PearlVLA: Progressive Embodied Action-Plan Refinement in Latent Space
Pith reviewed 2026-06-27 00:55 UTC · model grok-4.3
The pith
PearlVLA refines action plans iteratively inside the latent space of a vision-language model to improve deliberation while keeping execution fast.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
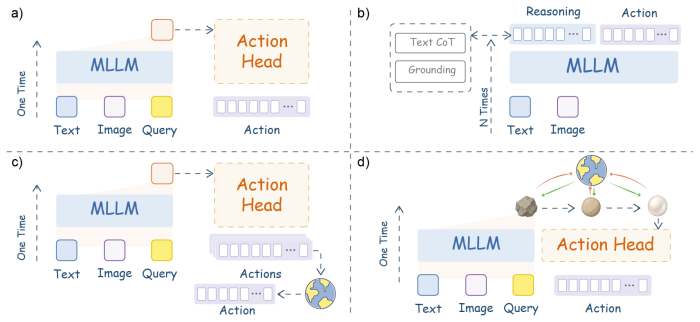
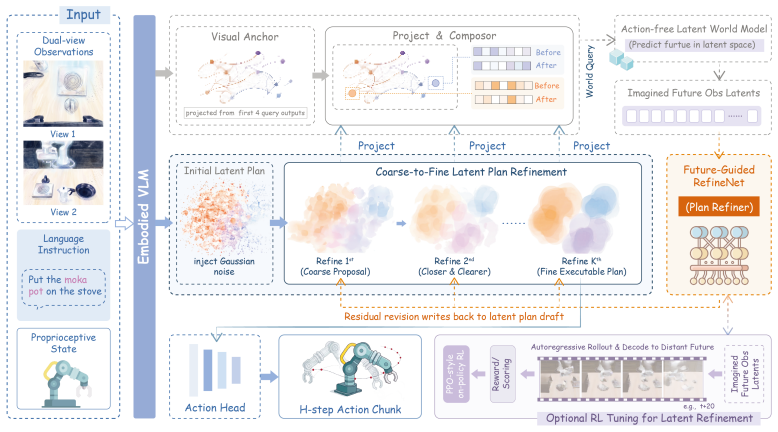
PearlVLA separates VLM meta-query representations into a fixed visual grounding branch and an iterative latent plan branch. At each refinement round, a plan-conditioned world query probes a lightweight frozen latent world model for an action-free future observation latent, which is fed back to guide plan refinement. A future-guided RefineNet then applies scheduled residual updates to progressively refine a coarse semantic draft into a fine-grained latent action plan. The refined plan after K rounds is then decoded in parallel into an action chunk for low-latency execution. Causal Refinement-Grouped Process-Reward RL optimizes the latent refinement process with rewards from longer-horizon ima
What carries the argument
The iterative latent plan branch that uses a plan-conditioned world query to retrieve future observation latents and a future-guided RefineNet to apply residual updates for progressive plan refinement.
If this is right
- The method reaches state-of-the-art success rates among existing approaches on the LIBERO benchmark.
- Action chunks are produced in a single parallel decode step after refinement, preserving low execution latency.
- Causal RL applied to the refinement process improves the quality of latent plans using rewards from imagined longer-horizon futures.
- Deliberation occurs entirely in latent space rather than through text chains or pixel subgoals, avoiding added computational cost at inference time.
Where Pith is reading between the lines
- The framework could support variable numbers of refinement rounds at test time to trade compute for performance on harder tasks.
- If the frozen world model remains accurate across domains, the same refinement loop might transfer to new robot embodiments without retraining the world model.
- Latent plans refined this way might serve as compact high-level abstractions that downstream modules can condition on without full re-encoding.
Load-bearing premise
A lightweight frozen latent world model can generate useful action-free future observation latents that reliably guide and improve plan refinement across rounds without introducing compounding errors or requiring explicit action inputs.
What would settle it
Running PearlVLA with zero refinement rounds on LIBERO tasks yields performance equal to or better than the full multi-round version, or the world model latents produce no measurable improvement in success rate when used for guidance.
Figures
read the original abstract
Current Vision-Language-Action (VLA) models face a trade-off between efficient action generation and explicit deliberation. Directly decoding actions from vision-language backbone representations enables low-latency control, whereas explicit reasoning through textual chains, pixel-level subgoals, or action search can improve planning but incurs substantial latency and computational cost. We propose PearlVLA, a VLA framework that moves deliberation into the latent space of a vision-language model (VLM). PearlVLA separates VLM meta-query representations into a fixed visual grounding branch and an iterative latent plan branch. At each refinement round, a plan-conditioned world query probes a lightweight frozen latent world model for an action-free future observation latent, which is fed back to guide plan refinement. A future-guided RefineNet then applies scheduled residual updates to progressively refine a coarse semantic draft into a fine-grained latent action plan. The refined plan after K rounds is then decoded in parallel into an action chunk for low-latency execution. We further introduce Causal Refinement-Grouped Process-Reward RL to optimize the latent refinement process with rewards from longer-horizon imagined futures induced by latent plan edits. Empirical evaluations on the LIBERO benchmark demonstrate that PearlVLA achieves state-of-the-art performance among existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. PearlVLA separates VLM meta-query representations into a fixed visual grounding branch and an iterative latent plan branch. At each of K refinement rounds, a plan-conditioned world query probes a lightweight frozen latent world model for an action-free future observation latent; a future-guided RefineNet applies scheduled residual updates to refine a coarse semantic draft into a fine-grained latent action plan, which is decoded in parallel to an action chunk. The refinement process is optimized via Causal Refinement-Grouped Process-Reward RL using rewards from longer-horizon imagined futures. The paper claims this yields state-of-the-art performance on the LIBERO benchmark.
Significance. If the empirical results and the stability of the action-free latent world model hold, the approach would demonstrate a viable middle ground between low-latency direct action decoding and costly explicit reasoning, by relocating deliberation to the VLM latent space. The RL component that rewards edits based on imagined futures would constitute a concrete technical contribution if the world-model signal is shown to be non-circular and non-compounding.
major comments (2)
- [Abstract] Abstract: the central SOTA claim on LIBERO is presented without any baselines, statistical tests, error bars, ablation studies, or even the value of K. Because the entire contribution rests on demonstrating that the iterative latent refinement loop improves performance, the absence of these details makes the claim impossible to evaluate from the supplied text.
- [Abstract] Abstract (method description): the iterative loop (plan-conditioned world query → action-free future latent → RefineNet residual update, repeated K times) is asserted to produce progressively better plans, yet the manuscript supplies no training details, validation metrics, or ablation isolating the contribution of the frozen world-model latents versus RefineNet alone. If those latents are uninformative or accumulate drift, the “progressive refinement” reduces to repeated residual updates without external signal, directly undermining the performance claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the abstract to improve clarity and completeness while preserving the manuscript's technical content.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central SOTA claim on LIBERO is presented without any baselines, statistical tests, error bars, ablation studies, or even the value of K. Because the entire contribution rests on demonstrating that the iterative latent refinement loop improves performance, the absence of these details makes the claim impossible to evaluate from the supplied text.
Authors: We agree the abstract should supply key quantitative context. The full manuscript reports LIBERO results in Table 1 (including all listed baselines), reports means and standard deviations over three random seeds, and presents ablations in Table 3. K is set to 4. We will revise the abstract to state the main success-rate improvement, note the statistical reporting, and include the value of K. revision: yes
-
Referee: [Abstract] Abstract (method description): the iterative loop (plan-conditioned world query → action-free future latent → RefineNet residual update, repeated K times) is asserted to produce progressively better plans, yet the manuscript supplies no training details, validation metrics, or ablation isolating the contribution of the frozen world-model latents versus RefineNet alone. If those latents are uninformative or accumulate drift, the “progressive refinement” reduces to repeated residual updates without external signal, directly undermining the performance claim.
Authors: The full manuscript details the RL training procedure and world-model pre-training in Section 3, reports world-model validation metrics in Appendix B.2, and isolates the world-model contribution via ablation in Section 5.3 (showing clear degradation when world-model latents are replaced by noise). We will add a concise clause to the abstract summarizing the training signal and confirming the ablation result. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claims rest on empirical SOTA results measured on the external LIBERO benchmark rather than any internal reduction. The abstract describes a novel architecture (plan-conditioned world query, future-guided RefineNet, Causal Refinement-Grouped Process-Reward RL) whose performance is reported via benchmark metrics; no equations, fitted parameters renamed as predictions, or self-citation chains are present that would make the reported gains equivalent to the inputs by construction. The derivation is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
free parameters (2)
- Number of refinement rounds K
- Scheduled residual update parameters
axioms (2)
- domain assumption Lightweight frozen latent world model produces reliable action-free future observation latents
- domain assumption Iterative latent refinement improves planning quality without increasing execution latency
Reference graph
Works this paper leans on
-
[1]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[2]
Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[3]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. pi_0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[4]
Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023
2023
-
[5]
Robotic control via embodied chain-of-thought reasoning.arXiv preprint arXiv:2407.08693, 2024
Michał Zawalski, William Chen, Karl Pertsch, Oier Mees, Chelsea Finn, and Sergey Levine. Robotic control via embodied chain-of-thought reasoning.arXiv preprint arXiv:2407.08693, 2024
Pith/arXiv arXiv 2024
-
[6]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025
2025
-
[7]
Haoming Song, Delin Qu, Yuanqi Yao, Qizhi Chen, Qi Lv, Yiwen Tang, Modi Shi, Guanghui Ren, Maoqing Yao, Bin Zhao, et al. Hume: Introducing system-2 thinking in visual-language- action model.arXiv preprint arXiv:2505.21432, 2025
arXiv 2025
-
[8]
Xiaowei Chi, Kuangzhi Ge, Jiaming Liu, Siyuan Zhou, Peidong Jia, Zichen He, Yuzhen Liu, Tingguang Li, Lei Han, Sirui Han, et al. Mind: Unified visual imagination and control via hierarchical world models.arXiv preprint arXiv:2506.18897, 2025
arXiv 2025
-
[9]
Fangqi Zhu, Zhengyang Yan, Zicong Hong, Quanxin Shou, Xiao Ma, and Song Guo. Wmpo: World model-based policy optimization for vision-language-action models.arXiv preprint arXiv:2511.09515, 2025
arXiv 2025
-
[10]
Hengtao Li, Pengxiang Ding, Runze Suo, Yihao Wang, Zirui Ge, Dongyuan Zang, Kexian Yu, Mingyang Sun, Hongyin Zhang, Donglin Wang, et al. Vla-rft: Vision-language-action reinforce- ment fine-tuning with verified rewards in world simulators.arXiv preprint arXiv:2510.00406, 2025
arXiv 2025
-
[11]
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[12]
Towards generalist embodied ai: A survey on world models for vla agents.Authorea Preprints, 2026
Wentao Tan, Lei Zhu, Bowen Wang, Enci Xie, Baixu Ji, Zengrong Lin, Wenjie Yang, Jingjing Li, and Heng Tao Shen. Towards generalist embodied ai: A survey on world models for vla agents.Authorea Preprints, 2026
2026
-
[13]
Vlanext: Recipes for building strong vla models.arXiv preprint arXiv:2602.18532, 2026
Xiao-Ming Wu, Bin Fan, Kang Liao, Jian-Jian Jiang, Runze Yang, Yihang Luo, Zhonghua Wu, Wei-Shi Zheng, and Chen Change Loy. Vlanext: Recipes for building strong vla models.arXiv preprint arXiv:2602.18532, 2026
Pith/arXiv arXiv 2026
-
[14]
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations.arXiv preprint arXiv:2412.14803, 2024
Pith/arXiv arXiv 2024
-
[15]
Zhenyang Liu, Yongchong Gu, Sixiao Zheng, Yanwei Fu, Xiangyang Xue, and Yu-Gang Jiang. Trivla: A triple-system-based unified vision-language-action model with episodic world modeling for general robot control.arXiv preprint arXiv:2507.01424, 2025. 11
arXiv 2025
-
[16]
Jacob Pfau, William Merrill, and Samuel R Bowman. Let’s think dot by dot: Hidden computation in transformer language models.arXiv preprint arXiv:2404.15758, 2024
arXiv 2024
-
[17]
Eric Zelikman, Georges Harik, Yijia Shao, Varuna Jayasiri, Nick Haber, and Noah D Goodman. Quiet-star: Language models can teach themselves to think before speaking.arXiv preprint arXiv:2403.09629, 2024
Pith/arXiv arXiv 2024
-
[18]
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024
Pith/arXiv arXiv 2024
-
[19]
Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, and Sashank J Reddi. Reasoning with latent thoughts: On the power of looped transformers.arXiv preprint arXiv:2502.17416, 2025
arXiv 2025
-
[20]
Halil Alperen Gozeten, M Emrullah Ildiz, Xuechen Zhang, Hrayr Harutyunyan, Ankit Singh Rawat, and Samet Oymak. Continuous chain of thought enables parallel exploration and reasoning.arXiv preprint arXiv:2505.23648, 2025
arXiv 2025
-
[21]
Codi: Com- pressing chain-of-thought into continuous space via self-distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. Codi: Com- pressing chain-of-thought into continuous space via self-distillation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 677–693, 2025
2025
-
[22]
DiJia Su, Hanlin Zhu, Yingchen Xu, Jiantao Jiao, Yuandong Tian, and Qinqing Zheng. Token assorted: Mixing latent and text tokens for improved language model reasoning.arXiv preprint arXiv:2502.03275, 2025
arXiv 2025
-
[23]
Diffusion of thought: Chain-of-thought reasoning in diffusion language models.Advances in Neural Information Processing Systems, 37:105345–105374, 2024
Jiacheng Ye, Shansan Gong, Liheng Chen, Lin Zheng, Jiahui Gao, Han Shi, Chuan Wu, Xin Jiang, Zhenguo Li, Wei Bi, et al. Diffusion of thought: Chain-of-thought reasoning in diffusion language models.Advances in Neural Information Processing Systems, 37:105345–105374, 2024
2024
-
[24]
Jiacheng Ye, Jiahui Gao, Shansan Gong, Lin Zheng, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Beyond autoregression: Discrete diffusion for complex reasoning and planning.arXiv preprint arXiv:2410.14157, 2024
arXiv 2024
-
[25]
Learning to act without actions.arXiv preprint arXiv:2312.10812, 2023
Dominik Schmidt and Minqi Jiang. Learning to act without actions.arXiv preprint arXiv:2312.10812, 2023
arXiv 2023
-
[26]
Latent action pretraining from videos.arXiv preprint arXiv:2410.11758, 2024
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, et al. Latent action pretraining from videos.arXiv preprint arXiv:2410.11758, 2024
Pith/arXiv arXiv 2024
-
[27]
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
Pith/arXiv arXiv 2025
-
[28]
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets.arXiv preprint arXiv:2504.02792, 2025
Pith/arXiv arXiv 2025
-
[29]
Anthony Liang, Yigit Korkmaz, Jiahui Zhang, Minyoung Hwang, Abrar Anwar, Sidhant Kaushik, Aditya Shah, Alex S Huang, Luke Zettlemoyer, Dieter Fox, et al. Robometer: Scaling general-purpose robotic reward models via trajectory comparisons.arXiv preprint arXiv:2603.02115, 2026
Pith/arXiv arXiv 2026
-
[30]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[31]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023. 12
2023
-
[32]
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523, 2024
Pith/arXiv arXiv 2024
-
[33]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi_0.5: a vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[34]
Moritz Reuss, Hongyi Zhou, Marcel Rühle, Ömer Erdinç Ya˘gmurlu, Fabian Otto, and Rudolf Lioutikov. Flower: Democratizing generalist robot policies with efficient vision-language-action flow policies.arXiv preprint arXiv:2509.04996, 2025
arXiv 2025
-
[35]
Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
Pith/arXiv arXiv 2025
-
[36]
Chia-Yu Hung, Qi Sun, Pengfei Hong, Amir Zadeh, Chuan Li, U Tan, Navonil Majumder, Soujanya Poria, et al. Nora: A small open-sourced generalist vision language action model for embodied tasks.arXiv preprint arXiv:2504.19854, 2025
Pith/arXiv arXiv 2025
-
[37]
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
Pith/arXiv arXiv 2025
-
[38]
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. Libero-plus: In-depth robustness analysis of vision-language- action models.arXiv preprint arXiv:2510.13626, 2025
Pith/arXiv arXiv 2025
-
[39]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[40]
Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[41]
Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[42]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[43]
Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
Pith/arXiv arXiv 2025
-
[44]
Wanpeng Zhang, Ye Wang, Hao Luo, Haoqi Yuan, Yicheng Feng, Sipeng Zheng, Qin Jin, and Zongqing Lu. Dig-flow: Discrepancy-guided flow matching for robust vla models.arXiv preprint arXiv:2512.01715, 2025. 13 A Architecture and Training Details A.1 Architecture Details PearlVLA starts from the same OpenVLA-style base architecture used by OpenVLA and OpenVLA-...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.