Bridging the Last Mile of Time Series Forecasting with LLM Agents
Pith reviewed 2026-06-28 14:39 UTC · model grok-4.3
The pith
LLM agents revise statistical time series forecasts with business context to produce controllable and auditable outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
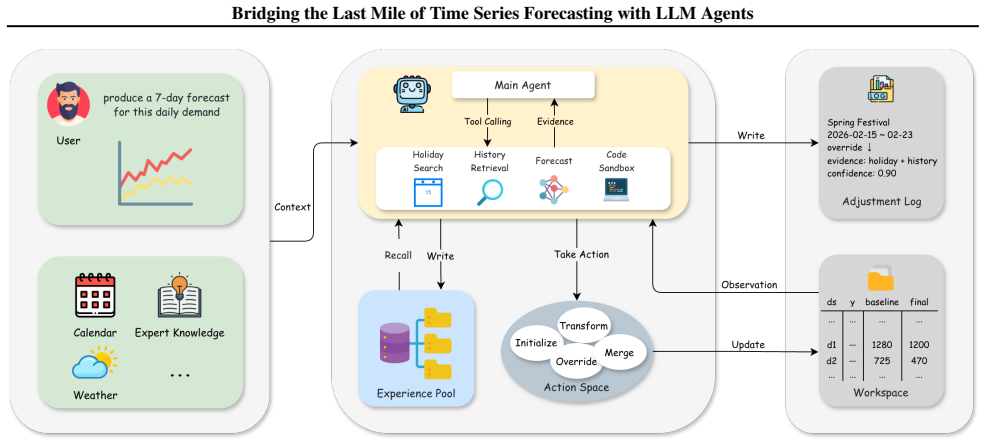
LLM agents can bridge the last-mile forecasting problem by maintaining a unified forecast workspace, invoking tools to gather contextual evidence, and converting reasoning trajectories into explicit revision actions that respect structural safety constraints, thereby making the final forecast controllable and auditable.
What carries the argument
The LLM-agent framework that maintains a unified forecast workspace, retrieves contextual evidence via tools, and converts reasoning trajectories into explicit revision actions under structural safety constraints.
If this is right
- Forecast revisions become explicit actions rather than opaque post-processing steps.
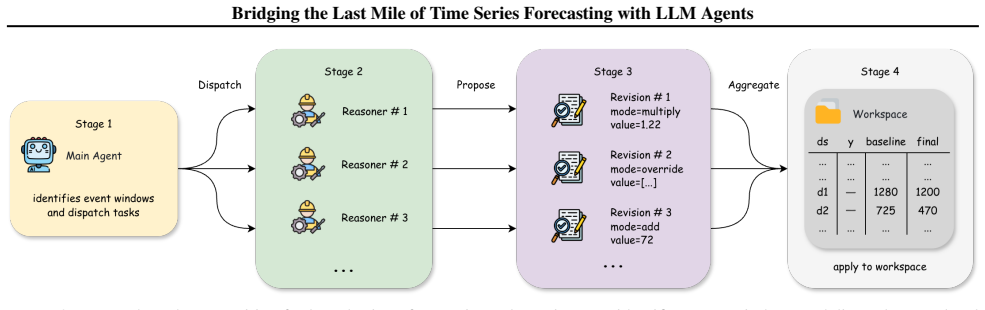
- Long-horizon forecasts can be produced by map-reduce decomposition within the same agent workspace.
- Post-hoc review of past revisions is enabled by a memory bank that stores reasoning trajectories.
- The overall pipeline remains compatible with any existing statistical or foundation-model forecasting backbone.
Where Pith is reading between the lines
- The same agent pattern could be tested on domains that also separate a statistical prediction from a final decision, such as inventory or demand planning.
- If the safety constraints prove insufficient, hybrid human-in-the-loop checkpoints would still be required at the revision stage.
- The framework implies that forecast accuracy metrics alone are insufficient; controllability and auditability become primary evaluation criteria.
Load-bearing premise
LLM agents can reliably retrieve and apply weakly structured business context to produce controllable, auditable forecast revisions without introducing uncontrolled errors.
What would settle it
A documented case in which an agent applies a revision based on misinterpreted business context that violates the safety constraints and is not caught before the forecast is used.
Figures

read the original abstract
Time series forecasting has advanced rapidly, especially with the emergence of foundation models that show strong zero-shot performance on numerical extrapolation. However, in real-world forecasting settings, a statistically plausible baseline is rarely the final forecast used in practice. Before a forecast becomes decision-ready, it often needs to be revised using weakly structured business context such as holiday effects, campaign plans, external events, historical analogs, and expert feedback. This practical stage remains underexplored in the forecasting literature. In this paper, we formulate this stage as the \textbf{last-mile forecasting} problem and present an LLM-agent framework that sits on top of a forecasting backbone. Our system maintains a unified forecast workspace, invokes tools to retrieve contextual evidence, and converts reasoning trajectories into explicit forecast revision actions under structural safety constraints. It also supports long-horizon forecasting through map-reduce-style decomposition and post-hoc reflection through a memory bank. The resulting system is designed to be controllable and auditable. Through real-world case studies, we show how LLM agents can bridge the gap between statistical prediction and business-ready forecasting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates the 'last-mile forecasting' problem of revising statistical forecasts with weakly structured business context (holidays, campaigns, events, analogs, feedback). It presents an LLM-agent framework atop a forecasting backbone that maintains a unified workspace, invokes tools for contextual evidence, converts reasoning trajectories into explicit revision actions under structural safety constraints, supports long-horizon forecasting via map-reduce decomposition, and enables post-hoc reflection via a memory bank. The system is positioned as controllable and auditable, with claims supported by real-world case studies.
Significance. If the central claims hold, the work would be significant for addressing an underexplored practical gap between zero-shot foundation-model forecasts and decision-ready outputs in business settings. The explicit formulation of last-mile forecasting and the agent architecture (workspace + tools + safety constraints + memory) provide a concrete starting point for controllable integration of contextual evidence.
major comments (2)
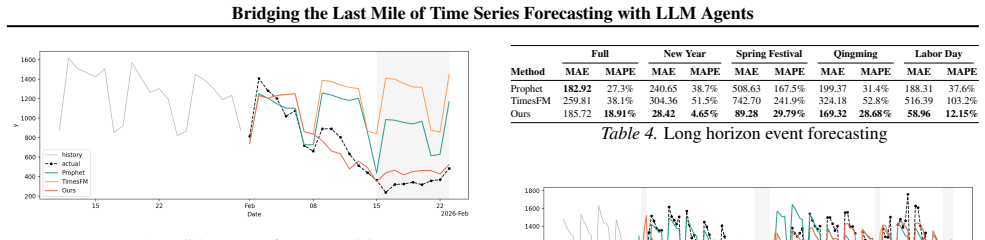
- [Case Studies] Case Studies section: the real-world case studies are presented qualitatively with no quantitative metrics on revision accuracy, error introduction rates, comparison against human-only or baseline revision processes, or failure-mode analysis of the structural safety constraints. This directly leaves the claim of reliable, controllable, auditable revisions untested.
- [System Description] System Description / Evaluation protocol: no ablation studies, error analysis, or formal evaluation protocol (e.g., ground-truth revision targets, inter-rater agreement on auditability) are reported, so the soundness of the weakest assumption—that LLM agents can reliably apply weakly structured context without uncontrolled errors—cannot be assessed from the manuscript.
minor comments (2)
- [Abstract / System Architecture] Clarify the precise definition and enforcement mechanism of 'structural safety constraints' (mentioned in the abstract) so readers can evaluate how they prevent uncontrolled revisions.
- [System Description] The abstract states the system 'converts reasoning trajectories into explicit forecast revision actions'; provide a concrete example of an action schema or output format in the main text.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback. Below we provide point-by-point responses to the major comments, clarifying the intended scope of the paper as a framework proposal with illustrative case studies.
read point-by-point responses
-
Referee: [Case Studies] Case Studies section: the real-world case studies are presented qualitatively with no quantitative metrics on revision accuracy, error introduction rates, comparison against human-only or baseline revision processes, or failure-mode analysis of the structural safety constraints. This directly leaves the claim of reliable, controllable, auditable revisions untested.
Authors: The case studies serve to illustrate the practical use of the proposed LLM-agent framework in real business settings, focusing on how the unified workspace, tool use, and constrained actions enable controllable and auditable revisions. We do not claim empirical proof of reliability across all cases but rather demonstrate the mechanism for bridging statistical forecasts with context. We agree that additional quantitative evaluation would be beneficial and will include in the revision a discussion of evaluation challenges and proposed metrics for future work. revision: partial
-
Referee: [System Description] System Description / Evaluation protocol: no ablation studies, error analysis, or formal evaluation protocol (e.g., ground-truth revision targets, inter-rater agreement on auditability) are reported, so the soundness of the weakest assumption—that LLM agents can reliably apply weakly structured context without uncontrolled errors—cannot be assessed from the manuscript.
Authors: The system description details the structural safety constraints and memory bank designed to address potential uncontrolled errors from LLM reasoning. The paper's contribution is the formulation of last-mile forecasting and the agent architecture rather than a full empirical study. We will revise the manuscript to include an explicit limitations section that acknowledges the need for formal evaluation protocols and suggests directions for ground-truth collection and ablation studies in subsequent research. revision: partial
Circularity Check
No circularity: framework description contains no derivations or self-referential reductions
full rationale
The paper formulates the last-mile forecasting problem and describes an LLM-agent system (unified workspace, tool invocation, reasoning-to-action conversion, safety constraints, map-reduce decomposition, memory bank) without any equations, fitted parameters, or mathematical derivations. Claims rest on real-world case studies rather than reductions to inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes appear in the provided text. The central claim is therefore self-contained and does not reduce to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
URL https://aclanthology.org/2025. findings-emnlp.834/. Jiang, Y ., Ning, K., Pan, Z., Shen, X., Ni, J., Yu, W., Schnei- der, A., Chen, H., Nevmyvaka, Y ., and Song, D. Multi- modal time series analysis: A tutorial and survey. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pp. 6043– 6053, 2025. Jin, M., Wang...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Inspect the series compactly (range, frequency, trend, anomalies)
-
[3]
Ensure the baseline exists; otherwise call forecast_tool, then append_forecast
-
[4]
Consult last_reflection_summary; prefer realized lessons over fresh guesses
-
[5]
For each user-mentioned or calendar-relevant event, gather evidence
-
[6]
26For a single isolated event, edit y_final directly via adjust_by_date_range 27or override_forecast_values
If the horizon contains MORE THAN ONE event, build a tasks list and call 25run_map_reduce_planners(tasks, context) followed by apply_json_policies. 26For a single isolated event, edit y_final directly via adjust_by_date_range 27or override_forecast_values
-
[7]
30 31## Revision policy (evidence priority) 32realized multipliers from reflection > memory critiques > historical 33same-period ratios > user instructions
Self-review the adjustment_log for empty evidence, implausible impact, 29duplicate ranges, or missing confidence. 30 31## Revision policy (evidence priority) 32realized multipliers from reflection > memory critiques > historical 33same-period ratios > user instructions. Listing 1.Main agent prompt (excerpt). B.2. Local Reasoner Prompt 1## Role 2You are a ...
-
[8]
Your output is a JSON envelope of proposed signals, not direct edits
-
[9]
Your scope of effect is the assigned event’s date range. 7 8## Inputs 9The task prompt wraps a global_context block and an assignment block 10 Bridging the Last Mile of Time Series Forecasting with LLM Agents Tool Role Forecasting tool obtains the baseline forecast from the time-series backbone Historical retrieval retrieves past windows from the current ...
-
[10]
Memory first: query_memory_bank(event); a prior critique outranks any 15fresh prior you might pick
-
[11]
Ground the magnitude: retrieve_history_tool over the same-period window 17returned by holiday_search_tool; compute realized/baseline ratio
-
[12]
Check whether the baseline already covers it; if so, propose mode ‘none‘
-
[13]
Pick the shape: range (multiply/add/clip) for uniform effects; 20override (per-day values from a historical analog) for distinctive shapes
-
[14]
Persist the decision via write_signal_envelope(signals); call it once. 22 23## Output schema (per signal) 24source, event, start_date, end_date, mode, value | dates+values, 25direction, magnitude, reason, evidence, confidence 26Confidence tiers: 0.9 (two strong evidences agree), 0.7 (one strong), 270.5 (weak/indirect), 0.3 (user instruction only). Listing...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.