Revisiting Parameter Redundancy in Vision-Language-Action Models: Insights from VLM-to-VLA Adaptation
Pith reviewed 2026-07-01 05:05 UTC · model grok-4.3
The pith
Pruning VLA models via adaptation divergence removes 12-30% parameters while retaining 90% performance without recovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Quantifying spatial patterns of parameter divergence during VLM-to-VLA adaptation reveals structured modular heterogeneities; controlled pruning without fine-tuning then serves as a diagnostic that links these divergence signals to functional importance, enabling a multi-module joint pruning scheme that reduces parameters of OpenVLA and π0.5 by 12-30% while preserving approximately 90% of original LIBERO performance.
What carries the argument
Multi-module joint pruning scheme that selects parameter subsets according to their measured divergence signals across modules during adaptation.
If this is right
- VLA performance degradation after pruning is not an inevitable consequence of parameter reduction if subsets are chosen according to adaptation divergence.
- Standard pruning criteria that ignore adaptation history discard functionally critical weights under recovery-free evaluation.
- Efficient robotic policies can be obtained directly from adapted models without subsequent fine-tuning or low-rank corrections.
- Parameter redundancy in VLAs is structured by module rather than uniformly distributed.
Where Pith is reading between the lines
- The same divergence-probe method could be applied to diagnose redundancy in other adaptation settings such as language-to-vision or multi-task fine-tuning.
- Tracking divergence during training might allow early stopping or regularization choices that reduce redundancy before full adaptation completes.
- If the modular patterns prove stable across different base VLMs, the pruning ratios could be predicted from adaptation statistics alone without running the full diagnostic.
Load-bearing premise
That the immediate performance change after removing a parameter subset without any fine-tuning directly reveals whether those parameters carry functional importance induced by adaptation.
What would settle it
Running the same controlled pruning experiment on a new VLA model or task where the proposed divergence-based subsets produce performance collapse comparable to random or magnitude-based removal.
Figures
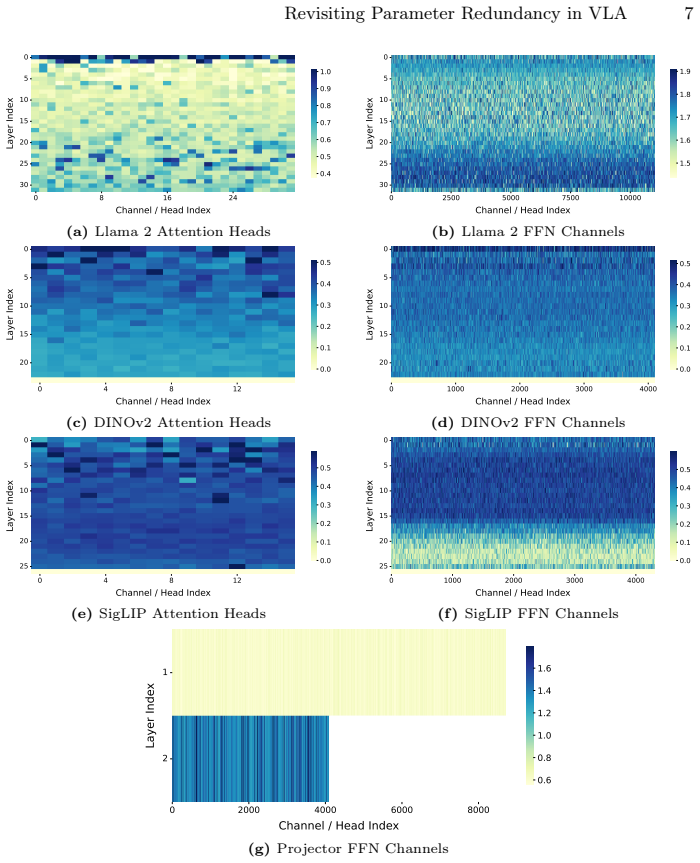
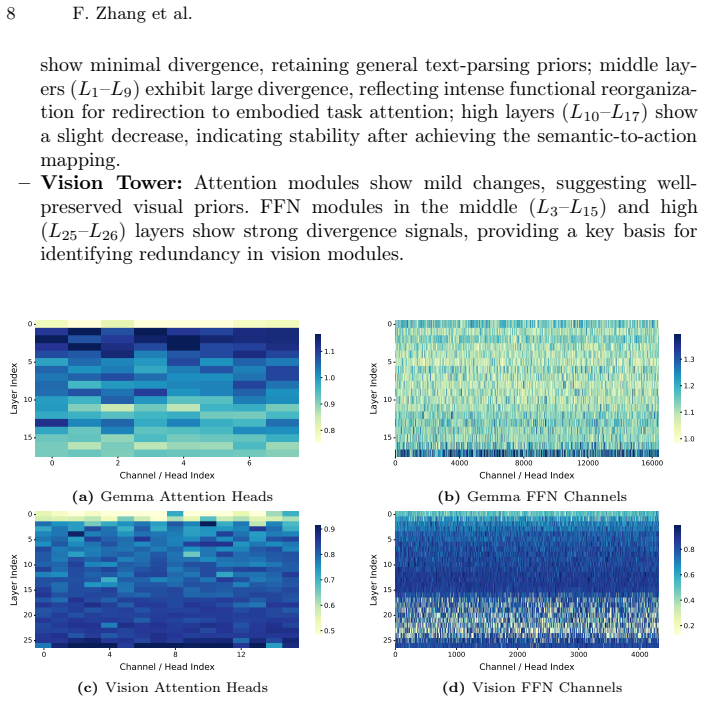
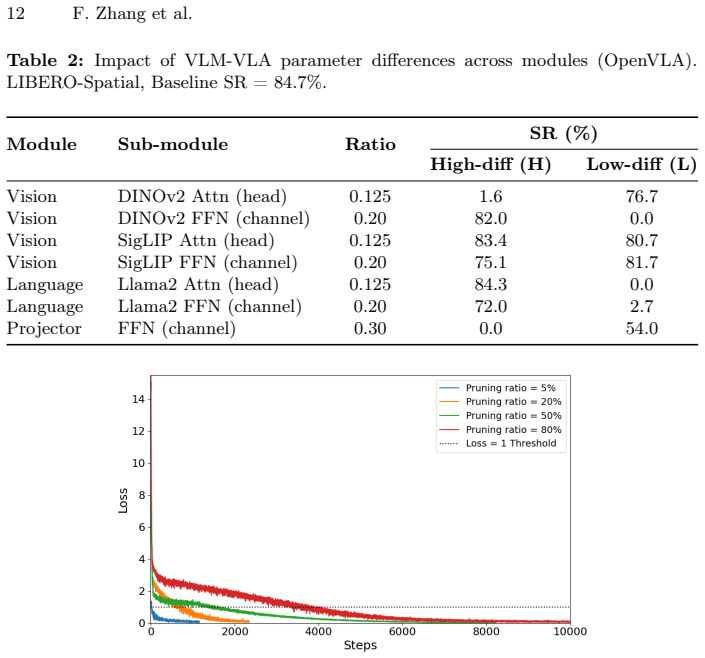
read the original abstract
Vision-Language-Action (VLA) models have made significant strides in embodied intelligence by integrating the powerful representations of pre-trained Vision-Language Models (VLMs). However, the massive parameter scale of VLAs imposes a heavy computational burden, and these models exhibit extreme sensitivity to parameter pruning. Current paradigms often treat the resulting performance degradation as inevitable, relying on fine-tuning or low-rank corrections to recover efficacy. We challenge this convention by questioning whether the removed parameters are truly redundant if VLA pruning necessitates performance recovery to be effective, or if this paradigm masks the indiscriminate pruning of critical parameters. We revisit parameter redundancy through the lens of VLM-to-VLA adaptation, first quantifying the spatial distribution of parameter divergence during adaptation to reveal structured patterns across different modules. Subsequently, we introduce controlled pruning as a diagnostic probe: by comparing the direct impact of removing different parameter subsets on VLA performance without any fine-tuning, we establish a causal link between adaptation-induced divergence signals and functional contributions. Based on the discovered modular heterogeneities, we design a multi-module joint pruning scheme. Evaluations on the LIBERO benchmark demonstrate that our approach reduces the parameters of OpenVLA and $\pi_{0.5}$ by 12\%--30\% while maintaining approximately 90\% of the original performance without any post-pruning recovery. In contrast, existing parameter pruning criteria result in total performance collapse when evaluated under the same recovery-free constraints. Our study reveals the parameter evolution mechanism in VLA adaptation and provides a new path for deploying efficient, robust robotic policies in resource-constrained environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that quantifying parameter divergence during VLM-to-VLA adaptation reveals modular heterogeneities; a controlled no-recovery pruning probe then establishes that divergence signals mark functionally important parameters; and a resulting multi-module joint pruning scheme reduces parameters in OpenVLA and π0.5 by 12–30% while retaining ~90% of original LIBERO performance, whereas standard criteria cause total collapse under identical recovery-free conditions.
Significance. If the central empirical result holds after addressing the causality concern, the work supplies a concrete, recovery-free route to smaller VLAs and new evidence on how adaptation redistributes parameter importance. The use of a public benchmark (LIBERO) and the explicit no-fine-tuning diagnostic are strengths that support reproducibility and falsifiability.
major comments (2)
- [Abstract and controlled pruning experiment] Abstract (controlled pruning paragraph) and the corresponding experimental section: the claim that the performance gap demonstrates a causal link between adaptation-induced divergence and functional contribution is load-bearing yet rests on an unablated comparison. Divergence is known to correlate with layer depth and weight magnitude in VLM-to-VLA transfer; without explicit matching or regression controls on these covariates, the observed superiority over baselines could be explained by module choice rather than the divergence metric itself.
- [Experimental results on LIBERO] Experimental results section (LIBERO tables/figures): the reported 12–30% reduction and ~90% retention figures lack accompanying details on exact divergence quantification (e.g., which norm or distance), per-module pruning thresholds, baseline implementations, number of seeds, and statistical tests. These omissions prevent verification that the performance retention is robust and not an artifact of particular hyper-parameter choices.
minor comments (2)
- [Throughout] Notation: the symbol π0.5 appears inconsistently (sometimes with subscript, sometimes without); standardize throughout.
- [Figures] Figure clarity: ensure that divergence heat-maps or module-wise plots include axis labels, color-bar scales, and error bars where applicable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important areas for strengthening the causal interpretation and improving experimental transparency. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and controlled pruning experiment] Abstract (controlled pruning paragraph) and the corresponding experimental section: the claim that the performance gap demonstrates a causal link between adaptation-induced divergence and functional contribution is load-bearing yet rests on an unablated comparison. Divergence is known to correlate with layer depth and weight magnitude in VLM-to-VLA transfer; without explicit matching or regression controls on these covariates, the observed superiority over baselines could be explained by module choice rather than the divergence metric itself.
Authors: We thank the referee for pointing out this potential confound. While our experiments compare the performance impact of pruning based on divergence versus standard criteria like magnitude, we did not explicitly control for correlations with layer depth and weight magnitude through matching or regression. We agree this is a valid concern and will incorporate additional controls and ablations in the revised manuscript to better isolate the effect of the divergence metric. revision: yes
-
Referee: [Experimental results on LIBERO] Experimental results section (LIBERO tables/figures): the reported 12–30% reduction and ~90% retention figures lack accompanying details on exact divergence quantification (e.g., which norm or distance), per-module pruning thresholds, baseline implementations, number of seeds, and statistical tests. These omissions prevent verification that the performance retention is robust and not an artifact of particular hyper-parameter choices.
Authors: We agree with the need for more details to ensure reproducibility. The revised manuscript will include: the specific divergence measure (L2 norm on parameter deltas), the exact per-module pruning thresholds, full descriptions of baseline methods, the number of evaluation seeds, and appropriate statistical tests for the reported results. revision: yes
Circularity Check
Empirical ablation on public benchmark exhibits no circularity
full rationale
The paper conducts an empirical study: it quantifies parameter divergence across modules during VLM-to-VLA adaptation, then applies controlled pruning (no recovery fine-tuning) on the LIBERO benchmark to measure performance retention. Reported results (12-30% parameter reduction at ~90% performance for OpenVLA and π0.5) are direct benchmark outcomes, not quantities defined by or fitted to the divergence metric itself. No equations, self-citations, or ansatzes reduce the performance claims to inputs by construction; the work remains self-contained against an external public benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fluctuation-based adaptive structured pruning for large language models
Yongqi An, Xu Zhao, Tao Yu, Ming Tang, and Jinqiao Wang. Fluctuation-based adaptive structured pruning for large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 10865–10873, 2024
2024
-
[2]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang,DanielSalz,MaximNeumann,IbrahimAlabdulmohsin,MichaelTschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
RLRC: Reinforcement Learning-based Recovery for Compressed Vision-Language-Action Models
Yuxuan Chen and Xiao Li. Rlrc: Reinforcement learning-based recovery for com- pressed vision-language-action models.arXiv preprint arXiv:2506.17639, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowd- hery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Hengyu Fang, Yijiang Liu, Yuan Du, Li Du, and Huanrui Yang. Sqap-vla: A synergistic quantization-aware pruning framework for high-performance vision- language-action models.arXiv preprint arXiv:2509.09090, 2025
-
[7]
Efficient Vision-Language-Action Models for Embodied Manipulation: A Systematic Survey
Weifan Guan, Qinghao Hu, Aosheng Li, and Jian Cheng. Efficient vision-language- action models for embodied manipulation: A systematic survey.arXiv preprint arXiv:2510.17111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Asher J Hancock, Xindi Wu, Lihan Zha, Olga Russakovsky, and Anirudha Ma- jumdar. Actions as language: Fine-tuning vlms into vlas without catastrophic forgetting.arXiv preprint arXiv:2509.22195, 2025
-
[9]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dha- balia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fu- sai, Manuel Y. Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Per...
2025
-
[10]
Jason Jabbour, Dong-Ki Kim, Max Smith, Jay Patrikar, Radhika Ghosal, Youhui Wang, Ali Agha, Vijay Janapa Reddi, and Shayegan Omidshafiei. Don’t run with scissors: Pruning breaks vla models but they can be recovered.arXiv preprint arXiv:2510.08464, 2025
-
[11]
Prismatic vlms: Investigating the design space of visually- conditioned language models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kol- lar, and Dorsa Sadigh. Prismatic vlms: Investigating the design space of visually- conditioned language models. InForty-first International Conference on Machine Learning, 2024
2024
-
[12]
Vision-language-action models for robotics: A review towards real-world applica- tions.IEEE Access, 2025
Kento Kawaharazuka, Jihoon Oh, Jun Yamada, Ingmar Posner, and Yuke Zhu. Vision-language-action models for robotics: A review towards real-world applica- tions.IEEE Access, 2025
2025
-
[13]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakr- ishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision- language-action model for synergizing cognition and action in robotic manipula- tion.arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
VLA-ATTC: Adaptive Test-Time Compute for VLA Models with Relative Action Critic Model
Wenhao Li, Xiu Su, Yichao Cao, Hongyan Xu, Xiaobo Xia, Shan You, Yi Chen, and Chang Xu. Vla-attc: Adaptive test-time compute for vla models with relative action critic model.arXiv preprint arXiv:2605.01194, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Ye Li, Yuan Meng, Zewen Sun, Kangye Ji, Chen Tang, Jiajun Fan, Xinzhu Ma, ShutaoXia,ZhiWang,andWenwuZhu. Sp-vla:Ajointmodelschedulingandtoken pruning approach for vla model acceleration.arXiv preprint arXiv:2506.12723, 2025
-
[17]
Libero: Benchmarking knowledge transfer for lifelong robot learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Pe- ter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[18]
Robomamba: Efficient vision-language-action model for robotic reasoning and manipulation.Ad- vances in Neural Information Processing Systems, 37:40085–40110, 2024
Jiaming Liu, Mengzhen Liu, Zhenyu Wang, Pengju An, Xiaoqi Li, Kaichen Zhou, Senqiao Yang, Renrui Zhang, Yandong Guo, and Shanghang Zhang. Robomamba: Efficient vision-language-action model for robotic reasoning and manipulation.Ad- vances in Neural Information Processing Systems, 37:40085–40110, 2024
2024
-
[19]
Llm-pruner: On the structural pruning of large language models.Advances in neural information processing sys- tems, 36:21702–21720, 2023
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Llm-pruner: On the structural pruning of large language models.Advances in neural information processing sys- tems, 36:21702–21720, 2023
2023
-
[20]
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, and Irwin King. A survey on vision-language-action models for embodied ai.arXiv preprint arXiv:2405.14093, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Mech- anistic finetuning of vision-language-action models via few-shot demonstrations
Chancharik Mitra, Yusen Luo, Raj Saravanan, Dantong Niu, Anirudh Pai, Jesse Thomason, Trevor Darrell, Abrar Anwar, Deva Ramanan, and Roei Herzig. Mech- anistic finetuning of vision-language-action models via few-shot demonstrations. arXiv preprint arXiv:2511.22697, 2025
-
[22]
Saliency-aware quantized imitation learning for efficient robotic control
Seongmin Park, Hyungmin Kim, Sangwoo Kim, Wonseok Jeon, Juyoung Yang, Byeongwook Jeon, Yoonseon Oh, and Jungwook Choi. Saliency-aware quantized imitation learning for efficient robotic control. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13140–13150, 2025. Revisiting Parameter Redundancy in VLA 17
2025
-
[23]
Action-aware dynamic pruning for efficient vision-language-action manipulation
Xiaohuan Pei, Yuxing Chen, Siyu Xu, Yunke Wang, Yuheng Shi, and Chang Xu. Action-aware dynamic pruning for efficient vision-language-action manipulation. arXiv preprint arXiv:2509.22093, 2025
-
[24]
Ranjan Sapkota, Yang Cao, Konstantinos I Roumeliotis, and Manoj Karkee. Vision-language-action (vla) models: Concepts, progress, applications and chal- lenges.arXiv preprint arXiv:2505.04769, 2025
-
[25]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language-action model for affordable and effi- cient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
A Simple and Effective Pruning Approach for Large Language Models
Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. A simple and effective pruning approach for large language models.arXiv preprint arXiv:2306.11695, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Xudong Tan, Yaoxin Yang, Peng Ye, Jialin Zheng, Bizhe Bai, Xinyi Wang, Jia Hao, and Tao Chen. Think twice, act once: Token-aware compression and ac- tion reuse for efficient inference in vision-language-action models.arXiv preprint arXiv:2505.21200, 2025
-
[28]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Hongyu Wang, Chuyan Xiong, Ruiping Wang, and Xilin Chen. Bitvla: 1- bit vision-language-action models for robotics manipulation.arXiv preprint arXiv:2506.07530, 2025
-
[30]
Tinyvla: Towards fast, data- efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters, 2025
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Zhibin Tang, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, et al. Tinyvla: Towards fast, data- efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters, 2025
2025
-
[31]
Siyu Xu, Yunke Wang, Chenghao Xia, Dihao Zhu, Tao Huang, and Chang Xu. Vla- cache: Efficient vision-language-action manipulation via adaptive token caching. arXiv preprint arXiv:2502.02175, 2025
-
[32]
Siyu Xu, Zijian Wang, Yunke Wang, Chenghao Xia, Tao Huang, and Chang Xu. Affordance field intervention: Enabling vlas to escape memory traps in robotic manipulation.arXiv preprint arXiv:2512.07472, 2025
-
[33]
Yuhao Xu, Yantai Yang, Zhenyang Fan, Yufan Liu, Yuming Li, Bing Li, and Zhipeng Zhang. Qvla: Not all channels are equal in vision-language-action model’s quantization.arXiv preprint arXiv:2602.03782, 2026
-
[34]
Yantai Yang, Yuhao Wang, Zichen Wen, Luo Zhongwei, Chang Zou, Zhipeng Zhang,ChuanWen,andLinfengZhang. Efficientvla:Training-freeaccelerationand compression for vision-language-action models.arXiv preprint arXiv:2506.10100, 2025
-
[35]
A survey on efficient vision-language-action models, 2025
Zhaoshu Yu, Bo Wang, Pengpeng Zeng, Haonan Zhang, Ji Zhang, Lianli Gao, Jingkuan Song, Nicu Sebe, and Heng Tao Shen. A survey on efficient vision- language-action models.arXiv preprint arXiv:2510.24795, 2025
-
[36]
Deer-vla: Dynamic inference of multimodal large language models for efficient robot execution.Advances in Neural Information Processing Systems, 37:56619–56643, 2024
Yang Yue, Yulin Wang, Bingyi Kang, Yizeng Han, Shenzhi Wang, Shiji Song, Jiashi Feng, and Gao Huang. Deer-vla: Dynamic inference of multimodal large language models for efficient robot execution.Advances in Neural Information Processing Systems, 37:56619–56643, 2024
2024
-
[37]
VLM4VLA: Revisiting Vision-Language-Models in Vision-Language-Action Models
Jianke Zhang, Xiaoyu Chen, Qiuyue Wang, Mingsheng Li, Yanjiang Guo, Yucheng Hu, Jiajun Zhang, Shuai Bai, Junyang Lin, and Jianyu Chen. Vlm4vla: Re- 18 F. Zhang et al. visiting vision-language-models in vision-language-action models.arXiv preprint arXiv:2601.03309, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Rongyu Zhang, Menghang Dong, Yuan Zhang, Liang Heng, Xiaowei Chi, Gaole Dai, Li Du, Yuan Du, and Shanghang Zhang. Mole-vla: Dynamic layer-skipping vision language action model via mixture-of-layers for efficient robot manipulation. arXiv preprint arXiv:2503.20384, 2025
-
[39]
strong compensation
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language- action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. Revisiting Parameter Redundancy in VLA 19 A Detailed Model Composition and Parameter ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.