Beyond Prediction: Longitudinal Reasoning in EHR-Integrated Clinical AI
Pith reviewed 2026-06-27 18:11 UTC · model grok-4.3
The pith
Clinical AI systems treat EHR data as static inputs rather than a substrate for ongoing reasoning across patient histories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
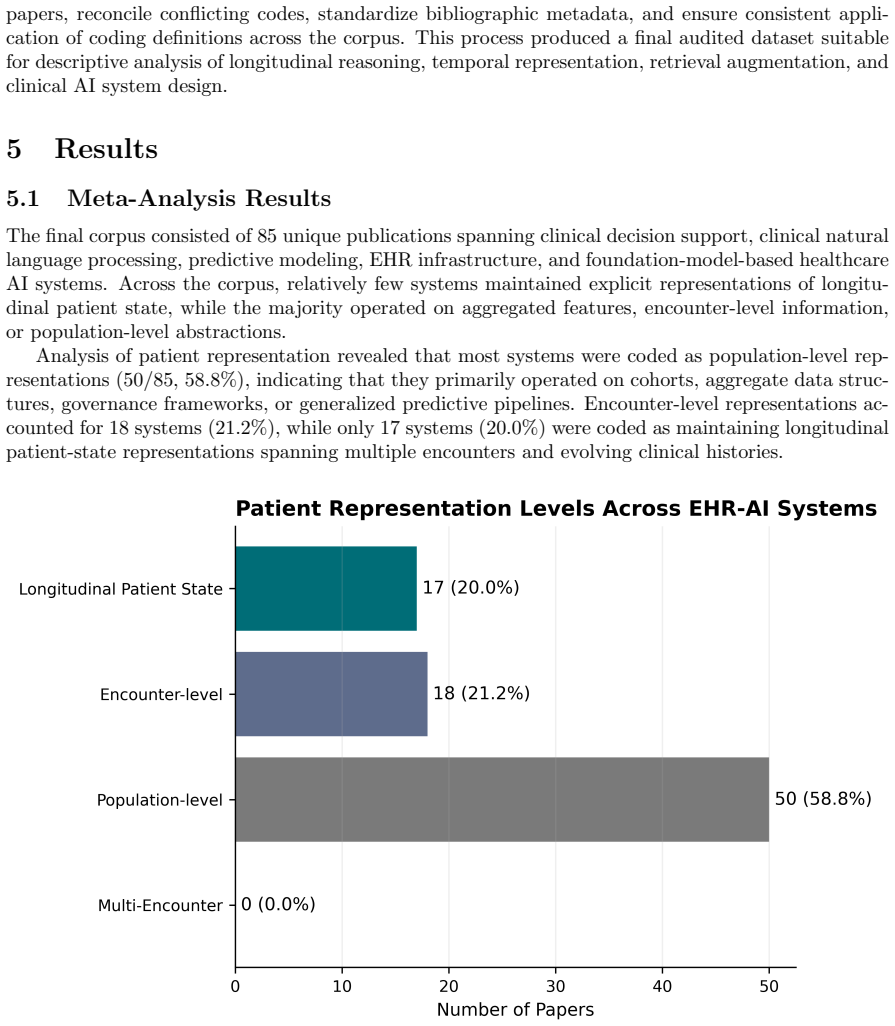
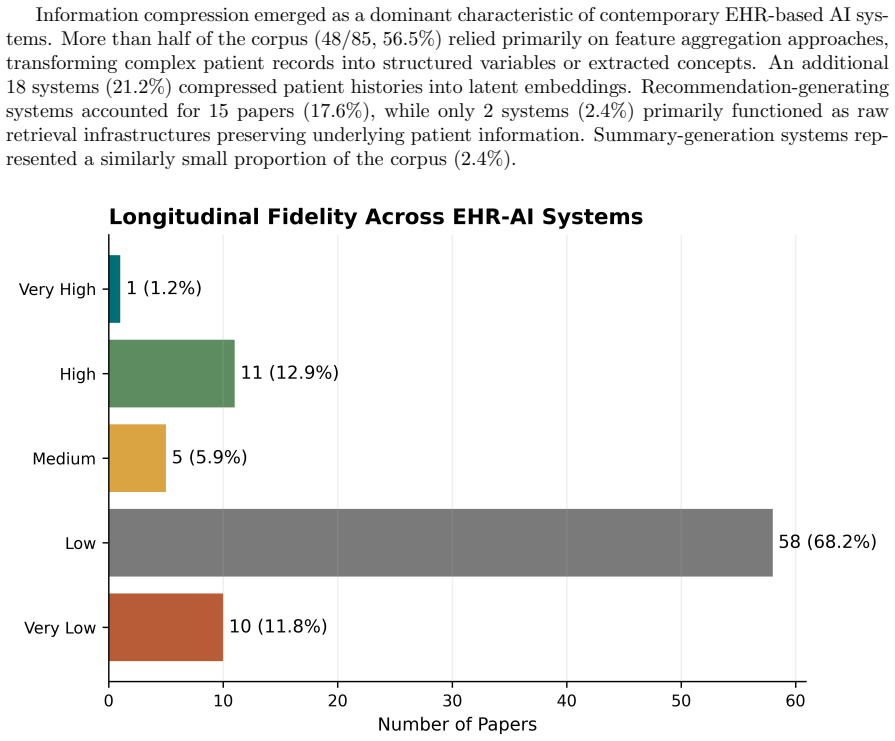
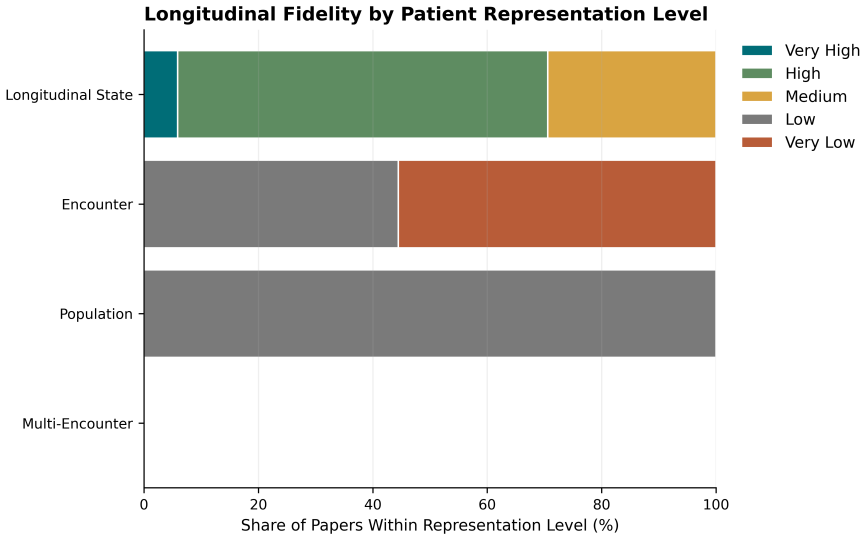
While many systems incorporate EHR data, they predominantly operate on encounter-level or aggregated representations, with limited support for explicit temporal reasoning across patient histories. Reasoning-relevant structures are inconsistently represented, and evaluation paradigms remain largely focused on predictive performance instead of longitudinal interpretability. The central argument is that current approaches treat EHR data as a static input rather than a substrate for ongoing clinical reasoning.
What carries the argument
A coding framework that captures technical integration strategies together with reasoning-relevant representational features such as trajectory modeling, cross-encounter synthesis, longitudinal analysis, and absence reasoning.
If this is right
- Systems would need to model patient trajectories explicitly rather than relying on single-encounter aggregates.
- Evaluation would shift toward metrics of longitudinal interpretability in addition to predictive accuracy.
- Future designs could treat EHR data as dynamic input supporting synthesis across encounters and absence detection.
- Clinical practice alignment would require consistent representation of temporal and interpretive features in system architectures.
Where Pith is reading between the lines
- Developers could prioritize architectures that synthesize information across a patient's entire record to surface patterns missed in isolated visits.
- Physician workflow tools might improve if they explicitly flag informative absences in historical data rather than treating missing entries as neutral.
- This framing could connect to broader efforts in building AI that supports iterative clinical decision-making over weeks or months rather than one-off predictions.
Load-bearing premise
The curated corpus of clinical NLP and EHR-integrated systems together with the developed coding framework provide a representative and unbiased view of the field's current capabilities and limitations.
What would settle it
A deployed clinical AI system that explicitly performs and is evaluated on longitudinal reasoning across full patient histories, showing measurable gains in interpretability over standard encounter-based predictors.
Figures
read the original abstract
We present a structured analysis of how contemporary clinical AI systems integrate electronic health record (EHR) data and the extent to which they support longitudinal clinical reasoning. Drawing on a curated corpus of clinical natural language processing (NLP) and EHR-integrated systems, we develop a coding framework that captures both technical integration strategies and reasoning-relevant representational features, such as trajectory modeling, cross-encounter synthesis, longitudinal analysis, and absence reasoning. We also elicited the experiences of three physicians in their EHR use, including what strengths and weaknesses they found with their institution's current EHR system(s). Our analysis shows that while many systems incorporate EHR data, they predominantly operate on encounter-level or aggregated representations, with limited support for explicit temporal reasoning across patient histories. Reasoning-relevant structures are inconsistently represented, and evaluation paradigms remain largely focused on predictive performance instead of longitudinal interpretability. We argue that current approaches treat EHR data as a static input rather than a substrate for ongoing clinical reasoning, and we outline a framework for understanding how future systems might more effectively align with the temporal and interpretive structure of clinical practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a structured analysis of how contemporary clinical AI systems integrate EHR data, developing a coding framework to assess technical integration strategies and reasoning-relevant features such as trajectory modeling, cross-encounter synthesis, and absence reasoning. Drawing on a curated corpus of clinical NLP and EHR-integrated systems plus elicitation from three physicians, it concludes that systems predominantly use encounter-level or aggregated representations with limited explicit temporal reasoning, that evaluation focuses on predictive performance rather than longitudinal interpretability, and that EHR data is treated as static input rather than a substrate for ongoing clinical reasoning. It outlines a framework for future systems to better align with the temporal structure of clinical practice.
Significance. If the analysis of the corpus holds, the paper usefully identifies a gap between current clinical AI capabilities and the longitudinal, interpretive demands of clinical reasoning. The coding framework and physician perspectives provide a starting point for discussion, and the emphasis on moving beyond prediction-only paradigms is a constructive contribution to the cs.CY literature on health AI. However, the absence of quantitative evaluation metrics, reproducible corpus details, or falsifiable predictions limits the strength of the contribution relative to more empirical work in the field.
major comments (3)
- [Methods (corpus curation)] Methods (corpus curation): No inclusion/exclusion criteria, search strategy, database sources, or coverage statistics (academic vs. commercial systems) are provided for the curated corpus. This directly undermines the central claim that systems 'predominantly operate on encounter-level or aggregated representations' because sampling bias cannot be ruled out.
- [Physician elicitation] Physician elicitation section: The sample is limited to three physicians with no details on selection, inter-rater process, or generalizability. This is load-bearing for the claim that current EHR systems exhibit specific strengths and weaknesses in supporting longitudinal reasoning.
- [Coding framework] Coding framework development: No information is given on how the framework was constructed, validated, or assessed for inter-rater reliability. This affects the reliability of the reported inconsistencies in reasoning-relevant structures.
minor comments (2)
- [Abstract] Abstract: The statement that 'evaluation paradigms remain largely focused on predictive performance' would be strengthened by at least one concrete citation or example from the corpus.
- [Coding framework] Notation: The terms 'trajectory modeling' and 'absence reasoning' are introduced without explicit definitions or examples in the coding framework description, which could improve clarity for readers outside clinical NLP.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important opportunities to strengthen the transparency of our methods. We address each major comment below and will revise the manuscript accordingly to improve reproducibility and address potential concerns about sampling and reliability.
read point-by-point responses
-
Referee: [Methods (corpus curation)] Methods (corpus curation): No inclusion/exclusion criteria, search strategy, database sources, or coverage statistics (academic vs. commercial systems) are provided for the curated corpus. This directly undermines the central claim that systems 'predominantly operate on encounter-level or aggregated representations' because sampling bias cannot be ruled out.
Authors: We agree that the Methods section should provide these details to allow readers to evaluate potential biases. In the revised manuscript, we will add a subsection detailing the search strategy (including databases such as PubMed and arXiv, and keywords), explicit inclusion/exclusion criteria, and available statistics on corpus composition (e.g., proportion of academic vs. commercial systems). This will directly support the validity of our prevalence claims. revision: yes
-
Referee: [Physician elicitation] Physician elicitation section: The sample is limited to three physicians with no details on selection, inter-rater process, or generalizability. This is load-bearing for the claim that current EHR systems exhibit specific strengths and weaknesses in supporting longitudinal reasoning.
Authors: We acknowledge the need for greater detail here. The revised version will expand this section to describe the physician selection process, the semi-structured nature of the elicitation, and any steps taken for consistency. We will also add an explicit discussion of limitations regarding sample size and generalizability, clarifying that these perspectives serve to illustrate and contextualize the corpus findings rather than provide standalone quantitative evidence. revision: yes
-
Referee: [Coding framework] Coding framework development: No information is given on how the framework was constructed, validated, or assessed for inter-rater reliability. This affects the reliability of the reported inconsistencies in reasoning-relevant structures.
Authors: We will revise the Methods to describe the iterative development of the coding framework, including how categories were derived from the literature and physician input. As this was an exploratory qualitative analysis, formal inter-rater reliability assessment was not performed; we will note this limitation and describe the steps taken to maintain coding consistency. These additions will improve transparency without altering the study's qualitative scope. revision: yes
Circularity Check
No significant circularity; descriptive synthesis with no derivations or fitted quantities
full rationale
The paper is a descriptive synthesis that develops a coding framework and applies it to a curated corpus of clinical NLP/EHR systems, supplemented by physician elicitation. It contains no equations, no predictions of fitted quantities, no self-definitional steps, and no load-bearing self-citations. The central claims rest on the empirical coding results and elicitation rather than any reduction to inputs by construction. The representativeness of the corpus is an external-validity question, not a circularity issue in any derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2009 , howpublished =
HITECH , title =. 2009 , howpublished =
2009
-
[2]
New England Journal of Medicine , year =
Blumenthal, David , title =. New England Journal of Medicine , year =
-
[3]
and Kuperman, Gilad J
Bates, David W. and Kuperman, Gilad J. and Wang, Shirley and Gandhi, Tejal and Kittler, Alice and Volk, Lisa and Spurr, Christopher and Khorasani, Ramin and Tanasijevic, Mark and Middleton, Blackford , title =. Journal of the American Medical Informatics Association , year =
-
[4]
Andrew and Balas, E
Kawamoto, Kensaku and Houlihan, C. Andrew and Balas, E. Andrew and Lobach, David F. , title =. BMJ , year =
-
[5]
and Wong, Angela and Dhurjati, Ritu and Bristow, Elizabeth and Bastian, Lori and Coeytaux, Remy R
Bright, Tiffani J. and Wong, Angela and Dhurjati, Ritu and Bristow, Elizabeth and Bastian, Lori and Coeytaux, Remy R. and Samsa, Gregory and Hasselblad, Vic and Williams, John W. and Musty, Matthew D. and Wing, Lisa and Kendrick, Amanda S. and Sanders, Gary D. and Lobach, David , title =. Annals of Internal Medicine , year =
-
[6]
and Sun, Jimeng , title =
Choi, Edward and Bahadori, Mohammad Taha and Schuetz, Andy and Stewart, Walter F. and Sun, Jimeng , title =. Proceedings of Machine Learning for Healthcare , year =
-
[7]
and Hajaj, Nir and Hardt, Michaela and Liu, Peter J
Rajkomar, Alvin and Oren, Eyal and Chen, Kai and Dai, Andrew M. and Hajaj, Nir and Hardt, Michaela and Liu, Peter J. and Liu, Xiaobing and Marcus, Jake and Sun, Mike and Sundberg, Patrik and Yee, Hector and Zhang, Kun and Duggan, Gavin E. and Irvine, James and Le, Quoc V. and Litsch, Kurt and Dean, Jeff and Socher, Richard , title =. npj Digital Medicine , year =
-
[8]
and Milstein, Arnold and Bagley, Steven C
Shah, Nigam H. and Milstein, Arnold and Bagley, Steven C. , title =. JAMA , year =
-
[9]
Nature Machine Intelligence , year =
Rudin, Cynthia , title =. Nature Machine Intelligence , year =
-
[10]
and Wei, Jason and Chung, Hyung Won and Scales, Nathan and others , title =
Singhal, Karan and Azizi, Shekoofeh and Tu, Tao and Mahdavi, Sara S. and Wei, Jason and Chung, Hyung Won and Scales, Nathan and others , title =. Nature , year =
-
[11]
arXiv preprint arXiv:1702.08608 , year =
Doshi-Velez, Finale and Kim, Been , title =. arXiv preprint arXiv:1702.08608 , year =. 1702.08608 , archivePrefix =
-
[12]
Journal of Medical Internet Research , year =
Chenais, Guillaume and Busche, Katharina and Bolognini, Damien and others , title =. Journal of Medical Internet Research , year =
-
[13]
, title =
Friedman, Charles P. , title =. Journal of the American Medical Informatics Association , year =
-
[14]
Topol, Eric , title =
-
[15]
and Jensen, Lars Juhl and Brunak, Søren , title =
Jensen, Peter B. and Jensen, Lars Juhl and Brunak, Søren , title =. Nature Reviews Genetics , year =
-
[16]
Nature Medicine , year =
Esteva, Andre and Robicquet, Alexandre and Ramsundar, Bharath and others , title =. Nature Medicine , year =
-
[17]
and Pincock, David and Baumgart, Daniel C
Sutton, Richard T. and Pincock, David and Baumgart, Daniel C. and others , title =. NPJ Digital Medicine , year =
-
[18]
and Goldenberg, Anna , title =
Tonekaboni, Sana and Joshi, Shalmali and McCradden, Melissa D. and Goldenberg, Anna , title =. Machine Learning for Healthcare Conference , year =
-
[19]
and D'Arcy, John and Kashyap, Sandeep and others , title =
Sendak, Mark P. and D'Arcy, John and Kashyap, Sandeep and others , title =. EMJ Innovations , year =
-
[20]
and Sepúlveda, Maria J
Shortliffe, Edward H. and Sepúlveda, Maria J. , title =. JAMA , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.