Reasoning-aware Speculative Decoding for Efficient Vision-Language-Action Models in Autonomous Driving
Pith reviewed 2026-07-01 06:33 UTC · model grok-4.3
The pith
A two-reasoner speculative decoding setup splits chain-of-causation reasoning into routine history-based tokens and novel visual commitments to cut VLA planner latency by 4x.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
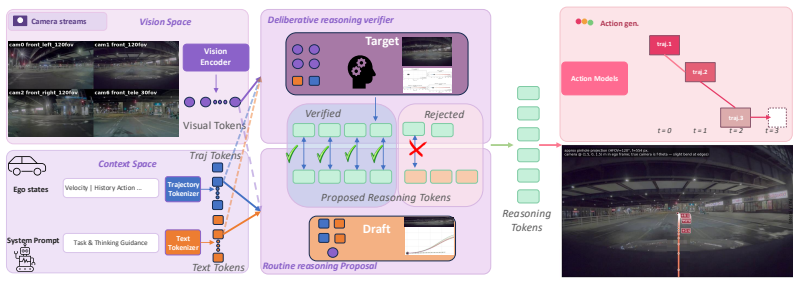
The authors establish that chain-of-causation reasoning tokens in VLA planners divide into two categories—predictable routine continuations from ego-trajectory history and sparse novel commitments requiring current visual evidence—and that a two-reasoner system using speculative decoding can assign the first category to a routine reasoner while reserving the second for the unmodified deliberative reasoner. They realize this split with FlatRoPE, a 1D rotary embedding in the routine reasoner that breaks the 3D M-RoPE rotational symmetry to redirect attention away from visuals, and Action-aware RL, a post-training stage that optimizes an action-quality reward against a static KL reference. This
What carries the argument
The two-reasoner speculative decoding framework, in which a routine reasoner specialized on trajectory history via FlatRoPE cooperates with the unmodified deliberative reasoner that attends to visual evidence.
If this is right
- Reasoning latency drops by a factor of four while the parallel trajectory head stays unchanged.
- The routine reasoner can be trained once and reused across multiple deliberative models that share the same history structure.
- Only the minority of tokens requiring visual evidence invoke the full costly model.
- The separation preserves action quality when the post-training reward and KL anchor are applied.
Where Pith is reading between the lines
- The same routine-versus-deliberative split could be tested in other autoregressive multimodal reasoning settings where history dominates most tokens.
- Hardware measurements on embedded vehicle processors would show whether the 4x reasoning speedup translates to end-to-end frame-rate gains under real sensor input.
- If the clean category split does not hold on new datasets, a learned router could replace the fixed two-path design.
Load-bearing premise
Chain-of-causation reasoning tokens divide cleanly into routine history-based continuations and novel visual commitments, and a specialized routine reasoner can be trained to handle the first category without degrading final trajectory quality.
What would settle it
A side-by-side evaluation on the same driving benchmark where the two-reasoner system produces trajectories with measurably higher collision rates or lower route-completion success than the original single-reasoner planner.
Figures
read the original abstract
Modern Vision-Language-Action (VLA) planners for autonomous driving emit a chain-of-causation (CoC) reasoning step \emph{before} producing a trajectory. The reasoning is autoregressive and dominates inference latency, while the trajectory head is parallel and cheap. Latency is an operational constraint in autonomous driving, so accelerating the reasoning step is the central problem we address. We observe that CoC reasoning has two qualitatively different needs: most tokens continue routine setup that follows naturally from the ego-trajectory history, and a small fraction encode commitments that require fresh visual evidence about an unexpected situation. We split this reasoning into two specialized paths: a \emph{routine reasoner} that handles the predictable continuation by attending to trajectory history, and a \emph{deliberative reasoner} (the unmodified VLA target) that handles novel cases by attending to current visual evidence, using the speculative decoding framework as the architectural template for how the two paths cooperate. Unlike standard speculative decoding, our routine reasoner is not a smaller replica of the target; the two reasoners are deliberately specialized to read different parts of the prompt. We propose two techniques to realize this. First, we introduce \textbf{FlatRoPE}, a 1D rotary positional embedding in the draft that breaks the rotational symmetry of the target's 3D M-RoPE, redirecting attention away from visual tokens and onto trajectory-history tokens. Second, we introduce \textbf{Action-aware RL (AARL)}, a post-training stage that uses an action-quality reward together with a static-reference KL anchor. Together, our two-reasoner system reduces the reasoning-step running time by approximately $4\times$ relative to the original Alpamayo planner.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a reasoning-aware speculative decoding framework for Vision-Language-Action (VLA) models in autonomous driving. It observes that chain-of-causation (CoC) reasoning tokens fall into routine continuations from trajectory history versus novel commitments requiring visual evidence, and introduces a specialized non-replica draft reasoner (via FlatRoPE to redirect attention to history tokens and Action-aware RL (AARL) with action-quality reward plus KL anchor) that cooperates with the unmodified target deliberative reasoner, claiming an approximately 4× reduction in reasoning-step latency relative to the Alpamayo baseline.
Significance. If validated, the result would address a key operational constraint (reasoning latency) in VLA planners for autonomous driving by accelerating the dominant autoregressive step while keeping the parallel trajectory head unchanged. The deliberate specialization of the draft beyond standard speculative decoding (breaking 3D M-RoPE symmetry and using RL anchoring) is a substantive technical contribution that could generalize to other autoregressive reasoning tasks.
major comments (2)
- [Abstract] Abstract: the central empirical claim of an approximately 4× reduction in reasoning-step running time is stated without any reported accuracy numbers, acceptance-rate statistics, trajectory-quality metrics, or ablation results on novel scenarios; this absence makes the speedup unverifiable and load-bearing for the paper's contribution.
- [Method] Method description of FlatRoPE and AARL: the assumption that CoC tokens split cleanly into routine vs. novel categories and that the specialized draft preserves final trajectory quality is not supported by any concrete test (e.g., acceptance curves or edge-case failure modes); because the draft is deliberately non-replica, standard speculative-decoding acceptance guarantees do not apply and the claim rests on this unverified split.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback on the empirical grounding of our claims. We agree that the abstract and method sections would benefit from additional explicit metrics and validation to strengthen verifiability, and we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of an approximately 4× reduction in reasoning-step running time is stated without any reported accuracy numbers, acceptance-rate statistics, trajectory-quality metrics, or ablation results on novel scenarios; this absence makes the speedup unverifiable and load-bearing for the paper's contribution.
Authors: We acknowledge that the abstract as written emphasizes the latency reduction without accompanying statistics. The full manuscript reports these supporting results (acceptance rates, trajectory metrics, and scenario ablations) in the experiments section. To make the central claim self-contained and verifiable at the abstract level, we will revise the abstract to include the key quantitative figures. revision: yes
-
Referee: [Method] Method description of FlatRoPE and AARL: the assumption that CoC tokens split cleanly into routine vs. novel categories and that the specialized draft preserves final trajectory quality is not supported by any concrete test (e.g., acceptance curves or edge-case failure modes); because the draft is deliberately non-replica, standard speculative-decoding acceptance guarantees do not apply and the claim rests on this unverified split.
Authors: The manuscript grounds the routine/novel split in observed token behavior during CoC generation and demonstrates overall trajectory quality preservation through end-to-end metrics. However, we agree that explicit per-category acceptance curves and targeted edge-case analysis would provide stronger support for the non-replica draft design. We will add these concrete tests and visualizations in the revised manuscript. revision: yes
Circularity Check
No circularity; 4× speedup is an empirical runtime measurement with no self-referential derivations
full rationale
The paper's central claim is an empirical measurement: the two-reasoner system (using FlatRoPE and AARL) reduces reasoning-step running time by ~4× relative to the Alpamayo baseline. No equations, derivations, or self-citations are exhibited that reduce this result to fitted parameters, self-definitions, or prior author work by construction. The techniques are presented as novel proposals whose effect is measured externally against a baseline, satisfying the criteria for a self-contained empirical result with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Chain-of-causation reasoning contains a majority of tokens whose content follows naturally from ego-trajectory history alone.
invented entities (2)
-
FlatRoPE
no independent evidence
-
Action-aware RL (AARL)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
GQA: Training generalized multi-query transformer models from multi- head checkpoints
Joshua Ainslie et al. GQA: Training generalized multi-query transformer models from multi- head checkpoints. InEMNLP, 2023
2023
-
[2]
Qwen-VL: A versatile vision-language model, 2023
Jinze Bai et al. Qwen-VL: A versatile vision-language model, 2023
2023
-
[3]
Medusa: Simple LLM inference acceleration framework with multiple decoding heads, 2024
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongyi Peng, Tri Chen, Bo Zhao, and Tri Dao. Medusa: Simple LLM inference acceleration framework with multiple decoding heads, 2024
2024
-
[4]
Accelerating large language model decoding with speculative sampling, 2023
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling, 2023
2023
-
[5]
Break the sequential dependency of LLM inference using lookahead decoding
Yichao Fu et al. Break the sequential dependency of LLM inference using lookahead decoding. InICML, 2024
2024
-
[6]
Orion-Lite: Distilling LLM reasoning into efficient vision-only driving models, 2026
Jing Gu, Niccolò Cavagnero, and Gijs Dubbelman. Orion-Lite: Distilling LLM reasoning into efficient vision-only driving models, 2026
2026
-
[7]
TinyDrive: Multiscale visual question answering with selective token routing for autonomous driving, 2025
Hossein Hassani, Soodeh Nikan, and Abdallah Shami. TinyDrive: Multiscale visual question answering with selective token routing for autonomous driving, 2025
2025
-
[8]
GAIA-1: A generative world model for autonomous driving, 2023
Anthony Hu et al. GAIA-1: A generative world model for autonomous driving, 2023
2023
-
[9]
Planning-oriented autonomous driving
Yihan Hu et al. Planning-oriented autonomous driving. InCVPR, 2023
2023
-
[10]
RoboTron-Drive: All-in-one large multimodal model for autonomous driving, 2024
Zhijian Huang, Chengjian Feng, Feng Yan, Baihui Xiao, Zequn Jie, Yujie Zhong, Xiaodan Liang, and Lin Ma. RoboTron-Drive: All-in-one large multimodal model for autonomous driving, 2024
2024
-
[11]
EMMA: End-to-end multimodal model for autonomous driving, 2024
Albert Hwang et al. EMMA: End-to-end multimodal model for autonomous driving, 2024
2024
-
[12]
Speculative decoding via big little decoder (SpS), 2023
Jongseok Kim et al. Speculative decoding via big little decoder (SpS), 2023. arXiv preprint. 10
2023
-
[13]
Big little decoder (BiLD)
Sehoon Kim et al. Big little decoder (BiLD). InNeurIPS, 2023
2023
-
[14]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InICML, 2023
2023
-
[15]
EAGLE: Speculative sampling requires rethinking feature uncertainty, 2024
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE: Speculative sampling requires rethinking feature uncertainty, 2024
2024
-
[16]
EAGLE-2: Faster inference of language models with dynamic draft trees, 2024
Yuhui Li et al. EAGLE-2: Faster inference of language models with dynamic draft trees, 2024. EMNLP
2024
-
[17]
EAGLE-3: Scaling up inference acceleration of LLMs via training-time test, 2025
Yuhui Li et al. EAGLE-3: Scaling up inference acceleration of LLMs via training-time test, 2025
2025
-
[18]
When hidden states drift: Can KV caches rescue long-range speculative decoding?, 2026
Tianyu Liu, Yuhao Shen, Xinyi Hu, Baolin Zhang, Hengxin Zhang, Jun Dai, Jun Zhang, Shuang Ge, Lei Chen, Yue Li, and MingCheng Wan. When hidden states drift: Can KV caches rescue long-range speculative decoding?, 2026
2026
-
[19]
KV-cache sharing across speculative iterations, 2024
Zixuan Liu et al. KV-cache sharing across speculative iterations, 2024. arXiv preprint
2024
-
[20]
SpecInfer: Accelerating generative LLM serving with speculative inference and token tree verification, 2023
Xupeng Miao et al. SpecInfer: Accelerating generative LLM serving with speculative inference and token tree verification, 2023
2023
-
[21]
Block diffusion language models, 2024
Subham Sahoo et al. Block diffusion language models, 2024. arXiv preprint
2024
-
[22]
Simple and effective masked diffusion language models, 2024
Subham Sahoo et al. Simple and effective masked diffusion language models, 2024
2024
-
[23]
DriveLM: Driving with graph visual question answering, 2023
Chonghao Sima et al. DriveLM: Driving with graph visual question answering, 2023
2023
-
[24]
OmniDrive: A holistic LLM-agent framework for autonomous driving, 2024
Shihao Wang et al. OmniDrive: A holistic LLM-agent framework for autonomous driving, 2024
2024
-
[25]
System-1.5 reasoning: Traversal in language and latent spaces with dynamic shortcuts, 2025
Xiaoqiang Wang, Suyuchen Wang, Yun Zhu, and Bang Liu. System-1.5 reasoning: Traversal in language and latent spaces with dynamic shortcuts, 2025
2025
-
[26]
Self-consistency improves chain of thought reasoning in language models, 2022
Xuezhi Wang et al. Self-consistency improves chain of thought reasoning in language models, 2022
2022
-
[27]
Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail, 2025
Yan Wang, Wenjie Luo, Junjie Bai, Yulong Cao, Tong Che, Ke Chen, Yuxiao Chen, Jenna Diamond, Yifan Ding, Wenhao Ding, Liang Feng, Greg Heinrich, Jack Huang, Peter Karkus, Boyi Li, Pinyi Li, Tsung-Yi Lin, Dongran Liu, Ming-Yu Liu, Langechuan Liu, Zhijian Liu, Jason Lu, Yunxiang Mao, Pavlo Molchanov, Lindsey Pavao, Zhenghao Peng, Mike Ranzinger, Ed Schmerli...
2025
-
[28]
LINGO-1: Exploring natural language for autonomous driving
Wayve. LINGO-1: Exploring natural language for autonomous driving. Technical report, Wayve, 2023
2023
-
[29]
Do what you say: Steering vision-language-action models via runtime reasoning-action align- ment verification, 2025
Yilin Wu, Anqi Li, Tucker Hermans, Fabio Ramos, Andrea Bajcsy, and Claudia Pérez-D’Arpino. Do what you say: Steering vision-language-action models via runtime reasoning-action align- ment verification, 2025
2025
-
[30]
OpenEMMA: Open-source multimodal model for end-to-end autonomous driving, 2024
Shuo Xing, Chengyuan Qian, Yuping Wang, Hongyuan Hua, Kexin Tian, Yang Zhou, and Zhengzhong Tu. OpenEMMA: Open-source multimodal model for end-to-end autonomous driving, 2024
2024
-
[31]
DriveGPT4: Interpretable end-to-end autonomous driving via large language model.IEEE Robotics and Automation Letters, 2024
Zhenhua Xu et al. DriveGPT4: Interpretable end-to-end autonomous driving via large language model.IEEE Robotics and Automation Letters, 2024
2024
-
[32]
DeeR-VLA: Dynamic inference of multimodal large language models for efficient robot execution, 2024
Yang Yue, Yulin Wang, Bingyi Kang, Yizeng Han, Shenzhi Wang, Shiji Song, Jiashi Feng, and Gao Huang. DeeR-VLA: Dynamic inference of multimodal large language models for efficient robot execution, 2024. 11
2024
-
[33]
X-Cache: Cross-chunk block caching for few-step autoregressive world models inference, 2026
Yixiao Zeng, Jianlei Zheng, Chaoda Zheng, Shijia Chen, Mingdian Liu, Tongping Liu, Tengwei Luo, Yu Zhang, Boyang Wang, Linkun Xu, Siyuan Lu, Bo Tian, and Xianming Liu. X-Cache: Cross-chunk block caching for few-step autoregressive world models inference, 2026
2026
-
[34]
MiniDrive: More efficient vision-language models with multi-level 2d features as text tokens for autonomous driving, 2024
Enming Zhang, Xingyuan Dai, Min Huang, Yisheng Lv, and Qinghai Miao. MiniDrive: More efficient vision-language models with multi-level 2d features as text tokens for autonomous driving, 2024
2024
-
[35]
the car is
Zewei Zhou, Tianhui Cai, Seth Z. Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. AutoVLA: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning, 2025. 12 A Implementation details 1D rotary in the draft.For each draft architecture we replace the rotary embedding module with a vanilla ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.