From Efficiency to Leakage -- Privacy Backdoor in Federated Language Model Fine-Tuning
Pith reviewed 2026-06-26 16:48 UTC · model grok-4.3
The pith
A malicious federated server can corrupt PEFT adapters into backdoors that memorize and reconstruct up to 79 percent of client fine-tuning samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
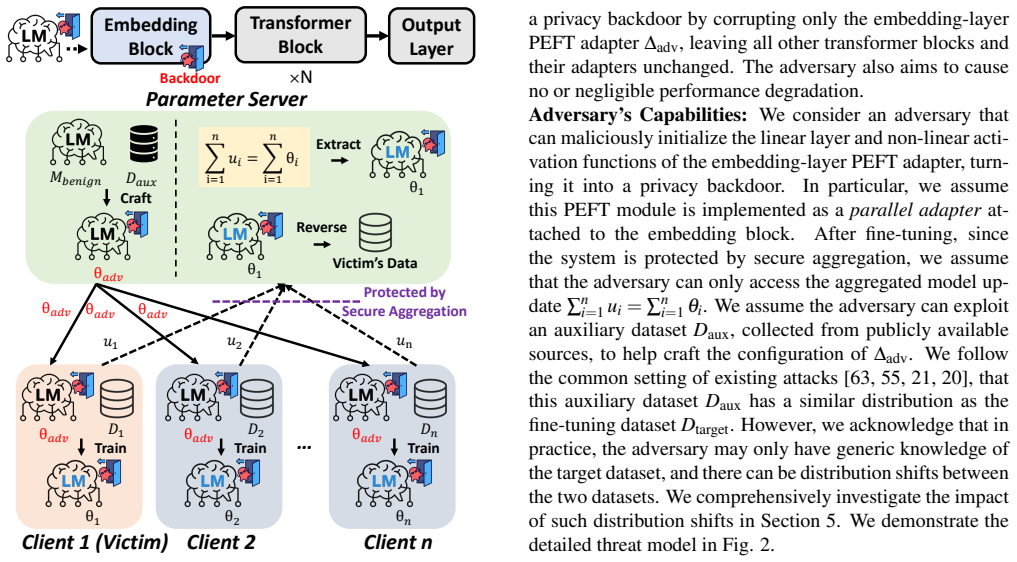
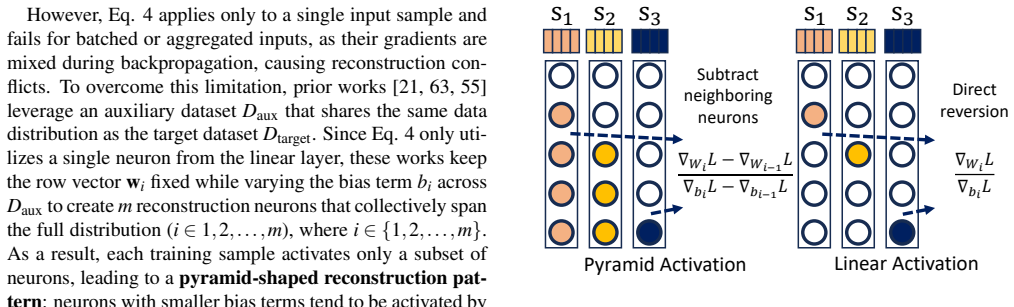
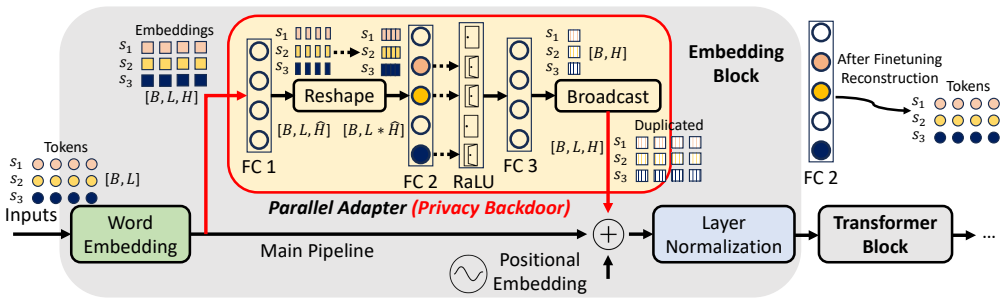
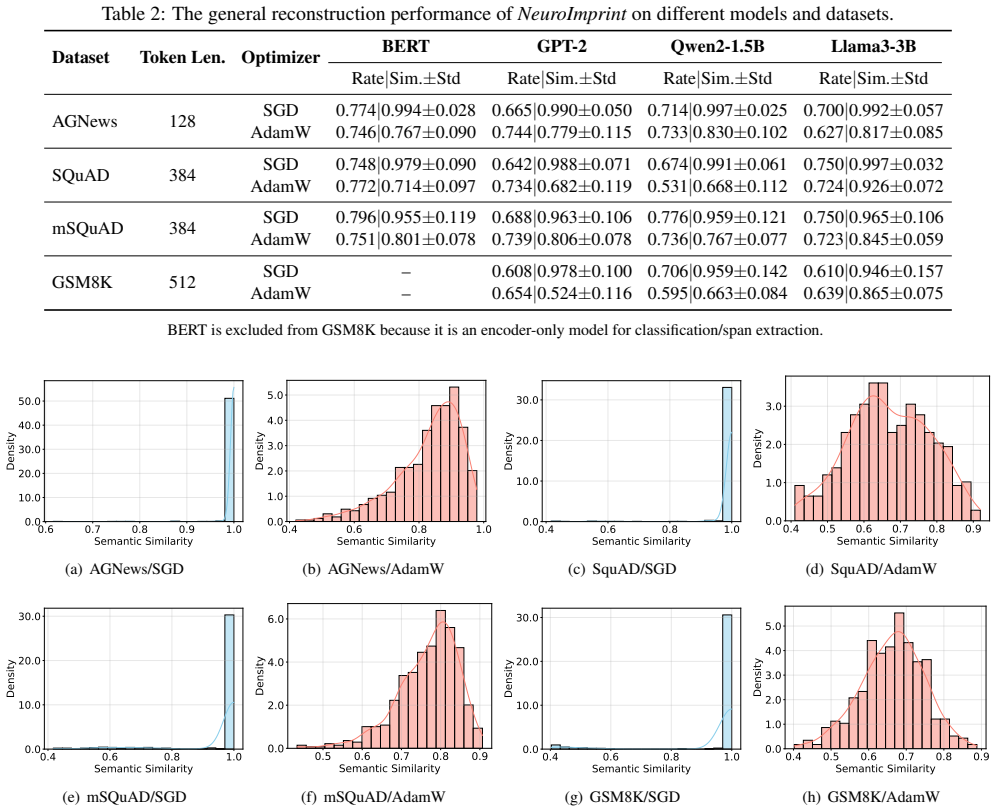
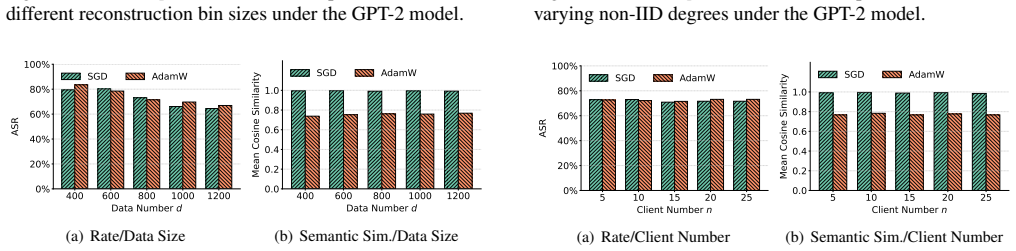
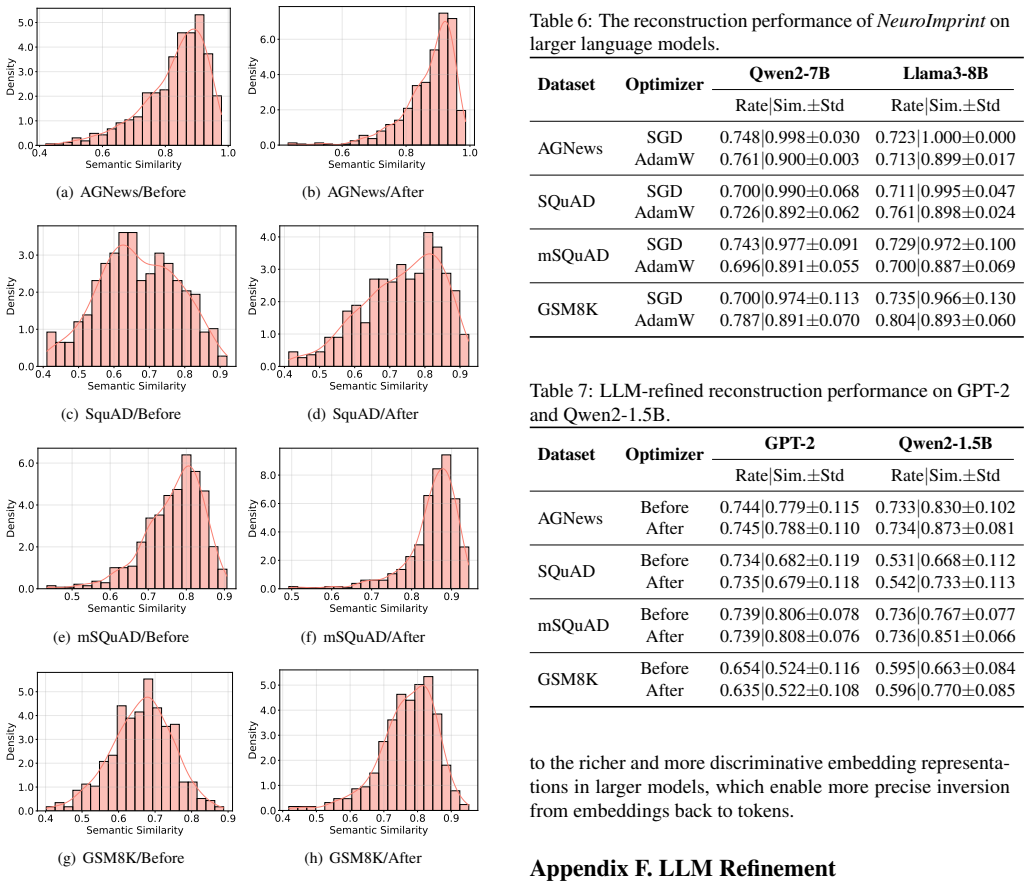
NeuroImprint assigns a dedicated memorization neuron to each training sample and constrains that each neuron is updated at most once along the local fine-tuning trajectory. This design mitigates both cross-sample collisions and cross-step mixing introduced by large local batches and stateful optimizers. After fine-tuning, the resulting isolated per-sample updates can be analytically inverted in closed form to recover text embeddings, which are then deterministically mapped back to token sequences.
What carries the argument
NeuroImprint attack that stores each sample as an isolated per-sample parameter update in a dedicated memorization neuron, updated at most once during local fine-tuning.
If this is right
- The attack applies unchanged to BERT, GPT-2, Qwen2, and Llama3.2.
- Recovery rates of 59 to 79 percent hold across four fine-tuning datasets from different domains.
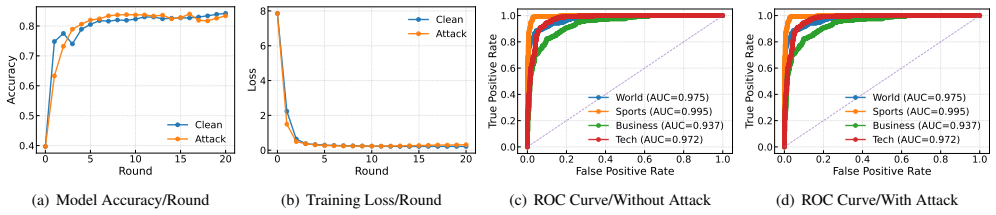
- Model utility remains intact while the backdoor is active.
- The same neuron-isolation technique works for both adapter-based and other parameter-efficient methods.
Where Pith is reading between the lines
- The same isolation trick could be adapted to full fine-tuning if the server can still control which weights receive single updates.
- Detection might require clients to monitor per-neuron activation patterns that deviate from normal training dynamics.
- Future defenses could add noise to each local update step to break the closed-form invertibility.
Load-bearing premise
The rule that each memorization neuron is updated at most once prevents mixing from batches or optimizers and keeps the per-sample updates separable for later inversion.
What would settle it
A run on the same models and datasets where each neuron is allowed to be updated more than once or where batch size is increased shows reconstruction rate falling below 20 percent.
Figures



read the original abstract
Federated learning (FL) enables multiple parties to collaboratively fine-tune language models for domain-specific tasks without sharing raw data. Since full model fine-tuning is often prohibitively expensive for FL clients, parameter-efficient fine-tuning (PEFT) has become the de facto approach in practice, freezing the base model and training only a small set of adapters. In this paper, we show that a malicious parameter server can stealthily corrupt a PEFT adapter into a privacy backdoor that implicitly memorizes the client's training samples as isolated per-sample parameter updates stored in separate neurons, without degrading model utility. Concretely, our attack, NeuroImprint, assigns a dedicated memorization neuron to each training sample and constrains that each neuron is updated at most once along the local fine-tuning trajectory. This design mitigates both cross-sample collisions and cross-step mixing introduced by large local batches and stateful optimizers (e.g., Adam/AdamW) in language-model fine-tuning. After fine-tuning, the resulting isolated per-sample updates can be analytically inverted in closed form to recover text embeddings, which are then deterministically mapped back to token sequences. To understand the generality of our method, we implemented NeuroImprint on multiple language models (BERT, GPT-2, Qwen2, and Llama3.2) and evaluated it across four fine-tuning datasets spanning diverse domains. The results demonstrate that our attack can reconstruct 59% to 79% of all finetuning samples with high semantic fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NeuroImprint, a privacy backdoor attack on federated parameter-efficient fine-tuning (PEFT) of language models. A malicious server injects dedicated 'memorization neurons' into the adapter such that each training sample produces an isolated per-sample parameter update (enforced by updating each neuron at most once). After local fine-tuning, these updates are analytically inverted in closed form from the final adapter weights to recover token sequences, achieving 59-79% reconstruction rates with high semantic fidelity. The attack is evaluated on BERT, GPT-2, Qwen2, and Llama3.2 across four datasets without degrading utility.
Significance. If the isolation mechanism is shown to survive realistic client-side batching and optimizers, the result identifies a previously under-appreciated privacy risk in PEFT-based federated learning: adapters can be turned into stealthy memorization backdoors. The multi-model, multi-dataset evaluation supports generality, and the closed-form inversion is a concrete, falsifiable contribution that could motivate new defenses or auditing requirements for FL adapters.
major comments (2)
- [NeuroImprint design description] The NeuroImprint design (abstract and method description): the claim that constraining each memorization neuron to be updated at most once 'mitigates both cross-sample collisions and cross-step mixing introduced by large local batches and stateful optimizers (e.g., Adam/AdamW)' lacks any equation, pseudocode, or diagram showing how the PEFT adapter implements sample-specific routing that prevents gradient averaging over a batch. Without this, the closed-form inversion recovers a linear combination rather than an isolated embedding, directly undermining the 59-79% fidelity numbers.
- [Evaluation] Evaluation (abstract and results): reconstruction rates of 59-79% are reported without baselines (e.g., random or non-backdoored adapters), exact inversion procedure details, statistical significance, or ablation on batch size/optimizer, leaving moderate empirical support for the central reconstruction claim.
minor comments (1)
- [Abstract] The abstract and method would benefit from an explicit threat model diagram or table clarifying server vs. client capabilities and when the backdoor is injected.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will revise the manuscript accordingly to improve clarity and empirical support.
read point-by-point responses
-
Referee: [NeuroImprint design description] The NeuroImprint design (abstract and method description): the claim that constraining each memorization neuron to be updated at most once 'mitigates both cross-sample collisions and cross-step mixing introduced by large local batches and stateful optimizers (e.g., Adam/AdamW)' lacks any equation, pseudocode, or diagram showing how the PEFT adapter implements sample-specific routing that prevents gradient averaging over a batch. Without this, the closed-form inversion recovers a linear combination rather than an isolated embedding, directly undermining the 59-79% fidelity numbers.
Authors: We agree that the manuscript would benefit from explicit implementation details to substantiate the isolation claim. The per-sample neuron assignment is realized by dynamically routing each training sample to a dedicated adapter neuron (via a sample-indexed mask) and enforcing a single-update constraint by zeroing gradients for that neuron after its first use. This prevents both intra-batch averaging and optimizer state mixing. We will add the corresponding equations for the masked update rule, pseudocode for the modified local training loop, and a diagram of the adapter routing mechanism in the revised method section. revision: yes
-
Referee: [Evaluation] Evaluation (abstract and results): reconstruction rates of 59-79% are reported without baselines (e.g., random or non-backdoored adapters), exact inversion procedure details, statistical significance, or ablation on batch size/optimizer, leaving moderate empirical support for the central reconstruction claim.
Authors: We acknowledge the need for stronger empirical grounding. The current rates reflect experiments under standard FL settings (batch size 8, AdamW), but we will expand the evaluation section to include: (i) baselines for random guessing and non-backdoored adapters, (ii) the closed-form inversion formula with derivation, (iii) statistical significance (e.g., confidence intervals over multiple runs), and (iv) ablations varying batch size (4-32) and optimizer (SGD vs. AdamW). These additions will be incorporated without altering the core results. revision: yes
Circularity Check
Empirical attack construction with no circular derivation
full rationale
The paper presents NeuroImprint as an attack that assigns per-sample neurons with an 'at most once' update constraint, then analytically inverts the resulting adapter weights to recover embeddings. All reported outcomes (59-79% reconstruction rates) are measured empirical results across BERT/GPT-2/Qwen2/Llama3.2 and four datasets. No equation or claim reduces a prediction to a fitted parameter, self-citation, or definitional tautology; the design choices are explicit construction steps whose effectiveness is validated externally rather than assumed by the equations themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Constraining each neuron to update at most once isolates per-sample parameter updates despite large batches and stateful optimizers
invented entities (1)
-
memorization neuron
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
Pith/arXiv arXiv 2023
-
[2]
Simple, scalable adap- tation for neural machine translation
Ankur Bapna and Orhan Firat. Simple, scalable adap- tation for neural machine translation. InProceedings of the 2019 conference on empirical methods in natu- ral language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), pages 1538–1548, 2019
2019
-
[3]
{ACORN}: input validation for secure aggregation
James Bell, Adri `a Gasc´on, Tancr`ede Lepoint, Baiyu Li, Sarah Meiklejohn, Mariana Raykova, and Cathie Yun. {ACORN}: input validation for secure aggregation. In 32nd USENIX Security Symposium (USENIX Security 23), pages 4805–4822, 2023
2023
-
[4]
Secure single-server aggregation with (poly) logarithmic over- head
James Henry Bell, Kallista A Bonawitz, Adri `a Gasc´on, Tancr`ede Lepoint, and Mariana Raykova. Secure single-server aggregation with (poly) logarithmic over- head. InProceedings of the 2020 ACM SIGSAC Con- ference on Computer and Communications Security, pages 1253–1269, 2020
2020
-
[5]
Scibert: A pretrained language model for scientific text.arXiv preprint arXiv:1903.10676, 2019
Iz Beltagy, Kyle Lo, and Arman Cohan. Scibert: A pretrained language model for scientific text.arXiv preprint arXiv:1903.10676, 2019
arXiv 1903
-
[6]
A question-entailment approach to question answering
Asma Ben Abacha and Dina Demner-Fushman. A question-entailment approach to question answering. BMC bioinformatics, 20(1):511, 2019
2019
-
[7]
Practi- cal secure aggregation for privacy-preserving machine learning
Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Anto- nio Marcedone, H Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. Practi- cal secure aggregation for privacy-preserving machine learning. Inproceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Secu- rity, pages 1175–1191, 2017. 14
2017
-
[8]
Rofl: Attestable robustness for secure federated learning.arXiv e-prints, pages arXiv–2107, 2021
Lukas Burkhalter, Hidde Lycklama, Alexander Viand, Nicolas K¨uchler, and Anwar Hithnawi. Rofl: Attestable robustness for secure federated learning.arXiv e-prints, pages arXiv–2107, 2021
2021
-
[9]
Poisoning and backdooring contrastive learning
Nicholas Carlini and Andreas Terzis. Poisoning and backdooring contrastive learning. InThe Tenth In- ternational Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenRe- view.net, 2022
2022
-
[10]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlings- son, et al. Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21), pages 2633–2650, 2021
2021
-
[11]
Extracting training data from diffusion models
Nicolas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramer, Borja Balle, Daphne Ippolito, and Eric Wallace. Extracting training data from diffusion models. In32nd USENIX security symposium (USENIX Security 23), pages 5253–5270, 2023
2023
-
[12]
Legal-bert: The muppets straight out of law school.arXiv preprint arXiv:2010.02559, 2020
Ilias Chalkidis, Manos Fergadiotis, Prodromos Malakasiotis, Nikolaos Aletras, and Ion Androut- sopoulos. Legal-bert: The muppets straight out of law school.arXiv preprint arXiv:2010.02559, 2020
arXiv 2010
-
[13]
Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song. Targeted backdoor attacks on deep learn- ing systems using data poisoning.arXiv preprint arXiv:1712.05526, 2017
Pith/arXiv arXiv 2017
-
[14]
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[15]
Qlora: Efficient finetuning of quan- tized llms.Advances in neural information processing systems, 36:10088–10115, 2023
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quan- tized llms.Advances in neural information processing systems, 36:10088–10115, 2023
2023
-
[16]
Bert: Pre-training of deep bidi- rectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidi- rectional transformers for language understanding. In Proceedings of the 2019 conference of the North Amer- ican chapter of the association for computational lin- guistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[17]
Depth gives a false sense of privacy:{LLM}internal states inversion
Tian Dong, Yan Meng, Shaofeng Li, Guoxing Chen, Zhen Liu, and Haojin Zhu. Depth gives a false sense of privacy:{LLM}internal states inversion. In34th USENIX Security Symposium (USENIX Security 25), pages 1629–1648, 2025
2025
-
[18]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
2024
-
[19]
emrqa-msquad: A med- ical dataset structured with the squad v2
Jimenez Eladio and Hao Wu. emrqa-msquad: A med- ical dataset structured with the squad v2. 0 frame- work, enriched with emrqa medical information.arXiv preprint arXiv:2404.12050, 2024
arXiv 2024
-
[20]
Privacy backdoors: Stealing data with corrupted pretrained models
Shanglun Feng and Florian Tram`er. Privacy backdoors: Stealing data with corrupted pretrained models. InIn- ternational Conference on Machine Learning, pages 13326–13364. PMLR, 2024
2024
-
[21]
Liam Fowl, Jonas Geiping, Wojtek Czaja, Micah Gold- blum, and Tom Goldstein. Robbing the fed: Directly obtaining private data in federated learning with modi- fied models.arXiv preprint arXiv:2110.13057, 2021
arXiv 2021
-
[22]
Inverting gradients-how easy is it to break privacy in federated learning?Advances in Neural Information Processing Systems, 33:16937– 16947, 2020
Jonas Geiping, Hartmut Bauermeister, Hannah Dr ¨oge, and Michael Moeller. Inverting gradients-how easy is it to break privacy in federated learning?Advances in Neural Information Processing Systems, 33:16937– 16947, 2020
2020
-
[23]
Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Identifying vulnerabilities in the ma- chine learning model supply chain.arXiv preprint arXiv:1708.06733, 2017
Pith/arXiv arXiv 2017
-
[24]
V eri fl: Communication-efficient and fast verifiable aggrega- tion for federated learning.IEEE Transactions on Information Forensics and Security, 16:1736–1751, 2020
Xiaojie Guo, Zheli Liu, Jin Li, Jiqiang Gao, Boyu Hou, Changyu Dong, and Thar Baker. V eri fl: Communication-efficient and fast verifiable aggrega- tion for federated learning.IEEE Transactions on Information Forensics and Security, 16:1736–1751, 2020
2020
-
[25]
Gradvit: Gradient inversion of vision transformers
Ali Hatamizadeh, Hongxu Yin, Holger R Roth, Wenqi Li, Jan Kautz, Daguang Xu, and Pavlo Molchanov. Gradvit: Gradient inversion of vision transformers. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 10021– 10030, 2022
2022
-
[26]
Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg- Kirkpatrick, and Graham Neubig. Towards a unified view of parameter-efficient transfer learning.arXiv preprint arXiv:2110.04366, 2021
arXiv 2021
-
[27]
Model inversion attacks against collaborative inference
Zecheng He, Tianwei Zhang, and Ruby B Lee. Model inversion attacks against collaborative inference. In Proceedings of the 35th annual computer security ap- plications conference, pages 148–162, 2019. 15
2019
-
[28]
Parameter- efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Ges- mundo, Mona Attariyan, and Sylvain Gelly. Parameter- efficient transfer learning for nlp. InInternational conference on machine learning, pages 2790–2799. PMLR, 2019
2019
-
[29]
Hsiang Hsu Hsu, Kuan-Chieh Yin, and C.-C. Jay Kuo. Measuring the effects of non-identical data distribu- tion for federated visual classification.arXiv preprint arXiv:1909.06335, 2019
Pith/arXiv arXiv 1909
-
[30]
Lora: Low-rank adaptation of large lan- guage models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large lan- guage models.ICLR, 1(2):3, 2022
2022
-
[31]
Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language mod- els
Zhiqiang Hu, Lei Wang, Yihuai Lan, Wanyu Xu, Ee- Peng Lim, Lidong Bing, Xing Xu, Soujanya Poria, and Roy Lee. Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language mod- els. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 5254– 5276, 2023
2023
-
[32]
Finbert: A large language model for extracting information from financial text.Contemporary Accounting Research, 40(2):806–841, 2023
Allen H Huang, Hui Wang, and Yi Yang. Finbert: A large language model for extracting information from financial text.Contemporary Accounting Research, 40(2):806–841, 2023
2023
-
[33]
Kexin Huang, Jaan Altosaar, and Rajesh Ran- ganath. Clinicalbert: Modeling clinical notes and predicting hospital readmission.arXiv preprint arXiv:1904.05342, 2019
Pith/arXiv arXiv 1904
-
[34]
Swanand Kadhe, Nived Rajaraman, O Ozan Koylu- oglu, and Kannan Ramchandran. Fastsecagg: Scal- able secure aggregation for privacy-preserving feder- ated learning.arXiv preprint arXiv:2009.11248, 2020
arXiv 2009
-
[35]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
Pith/arXiv arXiv 2014
-
[36]
Thanos Konstantinidis, Giorgos Iacovides, Mingxue Xu, Tony G Constantinides, and Danilo Mandic. Finl- lama: Financial sentiment classification for algorithmic trading applications.arXiv preprint arXiv:2403.12285, 2024
arXiv 2024
-
[37]
Biobert: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics, 36(4):1234–1240, 2020
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. Biobert: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics, 36(4):1234–1240, 2020
2020
-
[38]
Llava- med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Informa- tion Processing Systems, 36:28541–28564, 2023
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Nau- mann, Hoifung Poon, and Jianfeng Gao. Llava- med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Informa- tion Processing Systems, 36:28541–28564, 2023
2023
-
[39]
Xiao-Yang Liu, Guoxuan Wang, Hongyang Yang, and Daochen Zha. Fingpt: Democratizing internet-scale data for financial large language models.arXiv preprint arXiv:2307.10485, 2023
arXiv 2023
-
[40]
Trojaning attack on neural networks
Yingqi Liu, Shiqing Ma, Yousra Aafer, Wen-Chuan Lee, Juan Zhai, Weihang Wang, and Xiangyu Zhang. Trojaning attack on neural networks. In25th Annual Network And Distributed System Security Symposium (NDSS 2018). Internet Soc, 2018
2018
-
[41]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[42]
April: Finding the achilles’ heel on privacy for vision transformers
Jiahao Lu, Xi Sheryl Zhang, Tianli Zhao, Xiangyu He, and Jian Cheng. April: Finding the achilles’ heel on privacy for vision transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 10051–10060, 2022
2022
-
[43]
Biogpt: generative pre-trained transformer for biomedical text generation and mining.Briefings in bioinformatics, 23(6):bbac409, 2022
Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon, and Tie-Yan Liu. Biogpt: generative pre-trained transformer for biomedical text generation and mining.Briefings in bioinformatics, 23(6):bbac409, 2022
2022
-
[44]
Flamingo: Multi- round single-server secure aggregation with applica- tions to private federated learning
Yiping Ma, Jess Woods, Sebastian Angel, Antigoni Polychroniadou, and Tal Rabin. Flamingo: Multi- round single-server secure aggregation with applica- tions to private federated learning. In2023 IEEE Sym- posium on Security and Privacy (SP), pages 477–496. IEEE, 2023
2023
-
[45]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ram- age, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, pages 1273–1282. PMLR, 2017
2017
-
[46]
Eluding secure aggregation in federated learning via model inconsistency
Dario Pasquini, Danilo Francati, and Giuseppe Ate- niese. Eluding secure aggregation in federated learning via model inconsistency. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Commu- nications Security, pages 2429–2443, 2022
2022
-
[47]
Pseudo-private data guided model in- version attacks.Advances in Neural Information Pro- cessing Systems, 37:33338–33375, 2024
Xiong Peng, Bo Han, Feng Liu, Tongliang Liu, and Mingyuan Zhou. Pseudo-private data guided model in- version attacks.Advances in Neural Information Pro- cessing Systems, 37:33338–33375, 2024. 16
2024
-
[48]
Dager: Exact gra- dient inversion for large language models.Advances in Neural Information Processing Systems, 37:87801– 87830, 2024
Ivo Petrov, Dimitar I Dimitrov, Maximilian Baader, Mark N M¨uller, and Martin Vechev. Dager: Exact gra- dient inversion for large language models.Advances in Neural Information Processing Systems, 37:87801– 87830, 2024
2024
-
[49]
Adapterhub: A framework for adapting transformers.arXiv preprint arXiv:2007.07779, 2020
Jonas Pfeiffer, Andreas R ¨uckl´e, Clifton Poth, Aishwarya Kamath, Ivan Vuli ´c, Sebastian Ruder, Kyunghyun Cho, and Iryna Gurevych. Adapterhub: A framework for adapting transformers.arXiv preprint arXiv:2007.07779, 2020
arXiv 2007
-
[50]
Prompt inversion attack against collaborative inference of large language models
Wenjie Qu, Yuguang Zhou, Yongji Wu, Tingsong Xiao, Binhang Yuan, Yiming Li, and Jiaheng Zhang. Prompt inversion attack against collaborative inference of large language models. In2025 IEEE Symposium on Secu- rity and Privacy (SP), pages 1695–1712. IEEE, 2025
2025
-
[51]
Language mod- els are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language mod- els are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
2019
-
[52]
Squad: 100,000+ questions for machine comprehension of text.arXiv preprint arXiv:1606.05250, 2016
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text.arXiv preprint arXiv:1606.05250, 2016
Pith/arXiv arXiv 2016
-
[53]
Elsa: Secure aggregation for fed- erated learning with malicious actors
Mayank Rathee, Conghao Shen, Sameer Wagh, and Raluca Ada Popa. Elsa: Secure aggregation for fed- erated learning with malicious actors. In2023 IEEE Symposium on Security and Privacy (SP), pages 1961–
1961
-
[54]
Nils Reimers and Iryna Gurevych. Sentence-bert: Sen- tence embeddings using siamese bert-networks.arXiv preprint arXiv:1908.10084, 2019
Pith/arXiv arXiv 1908
-
[55]
Shanghao Shi, Ning Wang, Yang Xiao, Chaoyu Zhang, Yi Shi, Y Thomas Hou, and Wenjing Lou. Scale-mia: A scalable model inversion attack against secure fed- erated learning via latent space reconstruction.arXiv preprint arXiv:2311.05808, 2023
arXiv 2023
-
[56]
Congress
U.S. Congress. Health insurance portability and ac- countability act of 1996.https://www.govinf o.gov/link/plaw/104/public/191, 1996. Public Law 104-191, 110 Stat. 1936, enacted August 21, 1996
1996
-
[57]
Yuxin Wen, Jonas Geiping, Liam Fowl, Micah Gold- blum, and Tom Goldstein. Fishing for user data in large-batch federated learning via gradient magnifica- tion.arXiv preprint arXiv:2202.00580, 2022
arXiv 2022
-
[58]
Privacy backdoors: Enhancing membership inference through poisoning pre-trained models.Advances in Neural In- formation Processing Systems, 37:83374–83396, 2024
Yuxin Wen, Leo Marchyok, Sanghyun Hong, Jonas Geiping, Tom Goldstein, and Nicholas Carlini. Privacy backdoors: Enhancing membership inference through poisoning pre-trained models.Advances in Neural In- formation Processing Systems, 37:83374–83396, 2024
2024
-
[59]
See through gradients: Image batch recovery via gradinversion
Hongxu Yin, Arun Mallya, Arash Vahdat, Jose M Al- varez, Jan Kautz, and Pavlo Molchanov. See through gradients: Image batch recovery via gradinversion. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 16337– 16346, 2021
2021
-
[60]
Character-level convolutional networks for text classi- fication
Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classi- fication. InAdvances in Neural Information Processing Systems (NeurIPS), 2015
2015
-
[61]
The secret revealer: Generative model-inversion attacks against deep neu- ral networks
Yuheng Zhang, Ruoxi Jia, Hengzhi Pei, Wenxiao Wang, Bo Li, and Dawn Song. The secret revealer: Generative model-inversion attacks against deep neu- ral networks. InProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, pages 253–261, 2020
2020
-
[62]
idlg: Improved deep leakage from gradients.arXiv preprint arXiv:2001.02610, 2020
Bo Zhao, Konda Reddy Mopuri, and Hakan Bilen. idlg: Improved deep leakage from gradients.arXiv preprint arXiv:2001.02610, 2020
arXiv 2001
-
[63]
Loki: Large-scale data reconstruction attack against federated learning through model manip- ulation
Joshua C Zhao, Atul Sharma, Ahmed Roushdy Elko- rdy, Yahya H Ezzeldin, Salman Avestimehr, and Saurabh Bagchi. Loki: Large-scale data reconstruction attack against federated learning through model manip- ulation. In2024 IEEE Symposium on Security and Pri- vacy (SP), pages 1287–1305. IEEE, 2024
2024
-
[64]
R-gap: Re- cursive gradient attack on privacy.arXiv preprint arXiv:2010.07733, 2020
Junyi Zhu and Matthew Blaschko. R-gap: Re- cursive gradient attack on privacy.arXiv preprint arXiv:2010.07733, 2020
arXiv 2010
-
[65]
Deep leakage from gradients.Advances in neural information pro- cessing systems, 32, 2019
Ligeng Zhu, Zhijian Liu, and Song Han. Deep leakage from gradients.Advances in neural information pro- cessing systems, 32, 2019
2019
-
[66]
Yaoming Zhu, Jiangtao Feng, Chengqi Zhao, Mingx- uan Wang, and Lei Li. Counter-interference adapter for multilingual machine translation.arXiv preprint arXiv:2104.08154, 2021. 17 Appendix A. Adam Optimizer The Adam optimizer is an adaptive stochastic optimiza- tion algorithm that maintains exponential moving averages of both the first- and second-order mo...
arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.