Selective Ensemble Based on Preference-Directed Multi-Objective Bandits
Pith reviewed 2026-06-26 12:18 UTC · model grok-4.3
The pith
PrefUCB maintains directional confidence intervals to achieve instance-dependent logarithmic regret bounds in preference-directed multi-objective bandits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
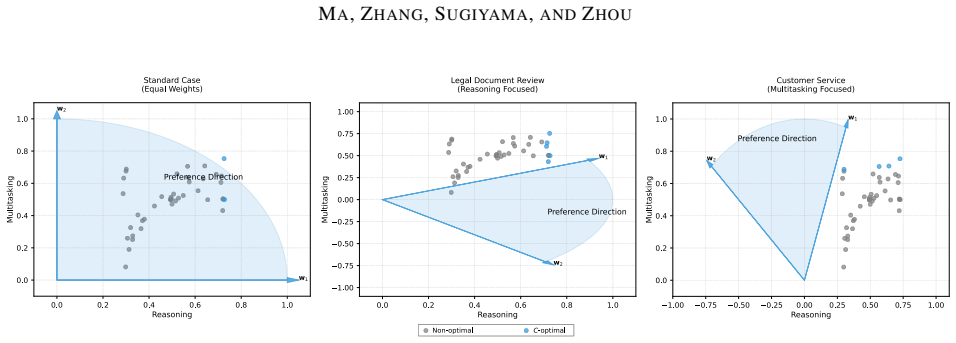
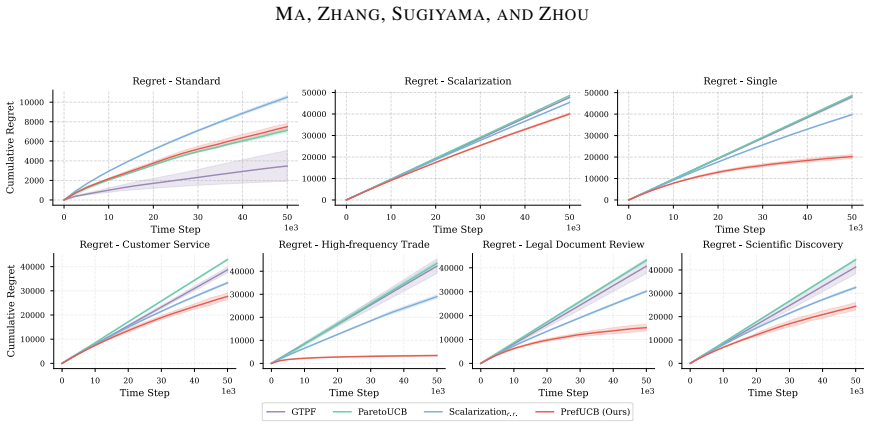
We formalize the selective ensemble problem under partial linear preferences as the preference-directed multi-objective bandit (PDMOB) problem, where admissible trade-offs lie in a polyhedral preference cone. We define Pareto C-optimality as a generalization of standard Pareto optimality and scalarization. The PrefUCB algorithm maintains directional confidence intervals and we prove instance-dependent logarithmic bounds on both indicator-based and gap-weighted regret, recovering the optimal T dependence in classical cases.
What carries the argument
The PrefUCB algorithm, which maintains directional confidence intervals to guide exploration in the PDMOB setting defined by a polyhedral preference cone.
If this is right
- Selective ensemble tasks can be solved with sublinear regret even when preferences are only partially specified via a cone.
- The algorithm applies equally to indicator-based and gap-weighted regret measures.
- In special cases such as full scalarization or single-objective bandits, PrefUCB recovers the known optimal logarithmic dependence on T.
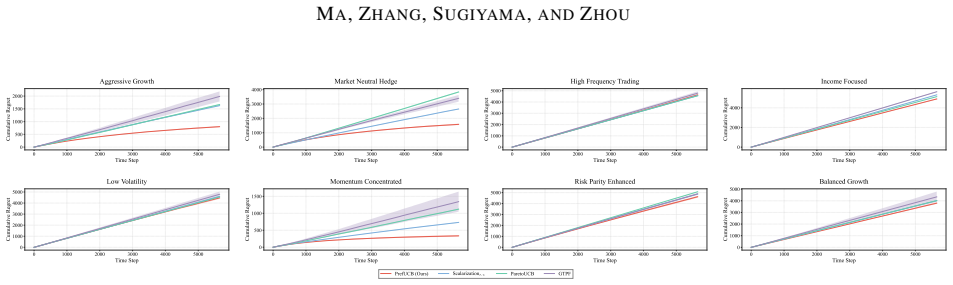
- The same directional-interval approach can be used for online asset allocation under institutional mandates.
Where Pith is reading between the lines
- The polyhedral-cone representation of preferences could be tested on other sequential selection problems such as recommendation or hyperparameter search.
- Instance-dependent bounds suggest that performance improves when the preference cone is narrow or when optimal arms are well-separated.
- Extensions could replace the linear cone with other convex sets while preserving the directional confidence construction.
Load-bearing premise
Admissible trade-offs can be represented by a polyhedral preference cone that captures the partially specified linear preferences over model capabilities.
What would settle it
An experiment on a PDMOB instance with a known polyhedral cone in which PrefUCB regret grows faster than logarithmically with T would falsify the claimed bounds.
Figures

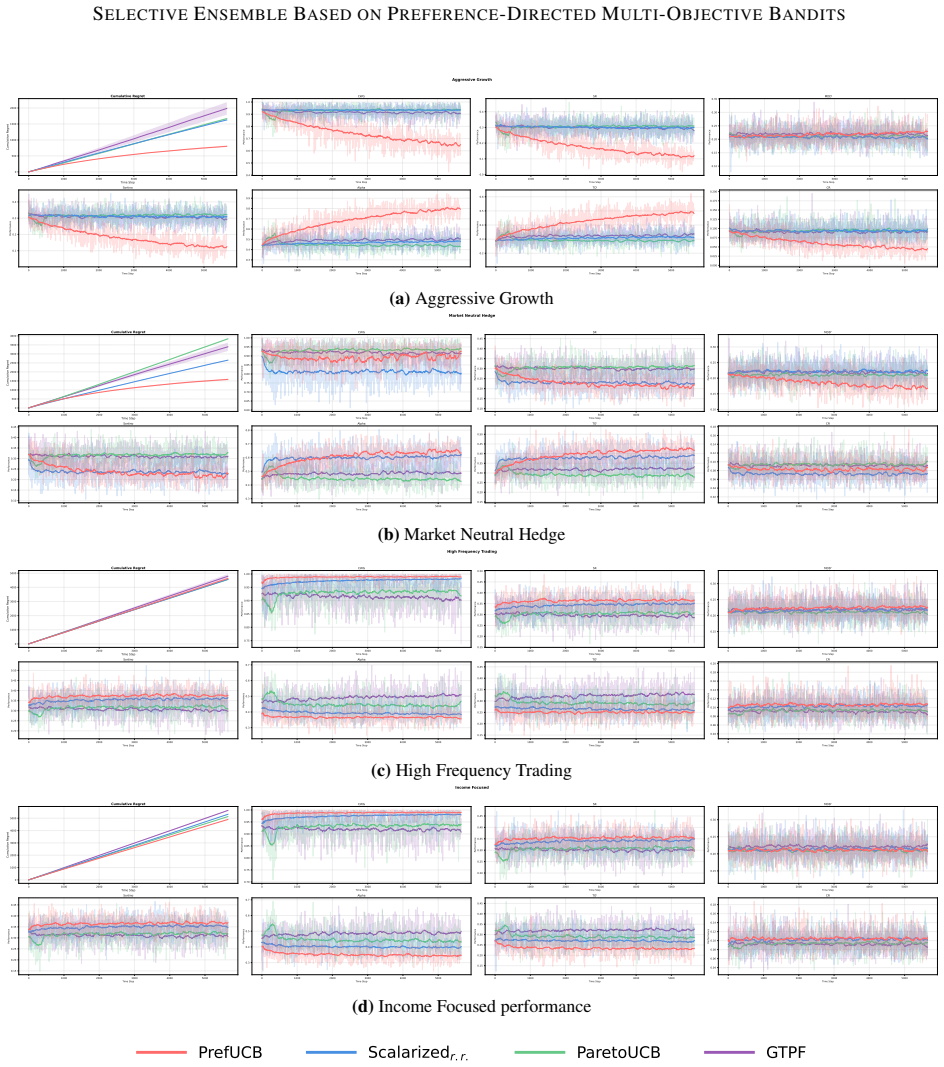
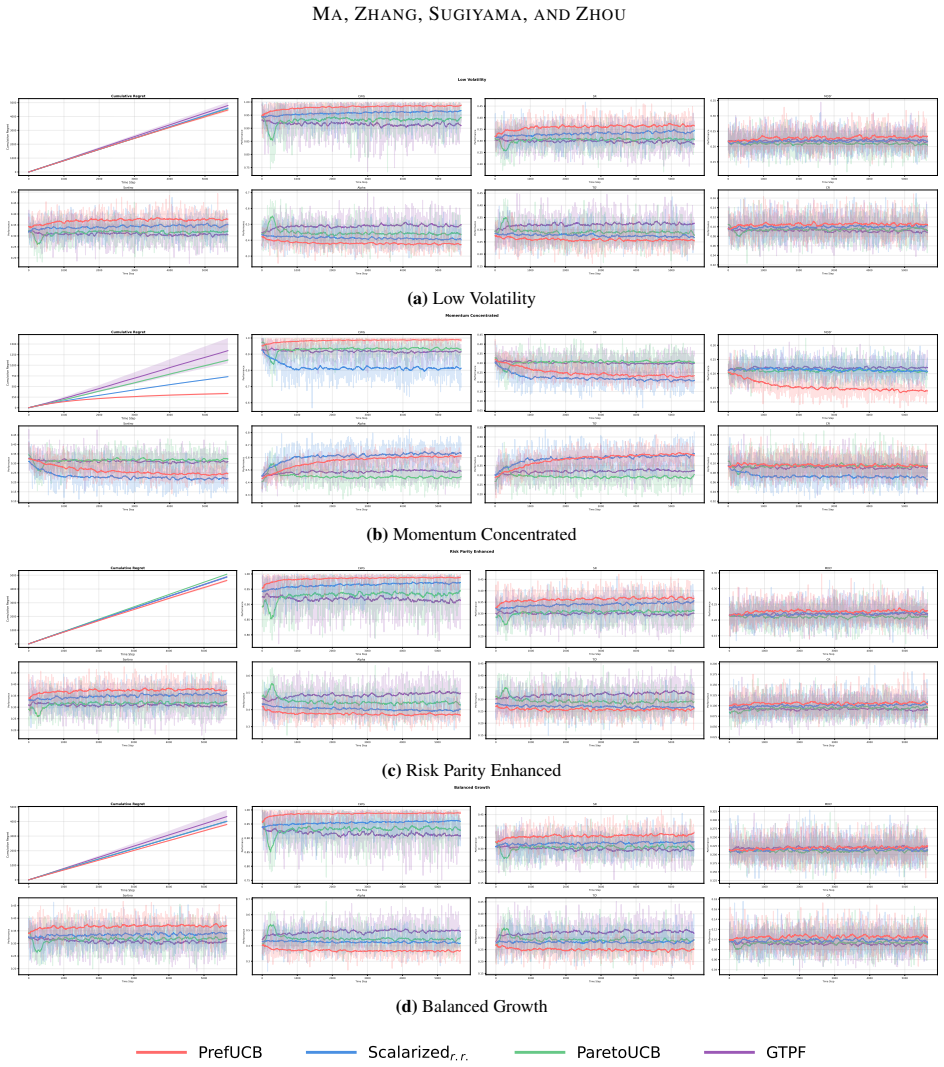
read the original abstract
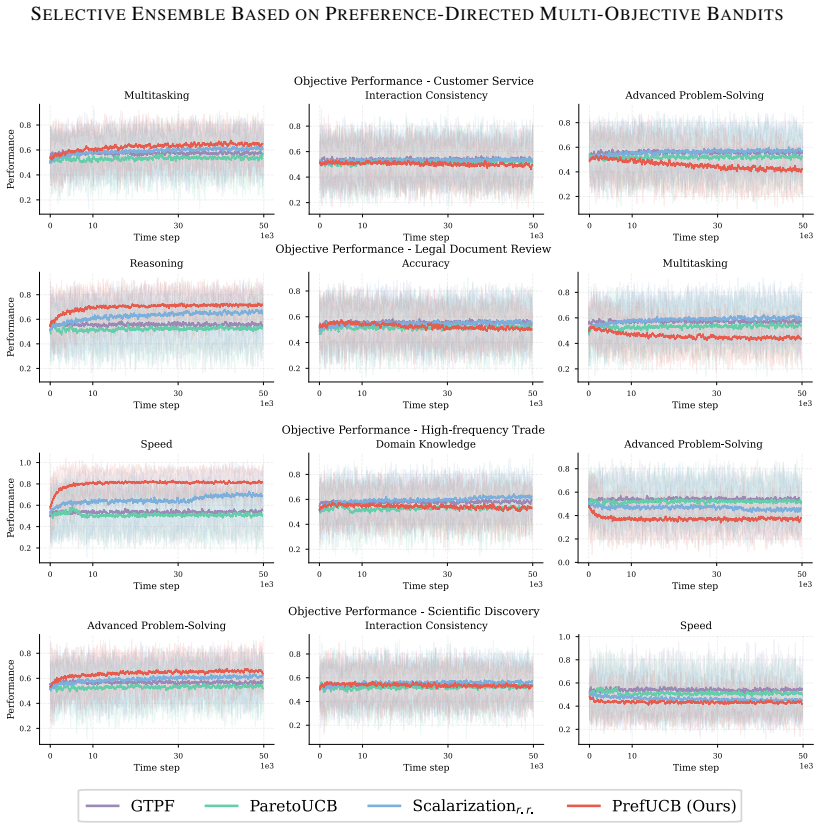
Selective ensemble for modern machine learning systems requires choosing promising model candidates under limited evaluation budgets, while downstream tasks often specify only partial preferences over capabilities such as accuracy, robustness, and reasoning. This setting naturally gives rise to a sequential decision problem under partially specified linear preferences. We formalize it as preference-directed multi-objective bandits (PDMOB), where admissible trade-offs are represented by a polyhedral preference cone. Based on this formulation, we introduce Pareto $C$-optimality, which recovers standard Pareto optimality and single-weight scalarization as special cases. We then propose the preference-directed upper confidence bound (PrefUCB) algorithm, which maintains directional confidence intervals to guide exploration. We analyze both indicator-based and gap-weighted regret, and establish instance-dependent logarithmic bounds for both criteria, recovering the optimal logarithmic dependence on the horizon $T$ in classical special cases. Experiments on large pre-trained model selective ensemble tasks and online asset allocation under institutional mandates validate the efficacy of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes preference-directed multi-objective bandits (PDMOB) in which admissible trade-offs are represented by a polyhedral preference cone. It defines Pareto C-optimality (recovering standard Pareto optimality and single-weight scalarization as special cases), proposes the PrefUCB algorithm that maintains directional confidence intervals, and claims instance-dependent logarithmic regret bounds for both indicator-based and gap-weighted criteria that recover the classical single-objective logarithmic dependence on T when the cone degenerates to a ray. Experiments are reported on selective ensemble tasks for large pre-trained models and online asset allocation under institutional mandates.
Significance. If the claimed regret bounds hold, the work supplies a coherent generalization of vector-valued bandits to partially specified linear preferences, with the directional UCB construction and the recovery of optimal T-dependence in the classical limit constituting clear technical strengths. The application to selective ensembles under institutional mandates is a natural and timely use case.
minor comments (3)
- [Abstract and §3] The abstract states that both indicator-based and gap-weighted regret receive instance-dependent logarithmic bounds, but the precise definitions of these two regret measures and the exact statement of the bounds (including any dependence on the cone geometry) should be stated explicitly in the main text before the analysis section.
- [§4 and experimental setup] The polyhedral cone is described as capturing 'partially specified linear preferences,' yet the paper should clarify how the cone is constructed from the institutional mandate in the asset-allocation experiment and whether the construction is unique or requires additional modeling choices.
- [§3.2] Notation for the directional confidence intervals and the projection onto the cone should be introduced once and used consistently; several symbols appear to be overloaded between the vector-valued reward and the preference direction.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our formalization of preference-directed multi-objective bandits, the introduction of Pareto C-optimality, and the PrefUCB algorithm, as well as for the recommendation of minor revision. We are prepared to incorporate any minor adjustments in the revised manuscript.
Circularity Check
No significant circularity detected
full rationale
The paper introduces a PDMOB formulation using a polyhedral preference cone, defines Pareto C-optimality recovering standard Pareto and scalarization as special cases, proposes the PrefUCB algorithm with directional confidence intervals, and derives instance-dependent logarithmic regret bounds for indicator-based and gap-weighted criteria that recover classical single-objective cases. These elements follow standard multi-objective bandit analysis without any quoted reduction of the central claims (regret bounds or optimality) to fitted parameters, self-definitions, or self-citation chains by construction. The derivation chain is self-contained against external benchmarks with independent mathematical content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
1999 , publisher =
Nonlinear Multiobjective Optimization , author =. 1999 , publisher =
1999
-
[2]
Proceedings of the 24th Annual Conference on Learning Theory (COLT) , pages =
Garivier, Aurelien and Cappe, Olivier , title =. Proceedings of the 24th Annual Conference on Learning Theory (COLT) , pages =
-
[3]
Journal of Business Economics , volume =
Nasim Nasrabadi and Akram Dehnokhalaji and Pekka Korhonen and Jyrki Wallenius , title =. Journal of Business Economics , volume =
-
[4]
Korhonen and Majid Soleimani-Damaneh and Jyrki Wallenius , title =
Pekka J. Korhonen and Majid Soleimani-Damaneh and Jyrki Wallenius , title =. European Journal of Operational Research , volume =
-
[5]
Lisha Chen and A. F. M. Saif and Yanning Shen and Tianyi Chen , title =. Advances in Neural Information Processing Systems 37 (NeurIPS) , pages =
-
[6]
Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI) , pages =
Shiyin Lu and Guanghui Wang and Yao Hu and Lijun Zhang , title =. Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI) , pages =
-
[7]
Proceedings of the 40th International Conference on Machine Learning (ICML) , pages =
Mengfan Xu and Diego Klabjan , title =. Proceedings of the 40th International Conference on Machine Learning (ICML) , pages =
-
[8]
Pareto Front Identification from Stochastic Bandit Feedback , booktitle =
Peter Auer and Chao. Pareto Front Identification from Stochastic Bandit Feedback , booktitle =
-
[9]
Sequential Learning of the Pareto Front for Multi-objective Bandits , booktitle =
-
[10]
Multi-objective Bandits: Optimizing the Generalized Gini Index , booktitle =
R. Multi-objective Bandits: Optimizing the Generalized Gini Index , booktitle =
-
[11]
IEEE Transactions on Signal Processing , volume =
Cem Tekin and Eralp Turgay , title =. IEEE Transactions on Signal Processing , volume =
-
[12]
Multi-objective multi-armed bandit with lexicographically ordered and satisficing objectives , journal =
Alihan H. Multi-objective multi-armed bandit with lexicographically ordered and satisficing objectives , journal =
-
[13]
Proceedings of the 38th
Ji Cheng and Bo Xue and Jiaxiang Yi and Qingfu Zhang , title =. Proceedings of the 38th
-
[14]
Roijers and Ann Now
Mathieu Reymond and Eugenio Bargiacchi and Diederik M. Roijers and Ann Now. Interactively Learning the User's Utility for Best-Arm Identification in Multi-Objective Multi-Armed Bandits , booktitle =
-
[15]
Shroff , title =
Linfeng Cao and Ming Shi and Ness B. Shroff , title =. Proceedings of the 40th
-
[16]
Proceedings of the 26th International Conference on Artificial Intelligence and Statistics (AISTATS) , pages =
Cagin Ararat and Cem Tekin , title =. Proceedings of the 26th International Conference on Artificial Intelligence and Statistics (AISTATS) , pages =
-
[17]
Proceedings of the 27th International Conference on Artificial Intelligence and Statistics (AISTATS) , pages =
Efe Mert Karagozlu and Yasar Cahit Yildirim and Cagin Ararat and Cem Tekin , title =. Proceedings of the 27th International Conference on Artificial Intelligence and Statistics (AISTATS) , pages =
-
[18]
Advances in Neural Information Processing Systems 37 (NeurIPS) , pages =
Apurv Shukla and Debabrota Basu , title =. Advances in Neural Information Processing Systems 37 (NeurIPS) , pages =
-
[19]
ACM Computing Surveys , volume=
Online portfolio selection: A survey , author=. ACM Computing Surveys , volume=
-
[20]
Mathematical Finance , volume=
Universal portfolios , author=. Mathematical Finance , volume=
-
[21]
Drugan and Ann Now
Madalina M. Drugan and Ann Now. Designing multi-objective multi-armed bandits algorithms:. Proceedings of the 23rd International Joint Conference on Neural Networks (IJCNN) , pages =
-
[22]
Stochastic Systems , volume=
Inferring sparse preference lists from partial information , author=. Stochastic Systems , volume=
-
[23]
Proceedings of the 34th
Jiancheng Wang and Jingjing Wang and Changlong Sun and Shoushan Li and Xiaozhong Liu and Luo Si and Min Zhang and Guodong Zhou , title =. Proceedings of the 34th
-
[24]
Integration of Rule-Based Reasoning and Transfer Learning in Legal Document Review , booktitle =
Robert Keeling and Ava Guo and Peter Gronvall and Nathaniel Huber. Integration of Rule-Based Reasoning and Transfer Learning in Legal Document Review , booktitle =
-
[25]
Multi-class imbalance problem:
Yi. Multi-class imbalance problem:. Information Science , volume =
-
[26]
Multi-objective Evolutionary Ensemble Pruning Guided by Margin Distribution , booktitle =
Yu. Multi-objective Evolutionary Ensemble Pruning Guided by Margin Distribution , booktitle =
-
[27]
Pareto Ensemble Pruning , booktitle =
Chao Qian and Yang Yu and Zhi. Pareto Ensemble Pruning , booktitle =
-
[28]
Evolutionary Learning: Advances in Theories and Algorithms , publisher =
Zhi. Evolutionary Learning: Advances in Theories and Algorithms , publisher =
-
[29]
Diversity Regularized Ensemble Pruning , booktitle =
Nan Li and Yang Yu and Zhi. Diversity Regularized Ensemble Pruning , booktitle =
-
[30]
Banfield and Lawrence O
Robert E. Banfield and Lawrence O. Hall and Kevin W. Bowyer and W. Philip Kegelmeyer , title =. Information Fusion , volume =
-
[31]
Margineantu and Thomas G
Dragos D. Margineantu and Thomas G. Dietterich , title =. Proceedings of the 14th International Conference on Machine Learning (ICML) , pages =
-
[32]
Artificial Intelligence Review , volume =
Lior Rokach , title =. Artificial Intelligence Review , volume =
-
[33]
Selective Ensemble of Classifier Chains , booktitle =
Nan Li and Zhi. Selective Ensemble of Classifier Chains , booktitle =
-
[34]
2012 , publisher=
Ensemble methods: foundations and algorithms , author=. 2012 , publisher=
2012
-
[35]
Ensembling neural networks: Many could be better than all , journal =
Zhi. Ensembling neural networks: Many could be better than all , journal =
-
[36]
Machine Learning , volume =
Leo Breiman , title =. Machine Learning , volume =
-
[37]
Wolpert , title =
David H. Wolpert , title =. Neural Networks , volume =
-
[38]
Handling Varied Objectives by Online Decision Making , booktitle =
Lanjihong Ma and Zhen. Handling Varied Objectives by Online Decision Making , booktitle =
-
[39]
Vector Optimization with Stochastic Bandit Feedback , booktitle =
-
[40]
Roijers and Luisa M
Diederik M. Roijers and Luisa M. Zintgraf and Pieter Libin and Mathieu Reymond and Eugenio Bargiacchi and Ann Now. Interactive Multi-objective Reinforcement Learning in Multi-armed Bandits with Gaussian Process Utility Models , booktitle =
-
[41]
Advances in Neural Information Processing Systems 32 (NeurIPS) , pages =
Majid Abdolshah and Alistair Shilton and Santu Rana and Sunil Gupta and Svetha Venkatesh , title =. Advances in Neural Information Processing Systems 32 (NeurIPS) , pages =
-
[42]
Frazier , title =
Raul Astudillo and Peter I. Frazier , title =. Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS) , pages =
-
[43]
A Flexible Framework for Multi-Objective Bayesian Optimization using Random Scalarizations , booktitle =
Biswajit Paria and Kirthevasan Kandasamy and Barnab. A Flexible Framework for Multi-Objective Bayesian Optimization using Random Scalarizations , booktitle =
-
[44]
Roijers and Luisa M
Diederik M. Roijers and Luisa M. Zintgraf and Ann Now. Interactive Thompson Sampling for Multi-objective Multi-armed Bandits , booktitle =
-
[45]
Machine Learning , volume =
Anmol Kagrecha and Jayakrishnan Nair and Krishna Jagannathan , title =. Machine Learning , volume =
-
[46]
Villar and Mihaela van der Schaar , title =
Cong Shen and Zhiyang Wang and Sofia S. Villar and Mihaela van der Schaar , title =. Proceedings of the 37th International Conference on Machine Learning (ICML) , pages =
-
[47]
Deep Learning , author=
-
[48]
2021 , publisher=
Beyond the worst-case analysis of algorithms , author=. 2021 , publisher=
2021
-
[49]
2021 , publisher=
Machine learning , author=. 2021 , publisher=
2021
-
[50]
Burdick and Yisong Yue , title =
Yanan Sui and Vincent Zhuang and Joel W. Burdick and Yisong Yue , title =. Proceedings of the 35th International Conference on Machine Learning (ICML) , pages =
-
[51]
Burdick and Andreas Krause , title =
Yanan Sui and Alkis Gotovos and Joel W. Burdick and Andreas Krause , title =. Proceedings of the 32nd International Conference on Machine Learning (ICML) , pages =
-
[52]
Advances in Neural Information Processing Systems 33 (NeurIPS) , year =
Samuel Daulton and Maximilian Balandat and Eytan Bakshy , title =. Advances in Neural Information Processing Systems 33 (NeurIPS) , year =
-
[53]
arXiv preprint arXiv:2305.05176 , year=
Frugalgpt: How to use large language models while reducing cost and improving performance , author=. arXiv preprint arXiv:2305.05176 , year=
-
[54]
arXiv preprint arXiv:2310.12963 , year=
Automix: Automatically mixing language models , author=. arXiv preprint arXiv:2310.12963 , year=
-
[55]
arXiv preprint arXiv:2412.12170 , year=
PickLLM: Context-Aware RL-Assisted Large Language Model Routing , author=. arXiv preprint arXiv:2412.12170 , year=
-
[56]
arXiv preprint arXiv:2309.15789 , year=
Large language model routing with benchmark datasets , author=. arXiv preprint arXiv:2309.15789 , year=
-
[57]
Yahyaa and Bernard Manderick , title =
Saba Q. Yahyaa and Bernard Manderick , title =. Proceedings of the 23rd European Symposium on Artificial Neural Networks (ESANN) , pages =
-
[58]
Proceedings of the 34th
Syrine Belakaria and Aryan Deshwal and Nitthilan Kannappan Jayakodi and Janardhan Rao Doppa , title =. Proceedings of the 34th
-
[59]
Multi-Bandit Best Arm Identification , booktitle =
Victor Gabillon and Mohammad Ghavamzadeh and Alessandro Lazaric and S. Multi-Bandit Best Arm Identification , booktitle =
-
[60]
The 13th International Conference on Learning Representations , year=
Mixture of Parrots: Experts improve memorization more than reasoning , author=. The 13th International Conference on Learning Representations , year=
-
[61]
2024 , publisher =
Clémentine Fourrier and Nathan Habib and Alina Lozovskaya and Konrad Szafer and Thomas Wolf , title =. 2024 , publisher =
2024
-
[62]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Language models are few-shot learners , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[63]
arXiv preprint arXiv:2302.13971 , year=
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
-
[64]
Advances in Applied Mathematics , volume=
Asymptotically efficient adaptive allocation rules , author=. Advances in Applied Mathematics , volume=
-
[65]
Journal of Machine Learning Research , volume =
Peter Auer , title =. Journal of Machine Learning Research , volume =
-
[66]
Proceedings of the 30th International Conference on Machine Learning (ICML) , volume =
Zohar Shay Karnin and Tomer Koren and Oren Somekh , title =. Proceedings of the 30th International Conference on Machine Learning (ICML) , volume =
-
[67]
Optimal Best Arm Identification with Fixed Confidence , booktitle =
Aur. Optimal Best Arm Identification with Fixed Confidence , booktitle =
-
[68]
Proceedings of the 26th Annual Conference on Learning Theory (COLT) , volume =
Emilie Kaufmann and Shivaram Kalyanakrishnan , title =. Proceedings of the 26th Annual Conference on Learning Theory (COLT) , volume =
-
[69]
Proceedings of the 29th International Conference on Machine Learning (ICML) , year =
Shivaram Kalyanakrishnan and Ambuj Tewari and Peter Auer and Peter Stone , title =. Proceedings of the 29th International Conference on Machine Learning (ICML) , year =
-
[70]
Action Elimination and Stopping Conditions for the Multi-Armed Bandit and Reinforcement Learning Problems , journal =
Eyal Even. Action Elimination and Stopping Conditions for the Multi-Armed Bandit and Reinforcement Learning Problems , journal =
-
[71]
Proceedings of the 15th Annual Conference on Computational Learning Theory (COLT) , volume =
Eyal Even. Proceedings of the 15th Annual Conference on Computational Learning Theory (COLT) , volume =
-
[72]
Zhou Zhao and Hanqing Lu and Deng Cai and Xiaofei He and Yueting Zhuang , title =
-
[73]
Stabilizing Reinforcement Learning in Dynamic Environment with Application to Online Recommendation , booktitle =
Shi. Stabilizing Reinforcement Learning in Dynamic Environment with Application to Online Recommendation , booktitle =
-
[74]
Proceedings of the 22nd
Chunqiu Zeng and Qing Wang and Shekoofeh Mokhtari and Tao Li , title =. Proceedings of the 22nd
-
[75]
Applied Mathematics and Optimization , volume=
Pareto optimality in multiobjective problems , author=. Applied Mathematics and Optimization , volume=
-
[76]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[77]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[78]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[79]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[80]
International Journal of Man-Machine Studies , volume = 20, number = 1, pages =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.