Exploring Agentic Tool-Calling Decisions via Uncertainty-Aligned Reinforcement Learning
Pith reviewed 2026-06-27 21:40 UTC · model grok-4.3
The pith
TRUST adds uncertainty as a repulsive force in RL rewards to keep correct and incorrect tool decisions distinguishable in LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
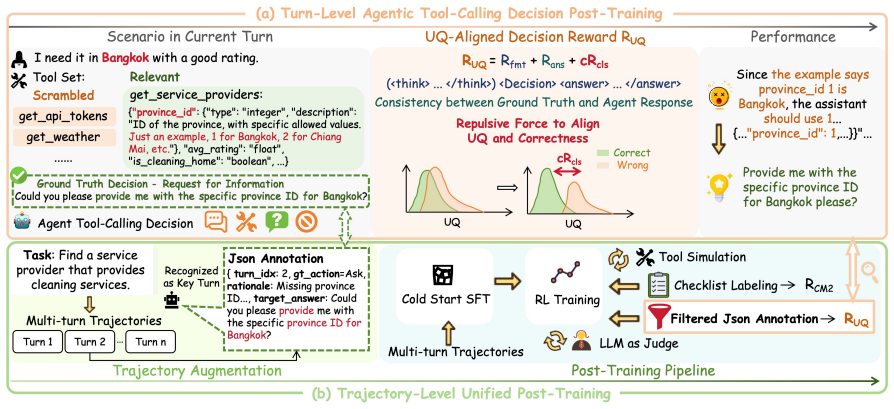
The paper claims that decision-oriented reinforcement learning weakens uncertainty separation between correct and incorrect actions; TRUST restores that separation by treating uncertainty quantification as a repulsive term in the reward and by supplying key-turn annotations for multi-turn post-training, yielding higher-quality tool decisions and more reliable uncertainty estimates.
What carries the argument
Uncertainty quantification used as a repulsive force inside the reinforcement-learning reward, paired with lightweight key-turn annotations for unified trajectory post-training.
If this is right
- Fewer unsupported tool invocations and hallucinated direct responses occur during multi-step interactions.
- Decision quality rises on diverse tool-use benchmarks.
- Overall agent task performance improves.
- Uncertainty estimates stay better calibrated throughout the optimization process.
Where Pith is reading between the lines
- The repulsive-force idea could be tested on other agent decisions that require calibrated exploration, such as planning or memory retrieval.
- If the separation effect holds, similar uncertainty terms might reduce compounding errors in longer-horizon agent workflows without extra supervision.
- The approach implies that reward shaping should explicitly target uncertainty calibration rather than outcome alone.
Load-bearing premise
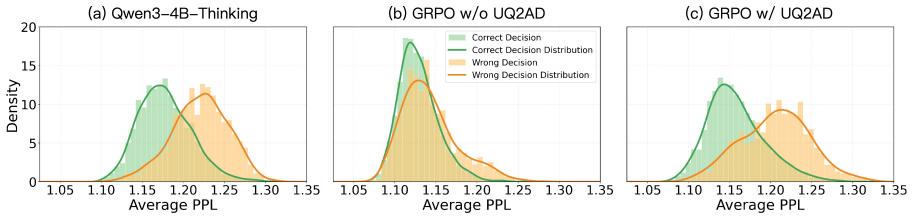
Decision-oriented reinforcement learning tends to weaken the uncertainty separation between correct and incorrect actions.
What would settle it
A controlled comparison in which agents trained with standard outcome rewards maintain the same uncertainty separation as TRUST agents, or show equal or better final performance on the tool-use benchmarks.
Figures


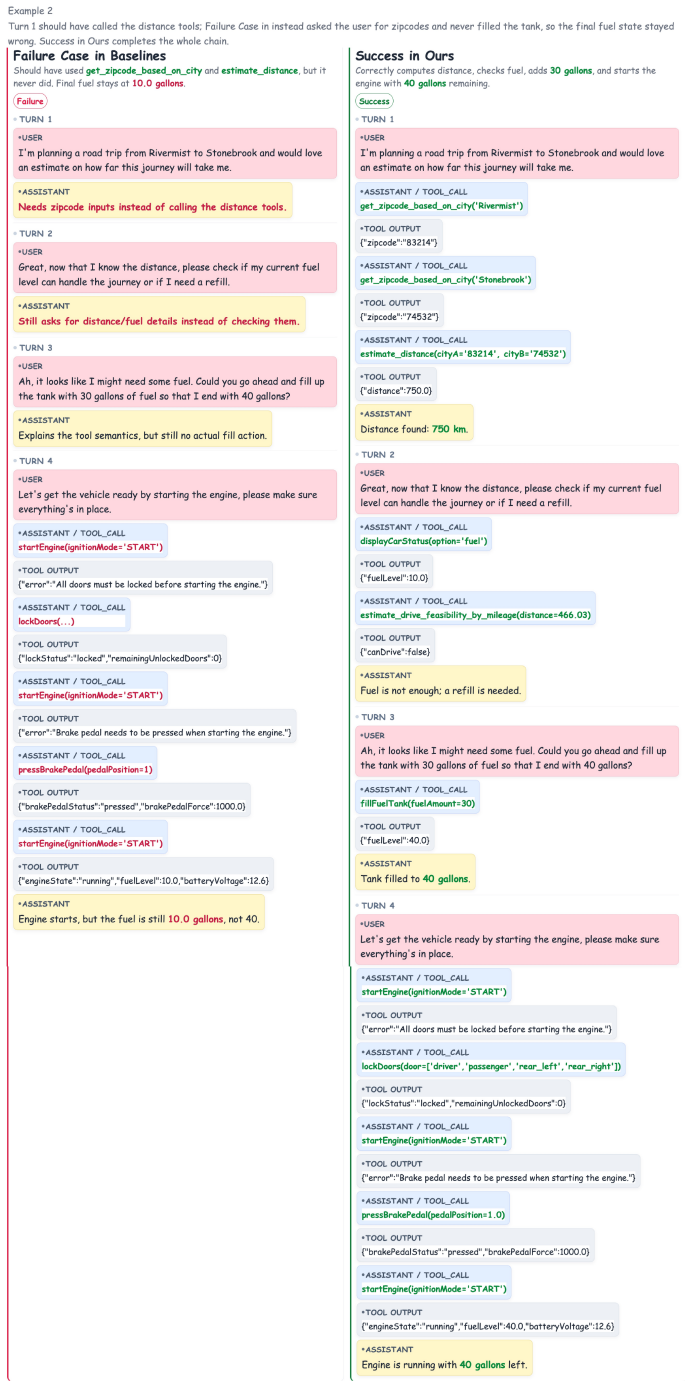
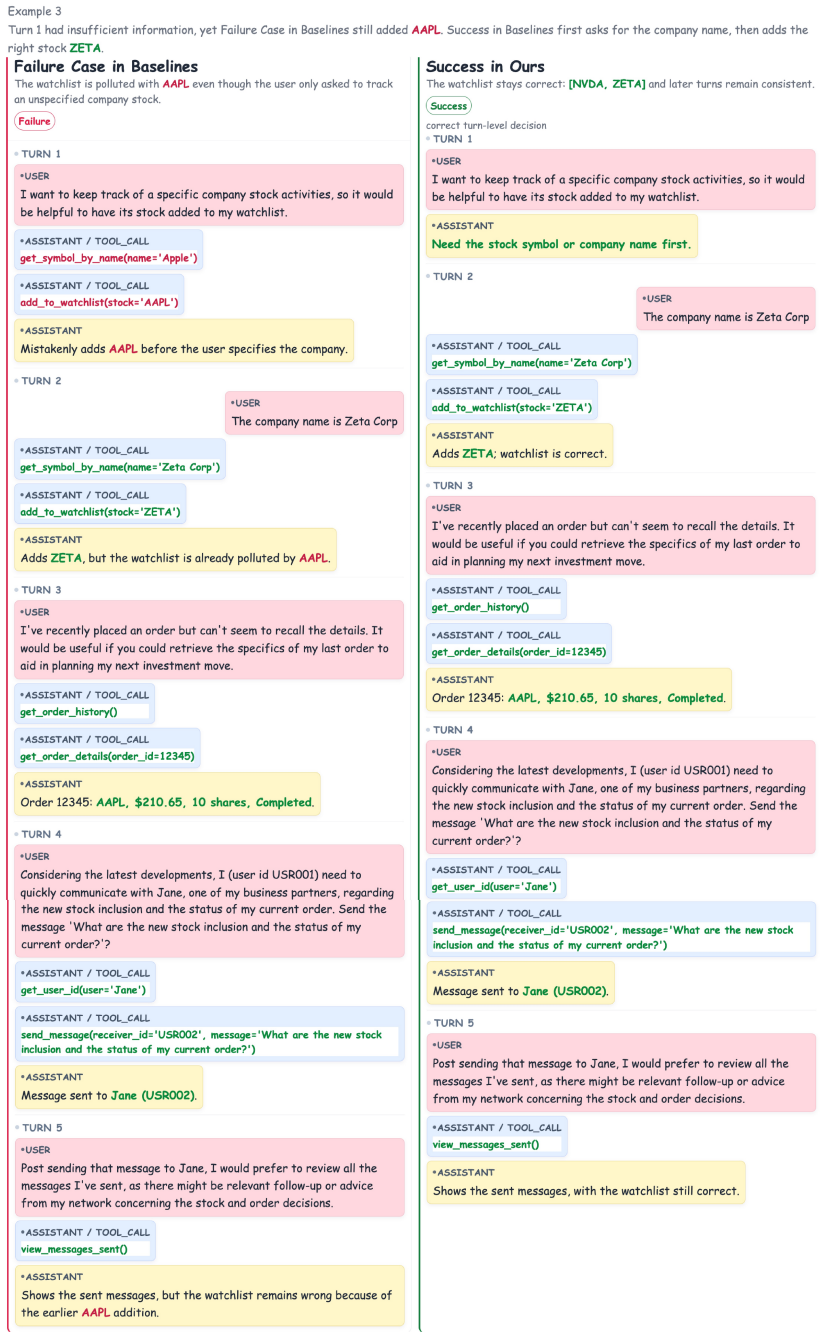
read the original abstract
Large language model (LLM)-based agents often make suboptimal tool-use decisions, including unsupported tool invocation and hallucinated direct responses, which may accumulate errors throughout multi-step interactions. Existing approaches mainly improve these behaviors through inference-time correction or coarse-grained reward signals based on decision outcomes and structured checklists, leaving the uncertainty characteristics of agent decisions underexplored. We observe that decision-oriented reinforcement learning tends to weaken the uncertainty separation between correct and incorrect actions, resulting in overconfident mistakes and weaker exploration signals. Therefore, we propose TRUST, which incorporates uncertainty quantification into reward design as a repulsive force for maintaining uncertainty separation, and labels lightweight key-turn annotations for unified post-training of multi-turn trajectories. Experimental results across diverse tool-use benchmarks show that TRUST consistently enhances both decision quality and agent performance while maintaining more reliable uncertainty estimates during optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TRUST, a method that augments decision-oriented reinforcement learning for LLM-based agents with a repulsive-force reward term derived from uncertainty quantification, together with lightweight key-turn annotations, to preserve separation between the uncertainty estimates of correct and incorrect tool-calling actions. The central empirical claim is that this design yields higher decision quality and agent performance on tool-use benchmarks while producing more reliable uncertainty estimates than standard RL baselines.
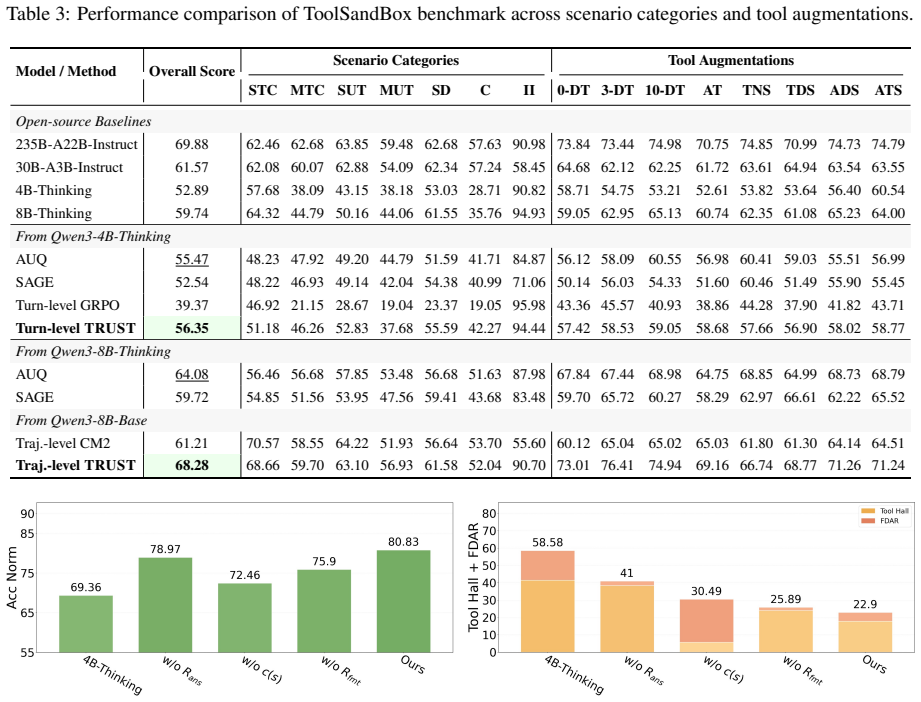
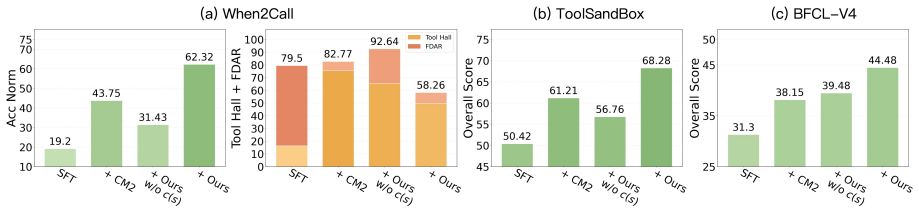
Significance. If the reported performance gains are reproducible and the repulsive-force component is shown to be responsible for the uncertainty separation, the work would supply a concrete, reward-level mechanism for mitigating overconfident tool-use errors in multi-turn agent trajectories; the approach is directly falsifiable via ablation of the repulsive term and direct measurement of uncertainty separation metrics.
major comments (2)
- [Abstract] Abstract: the motivating premise that 'decision-oriented reinforcement learning tends to weaken the uncertainty separation between correct and incorrect actions' is stated without any supporting quantification, pre-/post-RL uncertainty-distribution statistics, or ablation that isolates this effect from the key-turn annotation component; because this premise directly motivates the repulsive-force reward, its lack of empirical grounding renders the specific contribution of the proposed design unestablished.
- [Abstract] Abstract / experimental description: the claim that TRUST 'consistently enhances both decision quality and agent performance' is presented without reference to concrete benchmarks, baseline methods, statistical tests, or controls, preventing verification that the observed gains exceed those obtainable from the key-turn annotations alone.
minor comments (2)
- The abstract refers to 'diverse tool-use benchmarks' and 'more reliable uncertainty estimates' without naming the benchmarks, the uncertainty metric employed, or the precise definition of the repulsive-force term.
- Notation for the reward components (repulsive force, key-turn annotations) is introduced only at a high level; an explicit equation or pseudocode block would clarify how the uncertainty signal is converted into the reward modification.
Simulated Author's Rebuttal
We thank the referee for the feedback. We agree the abstract requires strengthening to better ground its claims and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the motivating premise that 'decision-oriented reinforcement learning tends to weaken the uncertainty separation between correct and incorrect actions' is stated without any supporting quantification, pre-/post-RL uncertainty-distribution statistics, or ablation that isolates this effect from the key-turn annotation component; because this premise directly motivates the repulsive-force reward, its lack of empirical grounding renders the specific contribution of the proposed design unestablished.
Authors: The manuscript body contains the supporting pre-/post-RL uncertainty statistics and component ablations that isolate the effect. However, we acknowledge the abstract itself lacks this grounding. We will revise the abstract to include a concise reference to these empirical observations. revision: yes
-
Referee: [Abstract] Abstract / experimental description: the claim that TRUST 'consistently enhances both decision quality and agent performance' is presented without reference to concrete benchmarks, baseline methods, statistical tests, or controls, preventing verification that the observed gains exceed those obtainable from the key-turn annotations alone.
Authors: The full manuscript reports results on specific tool-use benchmarks with named baselines, statistical significance, and ablations isolating the repulsive term from key-turn annotations. We will revise the abstract to reference these concrete elements and controls. revision: yes
Circularity Check
No circularity; empirical proposal validated by external benchmarks
full rationale
The paper motivates TRUST via an observation on RL weakening uncertainty separation and introduces a repulsive-force reward plus key-turn annotations, then reports end-to-end performance gains on tool-use benchmarks. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the text. The central claims rest on experimental results that are independent of any internal reduction to the motivating observation itself. This is a standard empirical contribution with no derivation chain that collapses by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Reinforcement learning can be applied to optimize multi-turn agent trajectories with outcome-based rewards.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2506.17419
Uprop: Investigating the uncertainty propaga- tion of llms in multi-step agentic decision-making. arXiv preprint arXiv:2506.17419. Kait Healy, Bharathi Srinivasan, Visakh Madathil, and Jing Wu. 2026. Internal representations as indica- tors of hallucinations in agent tool selection.arXiv preprint arXiv:2601.05214. Aaron Hurst, Adam Lerer, Adam P Goucher, ...
-
[2]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations. Dengjia Zhang, Xiaoou Liu, Lu Cheng, Yaqing Wang, Kenton Murray, and Hua Wei. 2026a. SE...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Agent-safetybench: Evaluating the safety of llm agents.arXiv preprint arXiv:2412.14470. Haitian Zhong, Jixiu Zhai, Lei Song, Jiang Bian, Qiang Liu, and Tieniu Tan. 2026. Rc-grpo: Reward- conditioned group relative policy optimization for multi-turn tool calling agents.arXiv preprint arXiv:2602.03025. Yijin Zhou, Yutang Ge, Wenyuan Xie, Linqian Zeng, Xi- a...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Read the full trajectory, the available tool specifications, and the checklist metadata
-
[5]
Identify decision-critical turns at which a when2call-style supervision signal is both informative and well supported by the observed trajectory
-
[6]
- ‘tool_call‘: the appropriate next step is to invoke one or more tools, and the necessary arguments are already available
For each selected turn, assign exactly one ground-truth action from the following action space: - ‘direct_answer‘: the request can be correctly addressed from the existing conversational context or general knowledge, without additional user input and without tool use. - ‘tool_call‘: the appropriate next step is to invoke one or more tools, and the necessa...
-
[7]
Prefer substantive reasoning over shallow lexical heuristics
-
[8]
name": "
Maintain broad coverage over the four action categories; do not overproduce ‘tool_call‘ annotations merely because the data originate from a tool-use setting. ## Annotation principles: - Prioritize turns that are genuinely decision-critical, including missing arguments, unsupported or hallucinated tool usage, inappropriate tool invocation, clarification a...
-
[9]
Judge the assistant’s next action from the current observed turn
-
[10]
- ‘tool_call‘: the assistant initiates one or more tool calls as the immediate next action
Map the action to exactly one normalized action category: - ‘direct_answer‘: the assistant provides a substantive answer directly, without invoking a tool and without requesting additional user information. - ‘tool_call‘: the assistant initiates one or more tool calls as the immediate next action. - ‘request_for_info‘: the assistant asks the user for miss...
-
[11]
- Otherwise, return the assistant’s realized natural-language response exactly as expressed in the turn
Extract the realized response content in a when2call-compatible representation: - If the action is ‘tool_call‘, return only the tool-call JSON content, without any surrounding prose. - Otherwise, return the assistant’s realized natural-language response exactly as expressed in the turn
-
[12]
pred_action
Ground the decision in the realized turn behavior rather than in hypothetical alternatives. ## The annotation of this turn: {JSON_ANNOTATON} ## If the assistant has conducted ‘gt_action‘ in ‘JSON_ANNOTATION‘ in this turn, choose ‘pred_action‘ the same as ‘gt_action‘. ## Return strict JSON. You MUST follow this Output Schema: { "pred_action": Action for th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.