Decoupled Guidance: Disentangling Subject and Context Pathways in Text-to-Image Personalization
Pith reviewed 2026-07-03 21:29 UTC · model grok-4.3
The pith
Routing subject identity and scene context through separate guidance streams reduces their competition in text-to-image personalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
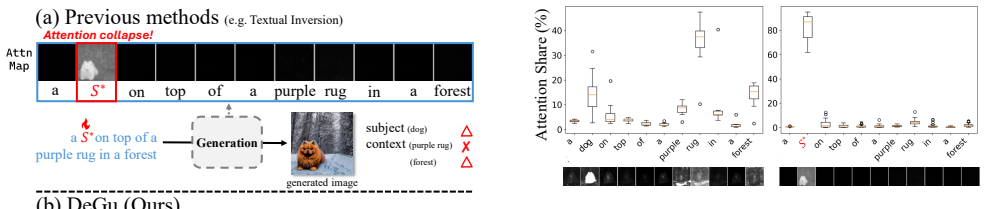
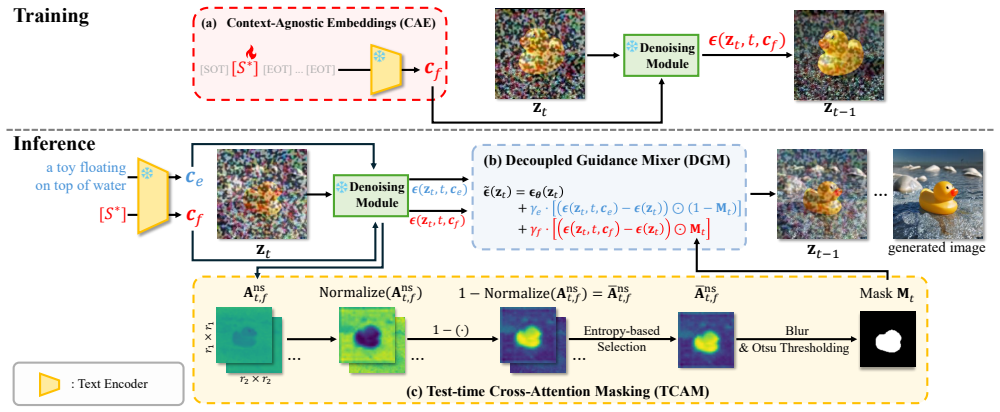
Conditioning entanglement occurs when subject identity and scene context are encoded through the same pathway, forcing them to compete for attention-map resources and producing a fidelity-editability trade-off. Replacing the target subject token with a generic token shifts attention allocation and alters context adherence, confirming the causal link. Decoupled Guidance counters this by maintaining two independent guidance streams and applying a spatial mixing mechanism that lets each stream operate only inside its relevant region.
What carries the argument
Decoupled Guidance (DeGu) with two independent guidance streams and a spatial mixing mechanism that fuses them without cross-region interference.
If this is right
- Personalization performance improves consistently across existing methods without backbone modifications.
- Users gain inference-time control to adjust the fidelity-editability balance for each generation.
- The approach extends to flow-matching Diffusion Transformers as well as standard diffusion backbones.
- Attention resources are allocated more efficiently because each stream stays confined to its semantic region.
Where Pith is reading between the lines
- The same separation principle could be tested in other conditional generation settings where multiple signals compete for model capacity.
- Automatic selection of the mixing strength based on prompt content might further reduce manual tuning.
- The method suggests that attention-map diagnostics can serve as a general tool for diagnosing signal interference in generative models.
Load-bearing premise
The fidelity-editability trade-off is caused primarily by the shared conditioning pathway rather than by other model or training factors.
What would settle it
If applying the two-stream guidance produces no measurable gain on standard personalization metrics such as subject fidelity and text alignment, or if the token-replacement test shows no corresponding attention shifts, the entanglement explanation would be falsified.
Figures







read the original abstract
Text-to-image personalization aims to generate a user-provided subject in novel scenes described by text. However, most existing methods encode subject identity (fidelity) and context (editability) through the same conditioning pathway, forcing the two to compete for attention-map resources. We refer to this phenomenon as conditioning entanglement and show that it induces a fidelity-editability trade-off. We further provide causal evidence by replacing the target subject token with a generic subject token, which produces shifts in attention allocation and corresponding changes in context adherence. To this end, we propose Decoupled Guidance (DeGu), a plug-and-play framework that routes subject identity and scene context through two independent guidance streams. We further introduce a spatial mixing mechanism that dynamically fuses these streams, ensuring each operates within its semantically relevant region without interference. Furthermore, DeGu can be readily applied to existing personalization methods without modifying the underlying backbone models, consistently improving the overall personalization performance while enabling inference-time control over the fidelity-editability balance, across diverse methods and backbones, including flow-matching Diffusion Transformers (DiTs).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies conditioning entanglement—where subject identity and scene context share a single conditioning pathway and compete for attention resources—as the root cause of the fidelity-editability trade-off in text-to-image personalization. It supplies causal evidence via a token-replacement experiment (substituting the target subject token with a generic subject token) that produces observable shifts in attention allocation and context adherence. It then introduces Decoupled Guidance (DeGu), a plug-and-play framework that routes subject and context through independent guidance streams, augmented by a spatial mixing mechanism to fuse them without interference. The approach is claimed to improve personalization performance across existing methods and backbones (including flow-matching DiTs) while permitting inference-time control of the fidelity-editability balance, all without modifying the underlying models.
Significance. If the empirical improvements and the causal isolation of entanglement hold under scrutiny, the work would offer a practical, backbone-agnostic advance for a widely studied problem. The plug-and-play design and demonstrated compatibility with DiTs are concrete strengths that could see rapid adoption.
major comments (1)
- [Abstract] Abstract (causal evidence paragraph): the token-replacement test correlates attention reallocation with changes in context adherence but does not establish that shared-pathway entanglement is the dominant driver of the fidelity-editability trade-off, as opposed to other factors such as training-data biases, loss weighting, or non-attention conditioning routes. Because this isolation is load-bearing for the motivation and claimed remedy of DeGu, additional experiments that rule out alternative explanations are required.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (causal evidence paragraph): the token-replacement test correlates attention reallocation with changes in context adherence but does not establish that shared-pathway entanglement is the dominant driver of the fidelity-editability trade-off, as opposed to other factors such as training-data biases, loss weighting, or non-attention conditioning routes. Because this isolation is load-bearing for the motivation and claimed remedy of DeGu, additional experiments that rule out alternative explanations are required.
Authors: The token-replacement experiment performs a controlled intervention: the model, training procedure, loss function, and all tokens except the subject token remain fixed. The only change is replacement of the target subject token with a generic one, which produces measurable shifts in attention maps and context adherence. Because data biases, loss weighting, and non-attention routes are identical in both conditions, the observed differences are attributable to competition within the shared conditioning pathway. We therefore maintain that the experiment supplies causal evidence for the role of entanglement. That said, we agree the abstract language could be more precise. In the revision we will (i) rephrase the abstract to state that the experiment demonstrates the contribution of pathway entanglement rather than claiming it is the sole dominant driver, and (ii) add a short discussion paragraph in Section 3 explicitly noting the controlled nature of the intervention and why alternative factors are held constant. revision: partial
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper's central claim rests on an empirical causal test (token replacement shifting attention and context adherence) plus an architectural proposal for independent guidance streams and spatial mixing. Neither the entanglement diagnosis nor the performance gains reduce by construction to a fitted parameter, self-defined quantity, or self-citation chain; the method introduces new routing and fusion mechanisms whose outputs are not equivalent to the inputs. No load-bearing uniqueness theorem, ansatz smuggling, or renaming of known results appears. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A neural space-time representation for text-to- image personalization.ACM TOG, 42, 2023
Yuval Alaluf, Elad Richardson, Gal Metzer, and Daniel Cohen-Or. A neural space-time representation for text-to- image personalization.ACM TOG, 42, 2023. 2, 3, 4, 6, 7, 8
2023
-
[2]
Break-a-scene: Extracting multiple concepts from a single image
Omri Avrahami, Kfir Aberman, Ohad Fried, Daniel Cohen- Or, and Dani Lischinski. Break-a-scene: Extracting multiple concepts from a single image. InACM SIGGRAPH Asia,
-
[3]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In ICCV, 2021. 6, 4
2021
-
[4]
Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models.ACM TOG, 42, 2023
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models.ACM TOG, 42, 2023. 3
2023
-
[5]
Disenbooth: Identity- preserving disentangled tuning for subject-driven text-to- image generation
Hong Chen, Yipeng Zhang, Simin Wu, Xin Wang, Xuguang Duan, Yuwei Zhou, and Wenwu Zhu. Disenbooth: Identity- preserving disentangled tuning for subject-driven text-to- image generation. InICLR, 2024. 2, 3
2024
-
[6]
Scaling rec- tified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rec- tified flow transformers for high-resolution image synthesis. InICML, 2024. 4
2024
-
[7]
Catastrophic forgetting in connectionist networks.Trends in Cognitive Sciences, 3, 1999
Robert M French. Catastrophic forgetting in connectionist networks.Trends in Cognitive Sciences, 3, 1999. 3
1999
-
[8]
An image is worth one word: Personalizing text-to-image generation using textual inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik, and Daniel Cohen-or. An image is worth one word: Personalizing text-to-image generation using textual inversion. InICLR, 2023. 2, 3, 4, 5, 6, 7, 8
2023
-
[9]
Mix-of-show: Decentralized low- rank adaptation for multi-concept customization of diffusion models
Yuchao Gu, Xintao Wang, Jay Zhangjie Wu, Yujun Shi, Yun- peng Chen, Zihan Fan, Wuyou Xiao, Rui Zhao, Shuning Chang, Weijia Wu, et al. Mix-of-show: Decentralized low- rank adaptation for multi-concept customization of diffusion models. InNeurIPS, 2023. 3
2023
-
[10]
Hybridbooth: Hybrid prompt inversion for efficient subject-driven generation
Shuang Guan, Yichen Ge, Yu-Wing Tai, Jian Yang, Weijian Li, and Min You. Hybridbooth: Hybrid prompt inversion for efficient subject-driven generation. InECCV, 2025. 3
2025
-
[11]
Svdiff: Compact param- eter space for diffusion fine-tuning
Ligong Han, Yinxiao Li, Han Zhang, Peyman Milanfar, Dimitris Metaxas, and Feng Yang. Svdiff: Compact param- eter space for diffusion fine-tuning. InICCV, 2023. 2, 3
2023
-
[12]
Improved noise schedule for diffusion training.ICCV, 2025
Tiankai Hang, Shuyang Gu, Xin Geng, and Baining Guo. Improved noise schedule for diffusion training.ICCV, 2025. 2
2025
-
[13]
Vico: Plug-and-play visual condition for personal- ized text-to-image generation.arXiv preprint, 2023
Shaozhe Hao, Kai Han, Shihao Zhao, and Kwan-Yee K Wong. Vico: Plug-and-play visual condition for personal- ized text-to-image generation.arXiv preprint, 2023. 3
2023
-
[14]
A data perspec- tive on enhanced identity preservation for diffusion person- alization
Xingzhe He, Zhiwen Cao, Nicholas Kolkin, Lantao Yu, Kun Wan, Helge Rhodin, and Ratheesh Kalarot. A data perspec- tive on enhanced identity preservation for diffusion person- alization. InWACV, 2025. 3
2025
-
[15]
Hertz, R
A. Hertz, R. Mokady, J. Tenenbaum, K. Aberman, Y . Pritch, and D. Cohen-Or. Prompt-to-prompt image editing with cross attention control.ICLR, 2023. 3
2023
-
[16]
Training products of experts by minimiz- ing contrastive divergence.Neural Computation, 14, 2002
Geoffrey E Hinton. Training products of experts by minimiz- ing contrastive divergence.Neural Computation, 14, 2002. 5, 1
2002
-
[17]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS Workshop on Deep Generative Models and Downstream Applications, 2021. 3, 5, 1
2021
-
[18]
Denoising diffu- sion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models. InNeurIPS, 2020. 2, 1
2020
-
[19]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InICLR,
-
[20]
Cus- tomized generation reimagined: Fidelity and editability har- monized
Jianyi Jin, Yuxuan Shen, Zhaofeng Fu, and Jian Yang. Cus- tomized generation reimagined: Fidelity and editability har- monized. InECCV, 2025. 2, 3, 4
2025
-
[21]
Directional textual inversion for personalized text-to- image generation.ICLR, 2026
Kunhee Kim, NaHyeon Park, Kibeom Hong, and Hyunjung Shim. Directional textual inversion for personalized text-to- image generation.ICLR, 2026. 6, 7, 4, 9
2026
-
[22]
Overcoming catastrophic forgetting in neu- ral networks.Proceedings of the National Academy of Sci- ences, 114, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska- Barwinska, et al. Overcoming catastrophic forgetting in neu- ral networks.Proceedings of the National Academy of Sci- ences, 114, 2017. 3
2017
-
[23]
Multi-concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. InCVPR, 2023. 2, 3
2023
-
[24]
Blip-diffusion: Pre- trained subject representation for controllable text-to-image generation and editing
Dongxu Li, Junnan Li, and Steven Hoi. Blip-diffusion: Pre- trained subject representation for controllable text-to-image generation and editing. InNeurIPS, 2023. 2, 3
2023
-
[25]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InICML,
-
[26]
Learning without forgetting
Zhizhong Li and Derek Hoiem. Learning without forgetting. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2017. 3
2017
-
[27]
Common diffusion noise schedules and sample steps are flawed.WACV, 2024
Shanchuan Lin, Bingchen Liu, Jiashi Li, and Xiao Yang. Common diffusion noise schedules and sample steps are flawed.WACV, 2024. 2
2024
-
[28]
Flow matching for generative mod- eling.ICLR, 2023
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling.ICLR, 2023. 2
2023
-
[29]
Compositional visual generation with composable diffusion models
Nan Liu, Shuang Li, Yilun Du, Antonio Torralba, and Joshua B Tenenbaum. Compositional visual generation with composable diffusion models. InECCV, 2022. 3, 5, 1, 2
2022
-
[30]
Grounding dino: Marrying dino with grounded pre- training for open-set object detection.arXiv preprint, 2023
Shilong Liu, Zewen Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre- training for open-set object detection.arXiv preprint, 2023. 6, 8, 5
2023
-
[31]
Cones: Concept neurons in diffusion models for customized generation.ICML, 2023
Zhiheng Liu, Ruili Feng, Kai Zhu, Yifei Zhang, Kecheng Zheng, Yu Liu, Deli Zhao, Jingren Zhou, and Yang Cao. Cones: Concept neurons in diffusion models for customized generation.ICML, 2023. 3 14
2023
-
[32]
Customizable image synthesis with multiple subjects
Zhiheng Liu, Yifei Zhang, Yujun Shen, Kecheng Zheng, Kai Zhu, Ruili Feng, Yu Liu, Deli Zhao, Jingren Zhou, and Yang Cao. Customizable image synthesis with multiple subjects. InNeurIPS, 2023. 3
2023
-
[33]
Nichol, P
A. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, and M. Chen. Glide: Towards pho- torealistic image generation and editing with text-guided dif- fusion models.ICML, 2022. 2, 3
2022
-
[34]
Cross initialization for face personaliza- tion of text-to-image models
Lianyu Pang, Jian Yin, Haoran Xie, Qiping Wang, Qing Li, and Xudong Mao. Cross initialization for face personaliza- tion of text-to-image models. InCVPR, 2024. 2, 3
2024
-
[35]
Seediff: Off-the-shelf seeded mask generation from diffusion models
Joon Hyun Park, Kumju Jo, and Sungyong Baik. Seediff: Off-the-shelf seeded mask generation from diffusion models. InAAAI, 2025. 3
2025
-
[36]
SDXL: Improving latent diffusion mod- els for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion mod- els for high-resolution image synthesis. InICLR, 2024. 2, 3, 4
2024
-
[37]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InICML, 2021. 3, 6, 4
2021
-
[38]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.JMLR, 2020. 3
2020
-
[39]
Hierarchical text-conditional image gener- ation with CLIP latents.arXiv preprint, 2022
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with CLIP latents.arXiv preprint, 2022. 2, 3
2022
-
[40]
Sam 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. Sam 2: Segment anything in images and videos. arXiv preprint, 2024. 6, 8, 5
2024
-
[41]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, 2022. 2, 4
2022
-
[42]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InCVPR, 2023. 2, 3, 6, 7, 4, 8
2023
-
[43]
Hyperdreambooth: Hypernetworks for fast personalization of text-to-image models
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Wei Wei, Tingbo Hou, Yael Pritch, Neal Wadhwa, Michael Rubinstein, and Kfir Aberman. Hyperdreambooth: Hypernetworks for fast personalization of text-to-image models. InCVPR, 2024. 3
2024
-
[44]
Photorealistic text-to-image diffusion models with deep lan- guage understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Sali- mans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep lan- guage understanding. InNeurIPS, 2022. 2, 3
2022
-
[45]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InICML, 2015. 2
2015
-
[46]
Denois- ing diffusion implicit models.ICLR, 2021
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models.ICLR, 2021
2021
-
[47]
Score-based generative modeling through stochastic differential equa- tions
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions. InICLR, 2021. 2
2021
-
[48]
Key-locked rank one editing for text-to-image personaliza- tion
Yoad Tewel, Rinon Gal, Gal Chechik, and Yuval Atzmon. Key-locked rank one editing for text-to-image personaliza- tion. InACM SIGGRAPH, 2023. 3
2023
-
[49]
Diffuse, attend, and segment: Unsupervised zero-shot segmentation using stable diffusion
Junjiao Tian, Lavisha Aggarwal, Andrea Colaco, Zsolt Kira, and Mar Gonzalez-Franco. Diffuse, attend, and segment: Unsupervised zero-shot segmentation using stable diffusion. InCVPR, 2024. 3
2024
-
[50]
Concept decomposition for visual exploration and inspiration.ACM Transactions on Graphics, 42, 2023
Yael Vinker, Andrey V oynov, Daniel Cohen-Or, and Ariel Shamir. Concept decomposition for visual exploration and inspiration.ACM Transactions on Graphics, 42, 2023. 3
2023
-
[51]
P+: Extended textual conditioning in text-to- image generation.arXiv preprint, 2023
Andrey V oynov, Qinghao Chu, Daniel Cohen-Or, and Kfir Aberman. P+: Extended textual conditioning in text-to- image generation.arXiv preprint, 2023. 2, 3, 4, 6, 7, 8
2023
-
[52]
Ms-diffusion: Multi-subject zero-shot image per- sonalization with layout guidance
Xierui Wang, Siming Fu, Qihan Huang, Wanggui He, and Hao Jiang. Ms-diffusion: Multi-subject zero-shot image per- sonalization with layout guidance. InICLR, 2025. 2, 3, 6, 7, 4, 9, 13
2025
-
[53]
Elite: Encoding visual con- cepts into textual embeddings for customized text-to-image generation
Yuxiang Wei, Yabo Zhang, Zhilong Ji, Jinfeng Bai, Lei Zhang, and Wangmeng Zuo. Elite: Encoding visual con- cepts into textual embeddings for customized text-to-image generation. InICCV, 2023. 2, 3
2023
-
[54]
Core: Context- regularized text embedding learning for text-to-image per- sonalization
Feize Wu, Yun Pang, Junyi Zhang, Lianyu Pang, Jian Yin, Baoquan Zhao, Qing Li, and Xudong Mao. Core: Context- regularized text embedding learning for text-to-image per- sonalization. InAAAI, 2025. 6, 7, 4, 8
2025
-
[55]
Cusconcept: Cus- tomized visual concept decomposition with diffusion mod- els
Zhi Xu, Shaozhe Hao, and Kai Han. Cusconcept: Cus- tomized visual concept decomposition with diffusion mod- els. InWACV, 2025. 3
2025
-
[56]
Prospect: Prompt spectrum for attribute- aware personalization of diffusion models.ACM Transac- tions on Graphics, 42, 2023
Yuxing Zhang, Wenbo Dong, Fanyi Tang, Nian Huang, Haisu Huang, Changjie Ma, Tong-Yee Lee, Oliver Deussen, and Changhe Xu. Prospect: Prompt spectrum for attribute- aware personalization of diffusion models.ACM Transac- tions on Graphics, 42, 2023. 3
2023
-
[57]
Ssr-encoder: Encoding selective subject representation for subject-driven generation
Yuxuan Zhang, Yiren Song, Jiaming Liu, Rui Wang, Jinpeng Yu, Hao Tang, Huaxia Li, Xu Tang, Yao Hu, Han Pan, et al. Ssr-encoder: Encoding selective subject representation for subject-driven generation. InCVPR, 2024. 2, 3 15
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.