Convex Low-resource Accent-Robust Language Detection in Speech Recognition
Pith reviewed 2026-05-25 05:08 UTC · model grok-4.3
The pith
A convex optimization framework detects languages in accented speech with 97-98 percent accuracy under low-resource constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Convex Language Detection integrates convex optimization into the spoken dialogue pipeline to produce a globally optimal solution via ADMM that carries certified margin stability and explicit guarantees against feature perturbations, while delivering 97-98 percent accuracy and sample efficiency on low-resource accented data where conventional fine-tuning overfits.
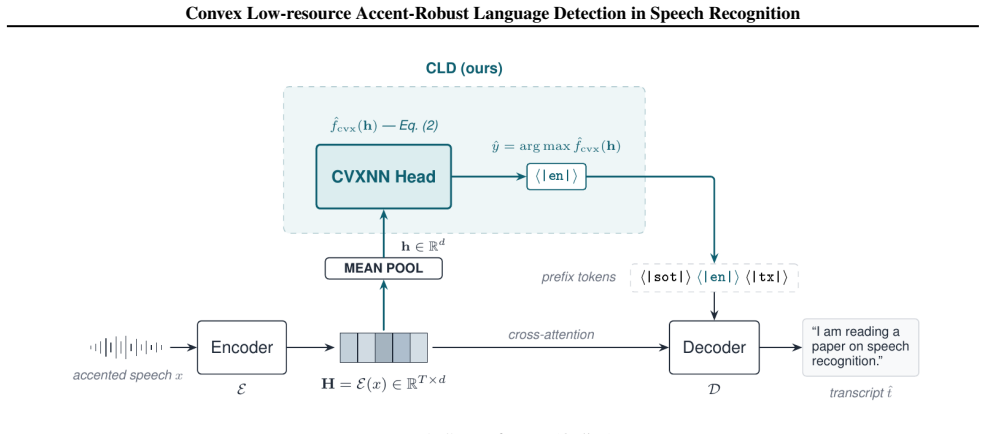
What carries the argument
Convex Language Detection (CLD) framework that formulates language detection as a convex objective solved by multi-GPU ADMM to obtain global optimality and certified margin stability.
If this is right
- The convex objective supplies certified margin stability and explicit guarantees against feature perturbations.
- Training remains sample-efficient and robust to dialectical variation while reaching 97-98 percent accuracy.
- Optimization finishes in polynomial time with global optimality guarantees.
- The method sidesteps the overfitting that occurs when standard fine-tuning is applied to high-dimensional speech data.
Where Pith is reading between the lines
- The same convex formulation could be tested on related audio classification tasks that also suffer from speaker or channel variation.
- Deployment across multicultural dialogue systems might become cheaper if retraining per accent is no longer required.
- Further checks on whether the certified stability holds for entirely new languages or recording conditions would clarify the scope of the guarantees.
Load-bearing premise
High-dimensional speech features admit a convex formulation whose global optimum via ADMM produces certified robustness to real accent-induced perturbations.
What would settle it
An experiment in which the ADMM solution on held-out accented speech loses margin stability under measured feature perturbations or drops below 95 percent accuracy in low-resource tests.
Figures


read the original abstract
Globalization and multiculturalism continue to produce increasingly diverse speech varieties. Yet current spoken dialogue systems frequently fail on under-represented dialects and accents, often misidentifying the input language and causing cascading failures in downstream dialogue tasks. Addressing this dialectal variance under low-resource constraints remains an open challenge, as standard fine-tuning is computationally expensive and prone to overfitting on high-dimensional speech data. We propose Convex Language Detection (CLD), a novel framework that integrates theoretically grounded convex optimization techniques into the spoken dialogue systems pipeline. Our method is efficiently implemented via multi-GPU Alternating Direction Method of Multipliers (ADMM) in JAX, thus providing global optimality guarantees and fast training in polynomial time. Theoretically, we prove that our convex objective induces certified margin stability and provide guarantees against feature perturbations. Empirically, we demonstrate sample efficiency and robustness to input dialectical variation, achieving 97-98% accuracy in challenging low-resource regimes. Our open-source package is available at https://pypi.org/project/jaxcld/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Convex Language Detection (CLD), a framework integrating convex optimization into spoken dialogue systems for accent-robust language detection under low-resource constraints. It claims an efficient multi-GPU ADMM implementation in JAX that yields global optimality, with theoretical proofs of certified margin stability and guarantees against feature perturbations, plus empirical results of 97-98% accuracy and sample efficiency.
Significance. If the claimed convex formulation, margin-stability proofs, and perturbation guarantees hold with the reported empirical performance, the work would offer a theoretically grounded alternative to overfitting-prone fine-tuning for dialectal variation in speech tasks, with potential impact on multilingual dialogue systems via polynomial-time global optimization.
major comments (3)
- Abstract: the central claims of proving 'certified margin stability' and 'guarantees against feature perturbations' are load-bearing for the contribution, yet the manuscript supplies no objective function, no derivation, no margin definition, and no proof sketch, preventing any verification that the convex program actually delivers these properties rather than reducing to standard convex theory.
- Abstract: the empirical claim of 97-98% accuracy in 'challenging low-resource regimes' is load-bearing for the robustness assertion, yet no datasets, feature extraction details, train/test splits, baselines, or experimental protocol are described, so it is impossible to assess whether the results support the contrast with standard fine-tuning.
- Abstract: the assumption that high-dimensional speech features admit a convex formulation whose ADMM optimum yields certified robustness to real accent-induced perturbations is stated without any supporting formulation or analysis, making the weakest assumption unverifiable from the provided text.
minor comments (1)
- The provision of an open-source package link is a positive step toward reproducibility, though the package itself cannot be evaluated without the missing technical details.
Simulated Author's Rebuttal
We thank the referee for the detailed and substantive review. The comments correctly identify that the abstract makes strong claims without visible supporting material in the provided manuscript text. We address each point below and will revise the manuscript to supply the missing elements.
read point-by-point responses
-
Referee: Abstract: the central claims of proving 'certified margin stability' and 'guarantees against feature perturbations' are load-bearing for the contribution, yet the manuscript supplies no objective function, no derivation, no margin definition, and no proof sketch, preventing any verification that the convex program actually delivers these properties rather than reducing to standard convex theory.
Authors: We agree that the current manuscript text does not contain the objective function, derivation, margin definition, or proof sketch. These elements are required for the claims to be verifiable. We will add an explicit formulation section and a proof sketch (or full proof) to the revised manuscript. revision: yes
-
Referee: Abstract: the empirical claim of 97-98% accuracy in 'challenging low-resource regimes' is load-bearing for the robustness assertion, yet no datasets, feature extraction details, train/test splits, baselines, or experimental protocol are described, so it is impossible to assess whether the results support the contrast with standard fine-tuning.
Authors: We agree that the manuscript as given provides none of the required experimental details. Without them the accuracy claim cannot be evaluated. We will include a full experimental section with datasets, feature extraction, splits, baselines, and protocol in the revision. revision: yes
-
Referee: Abstract: the assumption that high-dimensional speech features admit a convex formulation whose ADMM optimum yields certified robustness to real accent-induced perturbations is stated without any supporting formulation or analysis, making the weakest assumption unverifiable from the provided text.
Authors: We agree that the assumption is stated without supporting formulation or analysis in the supplied text. This renders the claim unverifiable. We will add the required formulation and analysis in the revised version. revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract asserts theoretical proofs of certified margin stability and perturbation guarantees for a convex objective solved via ADMM, but the provided text contains no equations, derivation steps, or self-citations that can be inspected for reductions by construction. No fitted inputs renamed as predictions, self-definitional loops, or load-bearing self-citations are visible. Without the full manuscript's technical content, the derivation cannot be shown to collapse to its inputs; standard convex optimization claims remain independent of the target result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Accessed: 2025- 11-18. Ardila, R., Branson, M., Davis, K., Kohler, M., Meyer, J., Henretty, M., Morais, R., Saunders, L., Tyers, F. M., and Weber, G. Common V oice: A massively- multilingual speech corpus. InProceedings of the 12th Language Resources and Evaluation Conference (LREC), pp. 4218–4222. European Language Resources Associ- ation (ELRA),
work page 2025
-
[3]
URL https://commonvoice. mozilla.org. Babirye, C., Nakatumba-Nabende, J., Tusubira, J. F., Muki- ibi, J., Katumba, A., Ogwang, R., Wanzare, L. D., Sen- tanda, M., and David, D. Building text and speech datasets for low resourced languages: A case of languages in East Africa. In3rd Workshop on African Natural Lan- guage Processing (AfricaNLP) at ICLR 2022,
work page 2022
-
[4]
Pre-training on high-resource speech recognition improves low-resource speech-to-text translation
Bansal, S., Kamper, H., Livescu, K., Lopez, A., and Goldwa- ter, S. Pre-training on high-resource speech recognition improves low-resource speech-to-text translation. InPro- ceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 58...
work page 2019
-
[5]
Cumbal, R., Moell, B., Lopes, J., and Engwall, O. You don’t understand me!: Comparing ASR results for L1 and L2 speakers of Swedish.arXiv preprint arXiv:2405.13379,
-
[6]
de Zuazo, X., Navas, E., Saratxaga, I., and Hern ´aez Ri- oja, I. Whisper-LM: Improving ASR models with lan- guage models for low-resource languages.arXiv preprint arXiv:2503.23542,
- [7]
- [8]
- [9]
- [10]
-
[11]
Infocomm Media Development Authority
doi: 10.1121/10.0024876. Infocomm Media Development Authority. Infocomm Me- dia Development Authority (IMDA). https://www. imda.gov.sg/,
-
[12]
Singapore Government Agency. Accessed: 2025-11-19. Javed, T., Nawale, J., Joshi, S., George, E. I., Bhogale, K. S., Mehendale, D., and Khapra, M. M. LAHAJA: A robust multi-accent benchmark for evaluating Hindi ASR systems. InProc. Interspeech,
work page 2025
-
[13]
Quantifying the dialect gap and its correlates across languages
Kantharuban, A., Vuli´c, I., and Korhonen, A. Quantifying the dialect gap and its correlates across languages. In Findings of the Association for Computational Linguis- tics: EMNLP 2023, pp. 7226–7245, Singapore,
work page 2023
-
[14]
doi: 10.1145/3636513. Le Page, R. B. Retrospect and prognosis in Malaysia and Singapore. InThe Sociolinguistics of the Speech Commu- nity. Walter de Gruyter, Berlin/New York,
-
[15]
Liu, Y ., Yang, X., and Qu, D. Exploration of Whisper fine-tuning strategies for low-resource ASR.EURASIP Journal on Audio, Speech, and Music Processing, 2024 (1):29,
work page 2024
-
[16]
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and Vladu, A
doi: 10.1186/s13636-024-00349-3. Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and Vladu, A. Towards deep learning models resistant to adversarial attacks. InInternational Conference on Learn- ing Representations (ICLR),
-
[17]
McGuire, M. Automatic speech recognition for non-native English: Accuracy and disfluency handling.arXiv preprint arXiv:2503.06924,
-
[18]
Ngueajio, M. K. and Washington, G. Hey ASR system! why aren’t you more inclusive? automatic speech recognition systems’ bias and proposed bias mitigation techniques. a literature review. InHCI International 2022 – Late Breaking Papers: Interacting with eXtended Reality and Artificial Intelligence, pp. 421–440. Springer,
work page 2022
-
[19]
doi: 10.1007/978-3-031-21707-4
-
[20]
Reitmaier, T., Wallington, E., Kalarikalayil Raju, D., Kle- jch, O., Pearson, J., Jones, M., Bell, P., and Robinson, S. Opportunities and challenges of automatic speech recognition systems for low-resource language speakers. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems, pp. 1–17. ACM,
work page 2022
-
[21]
A Survey of Available Corpora for Building Data-Driven Dialogue Systems
Serban, I. V ., Lowe, R., Henderson, P., Charlin, L., and Pineau, J. A survey of available corpora for building data-driven dialogue systems.arXiv preprint arXiv:1512.05742,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
C., Bansal, S., and Goldwater, S
Stoian, M. C., Bansal, S., and Goldwater, S. Analyzing ASR pretraining for low-resource speech-to-text translation. In ICASSP 2020 – 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 7909–7913. IEEE,
work page 2020
-
[23]
Wang, B., Zou, X., Sun, S., Zhang, W., He, Y ., Liu, Z., Wei, C., Chen, N. F., and Aw, A. Advancing Singlish under- standing: Bridging the gap with datasets and multimodal models.arXiv preprint arXiv:2501.01034,
-
[24]
have worked on building partnerships to document valuable linguistic data by remotely engaging participants to record themselves, identifying more recording opportunities, and categorizing challenges of ASR in deeply multicultural communities. This has uncovered valuable implications for collaborations across ASR and Human Computer Interface (HCI) that ad...
work page 2019
-
[25]
can be extremely challenging for high-dimensional data, such as the extracted ASR hidden features. ADMM makes this problem tractable by allowing the optimization to be performed in a batched, multi-GPU parallel fashion (especially when implemented in JAX). ADMM is perfectly suited for solving such problems by isolating the non-smooth term in one subproble...
work page 2011
-
[26]
Figure D.2.Language Classification Performance between WSP-SFT (left) and WSP (right) on Whisper-small across English (en), Chinese (zh), Indonesian (id), Malaysian (ms), Hindi (hi), and other predicted languages. 17 Convex Low-resource Accent-Robust Language Detection in Speech Recognition D.1. Classification Accuracy per Sample Size Ablation Table D.1.M...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.