Numerical Approximation for Path-Dependent McKean-Vlasov Control with Non-Asymptotic Error Estimates
Pith reviewed 2026-06-26 03:20 UTC · model grok-4.3
The pith
Euler discretization with piecewise-constant controls approximates path-dependent McKean-Vlasov control with non-asymptotic error O(h^{1/4}).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
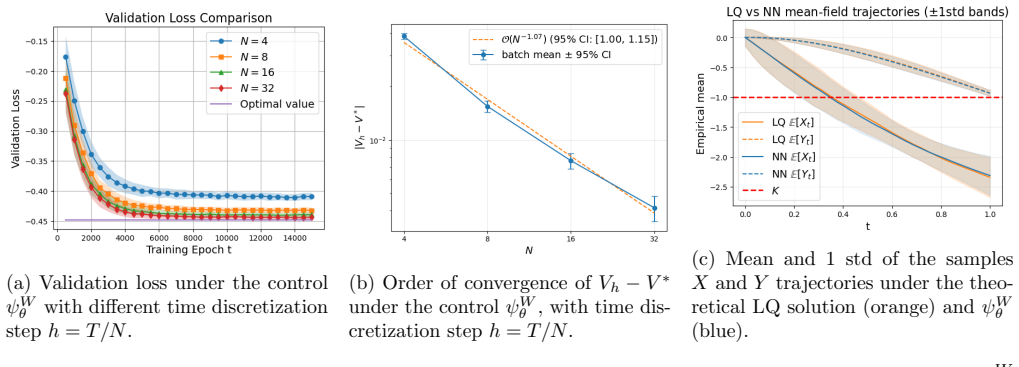
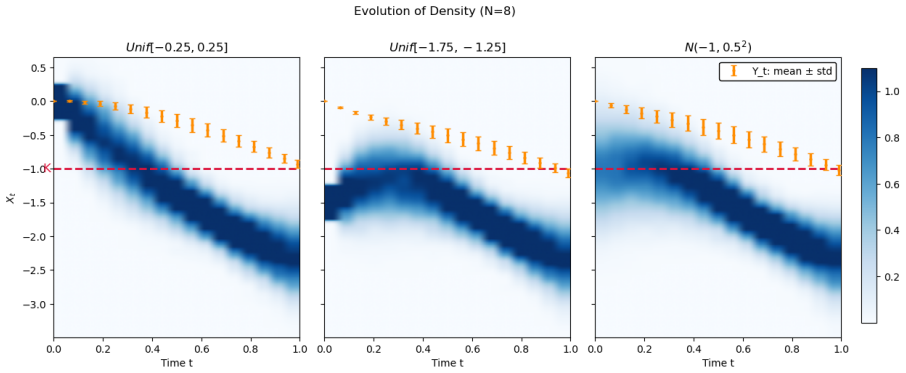
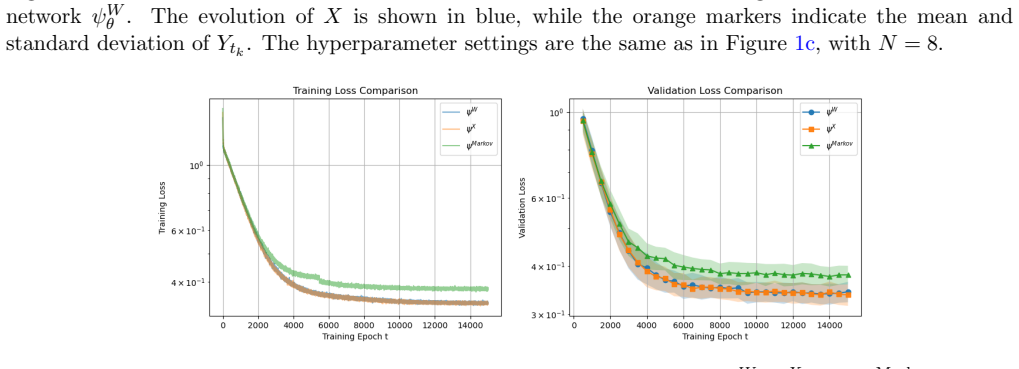
The paper proves that an Euler discretization scheme with piecewise-constant controls achieves a non-asymptotic error of O(h^{1/4}) for path-dependent McKean-Vlasov control under open-loop controls. It establishes a discrete dynamic programming principle and proves value equivalence between open-loop and history-dependent feedback controls. An interacting particle system approximates the continuous-time value, yielding an overall error bound of O(h^{1/4}) + O(M^{-γ}) for M particles with explicitly given γ > 0. A fully implementable neural-network policy-gradient method using pathwise features is proposed and tested on a path-dependent linear-quadratic benchmark.
What carries the argument
Euler discretization scheme with piecewise-constant controls together with the discrete dynamic programming principle that equates open-loop and feedback values.
If this is right
- Optimization reduces to a smaller filtration thanks to the open-loop/feedback equivalence.
- The particle approximation adds an explicit rate O(M^{-γ}) that can be balanced against the time-step error.
- A neural-network policy-gradient algorithm becomes fully implementable using pathwise features extracted from the Euler scheme.
- Numerical tests on a path-dependent linear-quadratic example confirm practical convergence.
Where Pith is reading between the lines
- The same discretization and particle rates could be tested on mean-field games with common noise to see whether the quarter-power rate persists.
- Extending the discrete DPP to controls that depend on the full empirical measure history would allow direct comparison with closed-loop particle methods.
- The neural-network implementation suggests that similar policy-gradient schemes might work for other path-dependent mean-field problems once the reduced filtration is available.
Load-bearing premise
The coefficients are Lipschitz continuous with suitable growth and a discrete dynamic programming principle holds for the discretized problem.
What would settle it
A concrete path-dependent McKean-Vlasov control problem with Lipschitz coefficients where the observed approximation error exceeds O(h^{1/4}) for small h, or where open-loop and feedback values differ after discretization.
Figures
read the original abstract
Path-dependent McKean--Vlasov (MKV) control models large interacting populations with history-dependent dynamics and costs. This paper develops a unified approximation-and-learning framework for continuous time path-dependent MKV problem under open-loop controls. First, an Euler discretization scheme with piecewise-constant controls is shown to achieve a non-asymptotic error of $O(h^{1/4})$. Second, we establish a discrete dynamic programming principle and prove value equivalence between open-loop and history-dependent feedback controls, enabling optimization on a reduced filtration. Third, an interacting particle system is introduced to approximate the continuous-time value, yielding an overall error bound of $O(h^{1/4}) + O(M^{-\gamma})$ for $M$ particles and an explicitly given $\gamma > 0$. Finally, we propose a fully implementable neural-network policy-gradient method using pathwise features. Numerical experiments, including a path-dependent linear-quadratic benchmark, demonstrate the effectiveness of the algorithm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a unified approximation framework for continuous-time path-dependent McKean-Vlasov control under open-loop controls. It shows that an Euler scheme with piecewise-constant controls achieves a non-asymptotic error bound of O(h^{1/4}), establishes a discrete dynamic programming principle proving value equivalence between open-loop and history-dependent feedback controls, introduces an interacting particle system yielding an overall error of O(h^{1/4}) + O(M^{-γ}) with explicit γ > 0, and proposes a neural-network policy-gradient algorithm using pathwise features, with numerical validation on a path-dependent linear-quadratic benchmark.
Significance. If the stated error estimates and equivalence results hold under the assumed Lipschitz/growth conditions, the work supplies rigorous non-asymptotic guarantees for a class of history-dependent mean-field control problems that are otherwise intractable. The explicit rates, reduction via the discrete DPP to a lower-dimensional filtration, and fully implementable learning procedure constitute a concrete advance for both theory and computation in path-dependent MKV control.
minor comments (2)
- [Abstract] The abstract states that γ is 'explicitly given' yet does not display its dependence on the Lipschitz constants or dimension; adding the precise expression (or a reference to the theorem that produces it) would improve readability.
- The numerical section would benefit from a brief statement of the network architecture (depth, width, activation) and the precise pathwise features used, to allow direct reproduction of the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work on the unified approximation framework for path-dependent McKean-Vlasov control and for recommending minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper establishes error bounds for Euler discretization (O(h^{1/4})) and particle approximation (O(M^{-γ})) of path-dependent McKean-Vlasov control via a discrete dynamic programming principle under explicit Lipschitz/growth assumptions on coefficients, followed by standard convergence analysis. These steps rely on classical stochastic control techniques and propagation-of-chaos results rather than any fitted parameters, self-definitional equations, or load-bearing self-citations that reduce the claimed rates to the inputs by construction. The value equivalence between open-loop and feedback controls is proved from the DPP under the stated regularity, with no renaming of known results or ansatz smuggling. The framework is externally falsifiable via the explicit γ and benchmark numerics, making the central claims independent of the result itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The drift, diffusion, and cost coefficients satisfy Lipschitz continuity and linear growth conditions sufficient for well-posedness of the path-dependent MKV dynamics.
Reference graph
Works this paper leans on
-
[1]
The Annals of Applied Probability , number =
Jean-Fran. The Annals of Applied Probability , number =. 2019 , doi =
2019
-
[2]
Stochastic Differential Equations (Lecture Series in Differential Equations, Session 7, Catholic Univ., 1967) , pages=
Propagation of chaos for a class of non-linear parabolic equations , author=. Stochastic Differential Equations (Lecture Series in Differential Equations, Session 7, Catholic Univ., 1967) , pages=
1967
-
[3]
Large population stochastic dynamic games: closed-loop
Huang, Minyi and Malham. Large population stochastic dynamic games: closed-loop. Communications in Information & Systems , volume=
-
[4]
arXiv preprint arXiv:2309.04317 , year=
Actor critic learning algorithms for mean-field control with moment neural networks , author=. arXiv preprint arXiv:2309.04317 , year=
-
[5]
ESAIM: Control, Optimisation and Calculus of Variations , volume=
Bellman equation and viscosity solutions for mean-field stochastic control problem , author=. ESAIM: Control, Optimisation and Calculus of Variations , volume=. 2018 , publisher=
2018
-
[6]
Discrete time
Pham, Huy. Discrete time. Applied Mathematics & Optimization , volume=. 2016 , publisher=
2016
-
[7]
Probabilistic Theory of Mean Field Games with Applications
Carmona, Ren. Probabilistic Theory of Mean Field Games with Applications. 2018 , publisher=
2018
-
[8]
Forward-backward stochastic differential equations and controlled
Carmona, Ren. Forward-backward stochastic differential equations and controlled. The Annals of Probability , volume=
-
[9]
Japanese Journal of Mathematics , volume=
Mean field games , author=. Japanese Journal of Mathematics , volume=
-
[10]
2013 , publisher=
Mean Field Games and Mean Field Type Control Theory , author=. 2013 , publisher=
2013
-
[11]
SIAM Journal on Control and Optimization , volume=
Linear-quadratic optimal control problems for mean-field stochastic differential equations , author=. SIAM Journal on Control and Optimization , volume=
-
[12]
Ecole d'
Topics in propagation of chaos , author=. Ecole d'. 1991 , publisher=
1991
-
[13]
Proceedings of the National Academy of Sciences , volume=
Solving high-dimensional partial differential equations using deep learning , author=. Proceedings of the National Academy of Sciences , volume=
-
[14]
Communications in Mathematics and Statistics , volume=
Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations , author=. Communications in Mathematics and Statistics , volume=
-
[15]
arXiv preprint arXiv:2503.17869 , year=
Learning algorithms for mean field optimal control , author=. arXiv preprint arXiv:2503.17869 , year=
-
[16]
arXiv preprint arXiv:2509.00904 , year=
Convergence Rates of Time Discretization in Extended Mean Field Control , author=. arXiv preprint arXiv:2509.00904 , year=
-
[17]
Electronic Communications of Probability , volume =
Improved order 1/4 convergence for piecewise constant policy approximation of stochastic control problems , author=. Electronic Communications of Probability , volume =
-
[18]
Approximating value functions for controlled degenerate diffusion processes by using piece-wise constant policies , journal =
Krylov, N , year=. Approximating value functions for controlled degenerate diffusion processes by using piece-wise constant policies , journal =
-
[19]
Optimal control of path-dependent
Cosso, Andrea and Gozzi, Fausto and Kharroubi, Idris and Pham, Huy. Optimal control of path-dependent. The Annals of Applied Probability , volume=. 2023 , publisher=
2023
-
[20]
Mathematics and Computers in Simulation , volume=
A discrete stochastic Gronwall lemma , author=. Mathematics and Computers in Simulation , volume=. 2018 , publisher=
2018
-
[21]
Probability and Stochastic Modelling
Stochastic optimal control in infinite dimension , author=. Probability and Stochastic Modelling. Springer , year=
-
[22]
2008 , publisher=
Optimal transport: old and new , author=. 2008 , publisher=
2008
-
[23]
On the rate of convergence in
Fournier, Nicolas and Guillin, Arnaud , journal=. On the rate of convergence in. 2015 , publisher=
2015
-
[24]
Zero-sum stochastic differential games of generalized
Cosso, Andrea and Pham, Huy. Zero-sum stochastic differential games of generalized. Journal de Math. 2019 , publisher=
2019
-
[25]
arXiv preprint arXiv:2503.20510 , year=
Extended mean field control: a finite-dimensional numerical approximation , author=. arXiv preprint arXiv:2503.20510 , year=
-
[26]
1996 , publisher=
Stochastic optimal control: the discrete-time case , author=. 1996 , publisher=
1996
-
[27]
Mean-field neural networks-based algorithms for
Pham, Huy. Mean-field neural networks-based algorithms for. arXiv preprint arXiv:2212.11518 , year=
-
[28]
2002 , isbn =
Olav Kallenberg , title =. 2002 , isbn =
2002
-
[29]
2017 , publisher=
Random measures, theory and applications , author=. 2017 , publisher=
2017
-
[30]
A. F. Filippov , title =. SIAM Journal on Control , year =
-
[31]
Computers & Mathematics with Applications , volume =
Olivier Bokanowski and Nidhal Gammoudi and Hasnaa Zidani , title =. Computers & Mathematics with Applications , volume =. 2022 , doi =
2022
-
[32]
2005 , publisher =
Martingale Methods in Financial Modelling , author =. 2005 , publisher =
2005
-
[33]
1998 , publisher =
Methods of Mathematical Finance , author =. 1998 , publisher =
1998
-
[34]
Journal of Risk , volume =
Optimal execution of portfolio transactions , author =. Journal of Risk , volume =
-
[35]
1993 , publisher =
Introduction to Functional Differential Equations , author =. 1993 , publisher =
1993
-
[36]
Theory of Optimal Search , author =
-
[37]
2008 , publisher =
Mathematical Epidemiology , editor =. 2008 , publisher =
2008
-
[38]
Compactification methods in the control of degenerate diffusions:
El Karoui, Nicole and Du' H. Compactification methods in the control of degenerate diffusions:. Stochastics , issn =. 1987 , language =. doi:10.1080/17442508708833443 , keywords =
-
[39]
Journal of Scientific Computing , volume=
Germain, Maximilien and Lauri. Journal of Scientific Computing , volume=. 2022 , publisher=
2022
-
[40]
Numerical resolution of
Germain, Maximilien and Mikael, Joseph and Warin, Xavier , journal=. Numerical resolution of. 2022 , publisher=
2022
-
[41]
Learning high-dimensional
Han, Jiequn and Hu, Ruimeng and Long, Jihao , journal=. Learning high-dimensional. 2024 , publisher=
2024
-
[42]
arXiv preprint arXiv:2306.04788 , year=
Deep learning for population-dependent controls in mean field control problems with common noise , author=. arXiv preprint arXiv:2306.04788 , year=
-
[43]
A fast iterative
Reisinger, Christoph and Stockinger, Wolfgang and Zhang, Yufei , journal=. A fast iterative. 2024 , publisher=
2024
-
[44]
Dayanikli and M
G. Dayanikli and M. Lauri. Deep Learning for Population-Dependent Controls in Mean Field Control Problems with Common Noise , booktitle =
-
[45]
Frontiers in Applied Mathematics and Statistics , volume=
Deep learning methods for mean field control problems with delay , author=. Frontiers in Applied Mathematics and Statistics , volume=. 2020 , publisher=
2020
-
[46]
The Annals of Applied Probability , volume=
CONVERGENCE ANALYSIS OF MACHINE LEARNING ALGORITHMS FOR THE NUMERICAL SOLUTION OF MEAN FIELD CONTROL AND GAMES , author=. The Annals of Applied Probability , volume=. 2022 , publisher=
2022
-
[47]
Journal of Machine Learning Research , volume=
Actor-critic learning for mean-field control in continuous time , author=. Journal of Machine Learning Research , volume=
-
[48]
arXiv preprint arXiv:2601.11217 , year=
Model-free policy gradient for discrete-time mean-field control , author=. arXiv preprint arXiv:2601.11217 , year=
-
[49]
arXiv preprint arXiv:2107.04568 , volume=
Deep learning for mean field games and mean field control with applications to finance , author=. arXiv preprint arXiv:2107.04568 , volume=
-
[50]
Electronic Journal of Probability , volume=
Extended mean field control problem: a propagation of chaos result , author=. Electronic Journal of Probability , volume=. 2022 , publisher=
2022
-
[51]
Communications in Mathematical Sciences , volume=
Mean field games and systemic risk , author=. Communications in Mathematical Sciences , volume=. 2015 , doi=
2015
-
[52]
SIAM Journal on Applied Mathematics , volume=
Controlling propagation of epidemics via mean-field control , author=. SIAM Journal on Applied Mathematics , volume=. 2021 , doi=
2021
-
[53]
Bioinspiration & Biomimetics , volume=
Mean-field models in swarm robotics: a survey , author=. Bioinspiration & Biomimetics , volume=. 2020 , doi=
2020
-
[54]
Contributions to Partial Differential Equations and Applications , series=
Mean field games for modeling crowd motion , author=. Contributions to Partial Differential Equations and Applications , series=. 2019 , doi=
2019
-
[55]
ESAIM: Control, Optimisation and Calculus of Variations , volume=
Nash equilibria for a model of traffic flow with several groups of drivers , author=. ESAIM: Control, Optimisation and Calculus of Variations , volume=. 2012 , doi=
2012
-
[56]
Quantitative Finance , volume=
Volatility is rough , author=. Quantitative Finance , volume=. 2018 , doi=
2018
-
[57]
Quantitative Finance , volume=
Deep hedging , author=. Quantitative Finance , volume=. 2019 , doi=
2019
-
[58]
Management Science , volume=
Path-dependent options: Extending the Monte Carlo simulation approach , author=. Management Science , volume=. 1997 , publisher=
1997
-
[59]
Vecer, Jan and Xu, Mingxin , journal=. Pricing. 2003 , publisher=
2003
-
[60]
The Journal of Finance , volume=
Path dependent options: The case of lookback options , author=. The Journal of Finance , volume=. 1991 , publisher=
1991
-
[61]
Mean-field controls with
Gu, Haotian and Guo, Xin and Wei, Xiaoli and Xu, Renyuan , journal=. Mean-field controls with. 2021 , publisher=
2021
-
[62]
arXiv preprint arXiv:2605.10313 , year=
Signature Approach for Contextual Bandits with Nonlinear and Path-dependent Rewards , author=. arXiv preprint arXiv:2605.10313 , year=
-
[63]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Transportation marketplace rate forecast using signature transform , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[64]
Itô’s formula for flows of measures on semimartingales , journal =. 2023 , issn =. doi:https://doi.org/10.1016/j.spa.2023.02.004 , url =
-
[65]
2009 , publisher=
Stochastic optimal control problems for pension funds management , author=. 2009 , publisher=
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.