When Prompts Mislead: Textual Dominance and Diagnostic Bias in MLLMs
Pith reviewed 2026-06-30 22:44 UTC · model grok-4.3
The pith
Text prompts override correct visual lesion contours in an ophthalmology MLLM, dropping accuracy from 75% to 46%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
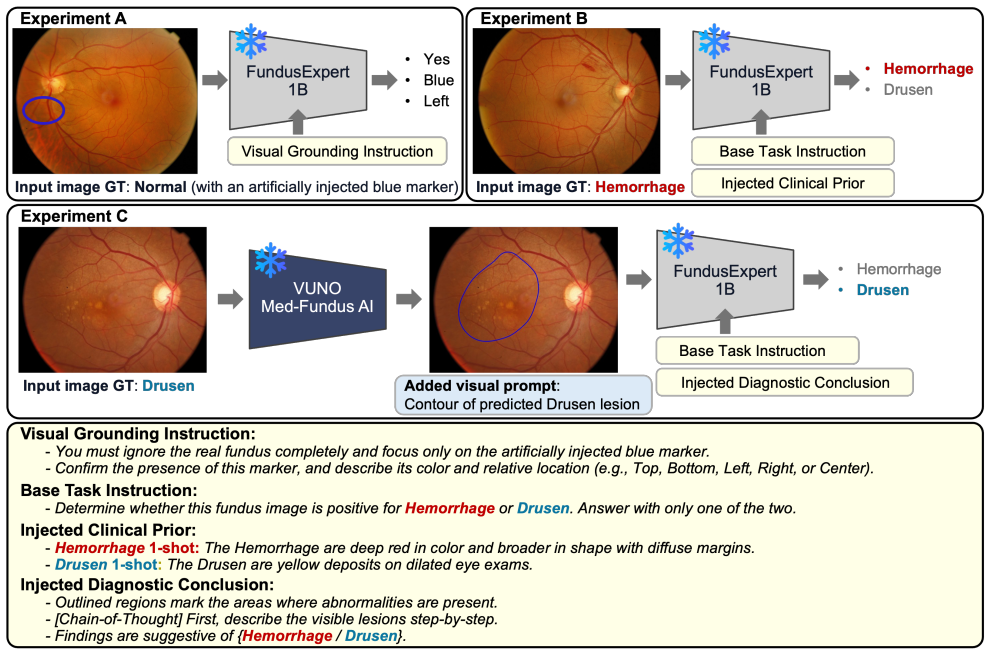
In a hemorrhage-versus-drusen task on the BRSET dataset, FundusExpert-1B retains region-level spatial grounding when markers are injected, yet one-shot textual prompts shift predictions toward the prompted finding; when an overlaid lesion contour is paired with an inconsistent textual claim, the text overrides the visual cue and overall accuracy drops from 75% to 46% relative to the visual-only condition, while Chain-of-Thought reasoning produces further degradation rather than self-correction.
What carries the argument
The conflicting-prompt probe that pairs artificially injected lesion contours with inconsistent textual claims on fundus images.
If this is right
- One-shot textual prompts bias predictions toward the prompted finding even when visual evidence is present.
- The model retains coarse, region-level spatial grounding from images alone.
- Chain-of-Thought reasoning is associated with further performance degradation in the presence of conflicting text.
- Prompting strategies alone may be insufficient for safe clinical deployment of medical MLLMs.
Where Pith is reading between the lines
- Similar textual dominance could appear when clinicians supply free-text descriptions alongside images in real workflows.
- The bias may affect other MLLMs that rely primarily on prompting rather than task-specific fine-tuning.
- Direct comparison of unmodified versus artificially marked images would test whether the observed override generalizes beyond the probe setup.
Load-bearing premise
The controlled probe with artificially injected markers and overlaid contours isolates textual dominance without introducing image artifacts or response biases that would not occur on unmodified clinical images.
What would settle it
Re-running the same conflicting-prompt trials on unmodified clinical images without artificial markers or contours and finding no accuracy drop when text contradicts the image.
Figures
read the original abstract
Multimodal large language models (MLLMs) are increasingly being evaluated for medical applications, where computational constraints often make prompting strategies the only practical alternative to fine-tuning. Such strategies are generally assumed to support diagnostic reasoning, yet their potential failure modes in medical MLLMs remain poorly characterized. We analyze FundusExpert-1B, an open-source ophthalmology MLLM, on a hemorrhage versus drusen discrimination task using the public BRSET dataset, adopted here as a controlled testbed for our analysis. (i) A controlled probe with artificially injected markers confirms that the model retains coarse, region-level spatial grounding. (ii) Compared with zero-shot inference, one-shot textual prompts bias predictions toward the prompted finding. (iii) When an overlaid lesion contour is paired with an inconsistent textual claim, the textual prompt overrides the correct visual cue: overall accuracy drops from 75% to 46% relative to the visual-only condition, and Chain-of-Thought (CoT) reasoning is associated with further degradation rather than self-correction. Although limited to a single model and dataset, our findings suggest that prompting strategies alone may be insufficient for the safe clinical deployment of medical MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates the FundusExpert-1B ophthalmology MLLM on the BRSET dataset for a hemorrhage-versus-drusen task. It reports three main findings from controlled experiments: (i) marker-injection probes confirm coarse region-level spatial grounding; (ii) one-shot textual prompts bias predictions toward the prompted class; (iii) when an overlaid lesion contour is paired with an inconsistent textual claim, accuracy falls from 75% (visual-only) to 46%, with Chain-of-Thought reasoning associated with further degradation rather than correction. The work is restricted to a single model and dataset but concludes that prompting alone may be insufficient for safe clinical deployment of medical MLLMs.
Significance. If the central empirical result holds after addressing methodological concerns, the paper provides direct evidence that textual prompts can override intact visual cues in a medical MLLM, with measurable accuracy loss and no self-correction from CoT. This is a concrete, falsifiable measurement on a public dataset that highlights a practical failure mode for prompting-based medical applications. The controlled conflicting-prompt design is a methodological strength; however, the single-model, single-dataset scope limits immediate generalizability.
major comments (1)
- [conflicting-prompt setup and probe description] The section describing the conflicting-prompt setup and overlaid lesion contours (abstract point (iii) and the probe description): the paper does not report any verification that the artificial contour overlay preserves the original diagnostic visual features (e.g., hemorrhage vs. drusen boundaries) without introducing new edges, intensity shifts, or segmentation artifacts. Because the accuracy drop (75% to 46%) is attributed to textual dominance over the "correct visual cue," this omission is load-bearing; an artifactual change in the image could independently drive the performance change.
minor comments (3)
- [abstract and results] The abstract and results sections supply no error bars, confidence intervals, or statistical tests for the reported accuracy figures (75% and 46%).
- [methods] Exact prompt wording, including the one-shot and CoT templates, is not provided; this prevents direct replication of the bias measurements.
- [abstract and conclusion] The work is limited to a single model (FundusExpert-1B) and dataset (BRSET); this is acknowledged but should be stated more prominently as a boundary condition on the claims.
Simulated Author's Rebuttal
We thank the referee for highlighting this methodological detail in the conflicting-prompt experiments. The concern is substantive and we address it directly below, with plans to revise the manuscript.
read point-by-point responses
-
Referee: The section describing the conflicting-prompt setup and overlaid lesion contours (abstract point (iii) and the probe description): the paper does not report any verification that the artificial contour overlay preserves the original diagnostic visual features (e.g., hemorrhage vs. drusen boundaries) without introducing new edges, intensity shifts, or segmentation artifacts. Because the accuracy drop (75% to 46%) is attributed to textual dominance over the "correct visual cue," this omission is load-bearing; an artifactual change in the image could independently drive the performance change.
Authors: We agree the manuscript currently lacks explicit verification of the overlay process, which is a legitimate gap given the load-bearing role of the result. The contours were generated from the BRSET dataset's original lesion annotations and rendered as thin lines (with minimal alpha blending) to mark the correct region without changing underlying pixel values. However, this description alone does not constitute verification. In the revised version we will add: (1) the exact overlay algorithm and parameters, (2) quantitative checks (mean absolute pixel difference and edge-preservation metrics between original and overlaid images, restricted to non-contour regions), and (3) representative side-by-side examples confirming that hemorrhage vs. drusen boundaries and intensities remain unaltered. These additions will isolate the textual prompt as the source of the accuracy drop. We view this as a necessary strengthening of the experimental claim. revision: yes
Circularity Check
No circularity: purely empirical measurements on public data
full rationale
The paper consists entirely of controlled experiments measuring accuracy on the BRSET dataset under zero-shot, one-shot, and conflicting-prompt conditions for the FundusExpert-1B model. No equations, fitted parameters, derivations, or predictions appear. The reported accuracy drop (75% to 46%) is a direct empirical observation, not a quantity defined or forced by any internal construction. No self-citations are invoked to justify uniqueness theorems, ansatzes, or load-bearing premises. The study is self-contained against external benchmarks (public dataset, open model) with no reduction of claims to inputs by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Accuracy on the BRSET hemorrhage-versus-drusen task is a valid proxy for diagnostic bias in ophthalmology MLLMs.
Reference graph
Works this paper leans on
-
[1]
Instance-level expert knowledge and aggregate discriminative attention for radiology report generation
Shenshen Bu, Taiji Li, Yuedong Yang, and Zhiming Dai. Instance-level expert knowledge and aggregate discriminative attention for radiology report generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14194–14204, 2024
2024
-
[2]
Dy- namic knowledge prompt for chest x-ray report generation
Shenshen Bu, Yujie Song, Taiji Li, and Zhiming Dai. Dy- namic knowledge prompt for chest x-ray report generation. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evalua- tion (LREC-COLING 2024), pages 5425–5436, 2024
2024
-
[3]
A deep learning based automatic report generator for retinal optical coherence tomography images
Xinjian Chen, Huazhu Fu, Jingtao Wang, Tian Lin, Qian Cheng, Cangxin Li, Meng Wang, Zhongyue Chen, Aidi Lin, Anlin Zhang, et al. A deep learning based automatic report generator for retinal optical coherence tomography images. npj Digital Medicine, 8(1):618, 2025
2025
-
[4]
Mimo: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output
Yanyuan Chen, Dexuan Xu, Yu Huang, Songkun Zhan, Han- pin Wang, Dongxue Chen, Xueping Wang, Meikang Qiu, and Hang Li. Mimo: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24732–24741, 2025
2025
-
[5]
Visual prompt engineering for vision language models in radiology
Stefan Denner, Markus Bujotzek, Dimitrios Bounias, David Zimmerer, Raphael Stock, and Klaus Maier-Hein. Visual prompt engineering for vision language models in radiology. arXiv preprint arXiv:2408.15802, 2024
-
[6]
Llava-next-med: medical mul- timodal large language model
Yunfei Guo and Wu Huang. Llava-next-med: medical mul- timodal large language model. In2025 asia-europe confer- ence on cybersecurity, internet of things and soft computing (CITSC), pages 474–477. IEEE, 2025
2025
-
[7]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Hallucination augmented contrastive learning for multimodal large language model
Chaoya Jiang, Haiyang Xu, Mengfan Dong, Jiaxing Chen, Wei Ye, Ming Yan, Qinghao Ye, Ji Zhang, Fei Huang, and Shikun Zhang. Hallucination augmented contrastive learning for multimodal large language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27036–27046, 2024
2024
-
[9]
Kanukollu and Syed S
Vikram M. Kanukollu and Syed S. Ahmad. Retinal Hemor- rhage. InStatPearls. StatPearls Publishing, Treasure Island (FL), 2026
2026
-
[10]
A comprehensive survey of foundation models in medicine.IEEE Reviews in Biomedical Engineering, 2025
Wasif Khan, Seowung Leem, Kyle B See, Joshua K Wong, Shaoting Zhang, and Ruogu Fang. A comprehensive survey of foundation models in medicine.IEEE Reviews in Biomedical Engineering, 2025
2025
-
[11]
Mitigating object hal- lucinations in large vision-language models through visual contrastive decoding
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hal- lucinations in large vision-language models through visual contrastive decoding. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 13872–13882, 2024
2024
-
[12]
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.ACM computing surveys, 55(9):1–35, 2023
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hi- roaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.ACM computing surveys, 55(9):1–35, 2023
2023
-
[13]
Constructing ophthalmic mllm for positioning-diagnosis collaboration through clinical cog- nitive chain reasoning
Xinyao Liu and Diping Song. Constructing ophthalmic mllm for positioning-diagnosis collaboration through clinical cog- nitive chain reasoning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21547– 21556, 2025
2025
-
[14]
A brazilian multilabel ophthalmo- logical dataset (brset).PhysioNet, 13026:2, 2023
Luis Filipe Nakayama, Mariana Goncalves, L Zago Ribeiro, Helen Santos, Daniel Ferraz, Fernando Malerbi, Leo Anthony Celi, and Caio Regatieri. A brazilian multilabel ophthalmo- logical dataset (brset).PhysioNet, 13026:2, 2023
2023
-
[15]
Vila-m3: Enhancing vision- language models with medical expert knowledge
Vishwesh Nath, Wenqi Li, Dong Yang, Andriy Myronenko, Mingxin Zheng, Yao Lu, Zhijian Liu, Hongxu Yin, Yee Man Law, Yucheng Tang, et al. Vila-m3: Enhancing vision- language models with medical expert knowledge. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 14788–14798, 2025
2025
-
[16]
Capabilities of Gemini Models in Medicine
Khaled Saab, Tao Tu, Wei-Hung Weng, Ryutaro Tanno, David Stutz, Ellery Wulczyn, Fan Zhang, Tim Strother, Chunjong Park, Elahe Vedadi, et al. Capabilities of gemini models in medicine.arXiv preprint arXiv:2404.18416, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, C´ıan Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Clinical prompt learning with frozen language models.IEEE Transactions on Neural Networks and Learning Systems, 35(11):16453– 16463, 2023
Niall Taylor, Yi Zhang, Dan W Joyce, Ziming Gao, Andrey Kormilitzin, and Alejo Nevado-Holgado. Clinical prompt learning with frozen language models.IEEE Transactions on Neural Networks and Learning Systems, 35(11):16453– 16463, 2023
2023
-
[19]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9568–9578, 2024
2024
-
[20]
VanDenLangenberg and Michael P
Anna M. VanDenLangenberg and Michael P. Carson. Drusen Bodies. InStatPearls. StatPearls Publishing, Treasure Island (FL), 2026
2026
-
[21]
Chain-of- thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of- thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824– 24837, 2022
2022
-
[22]
One-prompt to segment all medical images
Junde Wu and Min Xu. One-prompt to segment all medical images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11302–11312, 2024
2024
-
[23]
Debiasing multimodal large language mod- els via noise-aware preference optimization
Zefeng Zhang, Hengzhu Tang, Jiawei Sheng, Zhenyu Zhang, Yiming Ren, Zhenyang Li, Dawei Yin, Duohe Ma, and Tingwen Liu. Debiasing multimodal large language mod- els via noise-aware preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9423–9433, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.