Mixture-of-Parallelisms: Towards Memory-Efficient Training Stack for Mixture-of-Experts Models
Pith reviewed 2026-07-03 06:14 UTC · model grok-4.3
The pith
A layered set of parallelisms trains trillion-parameter MoE models at 1M context length on under 12 GPU nodes with 4.7x-8.2x higher throughput than FSDP2.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining and specializing parallelism techniques at different layers and stages of the MoE training pipeline together with a novel optimizer strategy, the approach respects the physical constraints of CPU, CPU memory, GPU HBM, and all levels of communication bandwidth, enabling training of trillion-parameter scale models at million-token context lengths on just under 12 8x H200 GPU nodes while delivering 4.7x to 8.2x higher per-GPU throughput than a tuned FSDP2 baseline.
What carries the argument
The Mixture-of-Parallelisms stack, which layers specialized parallelisms across pipeline stages and adds a novel optimizer step to fit within CPU-GPU and node-node bandwidth limits.
If this is right
- Training remains stable at context lengths up to 1M tokens where standard methods fail beyond 64-128K.
- Per-GPU throughput advantage over FSDP2 grows larger as model scale increases.
- Lossless pre-training and fine-tuning of trillion-parameter MoE models become feasible on clusters of roughly 100 GPUs.
- The same stack supports both pre-training and fine-tuning without loss of model quality.
Where Pith is reading between the lines
- The same layering idea might reduce memory pressure for non-MoE transformer training at long contexts.
- Hardware designers could target the specific communication patterns that arise from mixing these parallelisms.
- Fewer nodes per training run could change how organizations schedule and share large GPU clusters.
Load-bearing premise
The chosen parallelisms and optimizer step can be combined without creating instability, convergence problems, or extra communication costs that erase the reported memory and throughput gains.
What would settle it
Train the same MoE model at 1M context length once with MoP and once with the FSDP2 baseline on identical hardware and measure whether the baseline runs out of memory beyond 128K tokens while MoP completes with the claimed throughput advantage.
Figures
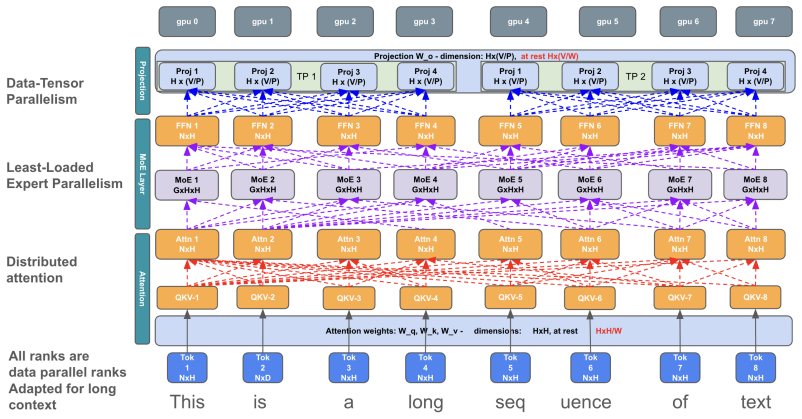
read the original abstract
This paper showcases a memory-efficient training stack for Mixture-of-Experts (MoE) models. It is a training paradigm that combines and specializes various existing and novel parallelism techniques at different layers and stages of the Mixture-of-Experts (MoE) model training pipeline. It leverages these techniques to achieve maximal efficiency given the physical constraints of CPU, CPU memory, GPU HBM memory, and the CPU-GPU, GPU-GPU, and node-node communication bandwidth of the GPU cluster. It also contains a novel strategy for the optimizer step to achieve high throughput and memory efficiency, enabling practitioners to conduct lossless pre-training/fine-tuning of trillion-parameter scale models, at a million context length, with just under 12 8x H200 GPU nodes, with state-of-the-art throughput and memory efficiency. In our experiments, MoP delivers 4.7x--8.2x higher per-GPU throughput than a strongly-tuned FSDP2 baseline (with the gap widening at larger scale) and sustains training at context lengths up to 1M tokens, where the baseline runs out of memory beyond 64--128K.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Mixture-of-Parallelisms (MoP), a training paradigm for Mixture-of-Experts (MoE) models that combines and specializes various existing and novel parallelism techniques at different layers and stages of the training pipeline, along with a novel optimizer strategy. This is designed to maximize efficiency under constraints of CPU, CPU memory, GPU HBM, and inter-device communication bandwidth. Experiments report 4.7x--8.2x higher per-GPU throughput than a strongly-tuned FSDP2 baseline (gap widening at larger scale), with the ability to sustain training at context lengths up to 1M tokens (where baseline OOMs beyond 64--128K), enabling lossless pre-training/fine-tuning of trillion-parameter MoE models at million-token context on just under 12 8x H200 GPU nodes.
Significance. If the measured throughput and memory gains hold under the described implementation, the work would be significant for practical scaling of large MoE models in distributed settings. It provides an engineering demonstration of how layered parallelism specialization plus optimizer modifications can extend feasible context lengths and model sizes on fixed hardware, with direct comparisons to a tuned baseline across scales.
minor comments (2)
- Abstract states strong quantitative claims (throughput ratios, context lengths, node counts) but provides no methods, ablation studies, error bars, or dataset details; while the full manuscript supplies implementation details, the abstract should be revised to include at least high-level experimental setup for standalone readability.
- The description of the novel optimizer strategy and its interaction with the combined parallelisms would benefit from an explicit pseudocode or step-by-step breakdown in the methods section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No specific major comments were raised in the report, so we have no point-by-point responses to provide. We are happy to address any minor issues or clarifications in a revised manuscript if requested by the editor.
Circularity Check
No significant circularity; engineering claims rest on measured experiments
full rationale
The paper presents an engineering system combining existing and novel parallelism techniques plus an optimizer strategy for MoE training. All load-bearing claims are throughput and memory measurements from direct comparisons to a tuned FSDP2 baseline across scales and context lengths. No equations, fitted parameters, self-definitional derivations, or self-citation chains appear in the provided text. The central results are externally falsifiable via reproduction of the described implementation and do not reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training Deep Nets with Sublinear Memory Cost
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost.arXiv preprint arXiv:1604.06174, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness.Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[3]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
2022
-
[4]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari, and Yuxiong He. DeepSpeed Ulysses: System optimizations for enabling training of extreme long sequence transformer models.arXiv preprint arXiv:2309.14509, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Reducing activation recomputation in large transformer models
Vijay Anand Korthikanti, Jared Casper, Sangkug Lym, Lawrence McAfee, Michael Andersch, Mohammad Shoeybi, and Bryan Catanzaro. Reducing activation recomputation in large transformer models. InProceedings of Machine Learning and Systems (MLSys), 2023
2023
-
[6]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[7]
TorchTitan: One-stop PyTorch native solution for production ready LLM pre-training
Wanchao Liang, Tianyu Liu, Less Wright, Will Constable, Andrew Gu, Chien-Chin Huang, Iris Zhang, Wei Feng, Howard Huang, Junjie Wang, Sanket Purandare, Gokul Nadathur, and Stratos Idreos. TorchTitan: One-stop PyTorch native solution for production ready LLM pre-training. InInternational Conference on Learning Representations (ICLR), 2025. arXiv:2410.06511
-
[8]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[9]
Xuan-Phi Nguyen, Shrey Pandit, Austin Xu, Caiming Xiong, and Shafiq Joty. Least- loaded expert parallelism: Load balancing an imbalanced mixture-of-experts.arXiv preprint arXiv:2601.17111, 2026
-
[10]
ZeRO: Memory optimizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. ZeRO: Memory optimizations toward training trillion parameter models. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC), 2020
2020
-
[11]
DeepSpeed-MoE: Advancing mixture-of- experts inference and training to power next-generation AI scale
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. DeepSpeed-MoE: Advancing mixture-of- experts inference and training to power next-generation AI scale. InInternational Conference on Machine Learning (ICML), 2022
2022
-
[12]
ZeRO-Offload: Democratizing billion-scale model training
Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He. ZeRO-Offload: Democratizing billion-scale model training. InUSENIX Annual Technical Conference (ATC), 2021
2021
-
[13]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-LM: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[14]
PyTorch FSDP: Experiences on scaling fully sharded data parallel.Proceedings of the VLDB Endowment, 16 (12):3848–3860, 2023
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. PyTorch FSDP: Experiences on scaling fully sharded data parallel.Proceedings of the VLDB Endowment, 16 (12):384...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.