Graph Set Transformer
Pith reviewed 2026-06-28 07:03 UTC · model grok-4.3
The pith
Graph Set Transformer interleaves node-level propagation with cross-graph context at every layer through a gate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
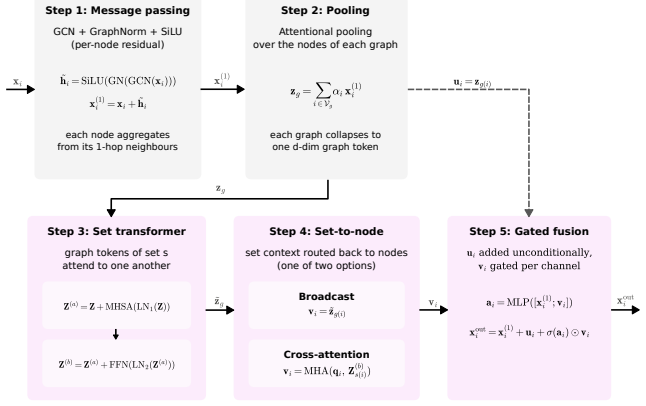
GST interleaves node-level feature propagation and cross-graph contextual modelling at every layer, fusing the two levels of information through a gating mechanism, and performs better than the baselines across these settings under matched parameter budgets.
What carries the argument
Interleaving of node-level feature propagation and cross-graph contextual modelling at every layer, fused by a gating mechanism.
If this is right
- Per-graph predictions can draw on set context without a separate pre-encoding stage that creates an information bottleneck.
- Local structure and global set signals remain coupled throughout training rather than being isolated in successive modules.
- The same architecture yields gains on per-atom reaction-centre identification, reaction yield prediction, and image classification under equal parameter counts.
- Ablation results tie the observed improvement directly to the repeated interleaving rather than to capacity alone.
Where Pith is reading between the lines
- The same layer-wise fusion pattern could be tested on other collections of structured objects such as point clouds or molecular conformers.
- Joint optimisation of local and contextual features may reduce the need for staged pre-training pipelines in multi-scale graph problems.
- The design suggests that similar interleaving could help models that must reason about both individual elements and their group statistics.
Load-bearing premise
That the gating mechanism can stably and effectively fuse local node features with set-wide context without introducing training instability or requiring additional hyperparameters that would undermine the claimed advantage over the two-stage baseline.
What would settle it
Training GST with the interleaving disabled on the synthetic set-conditional reasoning suite and checking whether accuracy falls to the level of the two-stage baseline.
Figures
read the original abstract
We introduce the Graph Set Transformer (GST), a neural network architecture for learning on sets of graphs, designed for tasks in which per-element predictions depend on set-wide context as well as local structure. Existing architectures, including DeepSets and SetTransformer, require pre-encoded graph embeddings from a separate GNN, creating a bottleneck between feature extraction and set-level contextualisation. In contrast, GST interleaves node-level feature propagation and cross-graph contextual modelling at every layer, fusing the two levels of information through a gating mechanism. We evaluate GST on a controlled synthetic suite designed to isolate set-conditional structural reasoning and on three real-data benchmarks spanning per-atom reaction-centre identification, reaction yield prediction, and image classification. Under matched parameter budgets, GST performs better than the baselines across these settings. An architectural ablation strongly suggests that the interleaving of local and set context contributes substantially to this advantage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Graph Set Transformer (GST), an architecture for sets of graphs in which per-element predictions depend on both local graph structure and set-wide context. It interleaves node-level feature propagation with cross-graph contextual modeling at every layer, fusing the levels via a gating mechanism, in contrast to two-stage baselines (separate GNN encoding followed by DeepSets or SetTransformer). The central claim is that GST outperforms these baselines on a controlled synthetic suite isolating set-conditional structural reasoning and on three real benchmarks (per-atom reaction-centre identification, reaction yield prediction, image classification) under matched parameter budgets, with an architectural ablation indicating that the interleaving contributes substantially to the advantage.
Significance. If the performance claims hold with proper quantitative support, the interleaving design could remove the information bottleneck between graph encoding and set-level reasoning, offering a more end-to-end trainable alternative for set-of-graphs tasks in chemistry and related domains.
major comments (2)
- [Abstract] Abstract: The assertion of superior performance 'across these settings' under matched parameter budgets supplies no quantitative results, error bars, dataset sizes, or statistical tests, so the central empirical claim cannot be verified from the manuscript text.
- [Abstract] Abstract: The claim that 'an architectural ablation strongly suggests that the interleaving of local and set context contributes substantially' is load-bearing for the advantage over two-stage baselines, yet no quantitative evidence is given on gating dynamics, sensitivity to initialization, training stability, or whether the gating introduces extra hyperparameters.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of superior performance 'across these settings' under matched parameter budgets supplies no quantitative results, error bars, dataset sizes, or statistical tests, so the central empirical claim cannot be verified from the manuscript text.
Authors: The abstract is intentionally concise and does not contain numerical details; the full manuscript reports all quantitative results, including performance tables with means and standard deviations (error bars), dataset sizes, and direct comparisons under matched parameter counts in Sections 4 and 5. We will revise the abstract to incorporate a small number of key metrics so that the performance claim is more immediately verifiable. revision: partial
-
Referee: [Abstract] Abstract: The claim that 'an architectural ablation strongly suggests that the interleaving of local and set context contributes substantially' is load-bearing for the advantage over two-stage baselines, yet no quantitative evidence is given on gating dynamics, sensitivity to initialization, training stability, or whether the gating introduces extra hyperparameters.
Authors: The ablation study (Section 4.3) already provides quantitative performance deltas that isolate the contribution of interleaving versus separate GNN+SetTransformer pipelines. Detailed analyses of gating activation statistics, initialization sensitivity, and training curves were omitted from the initial submission; we will add these in a revision (e.g., supplementary figures). The gating mechanism introduces only a small number of additional parameters that are already accounted for in the matched-budget experiments. revision: yes
Circularity Check
No circularity: architecture proposal and empirical comparison are self-contained
full rationale
The paper proposes the GST architecture as an interleaving of node-level GNN propagation and set-level attention with a gating mechanism, then reports empirical results on synthetic and real benchmarks under matched parameter budgets. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim rests on the design choice and ablation experiments rather than any reduction of outputs to inputs by construction. This is the normal case for an architectural contribution without mathematical derivation chains.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions of neural network expressivity and optimization apply to the interleaved architecture.
Reference graph
Works this paper leans on
-
[1]
Deep Sets , url =
Zaheer, Manzil and Kottur, Satwik and Ravanbakhsh, Siamak and Poczos, Barnabas and Salakhutdinov, Russ R and Smola, Alexander J , booktitle =. Deep Sets , url =
-
[2]
Proceedings of the 36th International Conference on Machine Learning , pages =
Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[3]
Convolutional Set Transformer , publisher =
Chinello, Federico and Boracchi, Giacomo , keywords =. Convolutional Set Transformer , publisher =. 2025 , copyright =. doi:10.48550/ARXIV.2509.22889 , url =
-
[4]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Deep Residual Learning for Image Recognition , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[5]
Ba, Jimmy Lei and Kiros, Jamie Ryan and Hinton, Geoffrey E. , keywords =. Layer Normalization , publisher =. 2016 , copyright =. doi:10.48550/ARXIV.1607.06450 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1607.06450 2016
-
[6]
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Lukasz and Polosukhin, Illia , keywords =. Attention Is All You Need , publisher =. 2017 , copyright =. doi:10.48550/ARXIV.1706.03762 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762 2017
-
[7]
Molecular set representation learning , volume =
Boulougouri, Maria and Vandergheynst, Pierre and Probst, Daniel , year =. Molecular set representation learning , volume =. Nature Machine Intelligence , publisher =. doi:10.1038/s42256-024-00856-0 , number =
-
[8]
Goldman, Samuel and Wohlwend, Jeremy and Stražar, Martin and Haroush, Guy and Xavier, Ramnik J. and Coley, Connor W. , year =. Annotating metabolite mass spectra with domain-inspired chemical formula transformers , volume =. Nature Machine Intelligence , publisher =. doi:10.1038/s42256-023-00708-3 , number =
-
[9]
Order Matters: Sequence to sequence for sets
Vinyals, Oriol and Bengio, Samy and Kudlur, Manjunath , keywords =. Order Matters: Sequence to sequence for sets , publisher =. 2015 , copyright =. doi:10.48550/ARXIV.1511.06391 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1511.06391 2015
-
[10]
Qi and Su, Hao and Kaichun, Mo and Guibas, Leonidas J
Charles, R. Qi and Su, Hao and Kaichun, Mo and Guibas, Leonidas J. , year =. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation , url =. doi:10.1109/cvpr.2017.16 , booktitle =
-
[11]
Veličković, Petar and Cucurull, Guillem and Casanova, Arantxa and Romero, Adriana and Liò, Pietro and Bengio, Yoshua , keywords =. Graph Attention Networks , publisher =. 2017 , copyright =. doi:10.48550/ARXIV.1710.10903 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1710.10903 2017
-
[12]
and Krizhevsky, Alex and Sutskever, Ilya and Salakhutdinov, Ruslan , year =
Srivastava, Nitish and Hinton, Geoffrey E. and Krizhevsky, Alex and Sutskever, Ilya and Salakhutdinov, Ruslan , year =. Dropout: A Simple Way to Prevent Neural Networks from Overfitting , volume =. Journal of Machine Learning Research , publisher =
-
[13]
Decoupled Weight Decay Regularization , url=
Loshchilov, Ilya and Hutter, Frank , booktitle=. Decoupled Weight Decay Regularization , url=
-
[14]
PyTorch: An Imperative Style, High-Performance Deep Learning Library , url =
Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and Antiga, Luca and Desmaison, Alban and Köpf, Andreas and Yang, Edward and DeVito, Zachary and Raison, Martin and Tejani, Alykhan and Chilamkurthy, Sasank and Steiner, Benoit and Fang, Lu an...
-
[15]
ICLR Workshop on Representation Learning on Graphs and Manifolds , author =
Fast Graph Representation Learning with. ICLR Workshop on Representation Learning on Graphs and Manifolds , author =
-
[16]
Semi-Supervised Classification with Graph Convolutional Networks
Kipf, Thomas N. and Welling, Max , keywords =. Semi-Supervised Classification with Graph Convolutional Networks , publisher =. 2016 , copyright =. doi:10.48550/ARXIV.1609.02907 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1609.02907 2016
-
[17]
2009 , publisher=
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
2009
-
[18]
and Luu, Anh Tuan and Laurent, Thomas and Bengio, Yoshua and Bresson, Xavier , title =
Dwivedi, Vijay Prakash and Joshi, Chaitanya K. and Luu, Anh Tuan and Laurent, Thomas and Bengio, Yoshua and Bresson, Xavier , title =. J. Mach. Learn. Res. , month = jan, articleno =. 2023 , issue_date =
2023
-
[19]
and Sun, Yizhou and Wang, Wei , year = 2024, booktitle =
Zhu, Yanqiao and Hwang, Jeehyun and Adams, Keir and Liu, Zhen and Nan, Bozhao and Stenfors, Brock and Du, Yuanqi and Chauhan, Jatin and Wiest, Olaf and Isayev, Olexandr and Coley, Connor W. and Sun, Yizhou and Wang, Wei , year = 2024, booktitle =
2024
-
[20]
and Gomes, Joseph and Geniesse, Caleb and Pappu, Aneesh S
Wu, Zhenqin and Ramsundar, Bharath and Feinberg, Evan N. and Gomes, Joseph and Geniesse, Caleb and Pappu, Aneesh S. and Leswing, Karl and Pande, Vijay , year =. MoleculeNet: a benchmark for molecular machine learning , volume =. Chemical Science , publisher =. doi:10.1039/c7sc02664a , number =
-
[21]
Therapeutics Data Commons: Machine Learning Datasets and Tasks for Drug Discovery and Development , url =
Huang, Kexin and Fu, Tianfan and Gao, Wenhao and Zhao, Yue and Roohani, Yusuf and Leskovec, Jure and Coley, Connor and Xiao, Cao and Sun, Jimeng and Zitnik, Marinka , booktitle =. Therapeutics Data Commons: Machine Learning Datasets and Tasks for Drug Discovery and Development , url =
-
[22]
Proceedings of the National Academy of Sciences , volume =
Jae Yong Ryu and Hyun Uk Kim and Sang Yup Lee , title =. Proceedings of the National Academy of Sciences , volume =. 2018 , doi =
2018
-
[23]
GraphNorm: A Principled Approach to Accelerating Graph Neural Network Training , publisher =
Cai, Tianle and Luo, Shengjie and Xu, Keyulu and He, Di and Liu, Tie-Yan and Wang, Liwei , keywords =. GraphNorm: A Principled Approach to Accelerating Graph Neural Network Training , publisher =. 2020 , copyright =. doi:10.48550/ARXIV.2009.03294 , url =
-
[24]
Going deeper with Image Transformers , publisher =
Touvron, Hugo and Cord, Matthieu and Sablayrolles, Alexandre and Synnaeve, Gabriel and Jégou, Hervé , keywords =. Going deeper with Image Transformers , publisher =. 2021 , copyright =. doi:10.48550/ARXIV.2103.17239 , url =
-
[25]
Advances in Neural Information Processing Systems , volume=
Ladislav Ramp\'. Advances in Neural Information Processing Systems , volume=
-
[26]
Ahneman, Derek T. and Estrada, Jesús G. and Lin, Shishi and Dreher, Spencer D. and Doyle, Abigail G. , year =. Predicting reaction performance in C–N cross-coupling using machine learning , volume =. Science , publisher =. doi:10.1126/science.aar5169 , number =
-
[27]
and Barzilay, Regina and Jaakkola, Tommi , title =
Jin, Wengong and Coley, Connor W. and Barzilay, Regina and Jaakkola, Tommi , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.