ContextNest: Verifiable Context Governance for Autonomous AI Agent
Pith reviewed 2026-07-03 13:12 UTC · model grok-4.3
The pith
Context governance supplies a verifiable layer beneath retrieval so AI agents use only approved and traceable knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
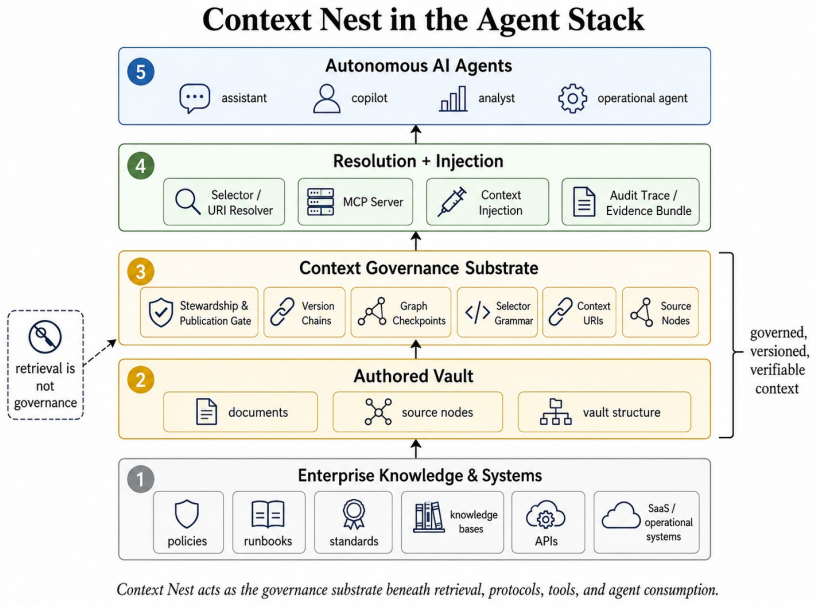
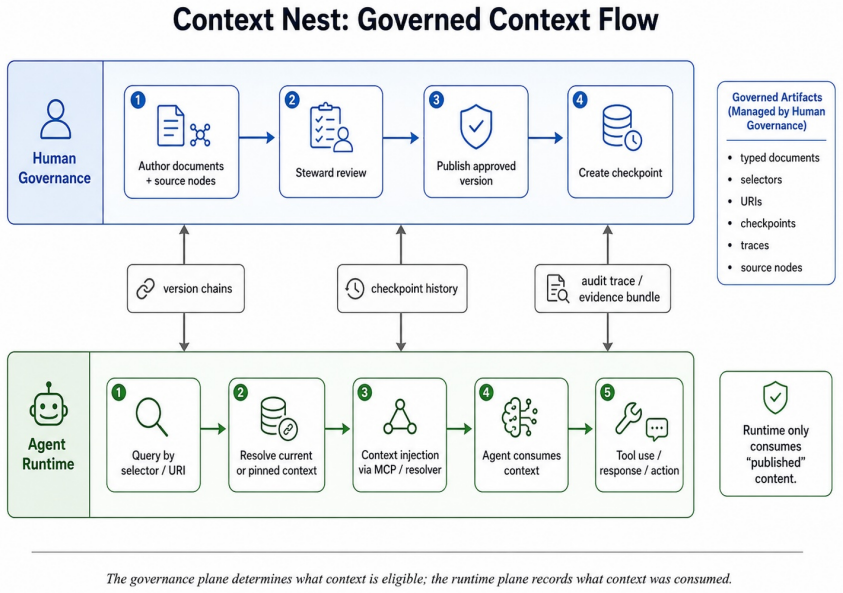
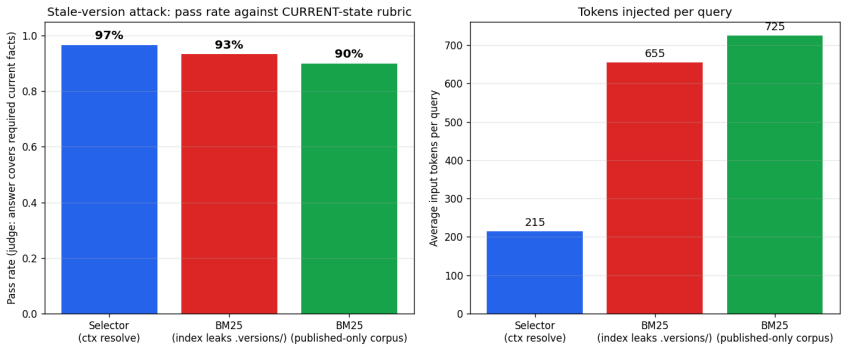
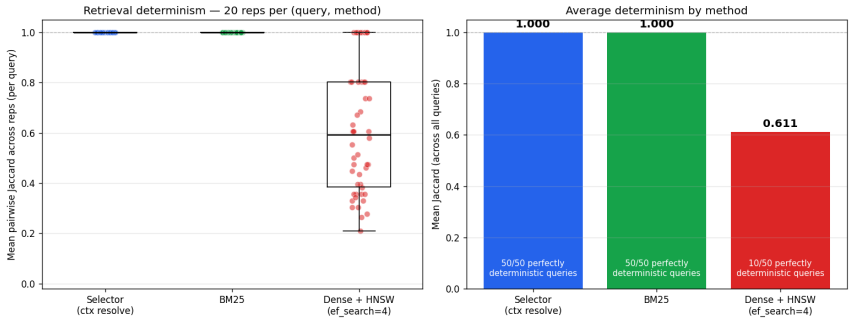
ContextNest is an open specification for governed AI-consumable knowledge vaults that combines typed Markdown documents with metadata, deterministic set-algebraic selectors, contextnest:// URI references, SHA-256 hash-chained version histories, graph-level checkpoints, and audit traces. These allow reconstruction of which knowledge versions informed an agent output and whether they were eligible. Empirical tests in a stale-version attack show governed selection Pareto-dominates BM25 with higher quality pass rates at lower cost, and determinism experiments show perfect stability versus non-deterministic dense retrieval.
What carries the argument
SHA-256 hash-chained version histories and deterministic set-algebraic selectors that enforce approval, currency, and traceability before any retrieval occurs
Load-bearing premise
The two controlled experiments accurately isolate governance failure modes from retrieval quality and the 1,060-document corpus and attack setup generalize to realistic autonomous AI agent deployments.
What would settle it
A larger experiment or real deployment in which governed selection no longer maintains a 97 percent pass rate at one-third the token cost under a stale-version attack that isolates governance from retrieval.
Figures
read the original abstract
Autonomous AI agents increasingly depend on external knowledge stores, yet most retrieval pipelines provide relevance without durable guarantees of provenance, version identity, integrity, traceability, or point-in-time reconstruction. We formalize this as context governance and present ContextNext, an open specification and reference implementation for governed AI-consumable knowledge vaults. ContextNext does not replace Retrieval-Augmented Generation (RAG); it supplies the governance layer beneath retrieval, determining which artifacts are approved, current, attributable, and integrity-verified before retrieval systems operate over them. The specification combines typed Markdown documents with metadata, deterministic set-algebraic selectors, contextnest:// URI references, SHA-256 hash-chained version histories, graph-level checkpoints, source nodes for live data through the Model Context Protocol (MCP), and audit traces of agent context consumption. These mechanisms let organizations reconstruct which knowledge versions informed an agent output and whether those versions were AI-eligible when consumed. We report first empirical results from two controlled experiments. In a stale-version attack isolating the governance-versus-retrieval failure mode, governed selection strictly Pareto-dominates BM25 sparse retrieval, with higher answer-quality pass rate (97% versus 93-90%) at about one-third the input-token cost. In a retrieval-determinism experiment over a 1,060-document corpus, deterministic selectors and BM25 return stable document sets across repeated identical queries (Jaccard 1.0), while a dense+HNSW baseline is non-deterministic on 80% of queries (mean Jaccard 0.611, worst case 0.210). These results suggest that context governance addresses failure modes retrieval quality alone is not designed to resolve. We release a core engine, CLI, and MCP server under open licenses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ContextNest (also styled ContextNext in the abstract), an open specification and reference implementation for verifiable context governance in autonomous AI agents. It layers mechanisms including typed Markdown documents with metadata, deterministic set-algebraic selectors, contextnest:// URI references, SHA-256 hash-chained version histories, graph-level checkpoints, Model Context Protocol (MCP) source nodes, and audit traces over existing retrieval systems such as RAG. The central empirical claims are that, in a stale-version attack, governed selection strictly Pareto-dominates BM25 (97% vs. 93-90% answer-quality pass rate at ~1/3 input-token cost) and that deterministic selectors achieve perfect stability (Jaccard 1.0) over a 1,060-document corpus while a dense+HNSW baseline does not (mean Jaccard 0.611).
Significance. If the empirical isolation holds, the work supplies a missing governance layer that addresses provenance, version identity, and integrity guarantees that standard retrieval quality metrics do not target. The open release of the core engine, CLI, and MCP server under open licenses is a concrete strength that would enable community verification and extension.
major comments (2)
- [Abstract] Abstract (stale-version attack paragraph): the reported Pareto dominance (97% pass rate at one-third token cost) is presented without any description of how stale versions were injected into the corpus, how answer quality was scored, what the exact selector logic was, or any ablation confirming that the governed and BM25 runs operated over identical candidate pools. This detail is load-bearing for the claim that governance, rather than incidental document filtering, produces the observed improvement.
- [Abstract] Abstract (retrieval-determinism experiment paragraph): the 1,060-document corpus, Jaccard scores, and comparison to dense+HNSW are given without dataset construction details, statistical analysis, variance estimates, or controls confirming that the determinism result is attributable to the selectors rather than corpus properties.
minor comments (2)
- [Abstract] The abstract introduces the 'contextnest:// URI scheme' and 'Model Context Protocol (MCP)' as core components without inline definitions or citations to prior work establishing these as standard.
- The paper title uses 'ContextNest' while the abstract body uses 'ContextNext'; this inconsistency should be resolved throughout.
Simulated Author's Rebuttal
Thank you for your review and for identifying these points where the abstract could provide more context on the experiments. We will make the suggested revisions to the abstract to ensure the empirical claims are presented with sufficient methodological transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract (stale-version attack paragraph): the reported Pareto dominance (97% pass rate at one-third token cost) is presented without any description of how stale versions were injected into the corpus, how answer quality was scored, what the exact selector logic was, or any ablation confirming that the governed and BM25 runs operated over identical candidate pools. This detail is load-bearing for the claim that governance, rather than incidental document filtering, produces the observed improvement.
Authors: We agree that these methodological details are essential for evaluating the claim and are not present in the abstract. They are fully described in the experimental section of the manuscript. To make the abstract more informative, we will revise it to include a short description of the stale-version injection method, quality scoring, and confirmation of identical candidate pools. This addresses the concern without expanding the abstract excessively. revision: yes
-
Referee: [Abstract] Abstract (retrieval-determinism experiment paragraph): the 1,060-document corpus, Jaccard scores, and comparison to dense+HNSW are given without dataset construction details, statistical analysis, variance estimates, or controls confirming that the determinism result is attributable to the selectors rather than corpus properties.
Authors: The abstract summarizes the key findings of the determinism experiment. Detailed information on corpus construction, Jaccard index computation, statistical measures, variance, and controls to isolate the effect of the selectors is provided in the manuscript. We will update the abstract to briefly reference the experimental controls and dataset to strengthen the presentation of this result. revision: yes
Circularity Check
No circularity: empirical results independent of specification
full rationale
The paper presents an open specification for context governance (typed Markdown, hash-chained histories, deterministic selectors, MCP sources) and then reports separate controlled experiments measuring answer-quality pass rates and determinism. No equations, first-principles derivations, or predictions appear in the abstract or described claims. The reported Pareto dominance (97% vs 93-90% at 1/3 token cost) and Jaccard scores are framed as experimental outcomes, not outputs computed from the specification itself. No self-citations, fitted parameters renamed as predictions, or ansatzes are load-bearing. This matches the default expectation that most papers contain no circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math SHA-256 provides collision resistance sufficient for version chaining
- domain assumption Deterministic selectors produce stable sets independent of query order or implementation details
invented entities (2)
-
contextnest:// URI scheme
no independent evidence
-
Model Context Protocol (MCP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
B. R. Konsynski. Trustworthy agentic systems: Evaluation harnesses, observability, and governance as the foundation for enterprise and market adoption. Executive briefing, Goizueta Business School, Emory University, January 2026
2026
-
[2]
Elofson and B
G. Elofson and B. R. Konsynski. Delegation technologies: Environmental scanning with intelligent agents. Journal of Management Information Systems, 8(1):37--62, 1991
1991
-
[3]
Fjeldstad and B
D. Fjeldstad and B. R. Konsynski. The role of cognitive apportionment in information systems. In Proceedings of the Seventh International Conference on Information Systems, pages 84--98, 1986
1986
-
[4]
B. R. Konsynski and J. J. Sviokla. Cognitive reapportionment: Rethinking the location of judgment in managerial decision making. In C. Heckscher and A. Donnellon, editors, The Post-Bureaucratic Organization: New Perspectives on Organizational Change. Sage Publications, 1994
1994
-
[5]
B. R. Konsynski, A. Kathuria, and P. P. Karhade. Special section: Cognitive reapportionment and the art of letting go: A theoretical framework for the allocation of decision rights. Journal of Management Information Systems, 41(2):328--340, 2024
2024
-
[6]
ISO/IEC 42001: Information technology --- Artificial intelligence --- Management system
ISO/IEC. ISO/IEC 42001: Information technology --- Artificial intelligence --- Management system. International Organization for Standardization, 2023. https://www.iso.org/standard/42001.html
2023
-
[7]
OWASP Top 10 for Large Language Model Applications, v1.1
OWASP. OWASP Top 10 for Large Language Model Applications, v1.1. OWASP Foundation, 2023. https://owasp.org/www-project-top-10-for-large-language-model-applications/
2023
-
[8]
What is OpenTelemetry ? Cloud Native Computing Foundation, 2025
OpenTelemetry. What is OpenTelemetry ? Cloud Native Computing Foundation, 2025. https://opentelemetry.io/docs/what-is-opentelemetry/
2025
-
[9]
Announcing Agent Payments Protocol (AP2) , September 2025
Google Cloud. Announcing Agent Payments Protocol (AP2) , September 2025. https://cloud.google.com/blog/products/ai-machine-learning/announcing-agents-to-payments-ap2-protocol
2025
-
[10]
Mastercard unveils Agent Pay , pioneering agentic payments technology to power commerce in the age of AI , April 2025
Mastercard. Mastercard unveils Agent Pay , pioneering agentic payments technology to power commerce in the age of AI , April 2025
2025
-
[11]
Nottingham and E
M. Nottingham and E. Wilde. Problem details for HTTP APIs . RFC 7807, IETF, 2016
2016
-
[12]
Model Context Protocol specification, 2024
Anthropic. Model Context Protocol specification, 2024. https://modelcontextprotocol.io
2024
-
[13]
Bordes, N
A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko. Translating embeddings for modeling multi-relational data. In NeurIPS, pages 2787--2795, 2013
2013
-
[14]
Buneman, S
P. Buneman, S. Khanna, and W. C. Tan. Why and where: A characterization of data provenance. In ICDT, pages 316--330, 2001
2001
-
[15]
J. Chen, H. Lin, X. Han, and L. Sun. Benchmarking large language models in retrieval-augmented generation. In AAAI, 2024
2024
-
[16]
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, D. Metropolitansky, R. O. Ness, and J. Larson. From local to global: A graph RAG approach to query-focused summarization. arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Regulation ( EU ) 2024/1689 laying down harmonised rules on artificial intelligence ( AI Act )
European Parliament . Regulation ( EU ) 2024/1689 laying down harmonised rules on artificial intelligence ( AI Act ). Official Journal of the European Union, 2024
2024
-
[18]
Gebru, J
T. Gebru, J. Morgenstern, B. Vecchione, J. W. Vaughan, H. Wallach, H. Daum \'e III, and K. Crawford. Datasheets for datasets. Communications of the ACM, 64(12):86--92, 2021
2021
-
[19]
T. J. Green, G. Karvounarakis, and V. Tannen. Provenance semirings. In PODS, pages 31--40, 2007
2007
-
[20]
Groth and L
P. Groth and L. Moreau. PROV -overview: An overview of the PROV family of documents. W3C Working Group Note, 2013
2013
-
[21]
Izacard, M
G. Izacard, M. Caron, L. Hosseini, S. Riedel, P. Bojanowski, A. Joulin, and E. Grave. Unsupervised dense information retrieval with contrastive learning. TMLR, 2022
2022
-
[22]
S. Ji, S. Pan, E. Cambria, P. Marttinen, and P. S. Yu. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Transactions on Neural Networks and Learning Systems, 33(2):494--514, 2022
2022
-
[23]
Kuprieiev et al
R. Kuprieiev et al. DVC : Data version control, 2021. https://dvc.org
2021
-
[24]
u ttler, M. Lewis, W. Yih, T. Rockt \
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. K \"u ttler, M. Lewis, W. Yih, T. Rockt \"a schel, S. Riedel, and D. Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. In NeurIPS, pages 9459--9474, 2020
2020
-
[25]
R. C. Merkle. A digital signature based on a conventional encryption function. In Advances in Cryptology --- CRYPTO '87, LNCS 293, pages 369--378. Springer, 1987
1987
-
[26]
Mitchell, S
M. Mitchell, S. Wu, A. Zaldivar, P. Barnes, L. Vasserman, B. Hutchinson, E. Spitzer, I. D. Raji, and T. Gebru. Model cards for model reporting. In FAT*, pages 220--229, 2019
2019
-
[27]
Moreau et al
L. Moreau et al. The open provenance model core specification (v1.1). Future Generation Computer Systems, 27(6):743--756, 2011
2011
-
[28]
AI risk management framework ( AI RMF 1.0)
NIST . AI risk management framework ( AI RMF 1.0). NIST AI 100-1, 2023
2023
-
[29]
R. Nogueira and K. Cho. Passage re-ranking with BERT . arXiv preprint arXiv:1901.04085, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[30]
Press, M
O. Press, M. Zhang, S. Min, L. Schmidt, N. A. Smith, and M. Lewis. Measuring and narrowing the compositionality gap in language models. In Findings of EMNLP, 2023
2023
-
[31]
Rundgren, B
A. Rundgren, B. Jordan, and S. Erdtman. JSON Canonicalization Scheme ( JCS ). RFC 8785, IETF, 2020. https://datatracker.ietf.org/doc/html/rfc8785
2020
-
[32]
Torvalds
L. Torvalds. Git: A distributed version control system, 2005. https://git-scm.com
2005
-
[33]
LakeFS : Data version control for data lakes, 2020
Treeverse. LakeFS : Data version control for data lakes, 2020. https://lakefs.io
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.