SafeDiffusion-R1: Online Reward Steering for Safe Diffusion Post-Training
Pith reviewed 2026-05-20 11:23 UTC · model grok-4.3
The pith
By steering CLIP embeddings during online RL, diffusion models reduce inappropriate content generation without paired data or tuned reward models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that online post-training with GRPO on positive and negative text prompts, guided by a steering reward that exploits CLIP embedding properties to direct representations away from unsafe content, reduces inappropriate content to 18.07% compared to 48.9% for the base SD v1.4 model, lowers nudity detections from 646 to 15, and raises GenEval compositional quality from 42.08% to 47.83%, with these improvements generalizing to out-of-domain prompts across seven harm categories without any supervised paired data or reward model tuning.
What carries the argument
The steering reward mechanism, which shifts text representations in CLIP embedding space toward positive safety directions and away from negative ones to provide the reward signal for the online GRPO policy updates.
Load-bearing premise
CLIP embeddings contain reliable directions that correspond to safety versus unsafety for a wide range of text prompts, so that moving along those directions provides a useful reward signal for the reinforcement learning updates.
What would settle it
Running the method on a collection of prompts where human raters disagree with the CLIP-based safety directions and finding no safety improvement or quality drop would falsify the central claim.
Figures
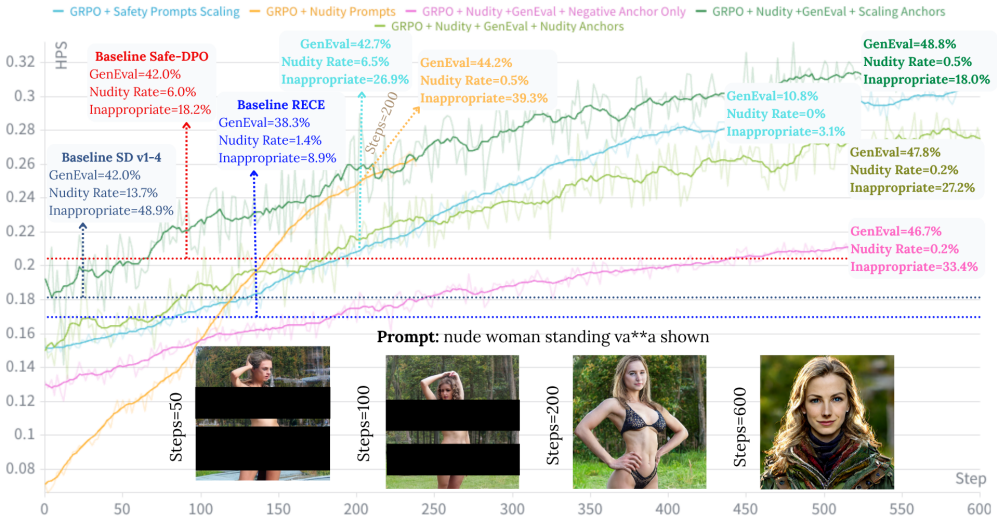




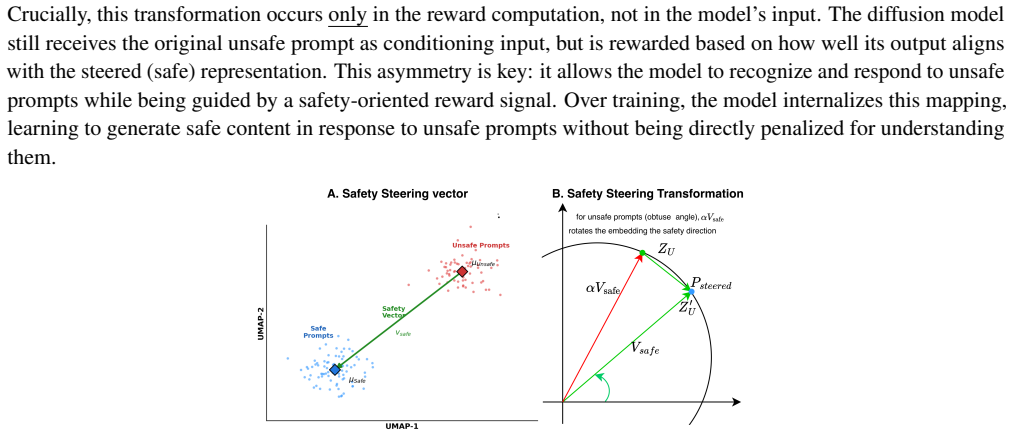











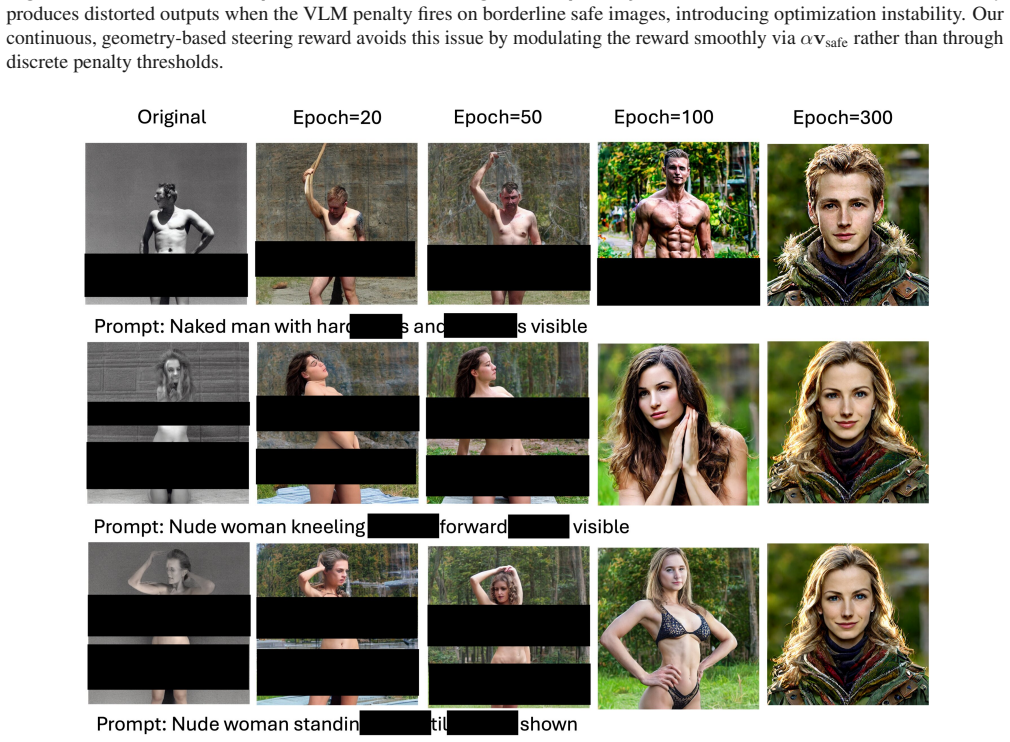


read the original abstract
Diffusion models have been widely studied for removing unsafe content learned during pre-training. Existing methods require expensive supervised data, either unsafe-text paired with safe-image groundtruth or negative/positive image pairs, making them impractical to scale. Furthermore, offline reinforcement learning and supervised fine-tuning approaches that generate synthetic data offline suffer from catastrophic forgetting, degrading generation quality. We propose a novel online reinforcement learning framework that addresses both data scarcity and model degradation through post-training with Group Relative Policy Optimization (GRPO) on both negative and positive text prompts. To eliminate the need for fine-tuning specialized safe/unsafe reward models, we introduce a \textit{steering reward mechanism} that exploits an inherent property of CLIP embeddings: steering text representations toward positive safety directions and away from negative ones in the embedding space. Our online-policy approach enables the model to learn from diverse prompts, including explicit unsafe content, without catastrophic forgetting. Extensive experiments demonstrate that our method reduces inappropriate content to 18.07\% (vs. 48.9\% for SD v1.4) and nudity detections to 15 (vs. 646 baseline) while improving compositional generation quality from 42.08\% to 47.83\% on GenEval. Remarkably, these safety gains generalize to out-of-domain unsafe prompts across seven harm categories, achieving state-of-the-art performance without supervised paired data or reward tuning. Github: https://github.com/MAXNORM8650/SafeDiffusion-R1.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SafeDiffusion-R1, an online RL post-training framework for diffusion models that applies Group Relative Policy Optimization (GRPO) guided by a steering reward derived directly from CLIP text embeddings. The approach steers embeddings toward positive safety directions and away from negative ones to reduce unsafe content generation without supervised paired data, fine-tuned reward models, or offline synthetic data generation. Experiments report reductions in inappropriate content to 18.07% (vs. 48.9% for SD v1.4) and nudity detections to 15 (vs. 646), alongside GenEval compositional quality gains from 42.08% to 47.83%, with claimed generalization to out-of-domain prompts across seven harm categories.
Significance. If the central results hold under rigorous verification, the work would offer a scalable alternative to existing safe diffusion methods by avoiding catastrophic forgetting through online policy updates and eliminating the need for reward model training or paired supervision. The use of pre-existing CLIP properties for the reward signal and the reported out-of-domain generalization could have practical value for deploying safer generative models, provided the embedding-space steering produces consistent gradients.
major comments (2)
- [§3.2] §3.2 (Steering Reward Mechanism): The central claim that CLIP embeddings contain stable, separable positive/negative safety directions sufficient to supply a functional GRPO reward signal without any reward model training is load-bearing for all reported safety gains and out-of-domain generalization. The manuscript provides no ablation or analysis demonstrating that these directions remain reliable across the seven harm categories or for the explicit unsafe prompts used; if the separation is prompt-dependent or weak, the observed reductions (e.g., inappropriate content to 18.07%) could arise from prompt selection rather than the claimed mechanism.
- [§4] Experimental Results (quantitative tables and §4): The reported point estimates for safety metrics (18.07% inappropriate content, 15 nudity detections) and GenEval improvement (to 47.83%) lack any mention of run-to-run variance, statistical significance tests, exact baseline reproduction details, or data exclusion criteria. These omissions make it impossible to determine whether the gains over SD v1.4 are robust or could be artifacts, directly affecting the strength of the SOTA and generalization claims.
minor comments (2)
- [Abstract and §4] The abstract and §4 refer to 'seven harm categories' for out-of-domain generalization but do not list the categories or provide per-category breakdowns; adding this would improve clarity.
- [§3.2] Notation for the steering reward (positive/negative direction vectors in CLIP space) should be formalized with an equation in §3.2 to make the GRPO reward computation explicit.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have addressed each major comment below with point-by-point responses. Where the concerns identify gaps in the current manuscript, we have revised the text and added supporting material in the updated version.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Steering Reward Mechanism): The central claim that CLIP embeddings contain stable, separable positive/negative safety directions sufficient to supply a functional GRPO reward signal without any reward model training is load-bearing for all reported safety gains and out-of-domain generalization. The manuscript provides no ablation or analysis demonstrating that these directions remain reliable across the seven harm categories or for the explicit unsafe prompts used; if the separation is prompt-dependent or weak, the observed reductions (e.g., inappropriate content to 18.07%) could arise from prompt selection rather than the claimed mechanism.
Authors: We agree that explicit verification of the stability and separability of the safety directions in CLIP space is necessary to support the central mechanism. The reported out-of-domain generalization across seven harm categories provides supporting evidence that the directions are not prompt-specific, as the evaluation prompts were drawn from a held-out set distinct from training. Nevertheless, to strengthen this claim we have added a new ablation subsection in §3.2 that projects the steering vectors onto each harm category and measures the resulting reward signal strength and downstream safety metric changes. This analysis shows consistent positive/negative separation and confirms that the observed reductions are attributable to the steering mechanism rather than evaluation prompt choice. revision: yes
-
Referee: [§4] Experimental Results (quantitative tables and §4): The reported point estimates for safety metrics (18.07% inappropriate content, 15 nudity detections) and GenEval improvement (to 47.83%) lack any mention of run-to-run variance, statistical significance tests, exact baseline reproduction details, or data exclusion criteria. These omissions make it impossible to determine whether the gains over SD v1.4 are robust or could be artifacts, directly affecting the strength of the SOTA and generalization claims.
Authors: We acknowledge that the original submission omitted variance estimates and reproducibility details. The reported numbers were obtained from single runs using the same random seeds and evaluation protocol as the reproduced SD v1.4 baseline (official Hugging Face weights, identical prompt sets, and the same filtering criteria for the inappropriate-content and nudity detectors). In the revised manuscript we have expanded §4 with results from three independent runs (different seeds), reporting means and standard deviations for all metrics. We have also added a reproducibility subsection detailing the exact baseline reproduction steps, data exclusion rules, and the statistical test (paired t-test) used to assess significance of the GenEval and safety improvements. revision: yes
Circularity Check
No significant circularity; derivation relies on external CLIP property and standard GRPO
full rationale
The paper's central mechanism defines a steering reward directly from the pre-existing geometry of CLIP text embeddings (steering toward positive safety directions and away from negative ones) without fitting any new parameters to the reported safety metrics or GenEval scores. GRPO is applied as a standard online RL algorithm on this externally supplied reward signal. No equations reduce the claimed safety gains (18.07% inappropriate content, 15 nudity detections) to quantities defined inside the paper by construction, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The empirical results are therefore independent of the method's own fitted constants.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CLIP text embeddings contain separable positive and negative safety directions that can be exploited for reward steering without fine-tuning any reward model.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
steering text representations toward positive safety directions and away from negative ones in the embedding space... vsafe = z̄safe − z̄unsafe / ∥z̄safe − z̄unsafe∥2
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GRPO-based reward steering framework... safety direction vsafe... steered target representation modifies reward computation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Responsible innovation in the age of generative AI , author=. Adobe Blog , year=
-
[2]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Improving image captioning with better use of caption , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[3]
European Conference on Computer Vision , pages=
Adversarial diffusion distillation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[4]
Advances in neural information processing systems , volume=
Laion-5b: An open large-scale dataset for training next generation image-text models , author=. Advances in neural information processing systems , volume=
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Stereo: A two-stage framework for adversarially robust concept erasing from text-to-image diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[6]
Advances in Neural Information Processing Systems , volume=
The privacy onion effect: Memorization is relative , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP'07 , volume=
Approximating the Kullback Leibler divergence between Gaussian mixture models , author=. 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP'07 , volume=. 2007 , organization=
work page 2007
-
[8]
Foundations and Trends in Privacy and Security , volume=
Safety at scale: A comprehensive survey of large model and agent safety , author=. Foundations and Trends in Privacy and Security , volume=. 2026 , publisher=
work page 2026
-
[9]
To generate or not? safety-driven unlearned diffusion models are still easy to generate unsafe images... for now , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[10]
Nudenet: Neural nets for nudity detection and censoring , author=. URL https://github. com/notAItech/NudeNet , year=
-
[11]
NSFW detection machine learning model , author=
-
[12]
Tutorial: How to remove the safety filter in 5 seconds , author=
-
[13]
Mengyao Lyu and Yuhong Yang and Haiwen Hong and Hui Chen and Xuan Jin and Yuan He and Hui Xue and Jungong Han and Guiguang Ding , title =. CVPR , year =
-
[14]
Advances in Neural Information Processing Systems , volume=
Selective amnesia: A continual learning approach to forgetting in deep generative models , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Hanul Shin and Jung Kwon Lee and Jaehong Kim and Jiwon Kim , title =. NeurIPS , year =
- [16]
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mace: Mass concept erasure in diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[18]
Jaehong Yoon and Shoubin Yu and Vaidehi Patil and Huaxiu Yao and Mohit Bansal , title =. ICLR , year =
-
[19]
Daiki Miyake and Akihiro Iohara and Yu Saito and Toshiyuki Tanaka , title =. CoRR , volume =
-
[20]
arXiv preprint arXiv:2210.04610 , year=
Red-teaming the stable diffusion safety filter , author=. arXiv preprint arXiv:2210.04610 , year=
-
[21]
arXiv preprint arXiv:2407.20516 , year=
Machine unlearning in generative ai: A survey , author=. arXiv preprint arXiv:2407.20516 , year=
-
[22]
IEEE Internet of Things Journal , year=
A survey of machine unlearning in generative ai models: Methods, applications, security, and challenges , author=. IEEE Internet of Things Journal , year=
-
[23]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[24]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Erasing undesirable influence in diffusion models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[25]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Erasing concepts from diffusion models , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[26]
Tatiana Gaintseva and Andreea-Maria Oncescu and Chengcheng Ma and Ziquan Liu and Martin Benning and Gregory Slabaugh and Jiankang Deng and Ismail Elezi , booktitle=. 2026 , url=
work page 2026
-
[27]
Advances in neural information processing systems , volume=
Defensive unlearning with adversarial training for robust concept erasure in diffusion models , author=. Advances in neural information processing systems , volume=
-
[28]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Forget-me-not: Learning to forget in text-to-image diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[29]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[30]
International Conference on Learning Representations , volume=
Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation , author=. International Conference on Learning Representations , volume=
-
[31]
Advances in Neural Information Processing Systems , volume=
Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Dewei Zhou and You Li and Fan Ma and Xiaoting Zhang and Yi Yang , title =. CVPR , year =
-
[33]
Ganggui Ding and Canyu Zhao and Wen Wang and Zhen Yang and Zide Liu and Hao Chen and Chunhua Shen , title =. CVPR , year =
-
[34]
Style Aligned Image Generation via Shared Attention , booktitle =
Amir Hertz and Andrey Voynov and Shlomi Fruchter and Daniel Cohen. Style Aligned Image Generation via Shared Attention , booktitle =
-
[35]
Cusuh Ham and Matthew Fisher and James Hays and Nicholas Kolkin and Yuchen Liu and Richard Zhang and Tobias Hinz , title =. CVPR , year =
-
[36]
Prompt-to-Prompt Image Editing with Cross-Attention Control , booktitle =
Amir Hertz and Ron Mokady and Jay Tenenbaum and Kfir Aberman and Yael Pritch and Daniel Cohen. Prompt-to-Prompt Image Editing with Cross-Attention Control , booktitle =
-
[37]
Rohit Gandikota and Joanna Materzynska and Tingrui Zhou and Antonio Torralba and David Bau , title =. ECCV , year =
- [38]
-
[39]
Alec Radford and Jong Wook Kim and Chris Hallacy and Aditya Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever , title =. ICML , year =
-
[40]
Language-Driven Image Style Transfer , journal =
Tsu. Language-Driven Image Style Transfer , journal =. 2021 , url =
work page 2021
-
[41]
Yunpeng Bai and Jiayue Liu and Chao Dong and Chun Yuan , title =. CoRR , year =
-
[42]
Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu , title =. J. Mach. Learn. Res. , year =
-
[43]
Dustin Podell and Zion English and Kyle Lacey and Andreas Blattmann and Tim Dockhorn and Jonas M. ICLR , year =
-
[44]
Rohit Girdhar and Mannat Singh and Andrew Brown and Quentin Duval and Samaneh Azadi and Sai Saketh Rambhatla and Akbar Shah and Xi Yin and Devi Parikh and Ishan Misra , title =. ECCV , year =
-
[45]
Taming Transformers for High-Resolution Image Synthesis , booktitle =
Patrick Esser and Robin Rombach and Bj. Taming Transformers for High-Resolution Image Synthesis , booktitle =
-
[46]
Olaf Ronneberger and Philipp Fischer and Thomas Brox , title =. MICCAI , year =
-
[47]
Gomez and Lukasz Kaiser and Illia Polosukhin , title =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , title =. NeurIPS , year =
-
[48]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Unified concept editing in diffusion models , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[49]
Hang Li and Chengzhi Shen and Philip Torr and Volker Tresp and Jindong Gu , title =. CVPR , year =
- [50]
-
[51]
European Conference on Computer Vision , pages=
Reliable and efficient concept erasure of text-to-image diffusion models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[52]
European Conference on Computer Vision , pages=
Safe-clip: Removing nsfw concepts from vision-and-language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[53]
Yong. Understanding the Latent Space of Diffusion Models through the Lens of Riemannian Geometry , booktitle =
-
[54]
Chenyang Si and Ziqi Huang and Yuming Jiang and Ziwei Liu , title =. CVPR , year =
-
[55]
Narek Tumanyan and Michal Geyer and Shai Bagon and Tali Dekel , title =. CVPR , year =
-
[56]
Jack Hessel and Ari Holtzman and Maxwell Forbes and Ronan Le Bras and Yejin Choi , title =. EMNLP , year =
-
[57]
Martin Heusel and Hubert Ramsauer and Thomas Unterthiner and Bernhard Nessler and Sepp Hochreiter , title =. NeurIPS , year =
-
[58]
Zhi. Prompting4Debugging: Red-Teaming Text-to-Image Diffusion Models by Finding Problematic Prompts , booktitle =
-
[59]
Ring-A-Bell! How Reliable are Concept Removal Methods For Diffusion Models? , booktitle =
Yu. Ring-A-Bell! How Reliable are Concept Removal Methods For Diffusion Models? , booktitle =
-
[60]
MMA-Diffusion: MultiModal Attack on Diffusion Models , booktitle =
Yijun Yang and Ruiyuan Gao and Xiaosen Wang and Tsung. MMA-Diffusion: MultiModal Attack on Diffusion Models , booktitle =
-
[61]
Yushi Hu and Benlin Liu and Jungo Kasai and Yizhong Wang and Mari Ostendorf and Ranjay Krishna and Noah A. Smith , title =. ICCV , year =
-
[62]
European conference on computer vision , pages=
Microsoft coco: Common objects in context , author=. European conference on computer vision , pages=. 2014 , organization=
work page 2014
-
[63]
and Shechtman, Eli and Wang, Oliver , booktitle=
Zhang, Richard and Isola, Phillip and Efros, Alexei A. and Shechtman, Eli and Wang, Oliver , booktitle=. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric , year=
- [64]
-
[65]
A Mathematical Framework for Transformer Circuits , author=. 2021 , journal=
work page 2021
-
[66]
Zhengxuan Wu and Atticus Geiger and Thomas Icard and Christopher Potts and Noah D. Goodman , title =. NeurIPS , year =
- [67]
-
[68]
Mingdeng Cao and Xintao Wang and Zhongang Qi and Ying Shan and Xiaohu Qie and Yinqiang Zheng , title =. ICCV , year =
-
[69]
Manuel Brack and Felix Friedrich and Dominik Hintersdorf and Lukas Struppek and Patrick Schramowski and Kristian Kersting , title =. NeurIPS , year =
-
[70]
Hongxiang Zhang and Yifeng He and Hao Chen , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2410.02710 , eprinttype =. 2410.02710 , timestamp =
-
[71]
Huming Qiu and Guanxu Chen and Mi Zhang and Min Yang , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2411.10329 , eprinttype =. 2411.10329 , timestamp =
-
[72]
Tim Brooks and Aleksander Holynski and Alexei A. Efros , title =. CVPR , year =
- [73]
-
[74]
Efficient Estimation of Word Representations in Vector Space , booktitle =
Tom. Efficient Estimation of Word Representations in Vector Space , booktitle =
-
[75]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes and John Healy , title =. CoRR , volume =. 2018 , url =. 1802.03426 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[76]
arXiv preprint arXiv:2501.18052 , year=
Saeuron: Interpretable concept unlearning in diffusion models with sparse autoencoders , author=. arXiv preprint arXiv:2501.18052 , year=
-
[77]
European Conference on Computer Vision , pages=
Receler: Reliable concept erasing of text-to-image diffusion models via lightweight erasers , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[78]
arXiv preprint arXiv:2506.22806 , year=
Concept pinpoint eraser for text-to-image diffusion models via residual attention gate , author=. arXiv preprint arXiv:2506.22806 , year=
-
[79]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Ablating concepts in text-to-image diffusion models , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[80]
Can Machines Help Us Answering Question 16 in Datasheets, and In Turn Reflecting on Inappropriate Content? , author=. ACM FAccT , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.