Secure-CHG: A Comprehensive Framework for Robust and Fair Federated Learning via Hybrid Defense and Contribution-Aware Trust
Pith reviewed 2026-07-01 05:51 UTC · model grok-4.3
The pith
Secure-CHG detects stealthy backdoor attackers in converged federated learning by projecting updates into a hardness-gradient space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
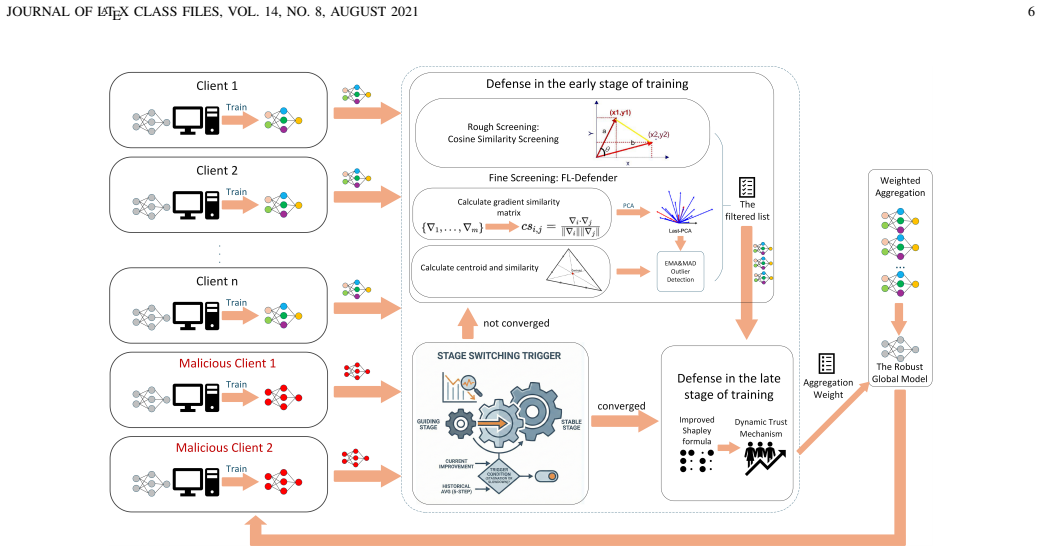
As the global model converges in federated learning, decaying gradient norms render malicious and benign updates morphologically indistinguishable, blinding traditional defenses. Secure-CHG pivots the defense to intrinsic semantic contribution verification by projecting updates into a Hardness-Gradient space using local training loss to amplify adversarial semantic traces, enabling isolation of stealthy attackers; it supplies a closed-form CHG-Shapley solution for retraining-free node valuation and trust-modulated aggregation.
What carries the argument
The CHG-Shapley mechanism projects client updates into a composite Hardness-Gradient space based on local training loss to verify semantic contributions and compute trust scores.
If this is right
- Secure-CHG reduces advanced backdoor attack success rates by 2.3 times and 2.0 times relative to Krum and Trimmed Mean baselines.
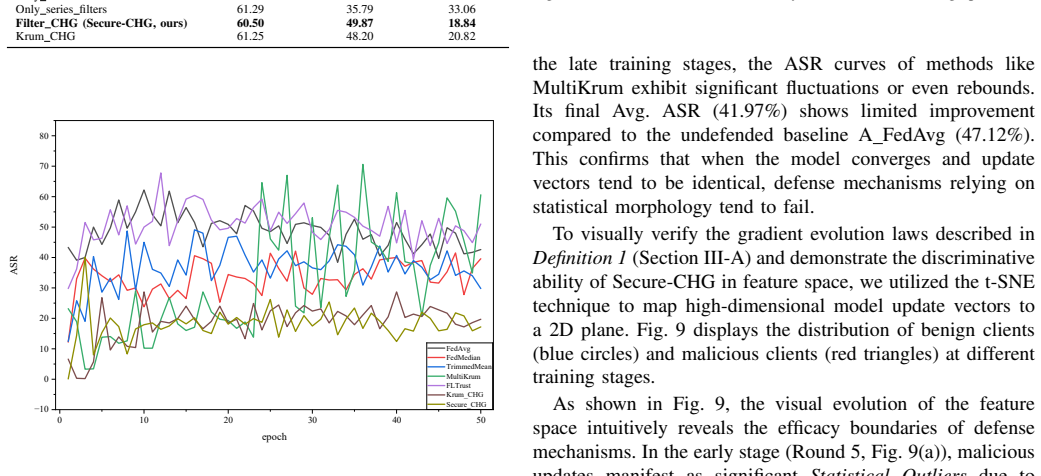
- The cascaded statistical filter stabilizes early training while CHG-Shapley handles late-stage convergence without retraining.
- Closed-form CHG-Shapley enables low-complexity, contribution-aware trust-modulated aggregation across clients.
- The approach maintains effectiveness across CIFAR-10, MedMNIST, and NEU-SDDB datasets against adaptive adversaries.
Where Pith is reading between the lines
- The hardness-based projection might extend to detecting other data poisoning attacks that become dormant after early rounds.
- Applying the same space projection in centralized training could reveal whether semantic traces persist outside federated settings.
- The method suggests testing whether trust scores remain stable when client participation rates vary widely in late stages.
- Future experiments could check if the composite space still separates attackers when local losses are deliberately equalized by adversaries.
Load-bearing premise
Projecting updates into a composite Hardness-Gradient space using local training loss amplifies adversarial semantic traces enough to isolate stealthy attackers even after gradient norms have vanished.
What would settle it
Measure whether advanced backdoor attack success rates stay suppressed under Secure-CHG on CIFAR-10 once gradient norms drop near zero, versus the rates observed with Krum and Trimmed Mean.
Figures
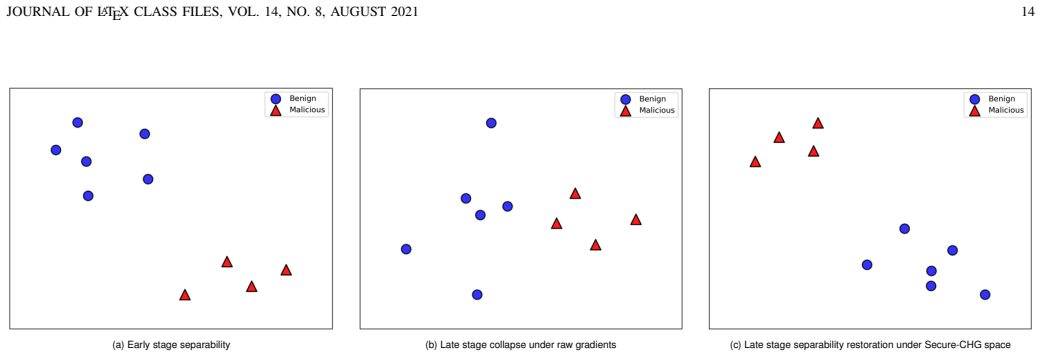
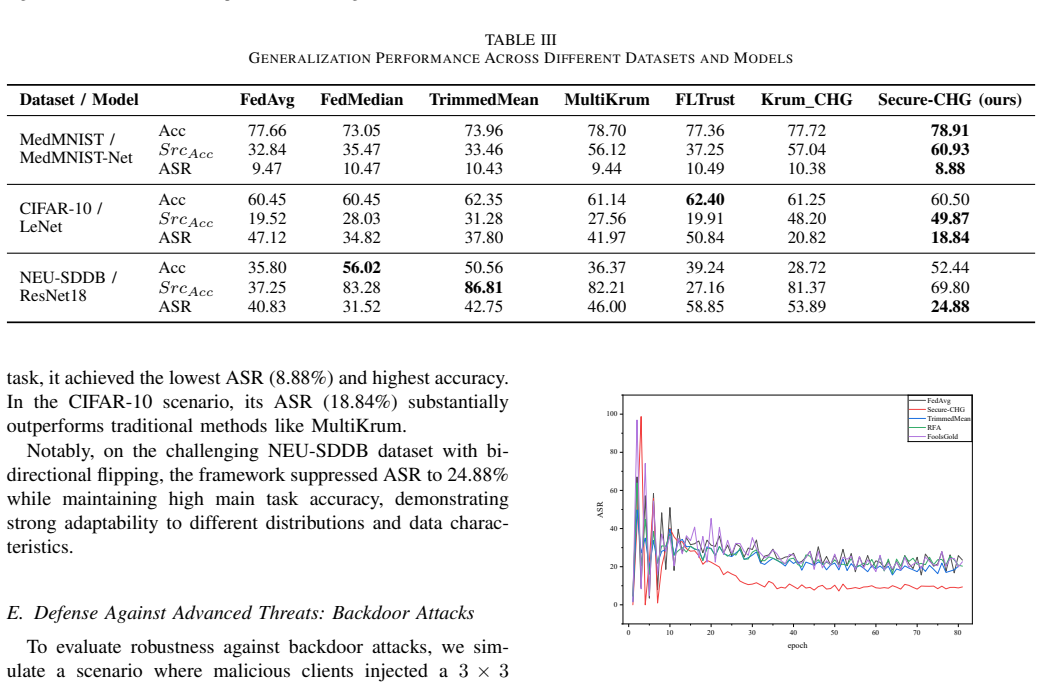
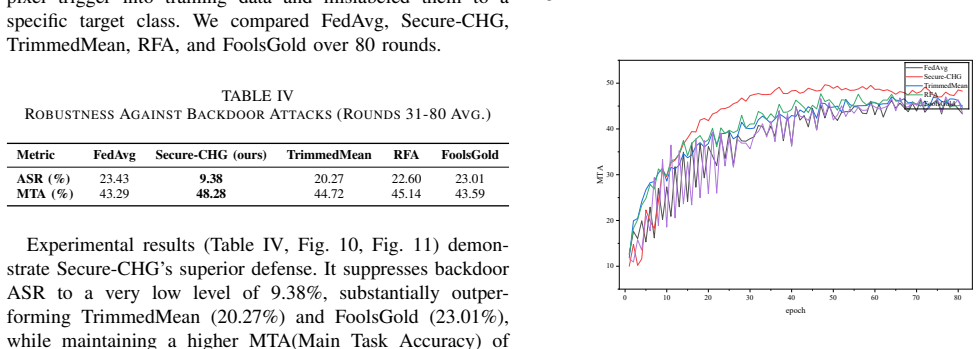
read the original abstract
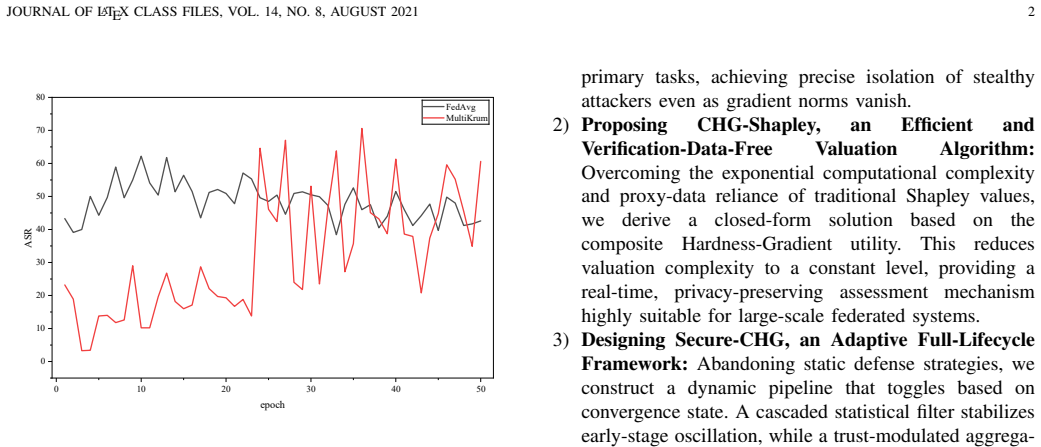
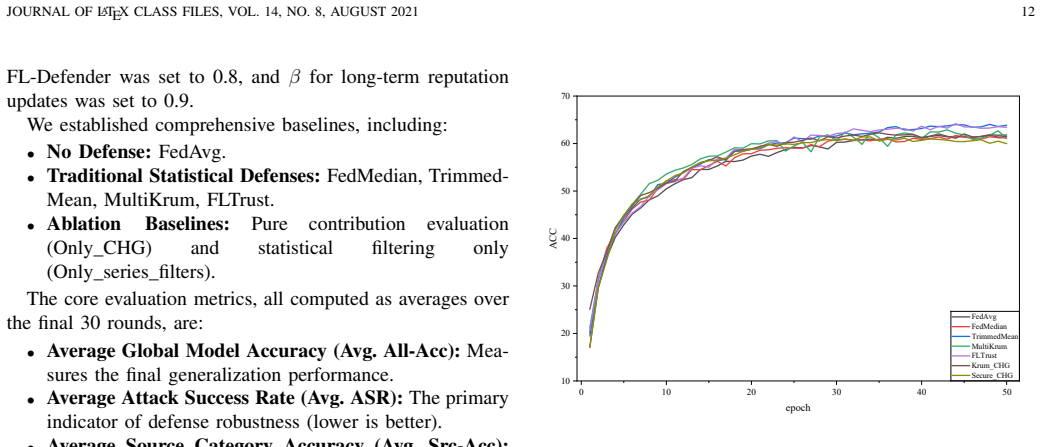
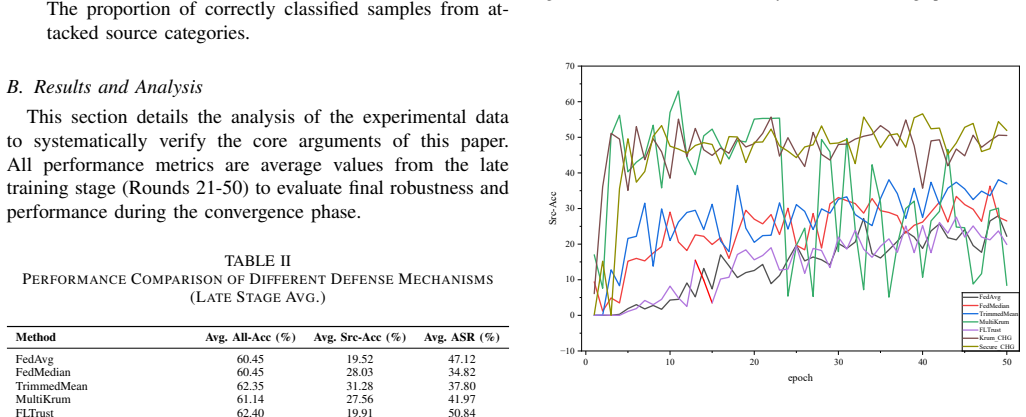
Federated Learning (FL) is highly susceptible to stealthy backdoor attacks, which aim to force a model into predicting an attacker-chosen target class for inputs containing a specific trigger. However, existing statistical defenses primarily focus on the early stages of model convergence. In this paper, we identify a fundamental vulnerability termed ``Late-stage Failure.'' We demonstrate that as the global model converges, decaying gradient norms render malicious and benign updates morphologically indistinguishable. This vanishing statistical variance effectively blinds traditional defenses, enabling adaptive adversaries to remain dormant and subsequently hijack the training process. To overcome these constraints, we propose Secure-CHG, a hybrid framework that pivots the defense paradigm from superficial morphological detection toward intrinsic semantic contribution verification. Secure-CHG employs an adaptive defense pipeline: a cascaded statistical filter stabilizes optimization during the early oscillatory phase, while a novel CHG-Shapley mechanism takes over during late-stage convergence. By leveraging sample hardness (i.e., local training loss) to project updates into a composite Hardness-Gradient space, it effectively amplifies adversarial semantic traces, enabling the isolation of stealthy attackers even as gradient norms vanish. Furthermore, we derive a closed-form solution for CHG-Shapley, facilitating low-complexity, retraining-free node valuation and trust-modulated aggregation. Extensive evaluations on CIFAR-10, MedMNIST, and NEU-SDDB demonstrate that Secure-CHG effectively mitigates Late-stage Failure. Specifically, it significantly suppresses advanced backdoor attacks, reducing their attack success rate by 2.3$\times$ and 2.0$\times$ relative to the mainstream Krum and Trimmed Mean baselines, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to identify a "Late-stage Failure" vulnerability in federated learning defenses against stealthy backdoor attacks, where vanishing gradient norms render malicious and benign updates indistinguishable. It proposes Secure-CHG, a hybrid framework consisting of an early cascaded statistical filter and a late-stage CHG-Shapley mechanism. The latter projects updates into a composite Hardness-Gradient space using local training loss (sample hardness) to amplify adversarial semantic traces, derives a closed-form solution for low-complexity node valuation, and performs trust-modulated aggregation. Experiments on CIFAR-10, MedMNIST, and NEU-SDDB report that Secure-CHG reduces attack success rates by 2.3× and 2.0× relative to Krum and Trimmed Mean baselines.
Significance. If the central claims hold, the work would address a potentially important gap in FL robustness by shifting from morphological to semantic contribution verification for late-stage convergence. The derivation of a closed-form CHG-Shapley solution is a strength, as it supports retraining-free, low-complexity implementation.
major comments (2)
- [Abstract] Abstract: The core claim that the CHG-Shapley projection into Hardness-Gradient space using local training loss isolates stealthy attackers even after gradient norms vanish lacks any derivation, bound, or analysis showing that loss distributions remain distinguishable under adaptive adversaries that mimic benign converged losses while embedding triggers. This assumption is load-bearing for the Late-stage Failure mitigation guarantee.
- [Abstract] Abstract: The quantitative claims of 2.3× and 2.0× ASR reductions are presented without any experimental protocol, baseline implementation details, number of clients, attack configurations, or error analysis, preventing verification of the empirical results against the stated improvements.
minor comments (1)
- The abstract refers to "extensive evaluations" and a "closed-form solution" but supplies no section references, equations, or pseudocode to locate the derivation or experimental setup.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on our manuscript. We address each major comment below, indicating where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The core claim that the CHG-Shapley projection into Hardness-Gradient space using local training loss isolates stealthy attackers even after gradient norms vanish lacks any derivation, bound, or analysis showing that loss distributions remain distinguishable under adaptive adversaries that mimic benign converged losses while embedding triggers. This assumption is load-bearing for the Late-stage Failure mitigation guarantee.
Authors: We acknowledge that the abstract does not contain an explicit derivation or bound. The manuscript describes the CHG-Shapley projection mechanism and derives its closed-form solution in the main text, with the rationale for using sample hardness to amplify semantic traces. However, a formal analysis or bound specifically addressing distinguishability under adaptive adversaries that mimic converged losses is not provided. We will revise the abstract to reference the relevant analysis in the main text and add a concise discussion of the loss distribution separation property to address this load-bearing assumption. revision: yes
-
Referee: [Abstract] Abstract: The quantitative claims of 2.3× and 2.0× ASR reductions are presented without any experimental protocol, baseline implementation details, number of clients, attack configurations, or error analysis, preventing verification of the empirical results against the stated improvements.
Authors: Abstracts are summaries and conventionally omit full protocol details. The complete experimental protocol, baseline implementations, client and attack configurations, and error analysis are provided in the Experiments section of the manuscript. To improve verifiability from the abstract alone, we will add a brief clause directing readers to the experimental section for the reported improvements and key setup parameters. revision: partial
Circularity Check
No circularity: CHG-Shapley presented as independent closed-form derivation
full rationale
The provided abstract and description show CHG-Shapley as a derived closed-form solution obtained by projecting updates into a Hardness-Gradient space via local training loss. No equations or steps reduce by construction to fitted parameters, self-definitions, or self-citation chains. The central mechanism is framed as a novel projection and valuation step with no visible renaming of known results or ansatz smuggling. The derivation chain appears self-contained against external benchmarks, consistent with the reader's assessment of no visible reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Local training loss can be used to project model updates into a space that separates benign and malicious contributions even at convergence.
invented entities (1)
-
CHG-Shapley mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inArtificial intelligence and statistics. Pmlr, 2017, pp. 1273–1282. [Online]. Available: https://proceedings.mlr.press/v54/ mcmahan17a
2017
-
[2]
Federated learning on non- iid data: A survey,
H. Zhu, J. Xu, S. Liu, and Y . Jin, “Federated learning on non- iid data: A survey,”Neurocomputing, vol. 465, pp. 371–390, 2021, doi:10.1016/j.neucom.2021.07.098
-
[3]
How to backdoor federated learning,
E. Bagdasaryan, A. Veit, Y . Hua, D. Estrin, and V . Shmatikov, “How to backdoor federated learning,” inInternational conference on artificial intelligence and statistics. PMLR, 2020, pp. 2938–2948. [Online]. Available: https://proceedings.mlr.press/v108/bagdasaryan20a
2020
-
[4]
Data poisoning attacks against federated learning systems,
V . Tolpegin, S. Truex, M. E. Gursoy, and L. Liu, “Data poisoning attacks against federated learning systems,” inEuropean symposium on research in computer security. Springer, 2020, pp. 480–501. [Online]. Available: https://link.springer.com/chapter/10.1007/978-3-030-58951-6 24
-
[5]
Manipulating the byzantine: Optimizing model poisoning attacks and defenses for federated learning,
V . Shejwalkar and A. Houmansadr, “Manipulating the byzantine: Optimizing model poisoning attacks and defenses for federated learning,” inProceedings of the 2021 Network and Distributed System Security Symposium (NDSS), 2021. [Online]. Available: https://par.nsf.gov/servlets/purl/10286354
-
[6]
Byzantine-Tolerant Machine Learning
P. Blanchard, E. M. El Mhamdi, R. Guerraoui, and J. Stainer, “Ma- chine learning with adversaries: Byzantine tolerant gradient descent,” Advances in neural information processing systems, vol. 30, 2017, doi:10.48550/arXiv.1703.02757
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1703.02757 2017
-
[7]
Byzantine-robust distributed learning: Towards optimal statistical rates,
D. Yin, Y . Chen, R. Kannan, and P. Bartlett, “Byzantine-robust distributed learning: Towards optimal statistical rates,” inInternational conference on machine learning. Pmlr, 2018, pp. 5650–5659. [Online]. Available: https://proceedings.mlr.press/v80/yin18a
2018
-
[8]
Fl-defender: Combating targeted attacks in federated learning,
N. M. Jebreel and J. Domingo-Ferrer, “Fl-defender: Combating targeted attacks in federated learning,”Knowledge-Based Systems, vol. 260, p. 110178, 2023, doi:10.1016/j.knosys.2022.110178
-
[9]
Robust aggregation for federated learning,
K. Pillutla, S. M. Kakade, and Z. Harchaoui, “Robust aggregation for federated learning,”IEEE Transactions on Signal Processing, vol. 70, pp. 1142–1154, 2022, doi:10.1109/TSP.2022.3153135
-
[10]
Mitigating sybil attacks in federated learning,
A. E. Samy and ˇS. Girdzijauskas, “Mitigating sybil attacks in federated learning,” inInternational Conference on Information Security Practice and Experience. Springer, 2023, pp. 36–51, doi:10.1007/978-981-99- 7032-2 3
-
[11]
Available: https://arxiv.org/abs/2012.13995
X. Cao, M. Fang, J. Liu, and N. Z. Gong, “Fltrust: Byzantine- robust federated learning via trust bootstrapping,”arXiv preprint arXiv:2012.13995, 2020, doi:10.48550/arXiv.2012.13995
-
[12]
Byzantine-robust aggregation for federated learning with reinforcement learning,
S. Yan, J. Du, Z. Xue, and A. Li, “Byzantine-robust aggregation for federated learning with reinforcement learning,” inAsia-Pacific Web (APWeb) and Web-Age Information Management (WAIM) Joint International Conference on Web and Big Data. Springer, 2024, pp. 152–166, doi:10.1007/978-981-97-7241-4 10
-
[13]
Meta stackelberg game: Robust federated learning against adaptive and mixed poisoning attacks,
T. Li, H. Li, Y . Pan, T. Xu, Z. Zheng, and Q. Zhu, “Meta stackelberg game: Robust federated learning against adaptive and mixed poisoning attacks,”arXiv preprint arXiv:2410.17431, 2024, doi:10.48550/arXiv.2410.17431
-
[14]
Understanding clipping for federated learning: Convergence and client-level differential privacy,
X. Zhang, X. Chen, M. Hong, Z. S. Wu, and J. Yi, “Understanding clipping for federated learning: Convergence and client-level differential privacy,” inInternational Conference on Machine Learning, ICML 2022,
2022
-
[15]
Available: https://par.nsf.gov/servlets/purl/10395073
[Online]. Available: https://par.nsf.gov/servlets/purl/10395073
-
[16]
Adaptive byzantine-robust differentially private fed- erated learning,
Y . W ANG, Q. ZHANG, W. QIU, Z. CHAI, S. GAO, J. ZHU, Y . TONG, and Z. ZHENG, “Adaptive byzantine-robust differentially private fed- erated learning,”SCIENTIA SINICA Informationis, vol. 55, no. 11, p. 2663, 2025, doi:10.1360/SSI-2025-0232. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 16
-
[17]
Differ- entially private federated learning with an adaptive noise mechanism,
R. Xue, K. Xue, B. Zhu, X. Luo, T. Zhang, Q. Sun, and J. Lu, “Differ- entially private federated learning with an adaptive noise mechanism,” IEEE Transactions on Information Forensics and Security, vol. 19, pp. 74–87, 2023, doi:10.1109/TIFS.2023.3318944
-
[18]
Y . Li, L. Fu, T. Wang, J. Lou, B. Chen, L. Yang, J. Shen, Z. Zheng, and C. Chen, “Clients collaborate: Flexible differentially private federated learning with guaranteed improvement of utility-privacy trade-off,”arXiv preprint arXiv:2402.07002, 2024, doi:10.48550/arXiv.2402.07002
-
[19]
Byzantine fault-tolerant federated learning based on trustworthy data and historical information,
X. Luo and B. Tang, “Byzantine fault-tolerant federated learning based on trustworthy data and historical information,”Electronics, vol. 13, no. 8, p. 1540, 2024, doi:10.3390/electronics13081540
-
[20]
Byzantine-robust decentralized federated learning via dual-domain clustering and trust bootstrapping,
P. Sun, X. Liu, Z. Wang, and B. Liu, “Byzantine-robust decentralized federated learning via dual-domain clustering and trust bootstrapping,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 24 756–24 765. [Online]. Available: https://openaccess.thecvf.com/content/CVPR2024/ html/Sun Byzantine-robust Decentraliz...
2024
-
[21]
Cgfl: A robust federated learning approach for intrusion detection systems based on data generation,
S. Feng, L. Gao, and L. Shi, “Cgfl: A robust federated learning approach for intrusion detection systems based on data generation,”Applied Sciences, vol. 15, no. 5, p. 2416, 2025, doi:10.3390/app15052416
-
[22]
Robust federated learning against poisoning attacks: a gan-based defense framework,
U. Zafar, A. Teixeira, S. Tooret al., “Robust federated learning against poisoning attacks: a gan-based defense framework,”arXiv e-prints, pp. arXiv–2503, 2025, doi:arXiv.2503.20884
-
[23]
Measure contribution of par- ticipants in federated learning,
G. Wang, C. X. Dang, and Z. Zhou, “Measure contribution of par- ticipants in federated learning,” in2019 IEEE international con- ference on big data (Big Data). IEEE, 2019, pp. 2597–2604, doi:10.1109/BigData47090.2019.9006179
-
[24]
Efficient participant contribution evaluation for horizontal and vertical federated learning,
J. Wang, L. Zhang, A. Li, X. You, and H. Cheng, “Efficient participant contribution evaluation for horizontal and vertical federated learning,” in 2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 2022, pp. 911–923, doi:10.1109/ICDE53745.2022.00073
-
[25]
L. S. Shapley, “A value for n-person games,” 1953. [Online]. Available: https://www.torrossa.com/en/resources/an/5641636#page=87
-
[26]
J. Zhao, X. Zhu, J. Wang, and J. Xiao, “Efficient client con- tribution evaluation for horizontal federated learning,” inICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 3060–3064, doi:10.1109/ICASSP39728.2021.9413377
-
[27]
Gtg-shapley: Efficient and accurate participant contribution evaluation in federated learning,
Z. Liu, Y . Chen, H. Yu, Y . Liu, and L. Cui, “Gtg-shapley: Efficient and accurate participant contribution evaluation in federated learning,” ACM Transactions on intelligent Systems and Technology (TIST), vol. 13, no. 4, pp. 1–21, 2022, doi:10.1145/3501811
-
[28]
Fedcon: Scalable and efficient federated learning via contribution-based aggregation,
W. Gao, G. Xu, and X. Meng, “Fedcon: Scalable and efficient federated learning via contribution-based aggregation,”Electronics, vol. 14, no. 5, p. 1024, 2025, doi:10.3390/electronics14051024
-
[29]
Chg shapley: Efficient data valuation and selection towards trustworthy machine learning,
H. Cai, “Chg shapley: Efficient data valuation and selection towards trustworthy machine learning,”arXiv preprint arXiv:2406.11730, 2024, doi:10.48550/arXiv.2406.11730
-
[30]
Fedcos: A scene-adaptive enhancement for federated learning,
H. Zhang, T. Wu, S. Cheng, and J. Liu, “Fedcos: A scene-adaptive enhancement for federated learning,”IEEE Internet of Things Journal, vol. 10, no. 5, pp. 4545–4556, 2022, doi:10.1109/JIOT.2022.3218315
-
[31]
Layer-wise contribution evaluation for incentivizing personalization in federated learning,
X. Zhang, M. Yao, Q. Guo, S. Qi, Y . Han, Y . Yang, Y . Qi, and Y . Qiao, “Layer-wise contribution evaluation for incentivizing personalization in federated learning,” inICASSP 2026-2026 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2026, pp. 3931–3935, doi:10.1109/ICASSP55912.2026.11460410
-
[32]
Zeno: Distributed stochastic gradient descent with suspicion-based fault-tolerance,
C. Xie, S. Koyejo, and I. Gupta, “Zeno: Distributed stochastic gradient descent with suspicion-based fault-tolerance,” inInternational conference on machine learning. PMLR, 2019, pp. 6893–6901. [Online]. Available: https://proceedings.mlr.press/v97/xie19b.html
2019
-
[33]
Redefining contributions: Shapley-driven federated learning,
N. Tastan, S. Fares, T. Aremu, S. Horvath, and K. Nandakumar, “Redefining contributions: Shapley-driven federated learning,”arXiv preprint arXiv:2406.00569, 2024, doi:10.48550/arXiv.2406.00569
-
[34]
P. A. Apell ´aniz, J. Parras, and S. Zazo, “Improving synthetic data generation through federated learning in scarce and heterogeneous data scenarios,”Big Data and Cognitive Computing, vol. 9, no. 2, p. 18, 2025, doi:10.3390/bdcc9020018
-
[35]
Fedeach: Federated learning with evaluator-based incentive mechanism for human activity recognition,
H. W. Lim, S. Y . Tanjung, I. Iwan, B. N. Yahya, and S.-L. Lee, “Fedeach: Federated learning with evaluator-based incentive mechanism for human activity recognition,”Sensors, vol. 25, no. 12, p. 3687, 2025, doi:10.3390/s25123687
-
[36]
Coba: Collusive backdoor attacks with opti- mized trigger to federated learning,
X. Lyu, Y . Han, W. Wang, J. Liu, B. Wang, K. Chen, Y . Li, J. Liu, and X. Zhang, “Coba: Collusive backdoor attacks with opti- mized trigger to federated learning,”IEEE Transactions on Depend- able and Secure Computing, vol. 22, no. 2, pp. 1506–1518, 2024, doi:10.1109/TDSC.2024.3445637
-
[37]
Data shapley: Equitable valuation of data for machine learning,
A. Ghorbani and J. Zou, “Data shapley: Equitable valuation of data for machine learning,” inInternational conference on machine learning. PMLR, 2019, pp. 2242–2251. [Online]. Available: https://proceedings.mlr.press/v97/ghorbani19c.html Guanming Cheis currently pursuing a B.S. degree in information security with the Software College, Northeastern Universi...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.