Generative Refinement for Low-Budget Black-Box Optimization
Pith reviewed 2026-07-02 16:19 UTC · model grok-4.3
The pith
SPARROW decouples any pre-trained generative sampler from reward signals to optimize black-box functions with few evaluations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
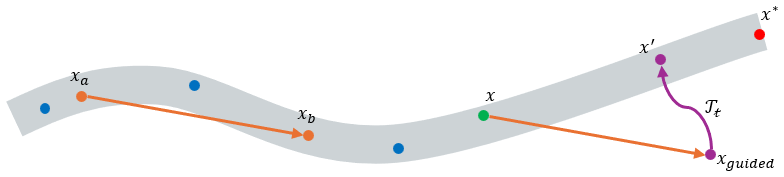
SPARROW completely decouples the generative prior from the reward signal. It uses any sampler with a known corruption process and trained on unevaluated data as a fixed, structured proposal operator. Optimization proceeds by rank-based guidance over an archive of evaluated candidates, allowing navigation of complex geometries, tolerance of unreliable rewards, and effective performance under very low evaluation budgets while providing asymptotic convergence guarantees over the sampler support.
What carries the argument
The fixed structured proposal operator: any sampler with known corruption process trained on unevaluated data, used without further alignment to rewards.
If this is right
- Optimization succeeds on geometrically complex landscapes such as thin curved manifolds or disconnected regions.
- The algorithm tolerates noisy or failure-prone reward signals without retraining the sampler.
- Effective search is possible with evaluation budgets far below those required to align a generative model to rewards.
- Asymptotic convergence holds over the support of the fixed sampler regardless of the reward distribution.
Where Pith is reading between the lines
- Pre-trained generative models from large unlabeled corpora could be reused across multiple downstream optimization tasks without any reward-specific fine-tuning.
- The approach suggests a modular separation between distribution learning and selection that might apply to other proposal-based search methods.
- Testing on problems where the sampler support only partially overlaps the optimum region would reveal the practical boundary of the convergence guarantee.
Load-bearing premise
The high-performing solutions must lie inside the support of the chosen fixed sampler.
What would settle it
Place the global optimum outside the support of the pre-trained sampler and run the algorithm to any budget; if it never recovers the optimum, the support-containment premise is necessary.
Figures
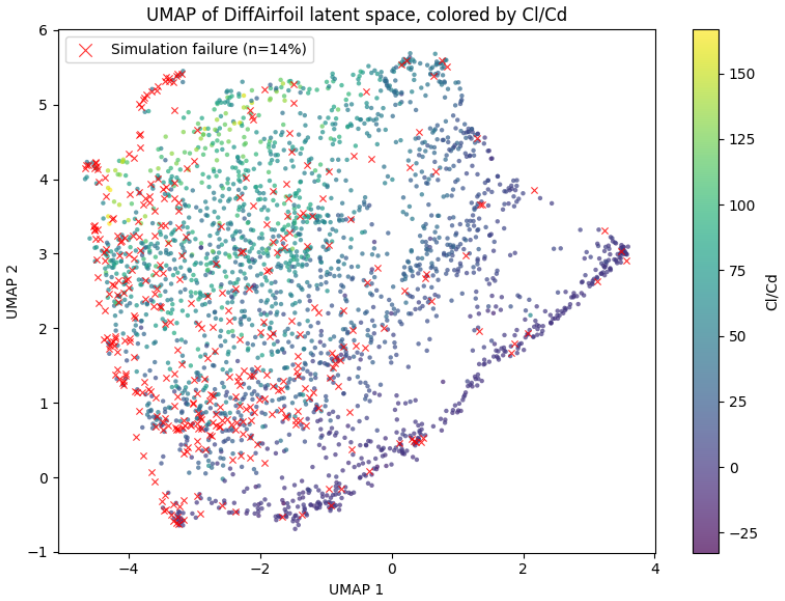
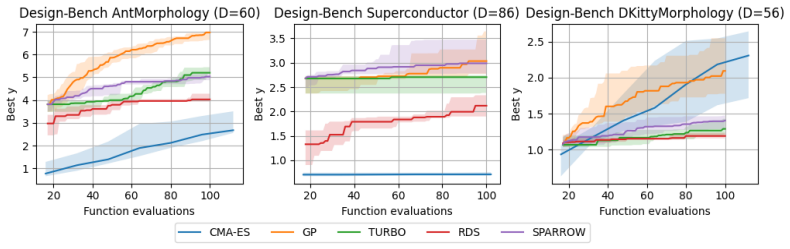
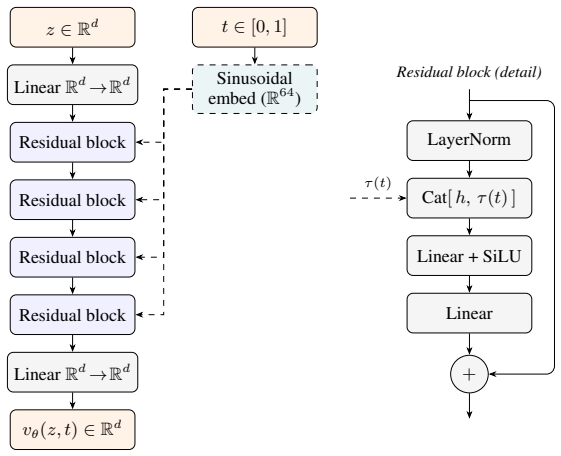
read the original abstract
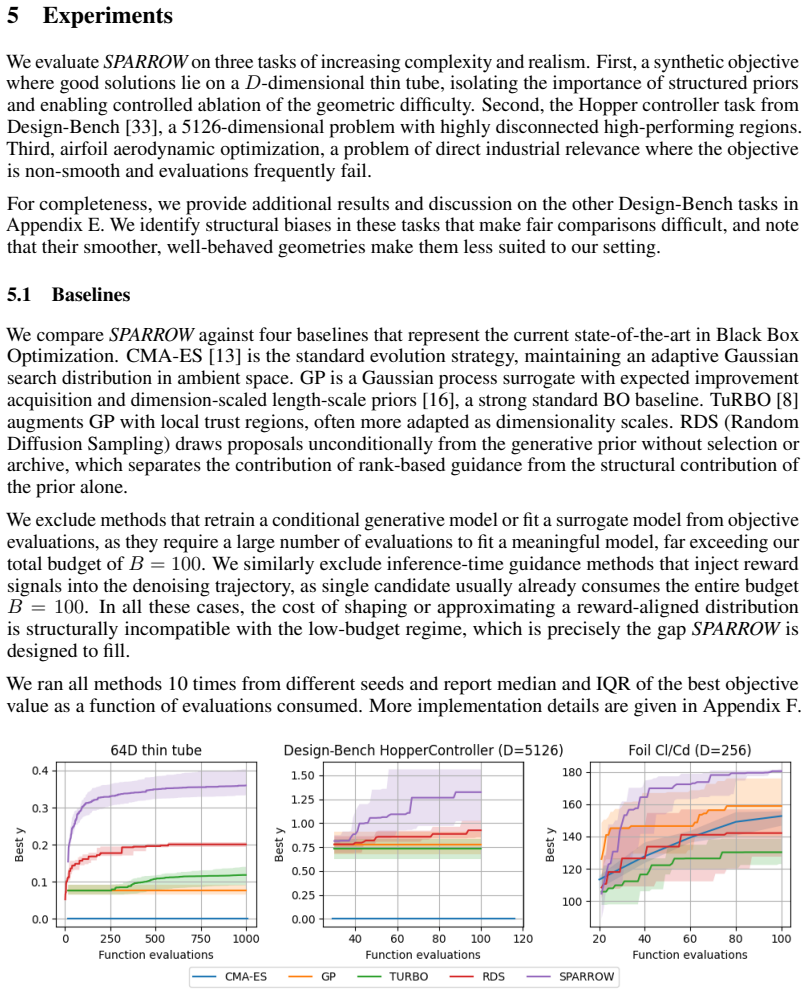
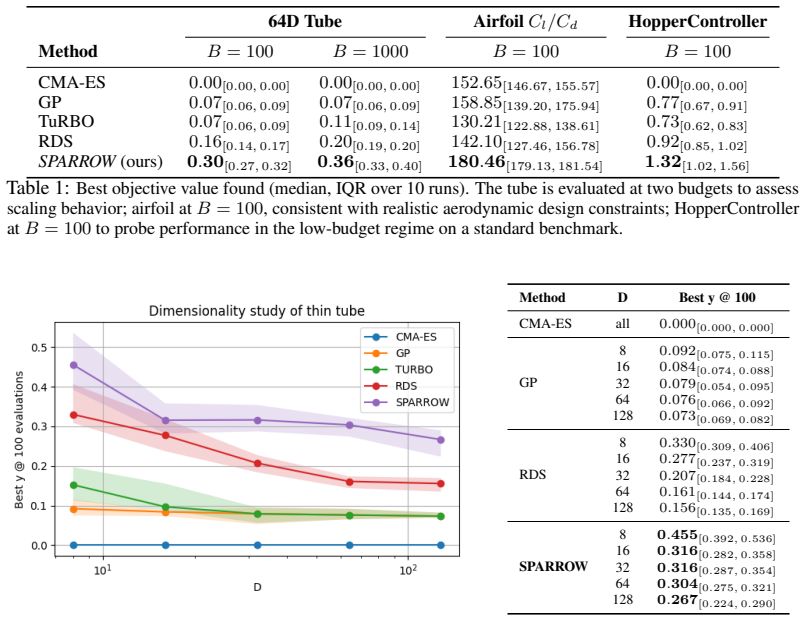
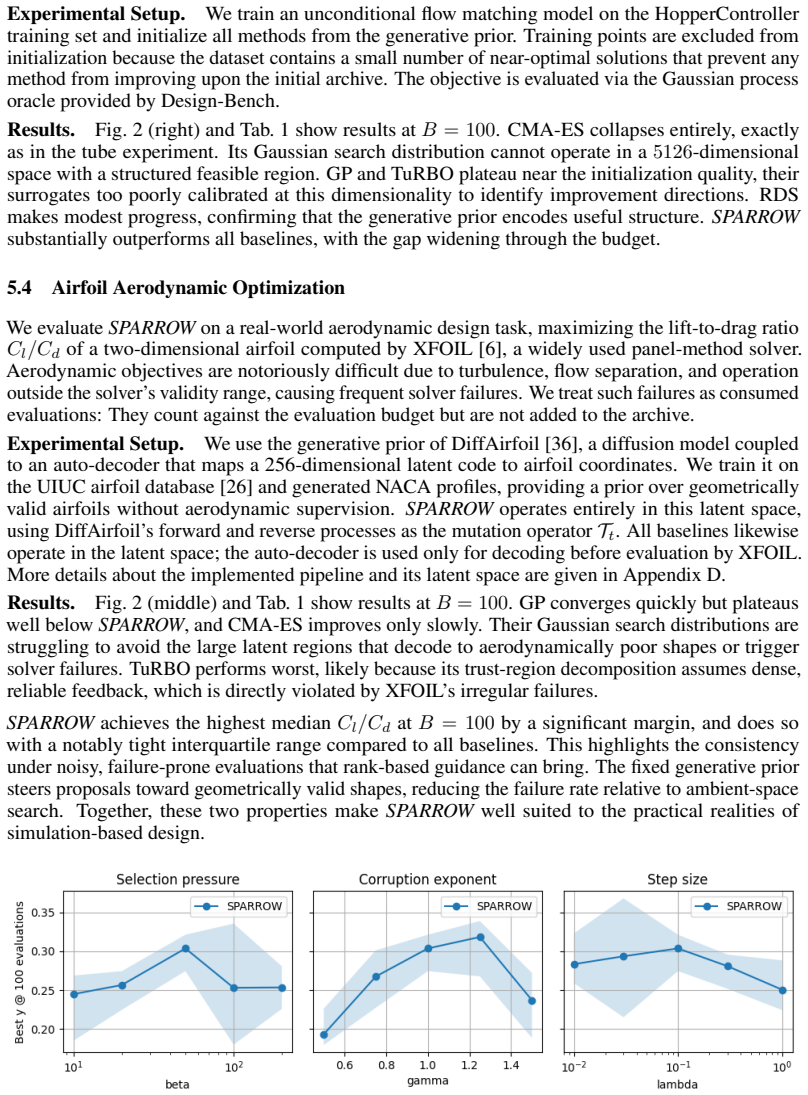
Black-box optimization is a fundamental science and engineering tool that makes it possible to optimize objectives without gradient information. Unfortunately, as it often requires many function evaluations, it can be challenging when each one is costly. This is especially true when the evaluation function is noisy or failure-prone, and when high-performing solutions are confined to thin, curved, or disconnected regions of the search space. Existing methods leveraging generative models to navigate these subspaces are built to sample from reward-aligned distributions. As a result, they require a large number of evaluations to align their sampler effectively, making them impractical in low-budget settings. We propose SPARROW, an algorithm that completely decouples the generative prior from the reward signal. SPARROW can use any sampler with a known corruption process and trained on unevaluated data, as a fixed, structured proposal operator. Optimization proceeds by rank-based guidance over an archive of evaluated candidates. SPARROW can navigate complex geometries, handle unreliable reward signals, and perform effective optimization under very low evaluation budgets. We provide asymptotic convergence guarantees over the sampler support and demonstrate strong empirical performance on problems with unreliable rewards and geometrically complex landscapes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SPARROW for low-budget black-box optimization. It decouples a fixed generative sampler (trained on unevaluated data with known corruption process) from the reward signal, using it as a structured proposal operator combined with rank-based guidance over an archive of evaluated points. The method claims to navigate complex (thin/curved/disconnected) geometries and unreliable rewards with very few evaluations, supported by asymptotic convergence guarantees over the sampler support plus strong empirical results.
Significance. If the sampler support is shown to contain near-optima for the target geometries, the decoupling of prior from reward could be a useful contribution for low-evaluation-budget settings where reward-aligned generative methods are impractical. The asymptotic guarantee and empirical claims on noisy/failure-prone objectives would be the primary strengths if substantiated.
major comments (1)
- [Abstract] Abstract: the asymptotic convergence guarantee is stated only 'over the sampler support,' yet no argument, assumption, or diagnostic is supplied showing that a sampler trained exclusively on unevaluated points will have support containing the high-performing solutions when those solutions lie in thin, curved, or disconnected regions. This leaves the guarantee potentially vacuous for the settings highlighted in the abstract and weakens attribution of low-budget performance to the method rather than to unverified prior coverage.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to clarify the scope of the convergence guarantee in the abstract. We address the comment below and will make corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the asymptotic convergence guarantee is stated only 'over the sampler support,' yet no argument, assumption, or diagnostic is supplied showing that a sampler trained exclusively on unevaluated points will have support containing the high-performing solutions when those solutions lie in thin, curved, or disconnected regions. This leaves the guarantee potentially vacuous for the settings highlighted in the abstract and weakens attribution of low-budget performance to the method rather than to unverified prior coverage.
Authors: We agree that the abstract should more explicitly qualify the guarantee. SPARROW's asymptotic result establishes convergence to the best point within the support of the supplied fixed sampler (under standard assumptions on the rank-based selection and known corruption process); it does not assert that every sampler trained solely on unevaluated data will automatically cover thin/curved/disconnected high-performing regions. The method is designed for settings in which a suitable generative prior is available or can be constructed, and the low-budget advantage arises from decoupling the prior from the reward signal rather than from any claim of universal coverage. We will revise the abstract to state the conditional nature of the guarantee and add a short paragraph in the introduction clarifying the prerequisite on sampler support, together with a brief note on practical ways to obtain or validate such priors for geometrically complex problems. revision: yes
Circularity Check
No significant circularity; guarantees conditional on input sampler support
full rationale
The paper states its asymptotic convergence guarantees explicitly hold 'over the sampler support' where the sampler is an external input (any model trained on unevaluated data with known corruption). No derivation step reduces a claimed result to its own fitted parameters, self-citations, or definitions by construction. The method decouples the fixed proposal from rewards and uses rank-based selection; the support-coverage assumption is presented as a premise rather than proven, but this does not create circularity in the algorithm's internal logic or guarantees. The derivation chain remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A sampler with known corruption process trained on unevaluated data can serve as a fixed structured proposal operator
Reference graph
Works this paper leans on
-
[1]
Botorch: A framework for efficient monte-carlo bayesian optimization
Maximilian Balandat, Brian Karrer, Daniel Jiang, Samuel Daulton, Ben Letham, Andrew G Wil- son, and Eytan Bakshy. Botorch: A framework for efficient monte-carlo bayesian optimization. Advances in neural information processing systems, 33:21524–21538, 2020
2020
-
[2]
Conditioning by adaptive sampling for robust design
David Brookes, Hahnbeom Park, and Jennifer Listgarten. Conditioning by adaptive sampling for robust design. InInternational conference on machine learning, pages 773–782. PMLR, 2019
2019
-
[3]
Bidirectional learning for offline model-based biological sequence design
Can Chen, Yingxue Zhang, Xue Liu, and Mark Coates. Bidirectional learning for offline model-based biological sequence design. InInternational Conference on Machine Learning, pages 5351–5366. PMLR, 2023
2023
-
[4]
Robust guided diffusion for offline black-box optimization.arXiv preprint arXiv:2410.00983, 2024
Can Sam Chen, Christopher Beckham, Zixuan Liu, Xue Liu, and Christopher Pal. Robust guided diffusion for offline black-box optimization.arXiv preprint arXiv:2410.00983, 2024
-
[5]
Investigating bayesian optimization for expensive-to-evaluate black box functions: Application in fluid dynamics.Frontiers in Applied Mathematics and Statistics, 8: 1076296, 2022
Mike Diessner, Joseph O’Connor, Andrew Wynn, Sylvain Laizet, Yu Guan, Kevin Wilson, and Richard D Whalley. Investigating bayesian optimization for expensive-to-evaluate black box functions: Application in fluid dynamics.Frontiers in Applied Mathematics and Statistics, 8: 1076296, 2022
2022
-
[6]
M. Drela. XFOIL: An Analysis and Design System for Low Reynolds Number Airfoils. In Conference on Low Reynolds Number Aerodynamics, pages 1–12, 1989
1989
-
[7]
Springer, 2015
Agoston E Eiben and James E Smith.Introduction to evolutionary computing. Springer, 2015
2015
-
[8]
Scalable global optimization via local bayesian optimization.Advances in neural information processing systems, 32, 2019
David Eriksson, Michael Pearce, Jacob Gardner, Ryan D Turner, and Matthias Poloczek. Scalable global optimization via local bayesian optimization.Advances in neural information processing systems, 32, 2019
2019
-
[9]
Bayesian optimization for materials design
Peter I Frazier and Jialei Wang. Bayesian optimization for materials design. InInformation science for materials discovery and design, pages 45–75. Springer, 2015
2015
-
[10]
Automatic chemical design using a data-driven continuous representation of molecules.ACS central science, 4(2):268–276, 2018
Rafael Gómez-Bombarelli, Jennifer N Wei, David Duvenaud, José Miguel Hernández-Lobato, Benjamín Sánchez-Lengeling, Dennis Sheberla, Jorge Aguilera-Iparraguirre, Timothy D Hirzel, Ryan P Adams, and Alán Aspuru-Guzik. Automatic chemical design using a data-driven continuous representation of molecules.ACS central science, 4(2):268–276, 2018. 12
2018
-
[11]
Protein design with guided discrete diffusion.URL https://arxiv
Nate Gruver, Samuel Stanton, Nathan C Frey, Tim GJ Rudner, Isidro Hotzel, Julien Lafrance- Vanasse, Arvind Rajpal, Kyunghyun Cho, and Andrew Gordon Wilson. Protein design with guided discrete diffusion.URL https://arxiv. org/abs/2305.20009, 2023
-
[12]
A data-driven statistical model for predicting the critical temperature of a superconductor.Computational Materials Science, 154:346–354, 2018
Kam Hamidieh. A data-driven statistical model for predicting the critical temperature of a superconductor.Computational Materials Science, 154:346–354, 2018
2018
-
[13]
The CMA Evolution Strategy: A Tutorial
Nikolaus Hansen. The CMA Evolution Strategy: A Tutorial. 2016
2016
-
[14]
Cma-es/pycma: r4
Nikolaus Hansen, Sait Cakmak, Gabi Kadlecová, Guillermo Abad López, Kento Nozawa, Luca Rolshoven, Youhei Akimoto, Dimo Brockhoff, et al. Cma-es/pycma: r4. 0.0.Zenodo, 2024
2024
-
[15]
J. Ho, A. Jain, and P. Abbeel. Denoising Diffusion Probabilistic Models. 2020
2020
-
[16]
Carl Hvarfner, Erik Orm Hellsten, and Luigi Nardi. Vanilla bayesian optimization performs great in high dimensions.arXiv preprint arXiv:2402.02229, 2024
-
[17]
Sunwoo Kim, Minkyu Kim, and Dongmin Park. Test-time alignment of diffusion models without reward over-optimization.arXiv preprint arXiv:2501.05803, 2025
-
[18]
Diffusion models for black-box optimization
Siddarth Krishnamoorthy, Satvik Mehul Mashkaria, and Aditya Grover. Diffusion models for black-box optimization. InInternational Conference on Machine Learning, pages 17842–17857. PMLR, 2023
2023
-
[19]
Model inversion networks for model-based optimization
Aviral Kumar and Sergey Levine. Model inversion networks for model-based optimization. Advances in neural information processing systems, 33:5126–5137, 2020
2020
-
[20]
Differential evolution
Jouni Lampinen and Rainer Storn. Differential evolution. InNew optimization techniques in engineering, pages 123–166. Springer, 2004
2004
-
[21]
Lipman, R
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow Matching for Generative Modeling. 2022
2022
-
[22]
Generative pretraining for black-box optimization
Satvik Mehul Mashkaria, Siddarth Krishnamoorthy, and Aditya Grover. Generative pretraining for black-box optimization. InInternational Conference on Machine Learning, pages 24173– 24197. PMLR, 2023
2023
-
[23]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations.arXiv preprint arXiv:2108.01073, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[24]
Information-geometric optimization algorithms: A unifying picture via invariance principles.Journal of Machine Learning Research, 18(18):1–65, 2017
Yann Ollivier, Ludovic Arnold, Anne Auger, and Nikolaus Hansen. Information-geometric optimization algorithms: A unifying picture via invariance principles.Journal of Machine Learning Research, 18(18):1–65, 2017
2017
-
[25]
Data-driven offline decision-making via invariant representation learning.Advances in Neural Information Processing Systems, 35: 13226–13237, 2022
Han Qi, Yi Su, Aviral Kumar, and Sergey Levine. Data-driven offline decision-making via invariant representation learning.Advances in Neural Information Processing Systems, 35: 13226–13237, 2022
2022
-
[26]
Selig.UIUC airfoil data site
Michael S. Selig.UIUC airfoil data site. Department of Aeronautical and Astronautical Engineering, University of Illinois at Urbana-Champaign, 1996
1996
-
[27]
Taking the human out of the loop: A review of bayesian optimization.Proceedings of the IEEE, 104 (1):148–175, 2015
Bobak Shahriari, Kevin Swersky, Ziyu Wang, Ryan P Adams, and Nando De Freitas. Taking the human out of the loop: A review of bayesian optimization.Proceedings of the IEEE, 104 (1):148–175, 2015
2015
-
[28]
Minimization by random search techniques.Mathematics of operations research, 6(1):19–30, 1981
Francisco J Solis and Roger J-B Wets. Minimization by random search techniques.Mathematics of operations research, 6(1):19–30, 1981
1981
-
[29]
J. Song, C. Meng, and S. Ermon. Denoising Diffusion Implicit Models. 2021
2021
-
[30]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and Ben Poole. Score-Based Generative Modeling through Stochastic Differential Equations. 2020. 13
2020
-
[31]
Zhiwei Tang, Jiangweizhi Peng, Jiasheng Tang, Mingyi Hong, Fan Wang, and Tsung-Hui Chang. Inference-time alignment of diffusion models with direct noise optimization.arXiv preprint arXiv:2405.18881, 2024
-
[32]
Conservative objective models for effective offline model-based optimization
Brandon Trabucco, Aviral Kumar, Xinyang Geng, and Sergey Levine. Conservative objective models for effective offline model-based optimization. InInternational Conference on Machine Learning, pages 10358–10368. PMLR, 2021
2021
-
[33]
Design-bench: Bench- marks for data-driven offline model-based optimization
Brandon Trabucco, Xinyang Geng, Aviral Kumar, and Sergey Levine. Design-bench: Bench- marks for data-driven offline model-based optimization. InInternational Conference on Machine Learning, pages 21658–21676. PMLR, 2022
2022
-
[34]
Masatoshi Uehara, Xingyu Su, Yulai Zhao, Xiner Li, Aviv Regev, Shuiwang Ji, Sergey Levine, and Tommaso Biancalani. Reward-guided iterative refinement in diffusion models at test-time with applications to protein and dna design.arXiv preprint arXiv:2502.14944, 2025
-
[35]
Latent Representation of CFD Meshes and Application to 2D Airfoil Aerodynamics
Zhen Wei, Benoît Guillard, Michaël Bauerheim, Vincent Chapin, and Pascal Fua. Latent Representation of CFD Meshes and Application to 2D Airfoil Aerodynamics. 63(8), 2023
2023
-
[36]
Zhen Wei, Edouard Dufour, Colin Pelletier, Pascal Fua, and Michaël Bauerheim. Diffairfoil: An efficient novel airfoil sampler based on latent space diffusion model for aerodynamic shape optimization. InAIAA A VIATION FORUM AND ASCEND, 2024. doi: 10.2514/6.2024-3755
-
[37]
Natural evolution strategies.The Journal of Machine Learning Research, 15(1):949–980, 2014
Daan Wierstra, Tom Schaul, Tobias Glasmachers, Yi Sun, Jan Peters, and Jürgen Schmidhuber. Natural evolution strategies.The Journal of Machine Learning Research, 15(1):949–980, 2014
2014
-
[38]
Diffusion-based inverse modeling for black-box optimization.arXiv preprint arXiv:2407.00610, 2024
Dongxia Wu, Nikki Lijing Kuang, Ruijia Niu, Yi-An Ma, and Rose Yu. Diffusion- bbo: Diffusion-based inverse modeling for online black-box optimization.arXiv preprint arXiv:2407.00610, 2024
-
[39]
A principled approach to design using high fidelity fluid-structure interaction simulations.Finite Elements in Analysis and Design, 194:103562, 2021
Wensi Wu, Christophe Bonneville, and Christopher Earls. A principled approach to design using high fidelity fluid-structure interaction simulations.Finite Elements in Analysis and Design, 194:103562, 2021
2021
-
[40]
Diffusion-es: Gradient-free planning with diffusion for autonomous and instruction-guided driving
Brian Yang, Huangyuan Su, Nikolaos Gkanatsios, Tsung-Wei Ke, Ayush Jain, Jeff Schneider, and Katerina Fragkiadaki. Diffusion-es: Gradient-free planning with diffusion for autonomous and instruction-guided driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15342–15353, 2024
2024
-
[41]
Roma: Robust model adaptation for offline model-based optimization.Advances in Neural Information Processing Systems, 34: 4619–4631, 2021
Sihyun Yu, Sungsoo Ahn, Le Song, and Jinwoo Shin. Roma: Robust model adaptation for offline model-based optimization.Advances in Neural Information Processing Systems, 34: 4619–4631, 2021
2021
-
[42]
Design editing for offline model-based optimization.arXiv preprint arXiv:2405.13964, 2024
Ye Yuan, Youyuan Zhang, Can Chen, Haolun Wu, Zixuan Li, Jianmo Li, James J Clark, and Xue Liu. Design editing for offline model-based optimization.arXiv preprint arXiv:2405.13964, 2024
-
[43]
Taeyoung Yun, Kiyoung Om, Jaewoo Lee, Sujin Yun, and Jinkyoo Park. Posterior infer- ence with diffusion models for high-dimensional black-box optimization.arXiv preprint arXiv:2502.16824, 2025. 14 A Maximum-entropy derivation of rank-based parent selection We show that the exponential rank-based selection rule pi = exp(−βri)P j exp(−βrj) arises as the max...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.