Trustworthy Image Authentication using Forensic Knowledge Graphs
Pith reviewed 2026-06-26 08:37 UTC · model grok-4.3
The pith
Forensic Knowledge Graphs integrate trace extraction, causal reasoning, and explanations to authenticate images more effectively than detectors or vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
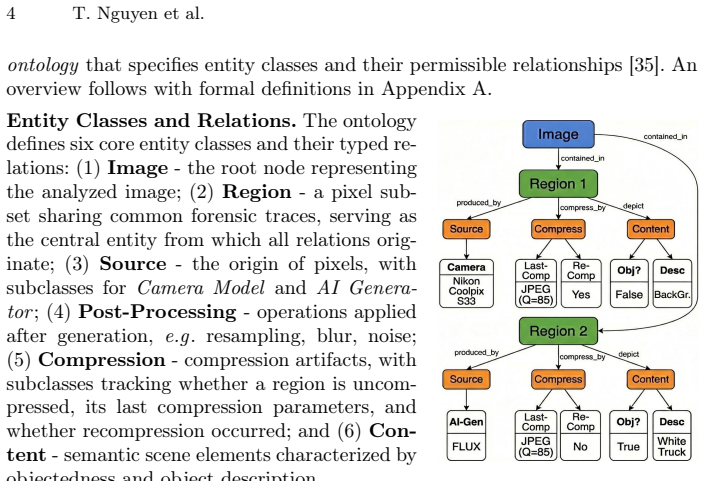
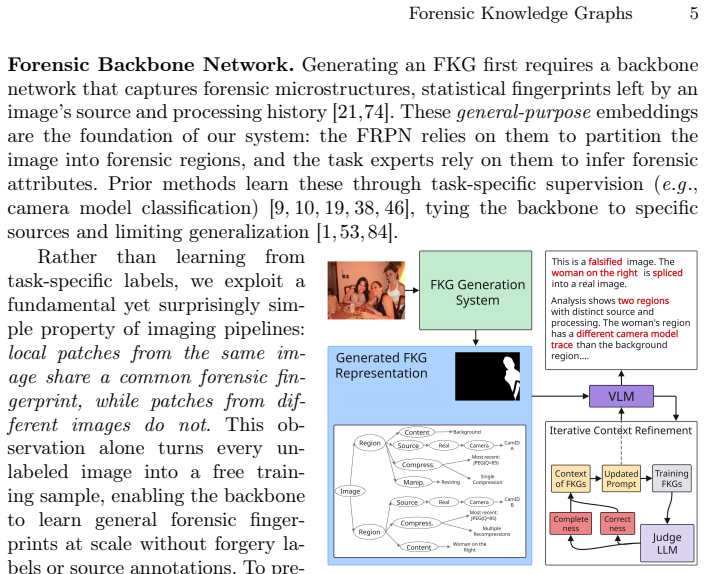
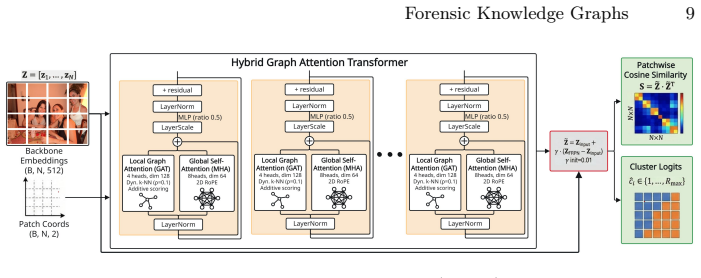
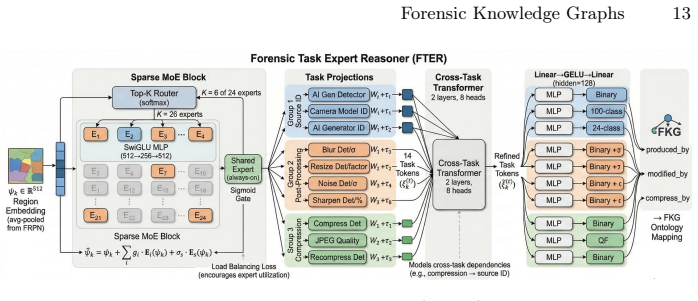
Forensic Knowledge Graphs encode forensic traces together with their causal dependencies and links to scene content, forming a unified structure that supports accurate forgery detection, identification, localization, and human-interpretable forensic justification when generated via a dedicated forensic authentication network and Iterative Context Refinement strategy.
What carries the argument
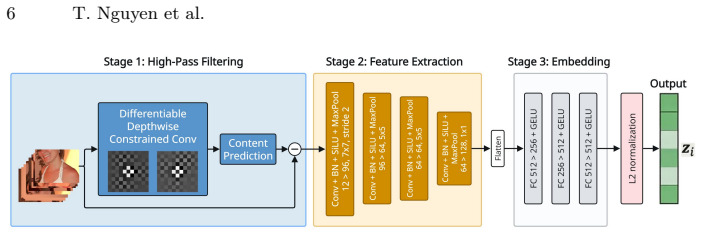
Forensic Knowledge Graphs (FKGs), which represent forensic traces along with causal dependencies and scene content links to enable structured reasoning and explanation.
If this is right
- Forgeries can be detected, localized, and identified with both higher accuracy and explicit justification.
- Structured graphs allow forensic evidence to be combined with scene content for more reliable authentication.
- The FKG-50K dataset enables training and evaluation of models that produce grounded forensic outputs.
Where Pith is reading between the lines
- The approach could extend to video or multi-image sequences by linking traces across frames.
- Integration with real-time capture devices might allow on-device verification before images are shared.
- New forgery techniques not represented in FKG-50K would require updates to the graph construction process.
Load-bearing premise
The Iterative Context Refinement strategy can guide vision-language models to base explanations on forensic traces instead of general scene understanding.
What would settle it
A controlled test set of forgeries where FKG explanations do not match the ground-truth forensic traces or where detection accuracy falls below that of the best baseline detector.
Figures



read the original abstract
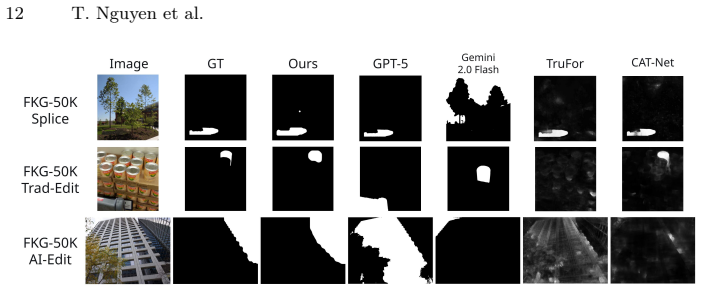
Advances in generative AI have made image falsification highly realistic, demanding trustworthy authentication systems. Existing forensic detectors can target certain forgery types but lack interpretability, while vision-language models (VLMs) provide explanations but cannot exploit forensic traces for reliable detection. We propose Forensic Knowledge Graphs (FKGs), a unified framework that integrates forensic evidence extraction, structured reasoning, and human-interpretable explanation. Our FKG structure encodes forensic traces along with their causal dependencies and links to scene content. To generate accurate FKGs, we introduce a novel forensic authentication network and an Iterative Context Refinement strategy that guides VLMs to produce faithful, grounded explanations. We also present FKG-50K, a dataset of 50,000 realistic forgeries with ground-truth FKGs. Experiments demonstrate that FKG outperforms both forensic detectors and VLMs in detection, forgery identification and localization, and forensic justification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Forensic Knowledge Graphs (FKGs) as a unified framework for trustworthy image authentication that integrates forensic evidence extraction, structured reasoning over causal dependencies, and human-interpretable explanations. It introduces a forensic authentication network, an Iterative Context Refinement strategy to guide VLMs toward grounded outputs, and the FKG-50K dataset of 50,000 realistic forgeries with ground-truth FKGs. The central claim is that the FKG approach outperforms both forensic detectors and VLMs on detection, forgery identification and localization, and forensic justification.
Significance. If the performance claims are substantiated, the work would meaningfully advance digital forensics by addressing the interpretability gap in detectors and the reliability gap in VLMs through structured forensic knowledge. The FKG-50K dataset with ground-truth annotations constitutes a concrete, reusable contribution that could support future benchmarking. The Iterative Context Refinement component, if shown to enforce forensic grounding rather than scene-level reasoning, would represent a useful methodological advance.
major comments (2)
- [Abstract] Abstract: the claim that 'Experiments demonstrate that FKG outperforms both forensic detectors and VLMs' is presented without any quantitative metrics, error bars, dataset splits, or ablation results. This absence directly prevents verification of the central outperformance claim.
- [Abstract] Abstract (paragraph on novel components): the Iterative Context Refinement strategy is asserted to 'successfully guide VLMs to produce faithful, grounded explanations that exploit forensic traces,' yet no mechanism, training procedure, or empirical test of this assumption is supplied; the assumption is load-bearing for the framework's claimed reliability advantage.
minor comments (2)
- The FKG structure is described at a high level; explicit formalization of node/edge types and how causal dependencies are encoded would improve reproducibility.
- Dataset construction details for FKG-50K (forgery generation pipeline, annotation protocol, train/test split) are referenced but not elaborated in the abstract.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on our manuscript. The comments focus on the abstract's presentation of key claims, which we address point by point below. We agree that enhancing the abstract will improve clarity and verifiability while preserving its summary nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'Experiments demonstrate that FKG outperforms both forensic detectors and VLMs' is presented without any quantitative metrics, error bars, dataset splits, or ablation results. This absence directly prevents verification of the central outperformance claim.
Authors: We acknowledge that the abstract, as a concise summary, does not include specific quantitative details. The full manuscript provides these in Section 4 (Experiments), including performance metrics with error bars, dataset splits on FKG-50K, and ablation studies comparing against forensic detectors and VLMs. To improve verifiability, we will revise the abstract to incorporate a small number of key quantitative results demonstrating the claimed outperformance. revision: yes
-
Referee: [Abstract] Abstract (paragraph on novel components): the Iterative Context Refinement strategy is asserted to 'successfully guide VLMs to produce faithful, grounded explanations that exploit forensic traces,' yet no mechanism, training procedure, or empirical test of this assumption is supplied; the assumption is load-bearing for the framework's claimed reliability advantage.
Authors: The abstract summarizes the strategy without detailing its implementation. The full manuscript describes the mechanism, iterative procedure, training, and empirical validation (including grounding improvements and ablations) in Section 3. To strengthen the abstract, we will add a brief reference to the empirical grounding tests while keeping the summary concise. revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract and available description introduce novel components (FKG structure, forensic authentication network, Iterative Context Refinement strategy, and FKG-50K dataset) without any equations, fitting procedures, or self-citations that reduce claims to prior inputs by construction. No load-bearing derivation steps are visible that equate predictions or results to fitted parameters or self-referential definitions. The framework is presented as resting on new elements evaluated against external benchmarks (forensic detectors and VLMs), making it self-contained per the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2408.00388 (2024)
Amerini, I., Barni, M., Battiato, S., Bestagini, P., Boato, G., Bonaventura, T.S., Bruni, V., Caldelli, R., De Natale, F., De Nicola, R., et al.: Deepfake media foren- sics: State of the art and challenges ahead. arXiv preprint arXiv:2408.00388 (2024)
arXiv 2024
-
[2]
Anlen, L., Vazquez Llorente, R.: Spotting the deepfakes: how AI detection tools work and where they fail.https://reutersinstitute.politics.ox.ac.uk/news/ spotting- deepfakes- year- elections- how- ai- detection- tools- work- and- where-they-fail(2024), reuters Institute / WITNESS
2024
-
[3]
anthropic.com/claude-4-system-card(2025)
Anthropic: System card: Claude Opus 4 & Claude Sonnet 4.https://www. anthropic.com/claude-4-system-card(2025)
2025
-
[4]
arXiv preprint arXiv:2511.22351 (2025)
Bagaria, A.: INSIGHT: An interpretable neural vision-language framework for rea- soning of generative artifacts. arXiv preprint arXiv:2511.22351 (2025)
arXiv 2025
-
[5]
arXiv preprint arXiv:2511.21631 (2025)
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., et al.: Qwen3-VL technical report. arXiv preprint arXiv:2511.21631 (2025)
Pith/arXiv arXiv 2025
-
[6]
IEEE Open Journal of Signal Processing5, 1–9 (2024)
Bammey, Q.: Synthbuster: Towards detection of diffusion model generated images. IEEE Open Journal of Signal Processing5, 1–9 (2024)
2024
-
[7]
Information Fusion58, 82–115 (2020)
Barredo Arrieta, A., Díaz-Rodríguez, N., Del Ser, J., Bennetot, A., Tabik, S., Bar- bado, A., García, S., Gil-López, S., Molina, D., Benjamins, R., Chatila, R., Herrera, F.: Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Information Fusion58, 82–115 (2020)
2020
-
[8]
arXiv preprint arXiv:2506.15742 (2025)
Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dockhorn, T., En- glish, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: FLUX.1 kon- text: Flow matching for in-context image generation and editing in latent space. arXiv preprint arXiv:2506...
Pith/arXiv arXiv 2025
-
[9]
In: Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security
Bayar, B., Stamm, M.C.: A deep learning approach to universal image manipula- tion detection using a new convolutional layer. In: Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security. pp. 5–10 (2016)
2016
-
[10]
IEEE Transactions on Information Forensics and Security13(11), 2691–2706 (2018)
Bayar, B., Stamm, M.C.: Constrained convolutional neural networks: A new ap- proach towards general purpose image manipulation detection. IEEE Transactions on Information Forensics and Security13(11), 2691–2706 (2018)
2018
-
[11]
Black Forest Labs: FLUX.1: A suite of text-to-image generation models.https: //blackforestlabs.ai(2024)
2024
-
[12]
In: CVPR
Brooks, T., Holynski, A., Efros, A.A.: InstructPix2Pix: Learning to follow image editing instructions. In: CVPR. pp. 18392–18402 (2023)
2023
-
[13]
In: NeurIPS
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. In: NeurIPS. vol. 33, pp. 1877–1901 (2020)
1901
-
[14]
arXiv preprint arXiv:2511.23158 (2025)
Cao, H., Mei, Q., Li, Z., Li, Y., Meng, Z., Zhang, Y., Li, C., Zhang, Z., Ding, X., Wang, Y., Lyu, J., Wu, F.: REVEAL: Reasoning-enhanced forensic evidence analy- sis for explainable AI-generated image detection. arXiv preprint arXiv:2511.23158 (2025)
Pith/arXiv arXiv 2025
-
[15]
arXiv preprint arXiv:2511.16719 (2025)
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. arXiv preprint arXiv:2511.16719 (2025)
Pith/arXiv arXiv 2025
-
[16]
In: ECCV
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: ECCV. pp. 213–229 (2020)
2020
-
[17]
IEEE Trans- actions on Information Forensics and Security8(7), 1182–1194 (2013) 16 T
de Carvalho, T.J., Riess, C., Angelopoulou, E., Pedrini, H., de Rezende Rocha, A.: Exposing digital image forgeries by illumination color classification. IEEE Trans- actions on Information Forensics and Security8(7), 1182–1194 (2013) 16 T. Nguyen et al
2013
-
[18]
Caulfield, M.: How to use ChatGPT to detect AI (and otherwise digitally al- tered) photos.https://mikecaulfield.substack.com/p/how-to-use-chatgpt- to-detect-ai-and(2025)
2025
-
[19]
In: ICCV
Chen, X., Dong, C., Ji, J., Cao, J., Li, X.: Image manipulation detection by multi- view multi-scale supervision. In: ICCV. pp. 14185–14193 (2021)
2021
-
[20]
In: ICASSP
Corvi, R., Cozzolino, D., Zingarini, G., Poggi, G., Nagano, K., Verdoliva, L.: On the detection of synthetic images generated by diffusion models. In: ICASSP. pp. 1–5 (2023)
2023
-
[21]
IEEE Transactions on Information Forensics and Security15, 144–159 (2020)
Cozzolino, D., Verdoliva, L.: Noiseprint: A CNN-based camera model fingerprint. IEEE Transactions on Information Forensics and Security15, 144–159 (2020)
2020
-
[22]
arXiv preprint arXiv:2511.03929 (2025)
Deshmukh, A.S., Chumachenko, K., Rintamaki, T., Le, M., Poon, T., et al.: NVIDIA Nemotron Nano V2 VL. arXiv preprint arXiv:2511.03929 (2025)
arXiv 2025
-
[23]
In: IEEE China Summit and International Conference on Signal and Information Processing
Dong, J., Wang, W., Tan, T.: CASIA image tampering detection evaluation database. In: IEEE China Summit and International Conference on Signal and Information Processing. pp. 422–426 (2013)
2013
-
[24]
arXiv preprint arXiv:1702.08608 (2017)
Doshi-Velez,F.,Kim,B.:Towardsarigorousscienceofinterpretablemachinelearn- ing. arXiv preprint arXiv:1702.08608 (2017)
Pith/arXiv arXiv 2017
-
[25]
politics.ox.ac.uk/news/ai-undermining-osints-core-assumptions-heres- how-journalists-should-adapt(2025), reuters Institute / WITNESS
Edwards, L., Wojciak, T., Anlen, L.: AI is undermining OSINT’s core as- sumptions: here’s how journalists should adapt.https://reutersinstitute. politics.ox.ac.uk/news/ai-undermining-osints-core-assumptions-heres- how-journalists-should-adapt(2025), reuters Institute / WITNESS
2025
-
[26]
Europol Innovation Lab: Facing reality? Law enforcement and the challenge of deepfakes. Tech. rep., Europol (2022)
2022
-
[27]
Journal of Machine Learning Research 23(120), 1–40 (2022)
Fedus,W.,Zoph,B.,Shazeer,N.:Switchtransformers:Scalingtotrillionparameter models with simple and efficient sparsity. Journal of Machine Learning Research 23(120), 1–40 (2022)
2022
-
[28]
org / crime / grok - google - lens - ai - imagery-train-attack/(2025), accessed: 2026
Full Fact: Grok and Google Lens AI overviews claim fake imagery shows Hunt- ingdon train attack.https : / / fullfact . org / crime / grok - google - lens - ai - imagery-train-attack/(2025), accessed: 2026
2025
-
[29]
arXiv preprint arXiv:2507.06261 (2025)
Gemini Team: Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
Pith/arXiv arXiv 2025
-
[30]
arXiv preprint arXiv:2312.11805 (2023)
Gemini Team, Anil, R., Borgeaud, S., Wu, Y., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., et al.: Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
Pith/arXiv arXiv 2023
-
[31]
arXiv preprint arXiv:2503.19786 (2025)
Gemma Team, Kamath, A.,Ferret, J., Pathak, S., etal.: Gemma3 technical report. arXiv preprint arXiv:2503.19786 (2025)
Pith/arXiv arXiv 2025
-
[32]
Communications of the ACM63(11), 139–144 (2020)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial networks. Communications of the ACM63(11), 139–144 (2020)
2020
-
[33]
com/deepmind-media/Model-Cards/Gemini-2-0-Flash-Model-Card.pdf(2025)
Google DeepMind: Gemini 2.0 Flash model card.https://storage.googleapis. com/deepmind-media/Model-Cards/Gemini-2-0-Flash-Model-Card.pdf(2025)
2025
-
[34]
Proceedings of the National Academy of Sciences119(1), e2110013119 (2022)
Groh, M., Epstein, Z., Firestone, C., Picard, R.: Deepfake detection by human crowds, machines, and machine-informed crowds. Proceedings of the National Academy of Sciences119(1), e2110013119 (2022)
2022
-
[35]
Knowl- edge Acquisition5(2), 199–220 (1993)
Gruber, T.R.: A translation approach to portable ontology specifications. Knowl- edge Acquisition5(2), 199–220 (1993)
1993
-
[36]
In: CVPR
Guillaro, F., Cozzolino, D., Sud, A., Dufour, N., Verdoliva, L.: TruFor: Leveraging all-round clues for trustworthy image forgery detection and localization. In: CVPR. pp. 20606–20615 (2023) Forensic Knowledge Graphs 17
2023
-
[37]
AI Magazine40(2), 44–58 (2019)
Gunning, D., Aha, D.W.: DARPA’s explainable artificial intelligence (XAI) pro- gram. AI Magazine40(2), 44–58 (2019)
2019
-
[38]
In: CVPR
Guo, X., Liu, X., Ren, Z., Grosz, S., Masi, I., Liu, X.: Hierarchical fine-grained image forgery detection and localization. In: CVPR. pp. 3155–3165 (2023)
2023
-
[39]
In: ICCV
He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask R-CNN. In: ICCV. pp. 2961– 2969 (2017)
2017
-
[40]
ACM Computing Surveys54(4), 1–37 (2021)
Hogan, A., Blomqvist, E., Cochez, M., d’Amato, C., de Melo, G., Gutierrez, C., Kirrane, S., Gayo, J.E.L., Navigli, R., Neumaier, S., et al.: Knowledge graphs. ACM Computing Surveys54(4), 1–37 (2021)
2021
-
[41]
In: CVPR (2025)
Huang, Z., Hu, J., Li, X., He, Y., Zhao, X., Peng, B., Wu, B., Huang, X., Cheng, G.: SIDA: Social media image deepfake detection, localization and explanation with large multimodal model. In: CVPR (2025)
2025
-
[42]
In: CVPRW
Jia, S., Lyu, R., Zhao, K., Chen, Y., Yan, Z., Ju, Y., Hu, C., Li, X., Wu, B., Lyu, S.: Can ChatGPT detect DeepFakes? A study of using multimodal large language models for media forensics. In: CVPRW. pp. 4324–4333 (2024)
2024
-
[43]
In: CVPR
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T.: Analyzing and improving the image quality of StyleGAN. In: CVPR. pp. 8110–8119 (2020)
2020
-
[44]
In: ICLR (2024)
Khattab, O., Singhvi, A., Maheshwari, P., Zhang, Z., Santhanam, K., Vard- hamanan, S., Haq, S., Sharma, A., Joshi, T.T., Mober, H., et al.: DSPy: Compiling declarative language model calls into state-of-the-art pipelines. In: ICLR (2024)
2024
-
[45]
In: ICCV
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollár, P., Girshick, R.: Segment anything. In: ICCV. pp. 4015–4026 (2023)
2023
-
[46]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Kwon, M.J., Yu, I.J., Nam, S.H., Lee, H.K.: CAT-Net: Compression artifact tracing network for detection and localization of image splicing. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 375–384 (2021)
2021
-
[47]
ACM Computing Surveys55(9), 1–46 (2023)
Li, B., Qi, P., Liu, B., Di, S., Liu, J., Pei, J., Yi, J., Zhou, B.: Trustworthy AI: From principles to practices. ACM Computing Surveys55(9), 1–46 (2023)
2023
-
[48]
Li, X., Lv, K., Yan, H., Lin, T., Zhu, W., Ni, Y., Xie, G., Wang, X., Qiu, X.: Unified demonstration retriever for in-context learning. In: ACL. pp. 4644–4668 (2023)
2023
-
[49]
In: NeurIPS (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: NeurIPS (2023)
2023
-
[50]
arXiv preprint arXiv:2410.10238 (2024)
Liu, J., Zhang, F., Zhu, J., Sun, E., Zhang, Q., Zha, Z.J.: ForgeryGPT: Multi- modal large language model for explainable image forgery detection and localiza- tion. arXiv preprint arXiv:2410.10238 (2024)
Pith/arXiv arXiv 2024
-
[51]
In: ECCV (2024)
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Li, C., Yang, J., Su, H., Zhu, J., Zhang, L.: Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection. In: ECCV (2024)
2024
-
[52]
IEEE Transactions on Information Forensics and Security1(2), 205–214 (2006)
Lukas, J., Fridrich, J., Goljan, M.: Digital camera identification from sensor pattern noise. IEEE Transactions on Information Forensics and Security1(2), 205–214 (2006)
2006
-
[53]
In: IEEE International Workshop on Information Forensics and Security (WIFS)
Mareen, H., Karageorgiou, D., Van Wallendael, G., Lambert, P., Papadopoulos, S.: TGIF: Text-guided inpainting forgery dataset. In: IEEE International Workshop on Information Forensics and Security (WIFS). pp. 1–6 (2024)
2024
-
[54]
IEEE Transactions on Information Forensics and Security15, 1331–1346 (2020)
Mayer, O., Stamm, M.C.: Forensic similarity for digital images. IEEE Transactions on Information Forensics and Security15, 1331–1346 (2020)
2020
-
[55]
Nguyen et al
Meta AI: The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation.https://ai.meta.com/blog/llama-4-multimodal-intelligence/ (2025) 18 T. Nguyen et al
2025
-
[56]
Midjourney: Midjourney.https://www.midjourney.com, accessed: 2025
2025
-
[57]
In: CVPR
Nguyen, T.D., Azizpour, A., Stamm, M.C.: Forensic self-descriptions are all you need for zero-shot detection, open-set source attribution, and clustering of AI- generated images. In: CVPR. pp. 3040–3050 (2025)
2025
-
[58]
Proceedings of the National Academy of Sciences 119(8), e2120481119 (2022)
Nightingale, S.J., Farid, H.: AI-synthesized faces are indistinguishable from real faces and more trustworthy. Proceedings of the National Academy of Sciences 119(8), e2120481119 (2022)
2022
-
[59]
Nightingale, S.J., Wade, K.A., Watson, D.G.: Can people identify original and manipulated photos of real-world scenes? Cognitive Research: Principles and Im- plications2(1), 30 (2017)
2017
-
[60]
In: CVPR
Ojha, U., Li, Y., Lee, Y.J.: Towards universal fake image detectors that generalize across generative models. In: CVPR. pp. 24480–24489 (2023)
2023
-
[61]
arXiv preprint arXiv:2303.08774 (2023)
OpenAI: GPT-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
-
[62]
OpenAI: GPT-4o system card.https://openai.com/index/gpt- 4o- system- card/(2024)
2024
-
[63]
com/index/introducing-4o-image-generation/(2025)
OpenAI: GPT-Image-1: Native image generation in ChatGPT.https://openai. com/index/introducing-4o-image-generation/(2025)
2025
-
[64]
arXiv preprint arXiv:2601.03267 (2025)
OpenAI: OpenAI GPT-5 system card. arXiv preprint arXiv:2601.03267 (2025)
Pith/arXiv arXiv 2025
-
[65]
Pevny, T., Fridrich, J.: Detection of double-compression in JPEG images for appli- cationsinsteganography.IEEETransactionsonInformationForensicsandSecurity 3(2), 247–258 (2008)
2008
-
[66]
pexels.com, accessed: 2025
Pexels: Pexels: Free stock photos, royalty free images and videos.https://www. pexels.com, accessed: 2025
2025
-
[67]
arXiv preprint arXiv:2307.01952 (2023)
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: SDXL: Improving latent diffusion models for high-resolution im- age synthesis. arXiv preprint arXiv:2307.01952 (2023)
Pith/arXiv arXiv 2023
-
[68]
gradient descent
Pryzant, R., Iter, D., Li, J., Lee, Y.T., Zhu, C., Zeng, M.: Automatic prompt optimization with “gradient descent” and beam search. In: EMNLP. pp. 7957–7968 (2023)
2023
-
[69]
arXiv preprint arXiv:2508.02324 (2025)
Qwen Team: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
Pith/arXiv arXiv 2025
-
[70]
arXiv preprint arXiv:2204.06125 (2022)
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text- conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 (2022)
Pith/arXiv arXiv 2022
-
[71]
In: CVPR
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR. pp. 10684–10695 (2022)
2022
-
[72]
In: ICCV
Rössler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J., Nießner, M.: Face- Forensics++: Learning to detect manipulated facial images. In: ICCV. pp. 1–11 (2019)
2019
-
[73]
In: Proceedings of the ACM SIGSAC Conference on Computer and Communications Security
Sha, Z., Li, Z., Yu, N., Zhang, Y.: DE-FAKE: Detection and attribution of fake images generated by text-to-image generation models. In: Proceedings of the ACM SIGSAC Conference on Computer and Communications Security. pp. 3418–3432 (2023)
2023
-
[74]
IEEE Transactions on Information Forensics and Security 5(3), 492–506 (2010)
Stamm, M.C., Liu, K.J.R.: Forensic detection of image manipulation using statisti- cal intrinsic fingerprints. IEEE Transactions on Information Forensics and Security 5(3), 492–506 (2010)
2010
-
[75]
IEEE Transactions on Information Forensics and Security6(3), 1050–1065 (2011)
Stamm, M.C., Liu, K.J.R.: Anti-forensics of digital image compression. IEEE Transactions on Information Forensics and Security6(3), 1050–1065 (2011)
2011
-
[76]
IEEE Access1, 167–200 (2013) Forensic Knowledge Graphs 19
Stamm, M.C., Wu, M., Liu, K.J.R.: Information forensics: An overview of the first decade. IEEE Access1, 167–200 (2013) Forensic Knowledge Graphs 19
2013
-
[77]
arXiv preprint arXiv:2508.01402 (2025)
Tan, C., Wang, J., Ming, X., Tao, R., Wei, Y., Zhao, Y., Lu, Y.: ForenX: Towards explainable AI-generated image detection with multimodal large language models. arXiv preprint arXiv:2508.01402 (2025)
arXiv 2025
-
[78]
In: CVPR
Tan, C., Zhao, Y., Wei, S., Gu, G., Liu, P., Wei, Y.: Rethinking the up-sampling operations in CNN-based generative network for generalizable deepfake detection. In: CVPR. pp. 28130–28139 (2024)
2024
-
[79]
arXiv preprint arXiv:2506.10474 (2025)
Tariq, S., Kim, S., Woo, S.S.: LLMs are not yet ready for deepfake image detection. arXiv preprint arXiv:2506.10474 (2025)
arXiv 2025
-
[80]
In: ICCV (2021)
Touvron, H., Cord, M., Sablayrolles, A., Synnaeve, G., Jégou, H.: Going deeper with image transformers. In: ICCV (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.