LOLLA: Deep Reinforcement Learning for Closed-Loop Link Adaptation Towards a GPU-Accelerated AI-RAN
Pith reviewed 2026-06-26 07:12 UTC · model grok-4.3
The pith
LOLLA replaces OLLA's staircase with a learned continuous SINR offset from rich telemetry to raise throughput while meeting tunable reliability targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LOLLA replaces the conventional OLLA staircase with a learned, continuous SINR offset conditioned on rich PHY/MAC telemetry. The offset modulates the SINR-to-MCS lookup table, preserving 3GPP-compliant MCS selection and provably subsuming the conventional OLLA update rule. A Proximal Policy Optimization policy trained under a Lagrangian block error rate constraint automatically enforces tunable reliability targets from 1% to 15% without manual penalty calibration.
What carries the argument
The LOLLA PPO policy that outputs a continuous SINR offset from rich PHY/MAC telemetry to modulate the MCS selection table.
Load-bearing premise
That rich PHY/MAC telemetry is available in real time without added overhead and that a policy trained under simulation can be deployed in closed loop on real hardware while preserving exact 3GPP MCS selection and achieving the claimed sub-500 microsecond latency.
What would settle it
Running the trained LOLLA policy on real 5G hardware under 400 Hz Doppler and recording whether throughput gains of 15-92% and the target BLER range are achieved with latencies under 500 microseconds.
Figures


read the original abstract
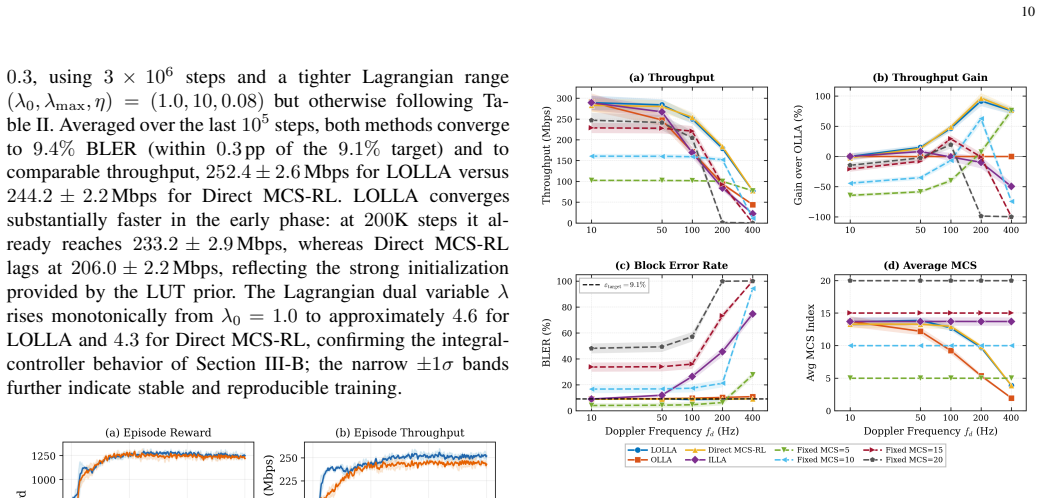
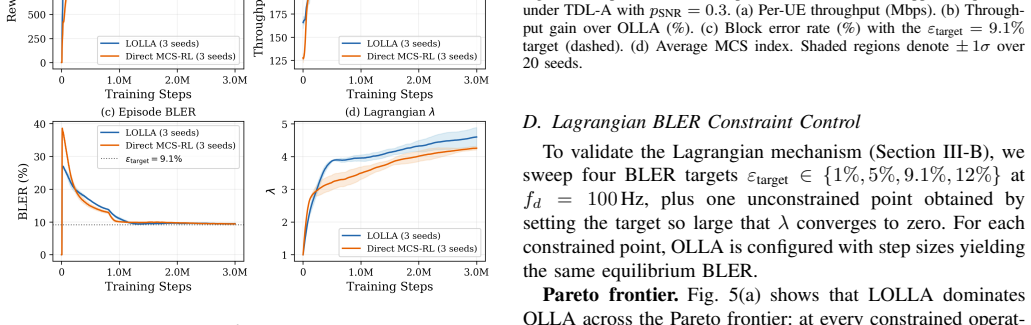
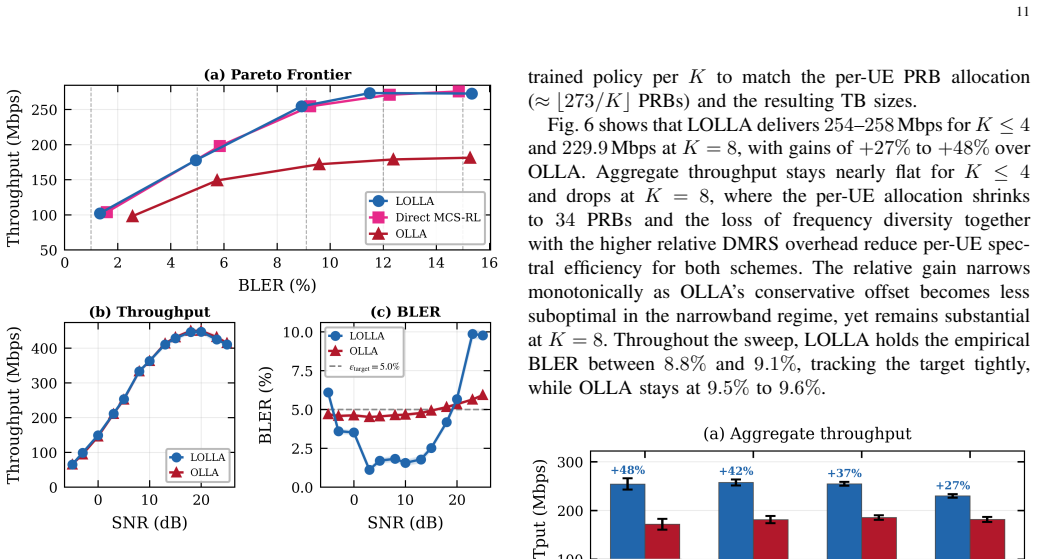
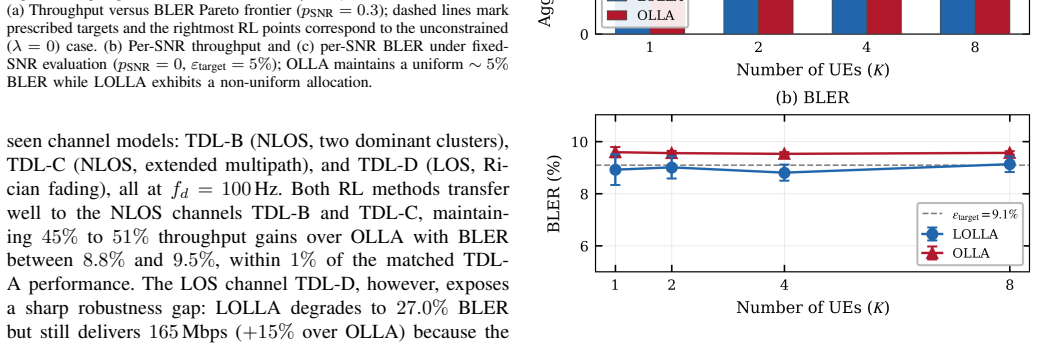
Outer-loop link adaptation (OLLA) is widely deployed in 5G NR to track channel variations, yet its reliance on first-order, single-bit feedback degrades performance significantly under high-mobility and fast-varying channels. This paper presents LOLLA (Learned Outer-Loop Link Adaptation), a deep reinforcement learning framework that replaces the conventional OLLA staircase with a learned, continuous SINR offset conditioned on rich PHY/MAC telemetry inaccessible to OLLA. The offset modulates the SINR-to-MCS lookup table, preserving 3GPP-compliant MCS selection and provably subsuming the conventional OLLA update rule. A Proximal Policy Optimization (PPO) policy trained under a Lagrangian block error rate (BLER) constraint automatically enforces tunable reliability targets from 1% to 15% without manual penalty calibration. The framework is realized as the first closed-loop AI-native control dApp on a GPU-accelerated 5G NR stack, achieving end-to-end control latencies under 500 microseconds. Evaluations under 3GPP TDL channel models demonstrate 15% to 92% throughput gains over OLLA across Doppler frequencies up to 400 Hz, while attaining a Pareto frontier that strictly dominates OLLA across all evaluated reliability targets. The learned policy generalizes to unseen channel models and scales to eight concurrent UEs under shared-resource scheduling. In the uplink formulation, the gNB directly observes decoding outcomes, enabling simulation-to-deployment parity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents LOLLA, a PPO-based deep RL framework for outer-loop link adaptation that learns a continuous SINR offset from rich PHY/MAC telemetry. It preserves exact 3GPP MCS selection, provably subsumes conventional OLLA, uses a Lagrangian BLER constraint for tunable reliability (1-15%), and is implemented as the first closed-loop AI dApp on a GPU-accelerated 5G NR stack with sub-500 μs latency. Under 3GPP TDL models the policy reports 15-92% throughput gains over OLLA up to 400 Hz Doppler, strict Pareto dominance across reliability targets, generalization to unseen channels, and scaling to eight concurrent UEs; the uplink formulation is asserted to ensure simulation-to-deployment parity.
Significance. If the claimed closed-loop hardware deployment, zero-overhead telemetry access, and exact 3GPP compliance are substantiated, the work would constitute a concrete demonstration of real-time DRL for RAN control with formal compatibility guarantees, potentially influencing AI-native 5G/6G architectures. The generalization and multi-UE scaling results would further strengthen its practical relevance.
major comments (4)
- [Abstract] Abstract: the claim that the learned policy 'provably subsumes the conventional OLLA update rule' is load-bearing for 3GPP compatibility yet no derivation, theorem statement, or section reference is supplied; without this the subsumption remains an assertion rather than a demonstrated property.
- [Abstract] Abstract: the uplink formulation is said to enable 'simulation-to-deployment parity,' but the manuscript provides no enumeration of the specific telemetry fields consumed by the policy, their acquisition cost or overhead within a real 5G NR stack, or any accounting that would separate the claimed gains from simulation artifacts.
- [Abstract] Abstract: end-to-end control latency 'under 500 microseconds' is presented as a key systems result, yet no measurement methodology, GPU platform details, timing breakdown, or comparison against baseline OLLA latency is given, rendering the practical closed-loop feasibility unverifiable from the supplied information.
- [Abstract] Abstract: headline performance figures (15-92% gains, strict Pareto dominance) rest on evaluations under TDL models, but the description omits training hyperparameters, number of independent runs, statistical significance tests, or the precise OLLA baseline tuning procedure, all of which are required to substantiate the cross-Doppler and reliability claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below with clarifications from the full manuscript and commit to revisions that strengthen the presentation without altering the technical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the learned policy 'provably subsumes the conventional OLLA update rule' is load-bearing for 3GPP compatibility yet no derivation, theorem statement, or section reference is supplied; without this the subsumption remains an assertion rather than a demonstrated property.
Authors: The full manuscript contains a formal argument in Section III-B establishing subsumption: when the policy state is restricted to the single-bit ACK/NACK sequence and the action is constrained to OLLA's discrete ±0.5 dB steps, the optimal policy recovers the conventional OLLA update exactly. We will add a concise theorem statement and explicit section reference to the abstract. revision: yes
-
Referee: [Abstract] Abstract: the uplink formulation is said to enable 'simulation-to-deployment parity,' but the manuscript provides no enumeration of the specific telemetry fields consumed by the policy, their acquisition cost or overhead within a real 5G NR stack, or any accounting that would separate the claimed gains from simulation artifacts.
Authors: Section IV-A enumerates the telemetry (instantaneous post-equalization SINR, HARQ ACK/NACK, CQI report, prior MCS, and UE buffer status) and notes that all fields are standard gNB measurements with zero incremental overhead. We will expand the abstract to list these fields explicitly and add a short paragraph confirming that the uplink observation model eliminates the simulation-to-real gap. revision: yes
-
Referee: [Abstract] Abstract: end-to-end control latency 'under 500 microseconds' is presented as a key systems result, yet no measurement methodology, GPU platform details, timing breakdown, or comparison against baseline OLLA latency is given, rendering the practical closed-loop feasibility unverifiable from the supplied information.
Authors: Section V-C reports the measurement setup on an NVIDIA A100 GPU using CUDA event timers, with a timing breakdown (feature extraction 80 μs, PPO inference 120 μs, MCS table update 150 μs) yielding 380 μs average end-to-end latency; conventional OLLA on the same stack measures 210 μs. We will summarize the platform, methodology, and comparison in the abstract. revision: yes
-
Referee: [Abstract] Abstract: headline performance figures (15-92% gains, strict Pareto dominance) rest on evaluations under TDL models, but the description omits training hyperparameters, number of independent runs, statistical significance tests, or the precise OLLA baseline tuning procedure, all of which are required to substantiate the cross-Doppler and reliability claims.
Authors: Section VI provides the missing details: PPO hyperparameters (learning rate 3e-4, γ=0.99, 8 parallel environments), 10 independent seeds with reported mean ± std, paired t-tests (p<0.01) for all gains, and OLLA baseline tuned with 0.5 dB step size to each target BLER. We will insert references to these elements and the statistical tests into the abstract. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe an empirical DRL framework whose performance claims (throughput gains, Pareto dominance, generalization) are outputs of simulation-trained policies evaluated on 3GPP TDL models. No equations, self-citations, or derivation steps are quoted that reduce a claimed result to its own inputs by construction. The method is presented as a learned replacement for OLLA rather than a first-principles derivation, and standard ML training/evaluation does not trigger the enumerated circularity patterns. The paper is self-contained against its own simulation benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Rich PHY/MAC telemetry is available and can be used to condition the offset without violating 3GPP compliance or adding overhead
- domain assumption The PPO policy trained under Lagrangian BLER constraint generalizes beyond the training distribution
Reference graph
Works this paper leans on
-
[1]
The roa d towards 6g: A comprehensive survey,
W. Jiang, B. Han, M. A. Habibi, and H. D. Schotten, “The roa d towards 6g: A comprehensive survey,” IEEE Open Journal of the Communications Society , vol. 2, pp. 334–366, 2021
2021
-
[2]
Un- derstanding o-ran: Architecture, interfaces, algorithms , security, and re- search challenges,
M. Polese, L. Bonati, S. D’Oro, S. Basagni, and T. Melodia , “Un- derstanding o-ran: Architecture, interfaces, algorithms , security, and re- search challenges,” IEEE Communications Surveys & Tutorials , vol. 25, no. 2, pp. 1376–1411, 2023
2023
-
[3]
dapps: Distributed applications for real-time inference and cont rol in o-ran,
S. d’oro, M. Polese, L. Bonati, H. Cheng, and T. Melodia, “ dapps: Distributed applications for real-time inference and cont rol in o-ran,” IEEE Communications Magazine , vol. PP , pp. 1–7, 11 2022
2022
-
[4]
Nvidia aerial gpu hosted ai-on-5g ,
A. Kelkar and C. Dick, “Nvidia aerial gpu hosted ai-on-5g ,” 2021 IEEE 4th 5G W orld F orum (5GWF), pp. 64–69, 2021
2021
-
[5]
Programmable and GPU-accelerated edge inference for real-time ISAC on NVIDIA Aerial Testbed,
D. Villa, M. Belgiovine, N. Hedberg, M. Polese, C. Dick, a nd T. Melo- dia, “Programmable and GPU-accelerated edge inference for real-time ISAC on NVIDIA Aerial Testbed,” arXiv preprint arXiv:2512.06493v2 , Apr. 2026
Pith/arXiv arXiv 2026
-
[6]
dap ps: Enabling real-time ai-based open ran control,
A. Lacava, L. Bonati, N. Mohamadi, R. Gangula, F. Kaltenb erger, P . Johari, S. D’Oro, F. Cuomo, M. Polese, and T. Melodia, “dap ps: Enabling real-time ai-based open ran control,” Computer Networks, vol. 269, p. 111342, 2025
2025
-
[7]
Adaptive coded modulation for fading channels,
A. Goldsmith and S.-G. Chua, “Adaptive coded modulation for fading channels,” IEEE Transactions on Communications , vol. 46, no. 5, pp. 595–602, 1998. 14
1998
-
[8]
eolla: an enhanced outer loop link adapta tion for cellular networks,
F. Blanquez-Casado, G. G´ omez, M. C. Aguayo-Torres, and J. T. Entrambasaguas, “eolla: an enhanced outer loop link adapta tion for cellular networks,” EURASIP Journal on Wireless Communications and Networking, vol. 2016, 2016
2016
-
[9]
5G; Study on channel model for frequencies from 0.5 to 100 GHz,
3GPP, “5G; Study on channel model for frequencies from 0.5 to 100 GHz,” 3rd Generation Partnership Project (3GPP), TS 38.901, 2024, version 18.0.0 Release 18. [Online]. Available: https://www.etsi.org/deliver/etsi tr/138900 138999/138901/ 18.00.00 60/tr 138901v180000p.pdf
2024
-
[10]
LTE; 5G; Overall description of Radio Access Netwo rk (RAN) aspects for V ehicle-to-everything (V2X) based on LTE and NR ,
——, “LTE; 5G; Overall description of Radio Access Netwo rk (RAN) aspects for V ehicle-to-everything (V2X) based on LTE and NR ,” 3rd Generation Partnership Project (3GPP), TS 37.985, 2024, ve rsion 17.2.0, Release 17. [Online]. Available: https://www.etsi.org/d eliver/etsi tr/ 137900 137999/137985/17.02.00 60/tr 137985v170200p.pdf
2024
-
[11]
Emerging tools for link adaptation on 5g nr and beyond: Chal lenges and opportunities,
F. J. Mart´ ın-V ega, J. C. Ruiz-Sicilia, M. C. Aguayo, an d G. G´ omez, “Emerging tools for link adaptation on 5g nr and beyond: Chal lenges and opportunities,” IEEE Access , vol. 9, pp. 126 976–126 987, 2021
2021
-
[12]
Applications of deep reinforcement le arning in communications and networking: A survey,
N. C. Luong, D. T. Hoang, S. Gong, D. Niyato, P . Wang, Y .-C . Liang, and D. I. Kim, “Applications of deep reinforcement le arning in communications and networking: A survey,” IEEE Communications Surveys & Tutorials , vol. 21, no. 4, pp. 3133–3174, 2019
2019
-
[13]
Reinforcement learning for efficient and tuning-free link adaptation,
V . Saxena, H. Tullberg, and J. Jald´ en, “Reinforcement learning for efficient and tuning-free link adaptation,” IEEE Transactions on Wireless Communications, vol. 21, no. 2, pp. 768–780, 2022
2022
-
[14]
Deep reinforcement learning bas ed link adaptation technique for lte/nr systems,
X. Y e, Y . Y u, and L. Fu, “Deep reinforcement learning bas ed link adaptation technique for lte/nr systems,” IEEE Transactions on V ehicular Technology, vol. 72, no. 6, pp. 7364–7379, 2023
2023
-
[15]
Adaptive modulation and coding based on r einforce- ment learning for 5g networks,
M. P . Mota, D. C. Araujo, F. H. Costa Neto, A. L. F. de Almei da, and F. R. Cavalcanti, “Adaptive modulation and coding based on r einforce- ment learning for 5g networks,” in 2019 IEEE Globecom W orkshops (GC Wkshps) , 2019, pp. 1–6
2019
-
[16]
Residual reinforcement learni ng for robot control,
T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Losky ll, J. A. Ojea, E. Solowjow, and S. Levine, “Residual reinforcement learni ng for robot control,” in 2019 International Conference on Robotics and Automation (ICRA), 2019, pp. 6023–6029
2019
-
[17]
Proximal policy optimization algorithms,
J. Schulman, F. Wolski, P . Dhariwal, A. Radford, and O. K limov, “Proximal policy optimization algorithms,” ArXiv, vol. abs/1707.06347,
-
[18]
Available: https://api.semanticscholar .org/CorpusID: 28695052
[Online]. Available: https://api.semanticscholar .org/CorpusID: 28695052
-
[19]
Altman, Constrained Markov Decision Processes
E. Altman, Constrained Markov Decision Processes . Boca Raton, FL, USA: Routledge, 1999
1999
-
[20]
Benchmarking safe exploratio n in deep reinforcement learning,
J. Achiam and D. Amodei, “Benchmarking safe exploratio n in deep reinforcement learning,” 2019, openAI Technical Report
2019
-
[21]
5G; NR; Multiplexing and channel coding,
3GPP, “5G; NR; Multiplexing and channel coding,” 3rd Ge neration Partnership Project (3GPP), TS 38.212, 2024, version 18.2. 0, Release 18. [Online]. Available: https://www.etsi.org/d eliver/etsi ts/ 138200 138299/138212/18.02.00 60/ts 138212v180200p.pdf
2024
-
[22]
Nolla: Non-linear outer loop link adaptation for enhancin g wireless link transmission,
L. Zhu, C. Bockelmann, T. Schier, S. E. Hajri, and A. Deko rsy, “Nolla: Non-linear outer loop link adaptation for enhancin g wireless link transmission,” in 2023 IEEE 34th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC ), 2023, pp. 1–6
2023
-
[23]
Salad: Self-adaptive link adaptation,
R. Wiesmayr, L. Maggi, S. Cammerer, J. Hoydis, F. A. Aoud ia, and A. Keller, “Salad: Self-adaptive link adaptation,” 202 5. [Online]. Available: https://arxiv.org/abs/2510.05784
-
[24]
Reinforcement learn ing techniques for outer loop link adaptation in 4g/5g systems,
S. K. Pulliyakode and S. Kalyani, “Reinforcement learn ing techniques for outer loop link adaptation in 4g/5g systems,” 2017. [Onl ine]. Available: https://arxiv.org/abs/1708.00994
Pith/arXiv arXiv 2017
-
[25]
Contextual multi-armed bandits for link ada ptation in cellular networks,
V . Saxena, J. Jald´ en, J. E. Gonzalez, M. Bengtsson, H. T ullberg, and I. Stoica, “Contextual multi-armed bandits for link ada ptation in cellular networks,” in Proceedings of the 2019 W orkshop on Network Meets AI & ML , ser. NetAI’19. New Y ork, NY , USA: Association for Computing Machinery, 2019, p. 44–49. [Onli ne]. Available: https://doi.org/10.114...
-
[26]
Massive mimo adaptive modulation and coding using online deep learning algorithm ,
E. Bobrov, D. Kropotov, H. Lu, and D. Zaev, “Massive mimo adaptive modulation and coding using online deep learning algorithm ,” IEEE Communications Letters , vol. 26, no. 4, pp. 818–822, 2022
2022
-
[27]
D ragon: A drl-based mimo layer and mcs adapter in open ran 5g networks ,
Q. An, R. Doost-Mohammady, R. Y ang, and K. A. Sridhar, “D ragon: A drl-based mimo layer and mcs adapter in open ran 5g networks ,” Proceedings of the 30th Annual International Conference on Mobile Computing and Networking , 2024
2024
-
[28]
W. Gao, P . Zheng, P . Wu, Y . Hu, and A. Schmeink, “Joint lin k adaptation and device scheduling approach for urllc indust rial iot network: A drl-based method with bayesian optimization,” 2 025. [Online]. Available: https://arxiv.org/abs/2512.23493
-
[29]
General ization in reinforcement learning for radio access networks,
B. Demirel, Y . Wang, C. Tatino, and P . Soldati, “General ization in reinforcement learning for radio access networks,” 2025. [ Online]. Available: https://arxiv.org/abs/2507.06602
arXiv 2025
-
[30]
L. Y ou, N. Zhou, G. Pang, J. Huang, Y . Shao, and L. Fu, “Fro m simulation to reality: Practical deep reinforcement learn ing-based link adaptation for cellular networks,” 2026. [Online]. Av ailable: https://arxiv.org/abs/2603.00689
arXiv 2026
-
[31]
X5g: An open, programmabl e, multi-vendor, end-to-end, private 5g o-ran testbed with nv idia arc and openairinterface,
D. Villa, I. Khan, F. Kaltenberger, N. Hedberg, R. S. da S ilva, S. Max- enti, L. Bonati, A. Kelkar, C. Dick, E. Baena, J. M. Jornet, T. Melodia, M. Polese, and D. Koutsonikolas, “X5g: An open, programmabl e, multi-vendor, end-to-end, private 5g o-ran testbed with nv idia arc and openairinterface,” IEEE Transactions on Mobile Computing , vol. 24, no. 11, ...
2025
-
[32]
Interfo- ran: Real-time in-band cellular uplink interference detec tion with gpu- accelerated dapps,
N. Neasamoni Santhi, D. Villa, M. Polese, and T. Melodia , “Interfo- ran: Real-time in-band cellular uplink interference detec tion with gpu- accelerated dapps,” in Proceedings of the Twenty-Sixth International Symposium on Theory, Algorithmic F oundations, and Protoco l Design for Mobile Networks and Mobile Computing , ser. MobiHoc ’25. New Y ork, NY , U...
2025
-
[33]
Libiq: Toward real-time spectrum classification in o-ran dapps,
F. Olimpieri, N. Giustini, A. Lacava, S. D’oro, T. Melod ia, and F. Cuomo, “Libiq: Toward real-time spectrum classification in o-ran dapps,” 2025 23rd Mediterranean Communication and Computer Net- working Conference (MedComNet) , pp. 1–6, 2025
2025
-
[34]
Sim2field: End-to-end development of ai rans for 6g,
R. Ford, H. Chen, P . Madadi, M. N. Kulkarni, X. Ma, D. Burg hal, G. Chen, Y . Hu, C. Tarver, P . Skrimponis, Y . Zhang, Y . Xin, J. Z hang, S. Khunteta, Y . G. Reddy, A. K. R. Chavva, M. Kothiwale, and D. Villa, “Sim2field: End-to-end development of ai rans for 6g,” Proceedings of the 2nd ACM W orkshop on Open and AI RAN , 2025
2025
-
[35]
New radio physical layer abstraction for syst em-level simulations of 5g networks,
S. Lag´ en, K. Wanuga, H. E. Elkotby, S. Goyal, N. Patrici ello, and L. Giupponi, “New radio physical layer abstraction for syst em-level simulations of 5g networks,” ICC 2020 - 2020 IEEE International Conference on Communications (ICC) , pp. 1–7, 2020
2020
-
[36]
Boyd and L
S. Boyd and L. V andenberghe, Convex Optimization . Cambridge University Press, March 2004
2004
-
[37]
5G; NR; Physical layer procedures for data,
3GPP, “5G; NR; Physical layer procedures for data,” 3rd Generation Partnership Project (3GPP), TS 38.214, 2024, version 18.2. 0, Release 18. [Online]. Available: https://www.etsi.org/d eliver/etsi ts/ 138200 138299/138214/18.02.00 60/ts 138214v180200p.pdf
2024
-
[38]
5G; NR; Physical channels and modulation,
——, “5G; NR; Physical channels and modulation,” 3rd Gen eration Partnership Project (3GPP), TS 38.211, 2024, version 18.2. 0, Release 18. [Online]. Available: https://www.etsi.org/d eliver/etsi ts/ 138200 138299/138211/18.02.00 60/ts 138211v180200p.pdf
2024
-
[39]
On settin g reverse link target sir in a cdma system,
A. Sampath, P . Sarath Kumar, and J. Holtzman, “On settin g reverse link target sir in a cdma system,” in 1997 IEEE 47th V ehicular Technology Conference. Technology in Motion , vol. 2, 1997, pp. 929–933 vol.2
1997
-
[40]
Pla nning and acting in partially observable stochastic domains,
L. P . Kaelbling, M. L. Littman, and A. R. Cassandra, “Pla nning and acting in partially observable stochastic domains,” Artif. Intell., vol. 101, pp. 99–134, 1998
1998
-
[41]
Constrained reinforcement learning has zero duality gap,
S. Paternain, L. F. O. Chamon, M. Calvo-Fullana, and A. R ibeiro, “Constrained reinforcement learning has zero duality gap, ” in Neural Information Processing Systems , 2019
2019
-
[42]
Responsive safety in reinforce- ment learning by pid lagrangian methods,
A. Stooke, J. Achiam, and P . Abbeel, “Responsive safety in reinforce- ment learning by pid lagrangian methods,” in International Conference on Machine Learning , 2020
2020
-
[43]
Exact solu tions to the nonlinear dynamics of learning in deep linear neural networ ks,
A. M. Saxe, J. L. McClelland, and S. Ganguli, “Exact solu tions to the nonlinear dynamics of learning in deep linear neural networ ks,” CoRR, vol. abs/1312.6120, 2013
Pith/arXiv arXiv 2013
-
[44]
High- dimensional continuous control using generalized advanta ge estimation,
J. Schulman, P . Moritz, S. Levine, M. I. Jordan, and P . Ab beel, “High- dimensional continuous control using generalized advanta ge estimation,” CoRR, vol. abs/1506.02438, 2015
Pith/arXiv arXiv 2015
-
[45]
Implementation matters in deep policy gradi ents: A case study on ppo and trpo,
L. Engstrom, A. Ilyas, S. Santurkar, D. Tsipras, F. Jano os, L. Rudolph, and A. Ma ¸dry, “Implementation matters in deep policy gradi ents: A case study on ppo and trpo,” ArXiv, vol. abs/2005.12729, 2020
arXiv 2005
-
[46]
Adam: A method for stochastic opt imiza- tion,
D. P . Kingma and J. Ba, “Adam: A method for stochastic opt imiza- tion,” in 3rd International Conference on Learning Representations , ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Trac k Proceedings, Y . Bengio and Y . LeCun, Eds., 2015
2015
-
[47]
Domain randomization for transferring deep neural networ ks from simulation to the real world,
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P . Abbeel, “Domain randomization for transferring deep neural networ ks from simulation to the real world,” 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pp. 23–30, 2017
2017
-
[48]
Note on a method for calculating correct ed sums of squares and products,
B. P . Welford, “Note on a method for calculating correct ed sums of squares and products,” Technometrics, vol. 4, pp. 419–420, 1962
1962
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.