Neural Texture Compression using Hypernetworks
Pith reviewed 2026-06-26 01:35 UTC · model grok-4.3
The pith
A single hypernetwork generates both latent features and MLP decoder weights for neural texture compression without per-material optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A single hypernetwork trained across materials outputs both the latent features and the MLP's weights and biases for a given material. Though the solution space is high-dimensional, this produces results comparable in quality to the current reference neural texture compressors that optimize separately per material. The same hypernetwork can be extended to infer multiple decoders at once or to produce decoders that learn super-resolution.
What carries the argument
The hypernetwork, which takes material input and directly outputs both latent feature textures and the complete weights and biases of the MLP decoder.
If this is right
- Neural texture compression becomes practical for large material libraries because no per-material optimization is required after the hypernetwork is trained.
- The same trained hypernetwork can generate decoders for new materials on demand.
- A single model can output multiple distinct decoders or super-resolution decoders for the same input material.
- Real-time shading pipelines can decode textures generated this way without storing separate optimized networks per material.
Where Pith is reading between the lines
- Dynamic scenes or user-created materials could receive compressed representations at runtime rather than requiring offline per-material fitting.
- The approach may transfer to other domains that currently rely on per-instance optimization of small decoders, such as neural material models or view synthesis.
- Scaling the hypernetwork could trade higher training cost for even smaller per-material storage if the generated decoders become more compact.
Load-bearing premise
A single hypernetwork trained across materials can reliably produce high-quality latent features and decoder parameters without per-material gradient-descent optimization.
What would settle it
Train the hypernetwork on one collection of materials, then measure whether the generated decoders for held-out materials reach the same reconstruction error or perceptual quality as decoders obtained by running per-material optimization on those same held-out materials.
Figures
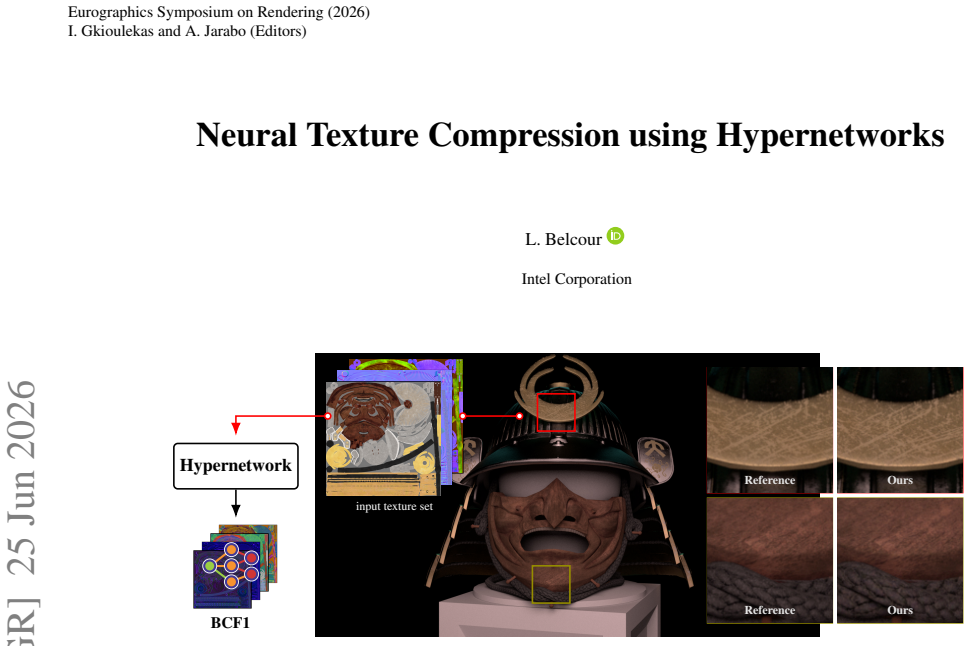
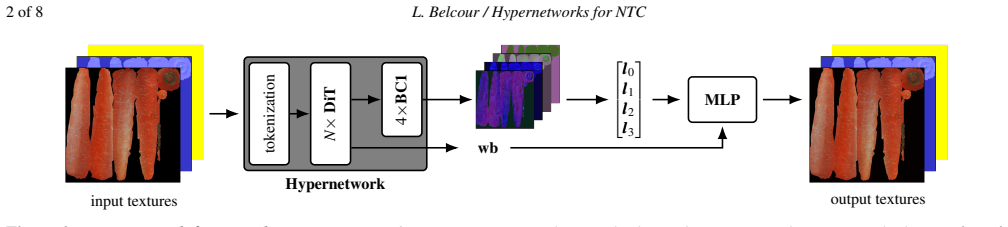
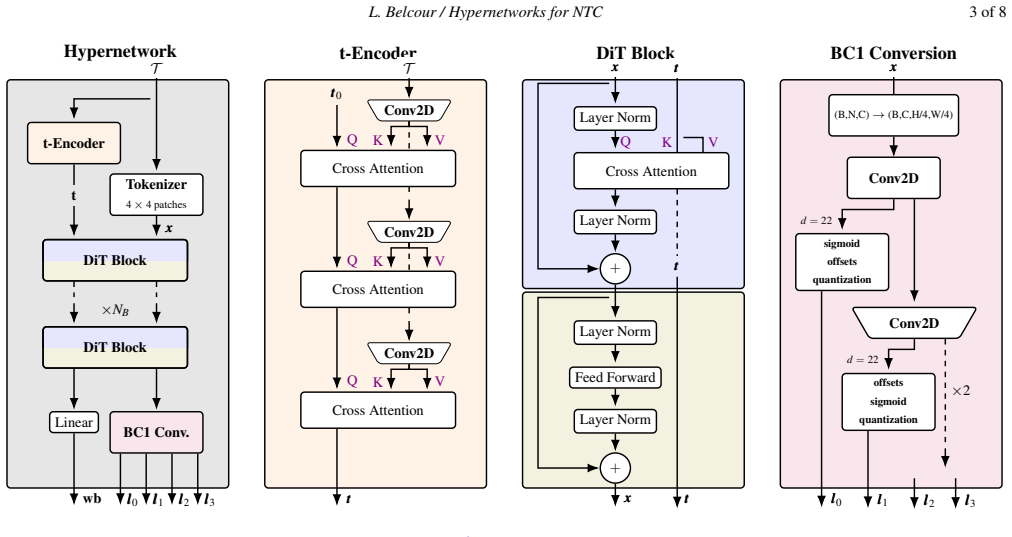
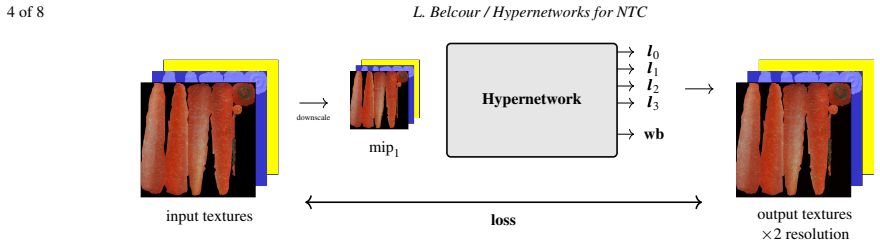



read the original abstract
Recent work on neural texture compression has demonstrated that it is possible to learn small, per-material texture representations (composed of latent textures and a small Multi-Layer Perceptron decoder) that can be decoded in real-time during shading to reproduce the input to a physically based shading model. However, existing methods require performing gradient-descent optimization per material for a given MLP and latent configuration. In this work, we train a single hypernetwork that outputs both the latent features and the MLP's weights and biases. Though the solution space is high-dimensional, this approach produces results comparable in quality to the current reference neural texture compressors. We further extend this approach to infer multiple decoders at once or even produce decoders that learn super-resolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes replacing per-material gradient-descent optimization in neural texture compression with a single hypernetwork that, given a material identifier or embedding, directly outputs both the compressed latent texture and the weights/biases of a small MLP decoder. The central claim is that this produces reconstruction quality comparable to existing per-material baselines despite the high-dimensional output space; the work also extends the hypernetwork to generate multiple decoders simultaneously or to produce super-resolution decoders.
Significance. If the hypernetwork reliably maps to per-material optima without any inference-time per-material optimization, the method would remove a major computational bottleneck, enabling scalable deployment of neural textures across large material libraries in real-time rendering pipelines. The hypernetwork formulation itself is a technically interesting way to amortize the high-dimensional search.
major comments (2)
- [Abstract / §3] Abstract and §3 (Method): the claim that a single hypernetwork produces results 'comparable in quality' to per-material baselines rests on the unverified assumption that joint training over the high-dimensional space converges to material-specific optima rather than an average approximation; no ablation is described that isolates whether the hypernetwork input is purely material-agnostic or includes a learned embedding that effectively performs per-material specialization.
- [§4] §4 (Experiments): without reported quantitative metrics (PSNR, SSIM, perceptual error), error bars, or direct comparison tables against the reference per-material compressors on the same test set, it is impossible to verify whether quality is truly matched or whether the hypernetwork merely approximates on average; the abstract's assertion of comparability is therefore load-bearing but unsupported in the provided text.
minor comments (2)
- [Abstract] The abstract states extensions to multiple decoders and super-resolution but provides no architectural diagram or loss-term description for these variants.
- [§3] Notation for the hypernetwork input (material ID vs. learned embedding) and the precise output dimensionality of the MLP weights should be clarified in §3 to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the two major comments point-by-point below, providing clarifications on the method and committing to additions that will strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Abstract / §3] the claim that a single hypernetwork produces results 'comparable in quality' to per-material baselines rests on the unverified assumption that joint training over the high-dimensional space converges to material-specific optima rather than an average approximation; no ablation is described that isolates whether the hypernetwork input is purely material-agnostic or includes a learned embedding that effectively performs per-material specialization.
Authors: The hypernetwork receives a learned material embedding as input (detailed in §3), which enables specialization to individual materials rather than producing a single average solution. We agree that an explicit ablation comparing the embedding-based input against a material-agnostic variant would more rigorously demonstrate this point and rule out mere averaging. We will add this ablation study to the revised manuscript. revision: yes
-
Referee: [§4] without reported quantitative metrics (PSNR, SSIM, perceptual error), error bars, or direct comparison tables against the reference per-material compressors on the same test set, it is impossible to verify whether quality is truly matched or whether the hypernetwork merely approximates on average; the abstract's assertion of comparability is therefore load-bearing but unsupported in the provided text.
Authors: We acknowledge that the experiments section currently emphasizes qualitative visual comparisons. To directly substantiate the comparability claim, we will add quantitative results including PSNR, SSIM, and perceptual error metrics (with error bars) together with side-by-side tables comparing against the per-material baselines on the identical test set. revision: yes
Circularity Check
No circularity: empirical hypernetwork training claim stands on its own
full rationale
The abstract and context present a direct empirical claim about training one hypernetwork to jointly output per-material latents and decoder weights, with quality comparable to per-material optimization baselines. No equations, derivation steps, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central assertion is a statement of training outcome rather than a reduction of any result to its own inputs by construction. This matches the default expectation of a self-contained empirical result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A hypernetwork can learn a useful mapping from material inputs to both latent codes and decoder parameters in a high-dimensional space.
Reference graph
Works this paper leans on
-
[1]
2023 , publisher=
Physically based rendering: From theory to implementation , author=. 2023 , publisher=
2023
-
[2]
Mitsuba 3 renderer , author =
-
[3]
Zap Andersson and Paul Edmondson and Julien Guertault and Adrien Herubel and Alan King and Peter Kutz and Andréa Machizaud and Jamie Portsmouth and Frédéric Servant and Jonathan Stone , title =
-
[4]
2023 , howpublished=
Fowler,Chris , title=. 2023 , howpublished=
2023
-
[5]
Vulkan Documentation: Compressed Image Formats , author=
-
[6]
IEEE transactions on Communications , volume=
Image compression using block truncation coding , author=. IEEE transactions on Communications , volume=. 1979 , publisher=
1979
-
[7]
The Computer Journal , volume=
Compression of digital images by block truncation coding: a survey , author=. The Computer Journal , volume=. 1994 , publisher=
1994
-
[8]
Random-Access Neural Compression of Material Textures , journal = tog, year =
Vaidyanathan, Karthik and Salvi, Marco and Wronski, Bartlomiej and Akenine-M. Random-Access Neural Compression of Material Textures , journal = tog, year =. doi:10.1145/3592407 , note =
-
[9]
Real-Time Neural Materials using Block-Compressed Features , journal = cgforum, year =
Weinreich, Cl. Real-Time Neural Materials using Block-Compressed Features , journal = cgforum, year =
-
[10]
European Conference on Computer Vision , pages=
Neural Graphics Texture Compression Supporting Random Access , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[11]
Belcour, Laurent and Benyoub, Amine , title =. 2025 , volume =. 2506.06040 , archivePrefix=
arXiv 2025
-
[12]
Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers , pages=
Image-gs: Content-adaptive image representation via 2d gaussians , author=. Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers , pages=
-
[13]
2024 , eprint =
Fujieda, Shin and Harada, Takahiro , title =. 2024 , eprint =
2024
-
[14]
Proceedings of the Fourth ACM SIGGRAPH/Eurographics Conference on High-Performance Graphics , pages=
Adaptive scalable texture compression , author=. Proceedings of the Fourth ACM SIGGRAPH/Eurographics Conference on High-Performance Graphics , pages=
-
[15]
MatUp: Repurposing Image Upsamplers for SVBRDFs , journal = cgforum, year =
Gauthier, Alban and Kerbl, Bernhard and Levallois, J. MatUp: Repurposing Image Upsamplers for SVBRDFs , journal = cgforum, year =. doi:10.1111/cgf.15151 , note =
-
[16]
Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
Chord: Chain of Rendering Decomposition for PBR Material Estimation from Generated Texture Images , author=. Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
2025
-
[17]
Proceedings of the 34th International Conference on Machine Learning (ICML) , year =
Finn, Chelsea and Abbeel, Pieter and Levine, Sergey , title =. Proceedings of the 34th International Conference on Machine Learning (ICML) , year =. 1703.03400 , archivePrefix =
-
[18]
, title =
Ha, David and Dai, Andrew and Le, Quoc V. , title =. 2016 , eprint =
2016
-
[19]
and Pfau, David and Schaul, Tom and Shillingford, Brendan and de Freitas, Nando , title =
Andrychowicz, Marcin and Denil, Misha and Gomez, Sergio and Hoffman, Matthew W. and Pfau, David and Schaul, Tom and Shillingford, Brendan and de Freitas, Nando , title =. 2016 , eprint =
2016
-
[20]
Hypernetwork Functional Image Representation , booktitle =
Klocek, Sylwester and Maziarka,. Hypernetwork Functional Image Representation , booktitle =. 2019 , pages =
2019
-
[21]
1989 First IEE International Conference on Artificial Neural Networks,(Conf
Sirat, JA and Viala, JR and Remus, C , title =. 1989 First IEE International Conference on Artificial Neural Networks,(Conf. Publ. No. 313) , year =
1989
-
[22]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Stylizing 3d scene via implicit representation and hypernetwork , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[23]
European Conference on Computer Vision , pages=
Hypernst: Hyper-networks for neural style transfer , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[24]
Advances in Neural Information Processing Systems , volume=
Hyp-nerf: Learning improved nerf priors using a hypernetwork , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
European Conference on Computer Vision , pages=
Hypernetworks for generalizable brdf representation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[26]
arXiv preprint arXiv:1412.6980 , year=
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
-
[27]
arXiv preprint arXiv:1711.05101 , year=
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
-
[28]
IEEE transactions on image processing , volume=
Image quality assessment: from error visibility to structural similarity , author=. IEEE transactions on image processing , volume=. 2004 , publisher=
2004
-
[29]
The thrity-seventh asilomar conference on signals, systems & computers, 2003 , volume=
Multiscale structural similarity for image quality assessment , author=. The thrity-seventh asilomar conference on signals, systems & computers, 2003 , volume=. 2003 , organization=
2003
-
[30]
Proceedings of the 42nd International Conference on Machine Learning, PMLR , year=
Peri-LN: Revisiting Normalization Layer in the Transformer Architecture , author=. Proceedings of the 42nd International Conference on Machine Learning, PMLR , year=
-
[31]
ACM SIGGRAPH 2021 Talks , pages=
Passing multi-channel material textures to a 3-channel loss , author=. ACM SIGGRAPH 2021 Talks , pages=
2021
-
[32]
ICLR , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. ICLR , year=
-
[33]
2022 , journal=
Scalable Diffusion Models with Transformers , author=. 2022 , journal=
2022
-
[34]
CoRR , volume =
Image Quality Assessment: Unifying Structure and Texture Similarity , author=. CoRR , volume =
-
[35]
arXiv preprint arXiv:1606.08415 , year=
Gaussian error linear units (gelus) , author=. arXiv preprint arXiv:1606.08415 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.