehmet Gunturkun, Gabriel Huang, David Vazquez, Dava Newman, Yoshua Bengio, Stefano Ermon, and Xiao Xiang Zhu. 2023. GEO-Bench: Toward Foundation Models for Earth Monitoring. In Proceedings of th...
2023
-
[15]
Chaehong Lee, Varatheepan Paramanayakam, Andreas Karatzas, Yanan Jian, Michael Fore, Heming Liao, Fuxun Yu, Ruopu Li, Iraklis Anagnostopoulos, and Dimitrios Stamoulis. 2025. Multi-Agent Geospatial Copilots for Remote Sensing Workflows. In IGARSS 2025 – 2025 IEEE International Geoscience and Remote Sensing Symposium. 1084–1089. doi:10.1109/IGARSS55030.2025...
-
[16]
Zhenlong Li and Huan Ning. 2023. Autonomous GIS: The Next-Generation AI-Powered GIS. International Journal of Digital Earth 16, 2 (2023), 4668–4686. doi:10.1080/17538947.2023.2278895
-
[17]
Qianqian Luo, Qingming Lin, Liuchang Xu, Sensen Wu, Ruichen Mao, Chao Wang, Hailin Feng, Bo Huang, and Zhenhong Du. 2026. GeoJSON Agents: A Multi-Agent LLM Architecture for Geospatial Analysis—Function Calling vs. Code Generation. Big Earth Data 0, 0 (2026), 1–55. doi:10.1080/20964471.2026.2615511
-
[18]
Valerio Marsocci, Yuru Jia, Georges Le Bellier, David Kerekes, Liang Zeng, Se- bastian Hafner, Sebastian Gerard, Eric Brune, Ritu Yadav, Ali Shibli, Heng Fang, Yifang Ban, Maarten Vergauwen, Nicolas Audebert, and Andrea Nascetti. 2025. PANGAEA: A Global and Inclusive Benchmark for Geospatial Foundation Models. arXiv:2412.04204 [cs.CV] doi:10.48550/arXiv.2...
-
[19]
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2024. GAIA: a benchmark for General AI Assistants. In The Twelfth International Conference on Learning Representations . https://openreview.net/ forum?id=fibxvahvs3
2024
-
[20]
Yu-Erh Pan and Ayesha Siddika Nipu. 2025. LLM-Enhanced Air Quality Monitor- ing Interface via Model Context Protocol. In 2025 7th International Symposium on Advanced Electrical and Communication Technologies (ISAECT) . IEEE, 1–6. doi:10.1109/ISAECT68904.2025.11318775
-
[21]
Planet Labs and Anthropic. 2025. Planet and Anthropic Partner to Use Claude’s Advanced AI Capabilities to Turn Geospatial Satellite Imagery into Actionable Insights. BusinessWire. https://www.businesswire.com/news/home/ 20250306606139/en/Planet-and-Anthropic-Partner-to-Use-Claudes-Advanced- AI-Capabilities-to-Turn-Geospatial-Satellite-Imagery-into-Actiona...
2025
-
[22]
Akashah Shabbir, Muhammad Akhtar Munir, Akshay Dudhane, Muham- mad Umer Sheikh, Muhammad Haris Khan, Paolo Fraccaro, Juan Bernabe Moreno, Fahad Shahbaz Khan, and Salman Khan. 2026. ThinkGeo: Evaluat- ing Tool-Augmented Agents for Remote Sensing Tasks. arXiv:2505.23752 [cs.CV] doi:10.48550/arXiv.2505.23752
-
[23]
Naomi Simumba, Nils Lehmann, Paolo Fraccaro, Hamed Alemohammad, Geeth De Mel, Salman Khan, Manil Maskey, Nicolas Longepe, Xiao Xiang Zhu, Hannah Kerner, Juan Bernabe-Moreno, and Alexandre Lacoste. 2026. GEO- Bench-2: From Performance to Capability, Rethinking Evaluation in Geospatial AI. arXiv:2511.15658 [cs.CV] doi:10.48550/arXiv.2511.15658
-
[24]
Dimitrios Stamoulis and Diana Marculescu. 2025. Geo-OLM: Enabling Sustainable Earth Observation Studies with Cost-Efficient Open Language Models and State- Driven Workflows. InProceedings of the 2025 ACM SIGCAS/SIGCHI Conference on Computing and Sustainable Societies (COMPASS ’25). Association for Computing Machinery, New York, NY, USA, 608–619. doi:10.11...
-
[25]
Daniela Szwarcman, Sujit Roy, Paolo Fraccaro, Thorsteinn Elí Gíslason, Benedikt Blumenstiel, Rinki Ghosal, Pedro Henrique de Oliveira, Joao Lucas de Sousa Almeida, Rocco Sedona, Yanghui Kang, Srija Chakraborty, Sizhe Wang, Carlos Gomes, Ankur Kumar, Vishal Gaur, Myscon Truong, Denys Godwin, Sam Khallaghi, Hyunho Lee, Chia-Yu Hsu, Ata Akbari Asanjan, Besar...
-
[26]
Thinh Hung Truong, Jey Han Lau, and Jianzhong Qi. 2026. GPSBench: Do Large Language Models Understand GPS Coordinates? arXiv:2602.16105 [cs.AI] doi:10.48550/arXiv.2602.16105
-
[27]
Iqramul Hoque, Shahriyar Zaman Ridoy, Mo- hammed Eunus Ali, Majd Hawasly, Mohammad Raza, and Md Rizwan Parvez
Azmine Toushik Wasi, Wahid Faisal, Abdur Rahman, Mahfuz Ahmed Anik, Munem Shahriar, Mohsin Mahmud Topu, Sadia Tasnim Meem, Rahatun Nesa Priti, Sabrina Afroz Mitu, Md. Iqramul Hoque, Shahriyar Zaman Ridoy, Mo- hammed Eunus Ali, Majd Hawasly, Mohammad Raza, and Md Rizwan Parvez
-
[28]
SpatiaLab: Can Vision-Language Models Perform Spatial Reasoning in the Wild? arXiv:2602.03916 [cs.CV] doi:10.48550/arXiv.2602.03916
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.03916
-
[29]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Mod- els. In Proceedings of the 11th International Conference on Learning Representations, ICLR 2023. doi:10.48550/arXiv.2210.03629
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.03629 2023
-
[30]
Yifan Zhang, Jingxuan Li, Zhiyun Wang, Zhengting He, Qingfeng Guan, Jianfeng Lin, and Wenhao Yu. 2025. Geospatial Large Language Model Trained with a Simulated Environment for Generating Tool-Use Chains Autonomously. Interna- tional Journal of Applied Earth Observation and Geoinformation 136 (2025), 104312. doi:10.1016/j.jag.2024.104312
-
[31]
Yuanxin Zhang, Sijie Lin, Yaxin Xiong, Nan Li, Lijin Zhong, Longzhen Ding, and Qing Hu. 2025. Fine-Tuning Large Language Models for Interdisciplinary Environmental Challenges. Environmental Science and Ecotechnology 27 (2025), 100608. doi:10.1016/j.ese.2025.100608
-
[32]
Yifan Zhang, Cheng Wei, Zhengting He, and Wenhao Yu. 2024. GeoGPT: An Assistant for Understanding and Processing Geospatial Tasks. International Journal of Applied Earth Observation and Geoinformation 131 (2024), 103976. doi:10.1016/j.jag.2024.103976 A Online Resources The GeoNatureAgent Benchmark code, evaluation harness, and self-hostable API are availa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.