Two AI Metrics Diverged: Will it Make All the Difference?
Pith reviewed 2026-07-02 12:27 UTC · model grok-4.3
The pith
The choice of performance metric decides whether frontier AI models keep a growing lead or smaller ones catch up as compute scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
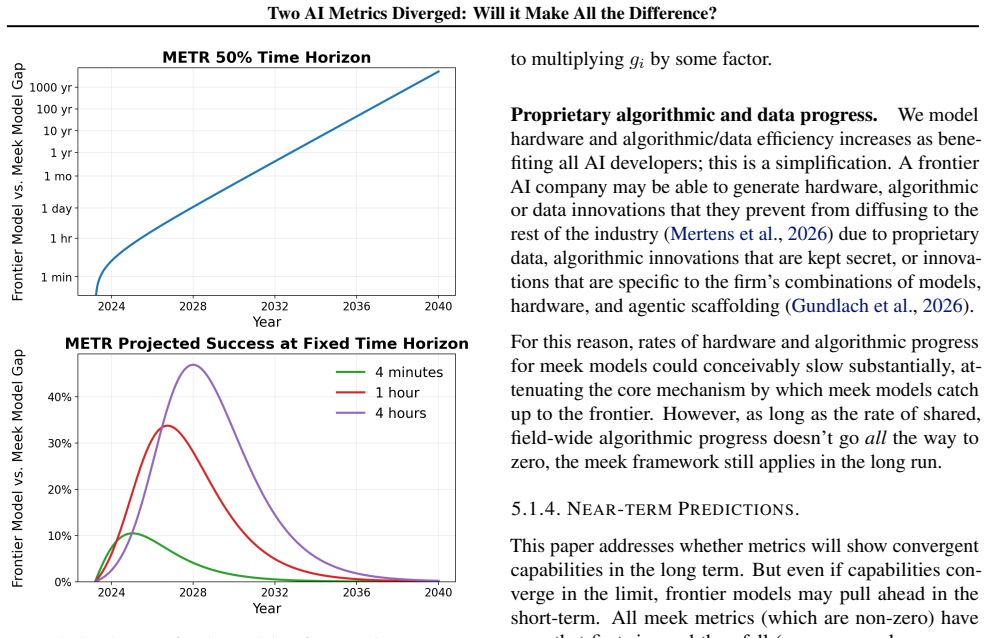
We provide tight mathematical conditions for determining which metrics favor meek models, and show that bounded performance metrics always do. But careful interpretation of performance metrics is essential: we show that many common bounded metrics have closely-related counterpart metrics that are unbounded (and vice versa). Determining the apt metric in a domain is a prerequisite for policy, since bounded and unbounded metrics may suggest opposing policy responses. If a particular capability is unbounded when measured in the terms we care about, frontier-level capability will likely be concentrated in the hands of a few wealthy actors. Conversely, if that capability is instead bounded, front
What carries the argument
Classification of performance metrics into bounded or unbounded categories according to their functional forms with respect to training and inference compute.
If this is right
- If a capability is measured with a bounded metric, frontier-level performance spreads to smaller models with more compute.
- If a capability is measured with an unbounded metric, frontier-level performance remains concentrated among high-compute developers.
- Many standard metrics have direct counterparts that reverse the bounded/unbounded property, so the same capability can yield opposite policy conclusions depending on the chosen measure.
- Policy debates over AI access and concentration must first settle which metric best reflects the valued outcome in each domain.
Where Pith is reading between the lines
- For domains such as software engineering or synthetic biology, the paper implies that the dominant metric will determine whether large-scale compute access remains a decisive advantage.
- The classification could be tested by tracking whether specific bounded metrics approach saturation while their unbounded counterparts keep improving with scale.
- Extending the same functional-form analysis to inference-only scaling or to multi-model ensembles might reveal additional conditions on when meek models gain ground.
- The result suggests that metric selection itself functions as a lever in debates about AI governance and resource allocation.
Load-bearing premise
The functional forms used to classify metrics as bounded or unbounded correctly capture how those metrics behave under real scaling of training and inference compute.
What would settle it
A direct measurement showing that a metric classified as bounded continues to exhibit a widening performance gap between frontier and small-budget models as training compute increases by another order of magnitude.
Figures

read the original abstract
As exponential compute scaling continues, will the capabilities of frontier AI models outstrip what is accessible to developers on a small fixed budget? Or will capabilities converge, with "meek models inheriting the earth"? Building on Gundlach et al. (2025b), we show that the answer depends on how we value and measure AI capabilities. We discuss conventional performance measures and show that, while validation loss shows a shrinking gap, on other metrics frontier models grow their lead forever. Classifying performance metrics by their functional forms in relation to training (and inference) compute, we provide tight mathematical conditions for determining which metrics favor meek models, and show that bounded performance metrics always do. But careful interpretation of performance metrics is essential: we show that many common bounded metrics have closely-related counterpart metrics that are unbounded (and vice versa). Determining the apt metric in a domain is a prerequisite for policy, since bounded and unbounded metrics may suggest opposing policy responses. If a particular capability -- like software engineering, synthetic biology, or rhetorical persuasiveness -- is unbounded when measured in the terms we care about, frontier-level capability will likely be concentrated in the hands of a few wealthy actors. Conversely, if that capability is instead bounded, frontier-level capabilities proliferate through meek models into the hands of the many.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the divergence between frontier and meek AI models under compute scaling depends on the performance metric used. Classifying metrics by their functional forms with respect to training and inference compute, it derives tight mathematical conditions determining which metrics favor meek models and concludes that all bounded metrics do so. It further notes that many common bounded metrics have closely related unbounded counterparts (and vice versa), with implications for policy on whether advanced capabilities concentrate among few actors or proliferate widely.
Significance. If the mathematical classification and derivations hold, the work offers a principled way to evaluate how metric choice affects conclusions about AI capability distribution, which could inform policy debates on concentration vs. democratization of frontier capabilities. The observation that bounded and unbounded counterparts can suggest opposing policy responses is a useful cautionary point, though its impact hinges on whether the functional-form assumptions align with empirical metric behavior.
major comments (2)
- [Abstract] Abstract and classification section: The central claim of 'tight mathematical conditions' and that 'bounded performance metrics always do' favor meek models is asserted without explicit functional forms, derivations, or an exhaustive verification that the classification covers all relevant cases. This leaves the 'always' conclusion uncheckable from the provided text.
- [Abstract] Abstract paragraph on classification by functional forms: The argument assumes that the chosen functional forms (e.g., saturating for bounded vs. power-law or logarithmic for unbounded) correctly describe how metrics such as accuracy, F1, or pass@k behave as compute scales, but these metrics are frequently post-hoc transformations of unbounded quantities (logits, losses, or raw counts). This could change the limiting behavior and undermine the claim that bounded metrics always favor meek models.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the clarity of our mathematical claims. We address each major comment below, providing references to the full manuscript derivations and making targeted revisions for improved checkability and discussion of transformations.
read point-by-point responses
-
Referee: [Abstract] Abstract and classification section: The central claim of 'tight mathematical conditions' and that 'bounded performance metrics always do' favor meek models is asserted without explicit functional forms, derivations, or an exhaustive verification that the classification covers all relevant cases. This leaves the 'always' conclusion uncheckable from the provided text.
Authors: The full manuscript (Section 3 and Appendix A) explicitly defines the functional forms: bounded metrics as saturating functions f(C) o L (finite limit) as compute C o o o, and unbounded as power-law or logarithmic f(C) = a C^b or log(C). We derive the tight conditions showing that for any bounded f, the performance gap between frontier (high C) and meek (fixed C) models converges to zero, while unbounded metrics allow indefinite divergence. The classification covers all standard metrics by their asymptotic behavior. To enhance checkability, we have added an explicit summary table of conditions and proofs to the main text. revision: yes
-
Referee: [Abstract] Abstract paragraph on classification by functional forms: The argument assumes that the chosen functional forms (e.g., saturating for bounded vs. power-law or logarithmic for unbounded) correctly describe how metrics such as accuracy, F1, or pass@k behave as compute scales, but these metrics are frequently post-hoc transformations of unbounded quantities (logits, losses, or raw counts). This could change the limiting behavior and undermine the claim that bounded metrics always favor meek models.
Authors: We agree many bounded metrics (e.g., accuracy from logits) are post-hoc transformations of unbounded base quantities. Our classification, however, is applied to the final evaluated metric, whose boundedness governs the scaling behavior regardless of origin. For example, loss may be unbounded while accuracy saturates, leading to convergence. We have revised the abstract, Section 2, and added a new subsection clarifying this distinction and confirming that the final metric's form determines the meek-model convergence result. revision: partial
Circularity Check
Minor self-citation present but central mathematical classification of metrics by functional form is independent
full rationale
The paper explicitly builds on Gundlach et al. (2025b) for its starting point, and one author overlaps, but the abstract and description present the classification of metrics (bounded vs. unbounded via functional dependence on compute) and the derivation of tight conditions as the paper's own mathematical contribution. No equations or steps are shown reducing the 'bounded metrics always favor meek models' result to a fit, a self-referential definition, or a chain that collapses to the citation alone. The functional-form classification is offered as an analytical tool rather than a post-hoc fit to data, so the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , month = dec, day =
Ord, Toby , title =. 2025 , month = dec, day =
2025
-
[2]
arXiv preprint arXiv:2104.03113 , year=
Scaling Scaling Laws with Board Games , author=. arXiv preprint arXiv:2104.03113 , year=
-
[3]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling , author=. arXiv preprint arXiv:2407.21787 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2507.00004 , year=
A Theory of Inference Compute Scaling: Reasoning through Directed Stochastic Skill Search , author=. arXiv preprint arXiv:2507.00004 , year=
-
[5]
arXiv preprint arXiv:2410.04343 , year=
Inference Scaling for Long-Context Retrieval Augmented Generation , author=. arXiv preprint arXiv:2410.04343 , year=
-
[6]
arXiv preprint arXiv:2502.17578 , year=
How do large language monkeys get their power (laws)? , author=. arXiv preprint arXiv:2502.17578 , year=
-
[7]
Hans Gundlach and Jayson Lynch and Neil Thompson , title =. arXiv:2507.07931 , year =
-
[8]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets , author=. arXiv preprint arXiv:2201.02177 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
and Barnes, Elizabeth and Chan, Lawrence , journal=
Kwa, Thomas and West, Ben and Becker, Joel and Deng, Amy and Garcia, Katharyn and Hasin, Max and Jawhar, Sami and Kinniment, Megan and Rush, Nate and Von Arx, Sydney and Bloom, Ryan and Broadley, Thomas and Du, Haoxing and Goodrich, Brian and Jurkovic, Nikola and Miles, Luke Harold and Nix, Seraphina and Lin, Tao and Painter, Chris and Parikh, Neev and Re...
-
[10]
Forecasting
Whitfill, Parker and Snodin, Ben and Becker, Joel , journal=. Forecasting
-
[11]
and Lyu, Harry and Li, Wensu and Rosenfeld, Jonathan and Anto, Meiri and Fleming, Martin and Thompson, Neil , journal=
Mertens, Matthias and Kuzee, Adam and Harris, Brittany S. and Lyu, Harry and Li, Wensu and Rosenfeld, Jonathan and Anto, Meiri and Fleming, Martin and Thompson, Neil , journal=. Crashing Waves vs. Rising Tides: Preliminary Findings on. 2026 , doi=
2026
-
[12]
arXiv preprint arXiv:2210.00849 , year=
Scaling Laws for a Multi-Agent Reinforcement Learning Model , author=. arXiv preprint arXiv:2210.00849 , year=
-
[13]
arXiv preprint arXiv:2301.13442 , year=
Scaling Laws for Single-Agent Reinforcement Learning , author=. arXiv preprint arXiv:2301.13442 , year=
-
[14]
Dota 2 with Large Scale Deep Reinforcement Learning
Dota 2 with Large Scale Deep Reinforcement Learning , author=. arXiv preprint arXiv:1912.06680 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[15]
arXiv preprint arXiv:2401.04757 , year=
How predictable is language model benchmark performance? , author=. arXiv preprint arXiv:2401.04757 , year=
-
[16]
Extrapolating
Finnveden, Lukas , year=. Extrapolating
-
[17]
Advances in Neural Information Processing Systems , year=
Observational Scaling Laws and the Predictability of Language Model Performance , author=. Advances in Neural Information Processing Systems , year=
-
[18]
Ho, Anson and Denain, Jean-Stanislas and Atanasov, David and Albanie, Samuel and Shah, Rohin , journal=. A. 2025 , doi=
2025
-
[19]
arXiv preprint arXiv:2304.15004 , year=
Are Emergent Abilities of Large Language Models a Mirage? , author=. arXiv preprint arXiv:2304.15004 , year=. doi:10.48550/arXiv.2304.15004 , url=
-
[20]
Is the gap between open and closed models growing?
H. Is the gap between open and closed models growing?. 2025 , month = aug, day =
2025
-
[21]
2025 , month = oct, day =
Luke Emberson , title =. 2025 , month = oct, day =
2025
-
[22]
2025 , publisher =
Chapter 2: Technical Performance , booktitle =. 2025 , publisher =
2025
-
[23]
1999 , school=
Reversibility for efficient computing , author=. 1999 , school=
1999
-
[24]
Physical Review D , volume=
Entropy content and information flow in systems with limited energy , author=. Physical Review D , volume=. 1984 , publisher=
1984
-
[25]
Earley, Hannah , journal=
-
[26]
Hardware-Enabled Mechanisms for Verifying Responsible
Aidan O'Gara and Gabriel Kulp and Will Hodgkins and James Petrie and Vincent Immler and Aydin Aysu and Kanad Basu and Shivam Bhasin and Stjepan Picek and Ankur Srivastava , year=. Hardware-Enabled Mechanisms for Verifying Responsible. 2505.03742 , archivePrefix=
-
[27]
There’s plenty of room at the Top: What will drive computer performance after
Leiserson, Charles E and Thompson, Neil C and Emer, Joel S and Kuszmaul, Bradley C and Lampson, Butler W and Sanchez, Daniel and Schardl, Tao B , journal=. There’s plenty of room at the Top: What will drive computer performance after. 2020 , publisher=
2020
-
[28]
Communications of the ACM , volume=
The future of microprocessors , author=. Communications of the ACM , volume=. 2011 , publisher=
2011
-
[29]
Semiconductor Industry Association and others , year=
-
[30]
arXiv preprint arXiv:2206.14007 , year=
The importance of (exponentially more) computing power , author=. arXiv preprint arXiv:2206.14007 , year=
-
[31]
arXiv preprint arXiv:2108.07686 , year=
Scaling laws for deep learning , author=. arXiv preprint arXiv:2108.07686 , year=
-
[32]
Explaining neural scaling laws , volume=
Bahri, Yasaman and Dyer, Ethan and Kaplan, Jared and Lee, Jaehoon and Sharma, Utkarsh , year=. Explaining neural scaling laws , volume=. Proceedings of the National Academy of Sciences , publisher=. doi:10.1073/pnas.2311878121 , number=
-
[33]
2020 , eprint=
Scaling Laws for Neural Language Models , author=. 2020 , eprint=
2020
-
[34]
2022 , eprint=
Training Compute-Optimal Large Language Models , author=. 2022 , eprint=
2022
-
[35]
Compute Trends Across Three Eras of Machine Learning , url=
Sevilla, Jaime and Heim, Lennart and Ho, Anson and Besiroglu, Tamay and Hobbhahn, Marius and Villalobos, Pablo , year=. Compute Trends Across Three Eras of Machine Learning , url=. doi:10.1109/ijcnn55064.2022.9891914 , booktitle=
-
[36]
Is there "Secret Sauce'' in Large Language Model Development?
Matthias Mertens and Natalia Fischl-Lanzoni and Neil Thompson , year =. Is there. arXiv preprint arXiv:2602.07238 , url =
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Advances in Neural Information Processing Systems , year=
Training Compute-Optimal Large Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[38]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Srivastava, Aarohi and Rastogi, Abhishek and Rao, Abhishek and Shoeb, Ahmad and Abid, Abubakar and Fisch, Adam and Brown, Adam R. and Santoro, Adam and Gupta, Aditya and Garriga-Alonso, Adri. Beyond the Imitation Game:. arXiv preprint arXiv:2206.04615 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Measuring Massive Multitask Language Understanding
Measuring Massive Multitask Language Understanding , author =. arXiv preprint arXiv:2009.03300 , year =
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[40]
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li , booktitle =
-
[41]
Learning Multiple Layers of Features from Tiny Images , author =
-
[42]
Proceedings of the IEEE , volume =
Gradient-Based Learning Applied to Document Recognition , author =. Proceedings of the IEEE , volume =
-
[43]
Nature , volume =
Human-level control through deep reinforcement learning , author =. Nature , volume =
-
[44]
and Naddaf, Yavar and Veness, Joel and Bowling, Michael , journal =
Bellemare, Marc G. and Naddaf, Yavar and Veness, Joel and Bowling, Michael , journal =. The Arcade Learning Environment:
-
[45]
2026 , month =
Data on. 2026 , month =
2026
-
[46]
Venkat Somala , year=
-
[47]
Zhang, Zhexin and Lei, Leqi and Wu, Lindong and Sun, Rui and Huang, Yongkang and Long, Chong and Liu, Xiao and Lei, Xuanyu and Tang, Jie and Huang, Minlie , year =. 2309.07045 , archivePrefix =
-
[48]
2024 , url =
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and Forsyth, David and Hendrycks, Dan , booktitle =. 2024 , url =
2024
-
[49]
EvilGenie: A Reward Hacking Benchmark
Gabor, Jonathan and Lynch, Jayson and Rosenfeld, Jonathan , year =. 2511.21654 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
On the Origin of Algorithmic Progress in
Gundlach, Hans and Fogelson, Alex and Lynch, Jayson and Trisovic, Ana and Rosenfeld, Jonathan and Sandhu, Anmol and Thompson, Neil , journal=. On the Origin of Algorithmic Progress in
-
[51]
On the Origin of Algorithmic Progress in
Gundlach, Hans and Fogelson, Alex and Lynch, Jayson and Trisovic, Ana and Rosenfeld, Jonathan and Sandhu, Anmol and Thompson, Neil , year=. On the Origin of Algorithmic Progress in. doi:10.48550/arXiv.2511.21622 , url=. 2511.21622 , archivePrefix=
-
[52]
American Economic Review , volume=
Are Ideas Getting Harder to Find? , author=. American Economic Review , volume=. 2020 , doi=
2020
-
[53]
2024 , url=
How far behind are open models? , author=. 2024 , url=
2024
-
[54]
2023 , url=
Trading Off Compute in Training and Inference , author=. 2023 , url=
2023
-
[55]
2026 , month = apr, type =
2026
-
[56]
2022 , month = jun, howpublished =
Hobbhahn, Marius and Besiroglu, Tamay , title =. 2022 , month = jun, howpublished =
2022
-
[57]
2024 , eprint=
Algorithmic progress in language models , author=. 2024 , eprint=
2024
-
[58]
2025 , month = apr, url =
Frontier Capability Assessments:. 2025 , month = apr, url =
2025
-
[59]
and Lucas, Caleb and Guest, Ella , institution =
Mouton, Christopher A. and Lucas, Caleb and Guest, Ella , institution =. The Operational Risks of. 2024 , number =. doi:10.7249/RRA2977-2 , url =
-
[60]
2024 , month = jan, url =
Building an Early Warning System for. 2024 , month = jan, url =
2024
-
[61]
Peppin, Aidan and Reuel, Anka and Casper, Stephen and Jones, Elliot and Strait, Andrew and Anwar, Usman and Agrawal, Anurag and Kapoor, Sayash and Koyejo, Sanmi and Pellat, Marie and Bommasani, Rishi and Frosst, Nick and Hooker, Sara , year =. The reality of. doi:10.48550/arXiv.2412.01946 , url =. 2412.01946 , archivePrefix =
-
[62]
International Conference on Learning Representations , year =. 2506.02548 , archivePrefix =
-
[63]
2025 , month = sep, url =
Why Do We Take. 2025 , month = sep, url =
2025
-
[64]
Jones, Charles I. , Title =. American Economic Review: Insights , Volume =. 2024 , Month =. doi:10.1257/aeri.20230570 , URL =
-
[65]
2023 , url=
Trading off compute in training and inference , author=. 2023 , url=
2023
-
[66]
The Illusion of Diminishing Returns:
Akshit Sinha and Arvindh Arun and Shashwat Goel and Steffen Staab and Jonas Geiping , booktitle=. The Illusion of Diminishing Returns:. 2026 , url=
2026
-
[67]
Rein, David and Becker, Joel and Deng, Amy and Nix, Seraphina and Canal, Chris and O'Connell, Daniel and Arnott, Pip and Bloom, Ryan and Broadley, Thomas and Garcia, Katharyn and Goodrich, Brian and Hasin, Max and Jawhar, Sami and Kinniment, Megan and Kwa, Thomas and Lajko, Aron and Rush, Nate and Sato, Lucas Jun Koba and Von Arx, Sydney and West, Ben and...
-
[68]
Wijk, Hjalmar and Lin, Tao and Becker, Joel and Jawhar, Sami and Parikh, Neev and Broadley, Thomas and Chan, Lawrence and Chen, Michael and Clymer, Josh and Dhyani, Jai and Ericheva, Elena and Garcia, Katharyn and Goodrich, Brian and Jurkovic, Nikola and Kinniment, Megan and Lajko, Aron and Nix, Seraphina and Sato, Lucas and Saunders, William and Taran, M...
-
[69]
Bostrom, Nick , title =. Global Policy , volume =. doi:https://doi.org/10.1111/1758-5899.12718 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1111/1758-5899.12718 , abstract =
-
[70]
Lewis Hammond and Alan Chan and Jesse Clifton and Jason Hoelscher-Obermaier and Akbir Khan and Euan McLean and Chandler Smith and Wolfram Barfuss and Jakob Foerster and Tomáš Gavenčiak and The Anh Han and Edward Hughes and Vojtěch Kovařík and Jan Kulveit and Joel Z. Leibo and Caspar Oesterheld and Christian Schroeder de Witt and Nisarg Shah and Michael We...
-
[71]
Hyperscaler capex has quadrupled since
Isabel Juniewicz , year =. Hyperscaler capex has quadrupled since
-
[72]
How Much Progress Has There Been in
Del Sozzo, Emanuele and Fleming, Martin and Flamm, Kenneth and Thompson, Neil , journal=. How Much Progress Has There Been in
-
[73]
and Lynch, Jayson and Thompson, Neil , title =
Gundlach, Hans and Brown, Zachary A. and Lynch, Jayson and Thompson, Neil , title =. 2026 , month = jun, note =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.