Scaling LLM Knowledge Boundaries via Distribution-Optimized Synthesis
Pith reviewed 2026-06-26 08:24 UTC · model grok-4.3
The pith
An optimal knowledge distribution maximizes LLM knowledge boundary expansion and stays stable across models and scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
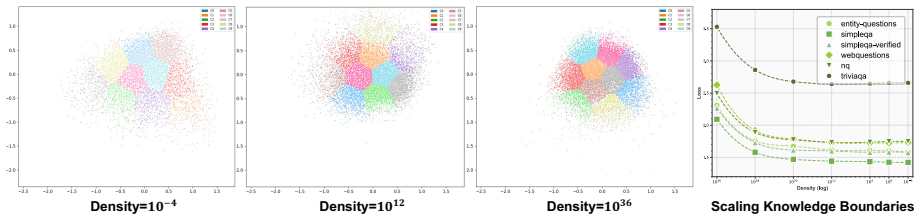
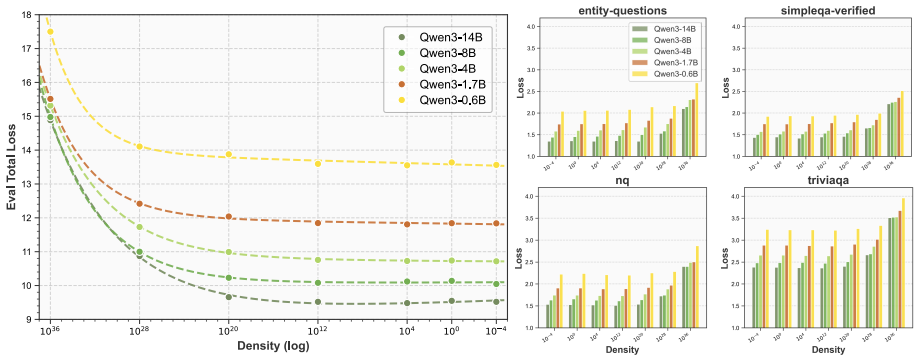
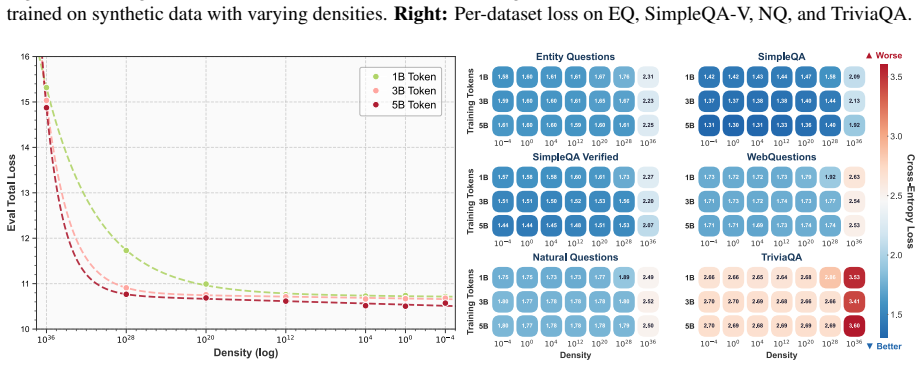
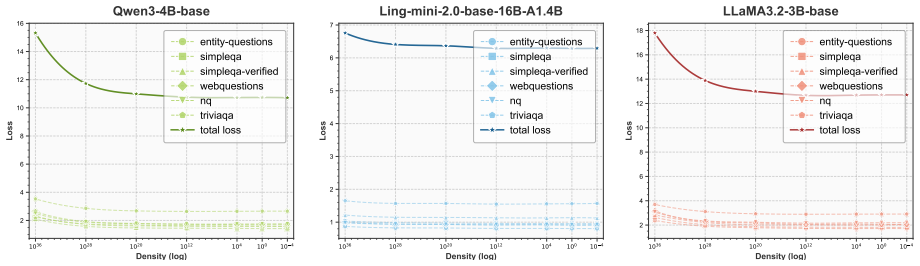
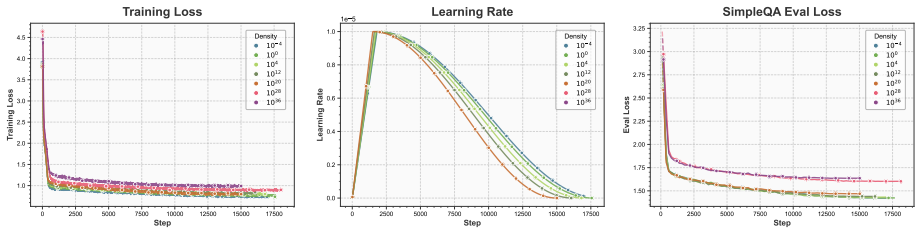
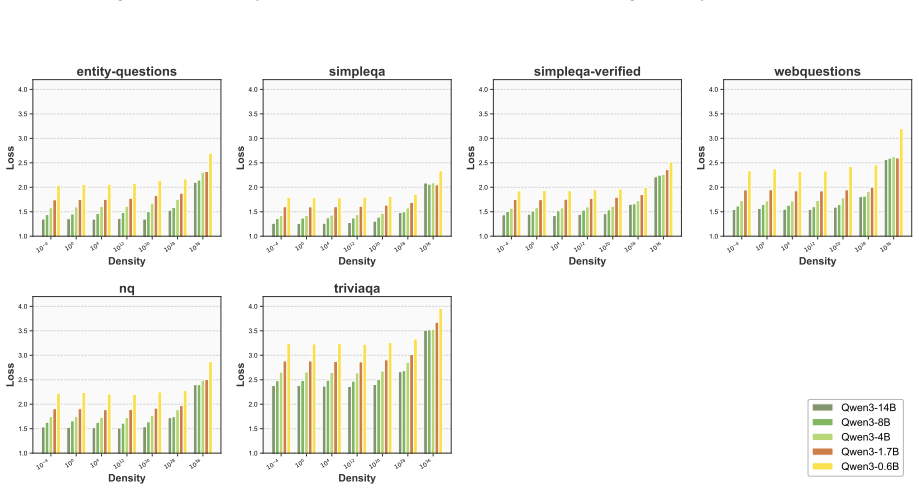
The paper claims that an optimal knowledge distribution exists to maximize knowledge boundary expansion in LLMs. This distribution is stable across backbones and scales. KDoS identifies it through a knowledge density-driven three-stage feedback mechanism for synthesis. When the resulting Wikipedia-based data is used, KDoS outperforms baselines across six knowledge benchmarks for models from 0.6B to 16B parameters and data scales from 1B to 5B tokens.
What carries the argument
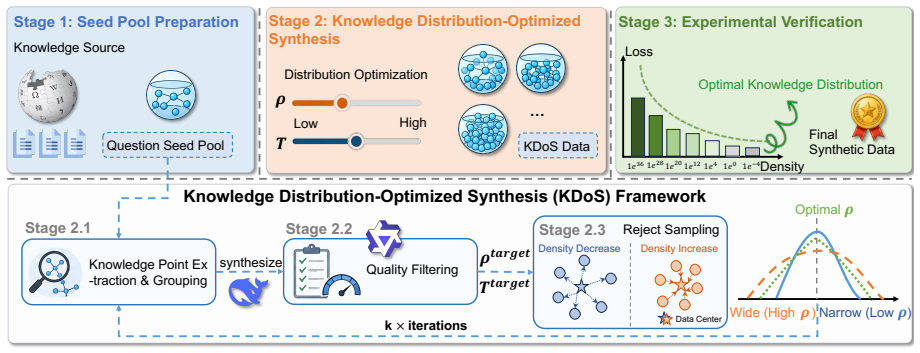
KDoS, a framework that measures knowledge density and applies a three-stage feedback mechanism to steer synthetic data generation toward an optimal distribution across knowledge domains.
If this is right
- Using the optimal distribution produces greater knowledge boundary expansion than preset token counts or fixed data ratios.
- The same distribution remains optimal across different LLM backbones and parameter scales from 0.6B to 16B.
- KDoS yields higher scores than standard synthesis methods on six knowledge benchmarks.
- The optimal distribution holds steady when total synthetic data varies between 1B and 5B tokens.
- Data synthesis should shift from blind generation to generation guided by knowledge density feedback.
Where Pith is reading between the lines
- Models trained on this distribution could reach comparable knowledge levels with fewer total tokens than current fixed-ratio approaches.
- The density feedback idea could be applied to synthetic data drawn from sources other than Wikipedia if a comparable density signal can be computed.
- Benchmarks that emphasize different knowledge domains might produce a different optimal distribution.
- Density-based adjustment could be added as a routine step in any synthetic data pipeline aimed at knowledge expansion.
Load-bearing premise
The knowledge density metric and three-stage feedback loop can locate a distribution that is truly optimal outside the Wikipedia data and the six evaluation benchmarks used in the experiments.
What would settle it
Training several models on different candidate distributions and finding that no single distribution produces the largest consistent gains on a new set of knowledge benchmarks that were not used during the original tests.
Figures

read the original abstract
Knowledge injection via synthetic data is crucial for enhancing Large Language Models (LLMs). However, current synthesis methods simply stop at preset token counts or fixed data ratios, lacking awareness of knowledge distribution. This results in some domains being sparse while others are redundant, limiting LLM knowledge boundaries. We revisit knowledge injection from a distribution perspective and hypothesize that an optimal knowledge distribution exists to maximize knowledge boundary expansion. We propose KDoS (Knowledge Distribution-optimized Synthesis), a framework that introduces knowledge density to drive synthesis through a three-stage feedback mechanism, shifting from blind generation to distribution-optimized synthesis. We construct Wikipedia-based synthetic data with varying knowledge distributions and conduct experiments on models from 0.6B to 16B (Qwen, Ling, LLaMA) and data scales from 1B to 5B tokens. Our key findings are: (1) an optimal knowledge distribution consistently maximizes boundary expansion; (2) this distribution is stable across backbones and scales; (3) KDoS outperforms baselines across six knowledge benchmarks. Our work offers a new perspective and practical framework for synthetic data-driven knowledge injection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an optimal knowledge distribution exists to maximize LLM knowledge boundary expansion during synthetic data injection. It introduces KDoS, which uses a knowledge-density-driven three-stage feedback mechanism to identify this distribution, reports that the distribution is stable across backbones (Qwen, Ling, LLaMA) and scales (0.6B–16B), and shows KDoS outperforming baselines on six knowledge benchmarks using 1B–5B token Wikipedia-derived synthetic data.
Significance. If the claims hold with rigorous validation, the work would shift synthetic data practices from fixed token counts or ratios toward distribution optimization, offering a practical framework for more effective knowledge injection in LLMs. Demonstrating stability across scales and models would strengthen understanding of data composition effects.
major comments (3)
- [Experiments] Experiments section: The optimal distribution is identified empirically from the same set of experiments on Wikipedia-based data used to validate its superiority and stability; this creates a circularity risk where reported optimality may be an artifact of the construction and evaluation loop rather than an independently verifiable property.
- [Experiments] Experiments section: All synthetic data is constructed from Wikipedia (1B–5B tokens) with evaluation limited to six knowledge benchmarks; the stability claim across backbones and scales lacks cross-corpus testing (e.g., scientific papers, code, or books), which is load-bearing for asserting that an optimal distribution exists in general rather than being local to this regime.
- [Results] Results section: Claims of consistent maximization, stability, and outperformance are stated without reported statistical tests, error bars, multiple random seeds, or explicit controls for confounds such as total token volume or synthesis compute, weakening the evidence for the central hypothesis.
minor comments (1)
- [Abstract] Abstract: Findings are summarized at a high level; including brief quantitative deltas or baseline names would improve clarity of the contribution.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment point-by-point below, clarifying our experimental design and committing to revisions that strengthen the evidence and scope of claims without overstating generalizability.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The optimal distribution is identified empirically from the same set of experiments on Wikipedia-based data used to validate its superiority and stability; this creates a circularity risk where reported optimality may be an artifact of the construction and evaluation loop rather than an independently verifiable property.
Authors: We appreciate the concern about potential circularity. The three-stage feedback mechanism identifies the optimal distribution through iterative knowledge-density refinement on performance signals, after which superiority is validated by direct comparison to baselines using the fixed optimal distribution. To address this explicitly, we will revise the Experiments section to delineate the distribution-search phase (using a systematic sweep with intermediate metrics) from the final validation phase, including any use of held-out splits for confirmation. revision: yes
-
Referee: [Experiments] Experiments section: All synthetic data is constructed from Wikipedia (1B–5B tokens) with evaluation limited to six knowledge benchmarks; the stability claim across backbones and scales lacks cross-corpus testing (e.g., scientific papers, code, or books), which is load-bearing for asserting that an optimal distribution exists in general rather than being local to this regime.
Authors: We agree the experiments are Wikipedia-specific and do not claim the particular optimal distribution generalizes to other corpora. The demonstrated stability applies across backbones and scales within the Wikipedia regime, supporting the broader hypothesis that some optimal distribution exists per data source. We will revise the manuscript to explicitly scope all claims to Wikipedia-derived data, add a limitations paragraph discussing corpus dependence, and note cross-corpus validation as important future work. revision: yes
-
Referee: [Results] Results section: Claims of consistent maximization, stability, and outperformance are stated without reported statistical tests, error bars, multiple random seeds, or explicit controls for confounds such as total token volume or synthesis compute, weakening the evidence for the central hypothesis.
Authors: We concur that additional statistical controls would strengthen the results. The revised version will report means and standard deviations across at least three random seeds with error bars, include paired statistical tests (e.g., t-tests) for key comparisons, and explicitly confirm that all conditions are matched on total token volume; synthesis compute differences will be documented as a controlled variable where relevant. revision: yes
Circularity Check
No significant circularity; empirical findings from controlled experiments
full rationale
The paper states a hypothesis that an optimal knowledge distribution exists, introduces KDoS with a knowledge-density three-stage mechanism, constructs Wikipedia-based synthetic data at 1B-5B tokens, runs experiments across Qwen/Ling/LLaMA models (0.6B-16B) and six benchmarks, and reports the observed findings that one distribution maximizes expansion and is stable. These are direct experimental observations within the defined setup rather than any derivation, equation, or fitted parameter that reduces the claims to inputs by construction. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing elements in the provided text. The work is self-contained as an empirical study.
Axiom & Free-Parameter Ledger
invented entities (1)
-
knowledge density
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Llemma: An open language model for mathe- matics.Preprint, arXiv:2310.10631. Zhengyu Chen, Siqi Wang, Teng Xiao, Yudong Wang, Shiqi Chen, Xunliang Cai, Junxian He, and Jingang Wang. 2025a. Revisiting scaling laws for language models: The role of data quality and training strate- gies. InProceedings of the 63rd Annual Meeting of the Association for Computa...
Pith/arXiv arXiv 2025
-
[2]
How to inject knowledge efficiently? knowl- edge infusion scaling law for pre-training large lan- guage models. InProceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Processing, pages 26204–26219. Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When not to trust language models...
Pith/arXiv arXiv 2025
-
[3]
Raoyuan Zhao, Abdullatif Köksal, Ali Modarressi, Michael A
Adept: Continual pretraining via adaptive expansion and dynamic decoupled tuning.arXiv preprint arXiv:2510.10071. Raoyuan Zhao, Abdullatif Köksal, Ali Modarressi, Michael A. Hedderich, and Hinrich Schuetze. 2025. Do we know what LLMs don’t know? a study of consistency in knowledge probing. InFindings of the Association for Computational Linguistics: EMNLP...
arXiv 2025
-
[4]
Llamafactory: Unified efficient fine-tuning of 100+ language models.Preprint, arXiv:2403.13372. A Dataset Statistics We report the statistics of the six knowledge evalua- tion benchmarks used in this work in Tab. 3, includ- ing Web Questions, Natural Questions, TriviaQA, SimpleQA, SimpleQA-Verified, and EntityQues- tions. The “Candidate Answer” column ind...
Pith/arXiv arXiv 2032
-
[5]
There may be one or multiple topic entities
**Extract the Topic Entity/Entities** — the core subject(s) or object(s) the question is about. There may be one or multiple topic entities
-
[6]
**List All Relevant Knowledge Points** — concisely list all knowledge points, facts, con- cepts, or information helpful for answering the question
-
[7]
**Abstract the Logic Form Between Knowl- edge Points** — represent how the knowl- edge points are connected through the reasoning structure or logical flow used to arrive at the an- swer
-
[8]
**Output the Logic Form in Mermaid for- mat** — choose the most appropriate diagram type from the following: - **flowchart** (‘flowchart TD‘ or ‘flowchart LR‘) — for sequential reasoning, decision- making processes, or step-by-step logic - **graph** (‘graph TD‘ or ‘graph LR‘) — for relationship networks, entity connections, or multi-directional reasoning ...
-
[9]
‘json ‘topic_entities’: [‘Entity1’, ‘Entity2’, ‘...’],
**Enable comparison** — your abstrac- tion should allow detection of overlap in Logic Forms across different questions. **Selection Guidelines:** - Use **flowchart** when reasoning follows a clear sequence or involves conditional branches - Use **graph** when showing interconnected relationships or bidirectional reasoning paths - Use **mindmap** when the ...
-
[10]
In which year did Marie Curie win her first Nobel Prize?
**Instance-Based Questions (MANDA- TORY)**: - ALL synthesized questions MUST examine specific, concrete instances - Questions MUST involve particular entities: specific people, events, places, organizations, dates, cases, or other concrete subjects - PROHIBIT abstract conceptual questions or vague generalities - Example ACCEPTABLE: "In which year did Mari...
-
[11]
**Question Differentiation**: - Generated questions MUST differ substantially from source questions in content and presenta- tion - Knowledge points in new questions MUST derive from source knowledge points or their thematic domains - Avoid superficial variations; ensure genuine conceptual recombination
-
[12]
**Question Diversity**: - Explore different aspects, angles, and dimen- sions of the knowledge domain - Prevent structural or thematic homogeneity across generated questions - All questions MUST use Q&A format WITH- OUT multiple-choice options
-
[13]
**Logical Consistency**: - Ensure coherence among question, knowledge points, and answer - **Eliminate mechanical combinations and log- ical contradictions**
-
[14]
**Distractor Integration**: - Include distractor elements derived from source knowledge points or thematic domains - Design distractors to increase question diffi- culty meaningfully
-
[15]
The Jammu and Kashmir State Film Development Corporation is focused on promoting cinema in which Indian union terri- tory?
**Quality Validation** (MANDATORY for each question): Conduct three critical checks before detailed evaluation. Apply STRICT standards for all checks - only flag obvious violations. When uncertain, allow the question to proceed to full evaluation. **Preliminary Checks:** **A. Answer Independence (an- swer_directly_in_question)** - Is the answer explicitly...
1987
-
[16]
Clear, answerable question with correct an- swer (MUST be instance-based, examining spe- cific entities)
-
[17]
Relevant topic entities
-
[18]
3-5 knowledge points (MUST be instance- based)
-
[19]
We design a detailed evaluation prompt to filter out low-quality samples that do not meet our require- ments
Complete Mermaid logic diagram Return your response including: - **Step 1**: Knowledge Point Expansion (ALL knowledge points MUST be instance-based) - **Step 2**: Knowledge Point Combination & Validation (with regeneration if validation fails; abandon specific question synthesis if regenera- tion repeatedly fails) - **Final Output**: JSON array with synth...
-
[20]
The knowledge points (array of strings)
-
[21]
The Jammu and Kashmir State Film Development Corporation is focused on promot- ing cinema in which Indian union territory?
The logic form (Mermaid diagram as string) **PRELIMINARY CHECK:** Conduct three critical checks before detailed evaluation. Apply STRICT standards for all checks - only flag obvious violations. When uncertain, allow the question to proceed to full evaluation. **1. Answer Independence (an- swer_directly_in_question)** Is the answer directly contained in th...
1987
-
[22]
The Massey Ferguson 35 is a tractor model
"The Massey Ferguson 35 is a tractor model."
-
[23]
The Massey Ferguson 35 is equipped with a Perkins 3-cylinder diesel engine
"The Massey Ferguson 35 is equipped with a Perkins 3-cylinder diesel engine."
-
[24]
The Massey Ferguson 35 is known for its global sales success
"The Massey Ferguson 35 is known for its global sales success."
-
[25]
Agriline is a company that provides expert advice, parts, and customer service for Massey Ferguson tractors
"Agriline is a company that provides expert advice, parts, and customer service for Massey Ferguson tractors."
-
[26]
Agriline’s specialization indicates the brand it supports is Massey Ferguson
"Agriline’s specialization indicates the brand it supports is Massey Ferguson." Knowledge Logic Chain: "graph TD A[Question] –> B["Tractor model with Perkins 3-cylinder engine"] B –> C["Perkins 3-cylinder engine is in Massey Ferguson 35"] A –> D["Tractor with global sales success"] D –> E["Massey Ferguson 35 is globally successful"] A –> F["Brand supporte...
1951
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.