Post-Hoc Understanding of Metaphor Processing in Decoder-Only Language Models via Conditional Scale Entropy
Pith reviewed 2026-05-21 04:31 UTC · model grok-4.3
The pith
Metaphorical tokens produce higher spectral breadth than literal tokens at contiguous layers in every decoder-only model tested.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
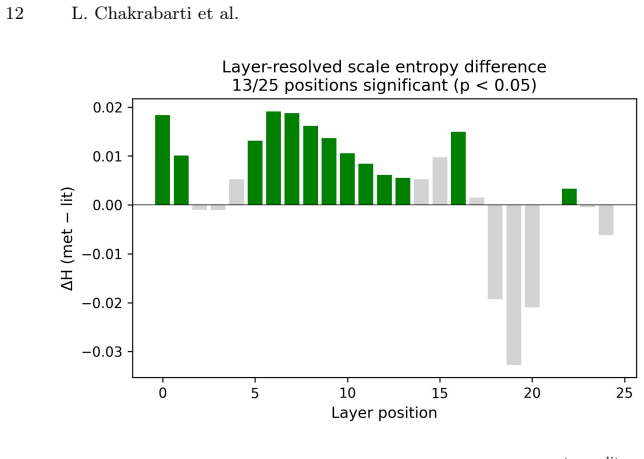
Conditional scale entropy, defined via wavelet analysis of layer updates, is invariant to update magnitude by two theorems; when applied to decoder-only models, it shows that metaphorical tokens produce significantly higher spectral breadth than literal tokens at contiguous layer positions from 124M to 20B parameters, an effect that recurs in early-to-mid relative depth, converges with VUA-pair analysis, and is not accounted for by semantic complexity or matched propositional content.
What carries the argument
Conditional scale entropy (CSE), a wavelet-derived scalar that quantifies the breadth of frequency scales engaged by a transformer layer's update at each depth position.
If this is right
- The CSE elevation for metaphors appears consistently in the early-to-mid relative depth range across all tested decoder-only families.
- The pattern survives cluster-based permutation correction and matches results from an independent set of 200 naturalistic VUA metaphor-literal pairs.
- Specificity controls indicate the elevation is not reducible to general semantic complexity or to matched propositional content.
- CSE therefore supplies a magnitude-invariant signature for tracking cross-depth structure during non-literal language processing.
Where Pith is reading between the lines
- If the same CSE widening appears in encoder-decoder or mixture-of-experts models, the signature may be architecture-general rather than limited to decoder-only stacks.
- The early-to-mid depth localization suggests metaphor resolution may rely on integrating lower-layer lexical features with mid-layer contextual reweighting.
- Because CSE isolates pattern from intensity, it could be combined with activation patching to test whether suppressing multi-scale updates impairs metaphor comprehension more than literal comprehension.
Load-bearing premise
The two theorems correctly prove that CSE remains unchanged when the magnitude of a layer update varies.
What would settle it
A controlled replication on the same models that finds no CSE difference between metaphorical and literal tokens after the same cluster-based permutation correction would falsify the central claim.
Figures


read the original abstract
Metaphor requires a language model to resolve a token whose contextual meaning diverges from its basic literal sense. Understanding how transformer models organize this reinterpretation across depth remains an open problem in mechanistic interpretability. We introduce conditional scale entropy (CSE), a wavelet-derived measure of how broadly transformer computation engages across frequency scales at each layer position. Two theorems establish that CSE is invariant to update magnitude, isolating the structural pattern of updates from their intensity. Using CSE, we find that metaphorical tokens produce significantly higher spectral breadth than literal tokens at contiguous layer positions on every decoder-only architecture tested, from 124M to 20B parameters (GPT-2 family, LLaMA-2 7B, GPT-oss 20B). The effect survives cluster-based permutation correction, recurs in the early-to-mid relative depth range across models, and converges with an independent analysis of 200 naturalistic VUA pairs. Specificity controls further show that the effect is not explained by semantic complexity or by matched propositional content. These results identify multi-scale coordination as a consistent signature of metaphorical language processing in the decoder-only architectures examined, and establish CSE as a principled tool for characterizing cross-depth structure in transformers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces conditional scale entropy (CSE), a wavelet-derived measure of spectral breadth in transformer layer updates. Two theorems establish CSE invariance to update magnitude, isolating structural patterns. Empirical results across decoder-only models (GPT-2 family, LLaMA-2 7B, GPT-oss 20B) show metaphorical tokens produce significantly higher CSE than literal tokens at contiguous early-to-mid layer positions; the effect survives cluster-based permutation correction, recurs across architectures, and converges with an independent VUA analysis. Specificity controls rule out semantic complexity and matched propositional content as explanations.
Significance. If the invariance theorems hold and the empirical patterns are robust, the work provides a new tool for mechanistic interpretability of metaphor processing, identifying multi-scale coordination as a consistent signature in decoder-only transformers. The breadth of model scales tested (124M to 20B) and convergence with naturalistic VUA data are notable strengths that could support falsifiable predictions about cross-depth structure.
major comments (2)
- [Theorems 1 and 2] Theorems 1 and 2 (section establishing CSE invariance): these are load-bearing for the central claim that elevated CSE reflects multi-scale coordination independent of update intensity. The proofs must be shown to fully decouple from discrete, non-stationary attention/FFN update statistics in decoder-only models; if they rely on continuous-scale or stationarity assumptions, residual magnitude sensitivity could confound the structural interpretation, as raised by the stress-test note.
- [Abstract and §5 (empirical results)] Abstract and experimental sections: the claims of statistical significance, survival of permutation correction, and convergence with VUA analysis lack details on data selection criteria, exact layer ranges examined, and full theorem proofs, leaving the central empirical claim only partially supported from the provided text.
minor comments (3)
- [Methods] Clarify the precise wavelet conditioning and scale discretization used in the CSE definition, ideally with an explicit equation reference.
- [§5.3] Provide more detail on the 200 naturalistic VUA pairs, including selection criteria and how the independent analysis was aligned with the CSE layer positions.
- [Figures] Figure captions and legends should explicitly note the relative depth normalization used when comparing across models of different sizes.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We respond to each major comment below and indicate planned revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Theorems 1 and 2] Theorems 1 and 2 (section establishing CSE invariance): these are load-bearing for the central claim that elevated CSE reflects multi-scale coordination independent of update intensity. The proofs must be shown to fully decouple from discrete, non-stationary attention/FFN update statistics in decoder-only models; if they rely on continuous-scale or stationarity assumptions, residual magnitude sensitivity could confound the structural interpretation, as raised by the stress-test note.
Authors: Theorems 1 and 2 derive CSE invariance from the properties of the discrete wavelet transform and conditional entropy applied to finite sequences of layer updates; the derivations impose no stationarity requirement and treat updates as discrete vectors without assuming continuous scaling. We will strengthen the presentation by adding an explicit discussion of how the proofs apply to the non-stationary, discrete statistics of attention and FFN blocks, together with expanded stress-test simulations that inject actual model-derived update patterns. revision: yes
-
Referee: [Abstract and §5 (empirical results)] Abstract and experimental sections: the claims of statistical significance, survival of permutation correction, and convergence with VUA analysis lack details on data selection criteria, exact layer ranges examined, and full theorem proofs, leaving the central empirical claim only partially supported from the provided text.
Authors: We agree that additional specificity will improve clarity. In the revised manuscript we will insert a new subsection in §5 that (i) states the exact token-pair selection criteria and dataset sizes, (ii) reports the precise relative layer ranges examined (early-to-mid depth normalized across models), and (iii) moves the complete proofs of Theorems 1 and 2 to an appendix with full derivations. These additions will make the statistical claims fully traceable from the text. revision: yes
Circularity Check
No significant circularity; CSE derivation and empirical claims are self-contained.
full rationale
The paper introduces conditional scale entropy (CSE) and states that two theorems establish its invariance to update magnitude, thereby isolating structural patterns. These theorems are presented as part of the paper's own derivation chain rather than reducing to fitted inputs or prior self-citations. The central findings consist of direct empirical comparisons of CSE values between metaphorical and literal tokens across multiple models, with controls for semantic complexity. No load-bearing step reduces by construction to the paper's own equations or self-referential definitions; the measure and results remain independent of the target claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CSE is invariant to update magnitude
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Two theorems establish that CSE is invariant to update magnitude, isolating the structural pattern of updates from their intensity.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
H(scale|b0) is invariant under δ ↦ cδ for any c ≠ 0.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Abraham, J., et al.: Wavelet-based mechanistic interpretability of vision transform- ers. In: CVPR Workshop on Mechanistic Interpretability in Vision (2025) Post-Hoc Understanding of Metaphor Processing via CSE 17
work page 2025
-
[2]
Aghazadeh, E., Fayyaz, M., Yaghoobzadeh, Y.: Metaphors in pre-trained language models: Probing and generalization across datasets and languages. In: Proceedings of ACL. pp. 2037–2050 (2022)
work page 2037
-
[3]
Psychological Review112(1), 193–216 (2005)
Bowdle, B.F., Gentner, D.: The career of metaphor. Psychological Review112(1), 193–216 (2005)
work page 2005
-
[4]
Choi, M., Lee, S., Choi, E., Park, H., Lee, J., Lee, D., Lee, J.: MelBERT: Metaphor detection via contextualized late interaction using metaphorical identification the- ories. In: Proceedings of NAACL. pp. 1763–1773 (2021)
work page 2021
-
[5]
Cover, T.M., Thomas, J.A.: Elements of Information Theory. Wiley-Interscience, 2nd edn. (2006)
work page 2006
-
[6]
Transformer Circuits Thread (2021)
Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., et al.: A mathematical framework for transformer circuits. Transformer Circuits Thread (2021)
work page 2021
-
[7]
Ethayarajh, K.: How contextual are contextualized word representations? compar- ing the geometry of BERT, ELMo, and GPT-2 embeddings. In: Proceedings of EMNLP. pp. 55–65 (2019)
work page 2019
-
[8]
Gao, G., Choi, E., Choi, Y., Zettlemoyer, L.: Neural metaphor detection in context. In: Proceedings of EMNLP. pp. 607–613 (2018)
work page 2018
-
[9]
Bulletin of the American Mathematical Society62(3) (2025)
Geshkovski, B., Letrouit, C., Polyanskiy, Y., Rigollet, P.: A mathematical per- spective on transformers. Bulletin of the American Mathematical Society62(3) (2025)
work page 2025
-
[10]
In: Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing
Geva, M., Caciularu, A., Wang, K., Goldberg, Y.: Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space. In: Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. pp. 30–45 (2022)
work page 2022
-
[11]
Cognitive Linguistics8(3), 183–206 (1997)
Giora, R.: Understanding figurative and literal language: The graded salience hy- pothesis. Cognitive Linguistics8(3), 183–206 (1997)
work page 1997
-
[12]
Mallat, S.: A Wavelet Tour of Signal Processing: The Sparse Way. Academic Press, 3rd edn. (2009)
work page 2009
-
[13]
Mao, R., Lin, C., Guerin, F.: End-to-end sequential metaphor identification in- spired by linguistic theories. In: Proceedings of ACL. pp. 3888–3898 (2019)
work page 2019
-
[14]
Journal of Neuroscience Methods164(1), 177–190 (2007)
Maris, E., Oostenveld, R.: Nonparametric statistical testing of EEG- and MEG-data. Journal of Neuroscience Methods164(1), 177–190 (2007). https://doi.org/10.1016/j.jneumeth.2007.03.024
-
[15]
Marshall, A.W., Olkin, I., Arnold, B.C.: Inequalities: Theory of Majorization and Its Applications. Springer, 2nd edn. (2011)
work page 2011
-
[16]
OpenAI: gpt-oss-120b & gpt-oss-20b model card (2025),https://arxiv.org/abs/ 2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I.: Language models are unsupervised multitask learners. Tech. rep., OpenAI (2019),https://cdn.openai.com/better-language-models/language_models_ are_unsupervised_multitask_learners.pdf
work page 2019
-
[18]
Rahaman, N., Barber, A., Arpit, D., Draxler, F., Lin, M., Hamprecht, F., Bengio, Y., Courville, A.: On the spectral bias of neural networks. In: Proceedings of ICML. pp. 5301–5310 (2019)
work page 2019
-
[19]
Opening the Black Box of Deep Neural Networks via Information
Shwartz-Ziv, R., Tishby, N.: Opening the black box of deep neural networks via information. arXiv preprint arXiv:1703.00810 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Sravanthi, P., Mamidi, R.: PUB: A pragmatics understanding benchmark for as- sessing LLMs’ pragmatics capabilities. In: Proceedings of the 2024 Joint Interna- tional Conference on Computational Linguistics, Language Resources and Evalu- ation (LREC-COLING) (2024) 18 L. Chakrabarti et al
work page 2024
-
[21]
Steen, G.J., Dorst, A.G., Herrmann, J.B., Kaal, A.A., Krennmayr, T., Pasma, T.: A Method for Linguistic Metaphor Identification. John Benjamins (2010)
work page 2010
-
[22]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Sun, Q., Pickett, M., Nain, A.K., Jones, L.: Transformer layers as painters. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 25219– 25227 (2025)
work page 2025
-
[23]
Tenney, I., Das, D., Pavlick, E.: BERT rediscovers the classical NLP pipeline. In: Proceedings of ACL. pp. 4593–4601 (2019)
work page 2019
-
[24]
Bul- letin of the American Meteorological Society79, 61–78 (1998),https://api
Torrence, C., Compo, G.P.: A practical guide to wavelet analysis. Bul- letin of the American Meteorological Society79, 61–78 (1998),https://api. semanticscholar.org/CorpusID:14928780
work page 1998
-
[25]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bash- lykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foun- dation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023). https://doi.org/10.48550/arXiv.2307.09288
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09288 2023
-
[26]
In: Advances in Neural Information Processing Systems
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems. vol. 30 (2017)
work page 2017
-
[27]
Voita, E., Titov, I.: Information-theoretic probing with minimum description length. In: Proceedings of EMNLP. pp. 183–196 (2020)
work page 2020
-
[28]
In: Proceedings of ACL (Volume 1: Long Papers)
Wachowiak, L., Gromann, D.: Does GPT-3 grasp metaphors? identifying metaphor mappings with generative language models. In: Proceedings of ACL (Volume 1: Long Papers). pp. 1018–1032 (2023)
work page 2023
-
[29]
arXiv preprint arXiv:2303.08296 (2023)
Zhai, S., Likhomanenko, T., Littwin, E., Busbridge, D., Ramapuram, J., Zhang, Y., Gu, J., Susskind, J.: Stabilizing transformer training by preventing attention entropy collapse. arXiv preprint arXiv:2303.08296 (2023)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.