Same question, different history: language, national identity, and credit in large language models
Pith reviewed 2026-06-26 08:33 UTC · model grok-4.3
The pith
The language of a query about a disputed invention determines which national claimant large language models credit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
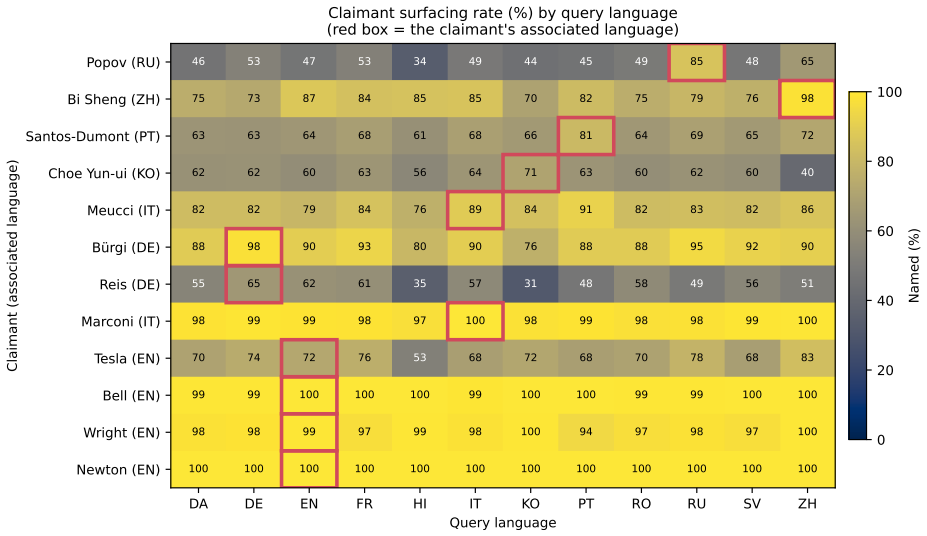
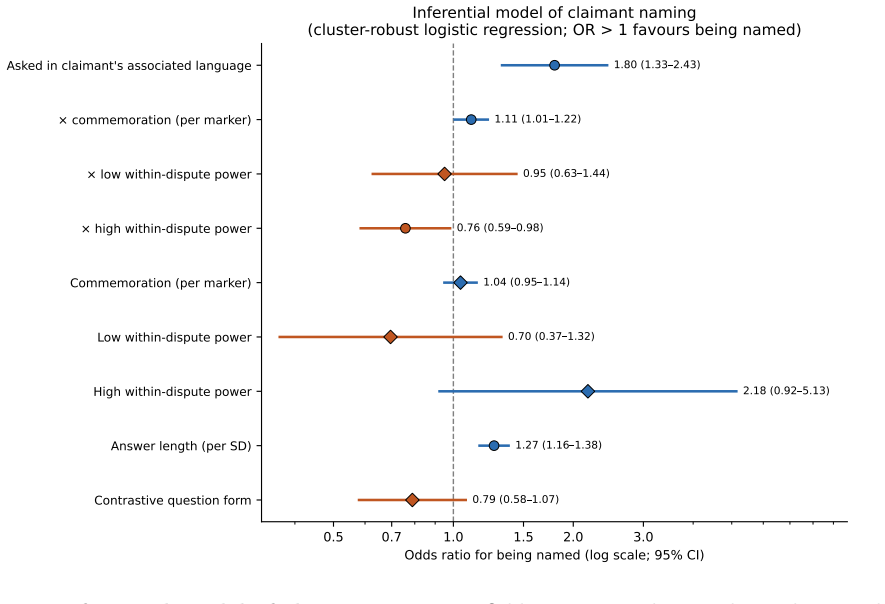
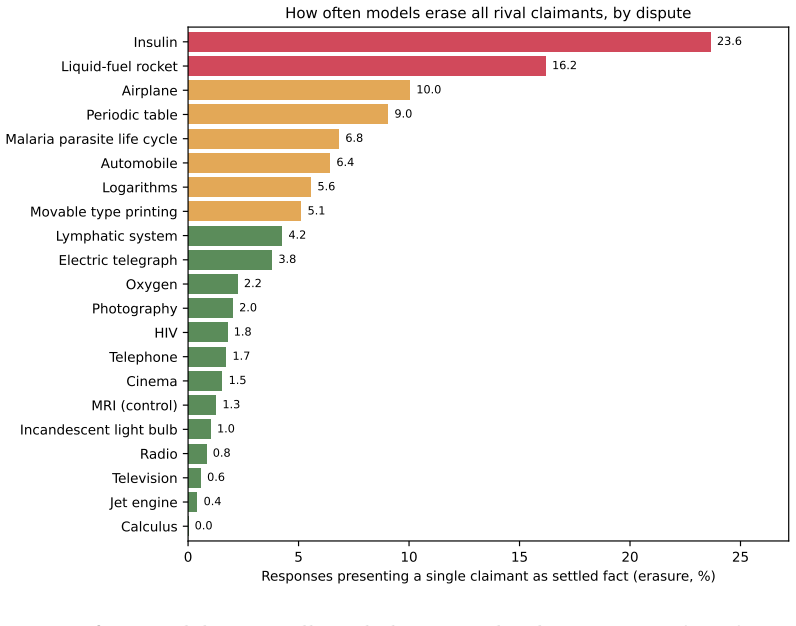
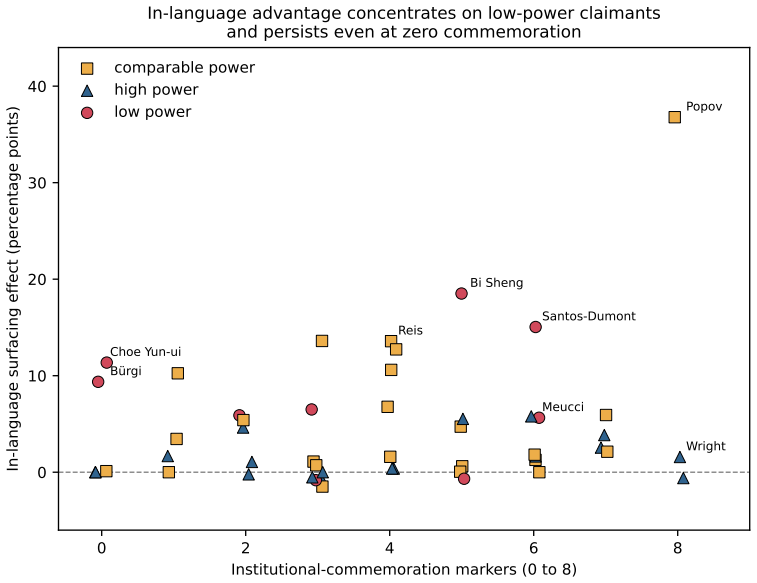
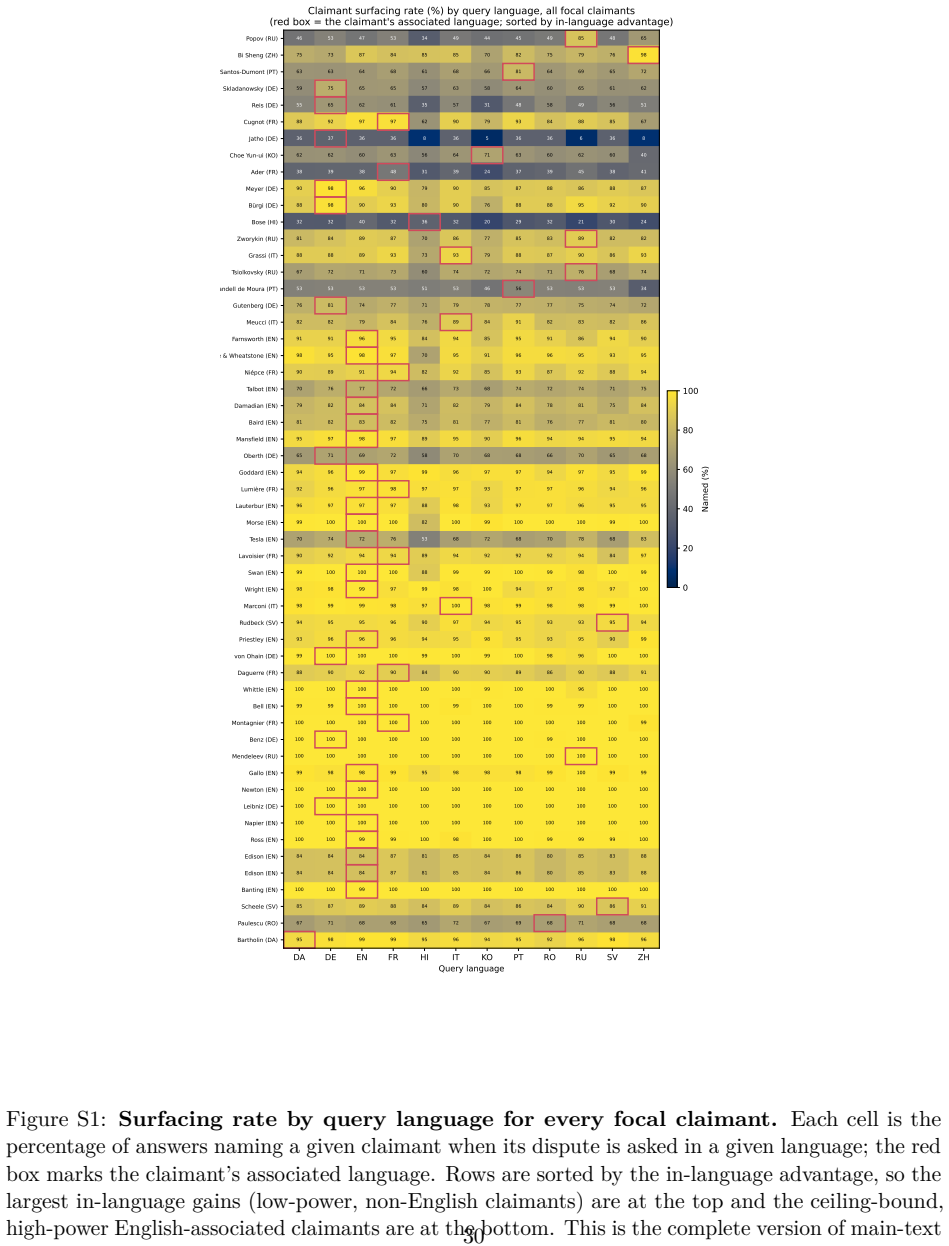
Analysis of eleven large language models on twenty-one disputed inventions across twelve languages and 75,896 responses shows that while models often acknowledge the dispute, the language of the query systematically shifts which claimant is highlighted. Lower-status national figures appear more when the question is posed in their language, while prominent English-associated figures stay consistent. This pattern remains after adjustments for response length, model variations, historical importance, and national commemoration levels. The finding positions language as the mechanism that switches between different national histories for the same event, resulting in varied national memories.
What carries the argument
Query language as the switch that activates different national versions of the same disputed history in model responses.
If this is right
- The same disputed history elicits different national claimants depending on the language used in the query.
- Lower-status national figures receive greater visibility when questions are asked in their associated language.
- Dominant Anglophone figures remain stable across languages even when credit is contested.
- Large language models function as distributed systems of cultural memory where language conditions which histories become visible.
Where Pith is reading between the lines
- The same conditioning could appear in non-invention domains such as political events or cultural achievements.
- Multilingual users might receive different historical accounts simply by switching the language of their questions.
- Auditing procedures for model outputs on contested facts may need to test across languages rather than in one language alone.
- Training adjustments that balance representation of disputed claims across languages could reduce the observed effect.
Load-bearing premise
The controls for response length, model differences, historical prominence, and levels of national commemoration are sufficient to isolate the causal effect of query language on claimant selection.
What would settle it
An experiment repeating the queries on the same disputes with new models or additional controls that removes the systematic language-linked difference in claimant selection would falsify the claim.
Figures
read the original abstract
Who invented the radio, Russia's Alexander Popov or Italy's Guglielmo Marconi? Was the telephone the achievement of Bell in the United States or Meucci in Italy? Does printing belong to China's Bi Sheng or Germany's Gutenberg? The answer depends not only on historical record but also on language and perspective. We analyse eleven widely used large language models across 21 disputed inventions and discoveries, evaluated in twelve languages and 75,896 responses. While models generally acknowledge that credit is contested, query language systematically affects which claimant is surfaced. Lower-status claimants are more likely to appear when questions are asked in their associated language, whereas dominant Anglophone figures remain stable across languages. These patterns persist after controlling for response length, model differences, historical prominence, and levels of national commemoration. Language thus acts as a switch that activates different national versions of the same history, producing systematically different national memories from the same question. We interpret this as evidence that large language models function as distributed systems of cultural memory, where language conditions which histories become visible, contributing to a computational form of banal nationalism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes responses from 11 LLMs to 21 disputed inventions/discoveries posed in 12 languages (75,896 total responses). It reports that query language systematically influences which claimant is surfaced, with lower-status national figures more likely to appear in their associated language while dominant Anglophone figures remain stable; these patterns are claimed to hold after controlling for response length, model, historical prominence, and national commemoration levels. The work interprets LLMs as distributed cultural memory systems that enact a form of banal nationalism via language-conditioned history selection.
Significance. If the controls adequately isolate language's independent effect, the scale of the study (75k responses across models and languages) would provide valuable empirical evidence on how LLMs encode and surface national perspectives, with implications for AI as cultural infrastructure. The explicit framing as a measurement study of contested credit rather than a fitted model is a strength.
major comments (2)
- [Abstract] Abstract: the central claim that 'patterns persist after controlling for response length, model differences, historical prominence, and levels of national commemoration' is load-bearing for the causal interpretation that language acts as an independent 'switch,' yet no details are provided on the statistical methods, exact proxy variables for prominence and commemoration, data exclusion rules, or inter-rater reliability for response coding; without these the support for isolating language's effect cannot be assessed.
- [Abstract] The skeptic concern is warranted here: if the proxies for historical prominence and national commemoration are derived from English-centric or global sources rather than language-specific visibility metrics, they may be correlated with the independent variable (query language), leaving residual confounding that could produce the observed claimant patterns without language functioning as a causal switch.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and the potential for residual confounding. We agree that additional detail is warranted to support the central claims and will revise the abstract accordingly while preserving its length constraints. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'patterns persist after controlling for response length, model differences, historical prominence, and levels of national commemoration' is load-bearing for the causal interpretation that language acts as an independent 'switch,' yet no details are provided on the statistical methods, exact proxy variables for prominence and commemoration, data exclusion rules, or inter-rater reliability for response coding; without these the support for isolating language's effect cannot be assessed.
Authors: We agree the abstract omits these specifics, which limits assessment of the controls. The full manuscript's Methods section specifies multilevel logistic regressions with the listed covariates, proxies drawn from language-specific Wikipedia page-view counts (for prominence) and official national commemoration records (for commemoration levels), exclusion of responses naming no claimant, and manual coding with inter-rater agreement reported. To address the concern directly, we will expand the abstract with a single sentence summarizing these elements so the load-bearing claim can be evaluated from the abstract alone. revision: yes
-
Referee: [Abstract] The skeptic concern is warranted here: if the proxies for historical prominence and national commemoration are derived from English-centric or global sources rather than language-specific visibility metrics, they may be correlated with the independent variable (query language), leaving residual confounding that could produce the observed claimant patterns without language functioning as a causal switch.
Authors: We share the concern about possible correlation between proxies and query language. The manuscript employs language-specific visibility metrics (per-language Wikipedia views) and country-level commemoration data wherever available; global sources were used only as supplements for low-resource languages. We will add an explicit limitations paragraph discussing residual confounding risk and report sensitivity checks that substitute alternative proxies. This strengthens rather than undermines the language-switch interpretation but acknowledges the point. revision: partial
Circularity Check
No circularity: empirical measurement study with independent data collection
full rationale
The paper reports an empirical analysis of 75,896 LLM responses to 21 questions across 12 languages, measuring how query language correlates with claimant selection after stated controls. No equations, fitted parameters renamed as predictions, or derivation steps appear in the provided text. The central claim rests on observed response patterns rather than any self-referential definition, self-citation chain, or ansatz. This is a standard measurement study whose validity depends on the quality of controls and data, not on internal reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 21 selected inventions and discoveries constitute a representative sample of contested historical credit cases.
- domain assumption The 12 languages sufficiently capture national identity perspectives relevant to the claimants.
Reference graph
Works this paper leans on
-
[1]
(2025) Language models' factuality depends on the language of inquiry
Aggarwal T, Tanmay K, Agrawal A et al. (2025) Language models' factuality depends on the language of inquiry. In: International Conference on Learning Representations (ICLR) 2025. https://arxiv.org/abs/2502.17955
arXiv 2025
-
[2]
Verso, London
Anderson B (1991) Imagined Communities: Reflections on the Origin and Spread of Nationalism, revised edn. Verso, London
1991
-
[3]
Assmann J, Czaplicka J (1995) Collective memory and cultural identity. New Ger Crit 65:125 to 133. https://doi.org/10.2307/488538
-
[4]
Sage, London
Billig M (1995) Banal Nationalism. Sage, London
1995
-
[5]
Blodgett SL, Barocas S, Daum\'e III H, Wallach H (2020) Language (technology) is power: a critical survey of ``bias'' in NLP. In: Proceedings of ACL 2020, pp 5454 to 5476. https://doi.org/10.18653/v1/2020.acl-main.485
-
[6]
Cambridge University Press, Cambridge
Brubaker R (1996) Nationalism Reframed: Nationhood and the National Question in the New Europe. Cambridge University Press, Cambridge
1996
-
[7]
(2026) Large language models reflect the ideology of their creators
Buyl M, Rogiers A, Noels S et al. (2026) Large language models reflect the ideology of their creators. npj Artif Intell 2:7. https://doi.org/10.1038/s44387-025-00048-0
-
[8]
(2025) Taxonomizing representational harms using speech act theory
Corvi E, Washington H, Reed S et al. (2025) Taxonomizing representational harms using speech act theory. In: Findings of the Association for Computational Linguistics: ACL 2025. https://doi.org/10.18653/v1/2025.findings-acl.202
-
[9]
(2022) On measures of biases and harms in NLP
Dev S, Sheng E, Zhao J et al. (2022) On measures of biases and harms in NLP. In: Findings of AACL-IJCNLP 2022, pp 246 to 267. https://doi.org/10.18653/v1/2022.findings-aacl.24
-
[10]
(2024) Towards measuring the representation of subjective global opinions in language models
Durmus E, Nguyen K, Liao T et al. (2024) Towards measuring the representation of subjective global opinions in language models. In: Conference on Language Modeling (COLM) 2024. https://arxiv.org/abs/2306.16388
Pith/arXiv arXiv 2024
-
[11]
Edgerton D (2007) The contradictions of techno-nationalism and techno-globalism: a historical perspective. New Glob Stud 1(1):1 to 32. https://doi.org/10.2202/1940-0004.1013
-
[12]
Oxford University Press, Oxford
Fricker M (2007) Epistemic Injustice: Power and the Ethics of Knowing. Oxford University Press, Oxford
2007
-
[13]
Gallegos IO, Rossi RA, Barrow J et al. (2024) Bias and fairness in large language models: a survey. Comput Linguist 50(3):1097 to 1179. https://doi.org/10.1162/coli_a_00524
-
[14]
Princeton University Press, Princeton
Gillis JR (ed) (1994) Commemorations: The Politics of National Identity. Princeton University Press, Princeton
1994
-
[15]
University of Chicago Press, Chicago
Halbwachs M (1992) On Collective Memory (Coser LA, ed and trans). University of Chicago Press, Chicago
1992
-
[16]
Cambridge University Press, Cambridge
Hobsbawm E, Ranger T (eds) (1983) The Invention of Tradition. Cambridge University Press, Cambridge
1983
-
[17]
Routledge, London
Hutchins RD (2016) Nationalism and History Education: Curricula and Textbooks in the United States and France. Routledge, London
2016
-
[18]
BBC Books and Chatto & Windus, London
Ignatieff M (1993) Blood and Belonging: Journeys into the New Nationalism. BBC Books and Chatto & Windus, London
1993
-
[19]
(2020) The state and fate of linguistic diversity and inclusion in the NLP world
Joshi P, Santy S, Budhiraja A et al. (2020) The state and fate of linguistic diversity and inclusion in the NLP world. In: Proceedings of ACL 2020, pp 6282 to 6293. https://doi.org/10.18653/v1/2020.acl-main.560
-
[20]
Kastoryano R (2025) Transnational nationalisms: reflections on nationalism and territory in globalization. Nations Natl. https://doi.org/10.1111/nana.13125
-
[21]
Benchmarking Cognitive Biases in Large Language Models as Evaluators
Koo R, Lee M, Raheja V et al. (2024) Benchmarking cognitive biases in large language models as evaluators. In: Findings of the Association for Computational Linguistics: ACL 2024, pp 517 to 545. https://doi.org/10.18653/v1/2024.findings-acl.29
-
[22]
From Generation to Judgment: Opportunities and Challenges of LLM -as-a-judge
Li D, Jiang B, Huang L et al. (2025) From generation to judgment: opportunities and challenges of LLM-as-a-judge. In: Proceedings of EMNLP 2025, pp 2757 to 2791. https://doi.org/10.18653/v1/2025.emnlp-main.138
-
[23]
G-eval: NLG evaluation using gpt-4 with better human alignment
Liu Y, Iter D, Xu Y et al. (2023) G-Eval: NLG evaluation using GPT-4 with better human alignment. In: Proceedings of EMNLP 2023, pp 2511 to 2522. https://doi.org/10.18653/v1/2023.emnlp-main.153
-
[24]
Am Sociol Rev 22(6):635 to 659
Merton RK (1957) Priorities in scientific discovery: a chapter in the sociology of science. Am Sociol Rev 22(6):635 to 659. https://doi.org/10.2307/2089193
-
[25]
Proc Am Philos Soc 105(5):470 to 486
Merton RK (1961) Singletons and multiples in scientific discovery: a chapter in the sociology of science. Proc Am Philos Soc 105(5):470 to 486. https://www.jstor.org/stable/985546
1961
-
[26]
Duke University Press, Durham
Mignolo WD (2011) The Darker Side of Western Modernity: Global Futures, Decolonial Options. Duke University Press, Durham
2011
-
[27]
(2024) BLEnD: a benchmark for LLMs on everyday knowledge in diverse cultures and languages
Myung J, Lee N, Zhou Y et al. (2024) BLEnD: a benchmark for LLMs on everyday knowledge in diverse cultures and languages. In: Advances in Neural Information Processing Systems 37, Datasets and Benchmarks Track. https://arxiv.org/abs/2406.09948
arXiv 2024
-
[28]
Having Beer after Prayer? Measuring Cultural Bias in Large Language Models
Naous T, Ryan MJ, Ritter A, Xu W (2024) Having beer after prayer? Measuring cultural bias in large language models. In: Proceedings of ACL 2024, pp 16366 to 16393. https://doi.org/10.18653/v1/2024.acl-long.862
-
[29]
Nora P (1989) Between memory and history: les lieux de m\'emoire. Representations 26:7 to 24. https://doi.org/10.2307/2928520
-
[30]
In: Advances in Neural Information Processing Systems 37
Panickssery A, Bowman SR, Feng S (2024) LLM evaluators recognize and favor their own generations. In: Advances in Neural Information Processing Systems 37. https://arxiv.org/abs/2404.13076
Pith/arXiv arXiv 2024
-
[31]
Washington, DC, 24 February 2026
Pew Research Center (2026) How teens use and view AI. Washington, DC, 24 February 2026. https://www.pewresearch.org/internet/2026/02/24/how-teens-use-and-view-ai/
2026
-
[32]
In: Proceedings of EMNLP 2023, pp 10650 to 10666
Qi J, Fern\'andez R, Bisazza A (2023) Cross-lingual consistency of factual knowledge in multilingual language models. In: Proceedings of EMNLP 2023, pp 10650 to 10666. https://doi.org/10.18653/v1/2023.emnlp-main.658
-
[33]
(2023) Whose opinions do language models reflect? In: Proceedings of ICML 2023, PMLR 202
Santurkar S, Durmus E, Ladhak F et al. (2023) Whose opinions do language models reflect? In: Proceedings of ICML 2023, PMLR 202. https://proceedings.mlr.press/v202/santurkar23a.html
2023
-
[34]
Paradigm Publishers, Boulder
de Sousa Santos B (2014) Epistemologies of the South: Justice Against Epistemicide. Paradigm Publishers, Boulder
2014
-
[35]
Trans N Y Acad Sci 39(1):147 to 157
Stigler SM (1980) Stigler's law of eponymy. Trans N Y Acad Sci 39(1):147 to 157. https://doi.org/10.1111/j.2164-0947.1980.tb02775.x
-
[36]
S\"usskind C (1962) Popov and the beginnings of radiotelegraphy. Proc IRE 50(10):2036 to 2047. https://doi.org/10.1109/JRPROC.1962.288232
-
[37]
Tao Y, Viberg O, Baker RS, Kizilcec RF (2024) Cultural bias and cultural alignment of large language models. PNAS Nexus 3(9):pgae346. https://doi.org/10.1093/pnasnexus/pgae346
-
[38]
https://www.congress.gov/bill/107th-congress/house-resolution/269/text
US House of Representatives (2002) H.Res.269, 107th Congress: honoring Antonio Meucci and his work in the invention of the telephone. https://www.congress.gov/bill/107th-congress/house-resolution/269/text
2002
-
[39]
Large Language Models are not Fair Evaluators
Wang P, Li L, Chen L et al. (2024) Large language models are not fair evaluators. In: Proceedings of ACL 2024, pp 9440 to 9450. https://doi.org/10.18653/v1/2024.acl-long.511
-
[40]
Knowledge conflicts for llms: A survey,
Xu R, Qi Z, Guo Z et al. (2024) Knowledge conflicts for LLMs: a survey. In: Proceedings of EMNLP 2024, pp 8541 to 8565. https://doi.org/10.18653/v1/2024.emnlp-main.486
-
[41]
(2023) Judging LLM-as-a-judge with MT-Bench and Chatbot Arena
Zheng L, Chiang W-L, Sheng Y et al. (2023) Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. In: Advances in Neural Information Processing Systems 36, Datasets and Benchmarks Track. https://arxiv.org/abs/2306.05685
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.