Towards Personalized Federated Learning for Dysarthric Speech Recognition
Pith reviewed 2026-06-27 05:50 UTC · model grok-4.3
The pith
Two aggregation strategies personalize federated models for dysarthric speech and reduce word error rates over regularized FedAvg.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that parameter-based averaging and embedding-based averaging during federated model aggregation produce personalized models that outperform regularized FedAvg on dysarthric speech, yielding statistically significant absolute WER reductions of up to 0.99 percent on UASpeech and 0.56 percent on TORGO.
What carries the argument
Parameter-based averaging strategy and embedding-based averaging strategy for adapting global model updates to individual speaker characteristics in federated learning.
If this is right
- Federated ASR systems can achieve measurable accuracy gains on heterogeneous dysarthric data while preserving privacy.
- Speaker variability in speech can be mitigated through aggregation choices rather than per-client model fine-tuning.
- The same aggregation approach may extend to other privacy-sensitive, speaker-variable recognition tasks.
- Statistically significant improvements are demonstrated on two established dysarthric corpora.
Where Pith is reading between the lines
- The strategies could be tested on additional neurological speech conditions to check broader applicability.
- Integration with lightweight client-side adaptation might produce further gains without violating the paper's no-extra-data premise.
- Performance on non-English dysarthric data remains an open question that would clarify language dependence.
Load-bearing premise
The two averaging strategies alone capture enough speaker-specific variation in dysarthric speech to improve recognition without extra per-speaker data, architecture changes, or added regularization.
What would settle it
A new dysarthric speech corpus or larger speaker set in which neither averaging method produces a statistically significant WER reduction over regularized FedAvg would falsify the central claim.
Figures
read the original abstract
Speech recognition is challenging for dysarthric speakers. While federated learning (FL)-based ASR can be an effective tool for protecting privacy, it suffers from heterogeneity issues caused by speaker variability. Forcing all speakers to share the same model components can be suboptimal under such heterogeneity, making personalization a promising direction; however, related research on dysarthric speech remains limited. To this end, this paper explores two aggregation strategies to achieve personalization, including the parameter-based averaging strategy and the embedding-based averaging strategy. Experiments on UASpeech and TORGO show that the proposed methods outperform the baseline regularized FedAvg by statistically significant WER reductions of up to 0.99% absolute (3.15% relative) on UASpeech and 0.56% absolute (4.73% relative) on TORGO, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two aggregation strategies—parameter-based averaging and embedding-based averaging—for achieving personalization in federated learning applied to dysarthric automatic speech recognition (ASR), addressing speaker heterogeneity while preserving privacy. Experiments on the UASpeech and TORGO datasets report that these methods outperform the baseline regularized FedAvg with statistically significant absolute WER reductions of up to 0.99% (3.15% relative) on UASpeech and 0.56% (4.73% relative) on TORGO.
Significance. If the reported gains are robustly validated, the work contributes to privacy-preserving personalization techniques for ASR in heterogeneous populations such as dysarthric speakers. The modest effect sizes, however, limit immediate practical significance without evidence that the strategies produce genuinely speaker-adapted models rather than marginal schedule effects.
major comments (3)
- [Abstract] Abstract: The claim of 'statistically significant' WER reductions provides no information on the statistical test employed, data partitioning scheme, hyperparameter selection protocol, number of runs, or multiple-comparison correction. This information is load-bearing for the central empirical claim that the two proposed aggregation strategies outperform regularized FedAvg.
- The manuscript does not report per-speaker WER breakdowns or any diagnostic showing that embedding-based averaging produces speaker-specific model behavior rather than collapsing toward the global model; without this, the outperformance cannot be attributed to the personalization thesis rather than training dynamics.
- No ablation or analysis is provided to rule out that the observed gains arise from differences in training schedule or regularization strength rather than the parameter- versus embedding-based averaging mechanisms themselves.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the empirical claims. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of 'statistically significant' WER reductions provides no information on the statistical test employed, data partitioning scheme, hyperparameter selection protocol, number of runs, or multiple-comparison correction. This information is load-bearing for the central empirical claim that the two proposed aggregation strategies outperform regularized FedAvg.
Authors: We agree that these details are essential. The revised manuscript will expand the abstract and add a dedicated paragraph in Section 4 (Experiments) specifying: (i) paired t-test over 5 independent runs with different random seeds, (ii) speaker-independent 5-fold cross-validation partitioning as described in Section 3.2, (iii) hyperparameter selection via grid search on a held-out validation speaker set, and (iv) no multiple-comparison correction applied because only two primary comparisons were performed. These additions will be made without altering the reported numbers. revision: yes
-
Referee: The manuscript does not report per-speaker WER breakdowns or any diagnostic showing that embedding-based averaging produces speaker-specific model behavior rather than collapsing toward the global model; without this, the outperformance cannot be attributed to the personalization thesis rather than training dynamics.
Authors: We acknowledge the request for direct evidence of speaker-specific adaptation. Due to the federated and privacy-preserving setting, raw per-speaker test utterances cannot be re-accessed centrally for post-hoc breakdowns. However, we will add in the revision: (a) WER stratified by dysarthria severity (mild/moderate/severe) on both datasets as a proxy, and (b) analysis of embedding cosine similarities across clients to demonstrate that the embedding-based method maintains distinct clusters rather than collapsing to the global model. These additions support the personalization claim while respecting data constraints. revision: partial
-
Referee: No ablation or analysis is provided to rule out that the observed gains arise from differences in training schedule or regularization strength rather than the parameter- versus embedding-based averaging mechanisms themselves.
Authors: We will include a new ablation subsection in the revised experiments. All methods will be re-run with identical training schedules (same number of local epochs and communication rounds) and identical regularization coefficients. The results will isolate the contribution of the aggregation strategy itself. If the gains persist under these controls, this will be reported; otherwise the claims will be qualified accordingly. revision: yes
Circularity Check
No circularity: empirical evaluation of proposed aggregation strategies on public datasets.
full rationale
The paper proposes parameter-based and embedding-based averaging for personalization in federated dysarthric ASR and reports WER reductions from experiments on UASpeech and TORGO. No derivation chain, equations, or fitted parameters exist that reduce claimed improvements to inputs by construction. Results are independent empirical measurements against a baseline (regularized FedAvg), with no self-citation load-bearing on a uniqueness theorem or ansatz. The central claims rest on external dataset outcomes rather than self-referential definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Despite decades of progress in automatic speech recognition (ASR) systems for typical speech [1, 2], accurate recognition of dysarthric speech remains challenging to date [3, 4, 5, 6, 7, 8, 9, 10, 11]. Dysarthric speech presents multi-fold challenges for current deep learning-based ASR systems primarily targeting healthy users, including:1) s...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
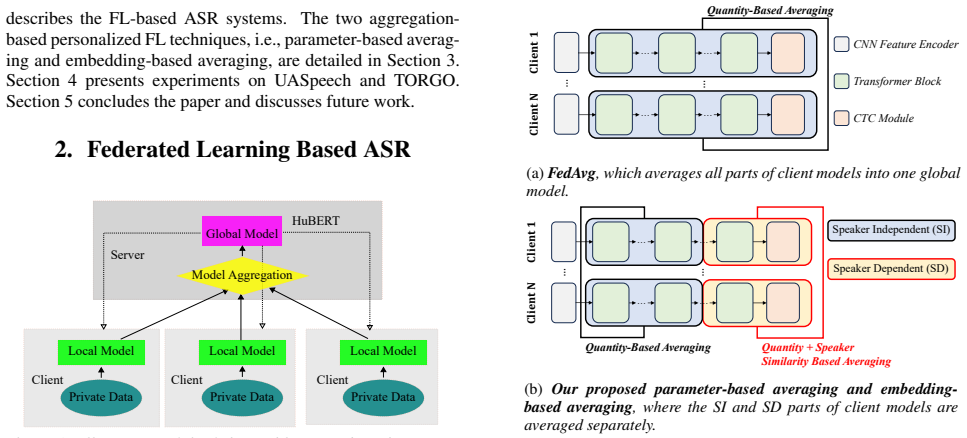
Federated Learning Based ASR Private Data Local Model Private Data Local Model Private Data Local Model Global Model Model Aggregation HuBERT Client Client Client Server Figure 1:Illustration of the federated learning based HuBERT ASR system. Each communication round includes:(a)aggre- gating the parameters of locally trained client-side models into a glo...
-
[3]
#$%&' …… !
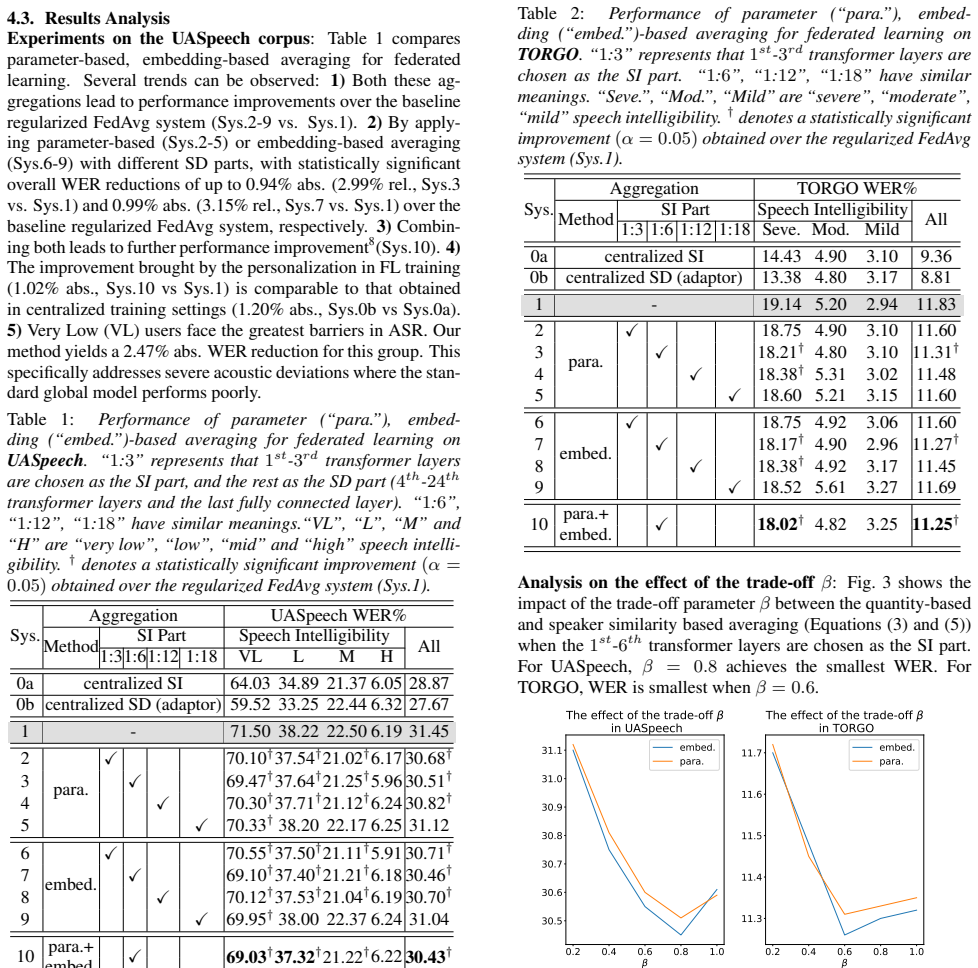
Personalized federated learning based ASR 3.1. Parameter-Based Averaging 1The SI components are positioned below the SD components to ensure that embedding similarity is evaluated within a unified vector encoding space defined by the SI components shared across all speakers (devices). …… !"#$%&' …… !"#$%&( CNNFeatureEncoderTransformerBlockCTCModule …… !"#...
-
[4]
very low
Experiments and Results 4.1. Task Description The English UASpeechcorpus [34] is the largest publicly available and widely used dataset for dysarthric speech recog- nition. It comprises an isolated word recognition task with ap- proximately 103 hours of speech data from 29 speakers, among whom 16 are dysarthric speakers and 13 are healthy control speakers...
-
[5]
These two strategies include the parameter-based and embedding-based averaging strategies
Conclusions This paper explores two aggregation strategies in federated learning to achieve personalization for dysarthric speech recog- nition. These two strategies include the parameter-based and embedding-based averaging strategies. Experiments on UASpeech and TORGO demonstrate the effectiveness. Future research will focus on aggregation strategies for...
-
[6]
14200021 and 14200324
Acknowledgments This research is supported by Hong Kong RGC GRF grant No. 14200021 and 14200324
-
[7]
Generative AI Use Disclosure Generative AI tools are used for proofreading and grammar cor- rection with minor changes
-
[8]
Speech-Transformer: A No- Recurrence Sequence-to-Sequence Model for Speech Recogni- tion,
L. Dong, S. Xu, and B. Xu, “Speech-Transformer: A No- Recurrence Sequence-to-Sequence Model for Speech Recogni- tion,” inICASSP, 2018
2018
-
[9]
Conformer: Convolution-augmented Transformer for Speech Recognition,
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y . Wu, and R. Pang, “Conformer: Convolution-augmented Transformer for Speech Recognition,” in INTERSPEECH, 2020
2020
-
[10]
In- vestigation of data augmentation techniques for disordered speech recognition,
M. Geng, X. Xie, S. Liu, J. Yu, S. Hu, X. Liu, and H. Meng, “In- vestigation of data augmentation techniques for disordered speech recognition,” inINTERSPEECH, 2025
2025
-
[11]
Speaker Adaptation Using Spectro-Temporal Deep Features for Dysarthric and Elderly Speech Recognition,
M. Geng, X. Xie, Z. Ye, T. Wang, G. Li, S. Hu, X. Liu, and H. Meng, “Speaker Adaptation Using Spectro-Temporal Deep Features for Dysarthric and Elderly Speech Recognition,” IEEE/ACM T-ASLP, 2022
2022
-
[12]
Acoustic modelling from raw source and filter components for dysarthric speech recognition,
Z. Yue, E. Loweimi, H. Christensen, J. Barker, and Z. Cvetkovic, “Acoustic modelling from raw source and filter components for dysarthric speech recognition,”IEEE/ACM T-ASLP, 2022
2022
-
[13]
Speaker adaptation for Wav2vec2 based dysarthric ASR,
M. K. Baskar, T. Herzig, D. Nguyen, M. Diez, T. Polzehl, L. Bur- get, and J. ˇCernock`y, “Speaker adaptation for Wav2vec2 based dysarthric ASR,” inINTERPSEECH, 2022
2022
-
[14]
Self-Supervised ASR Models and Features for Dysarthric and Elderly Speech Recognition,
S. Hu, X. Xie, M. Geng, Z. Jin, J. Deng, G. Li, Y . Wang, M. Cui, T. Wang, H. Meng, and X. Liu, “Self-Supervised ASR Models and Features for Dysarthric and Elderly Speech Recognition,” IEEE/ACM T-ASLP, 2024
2024
-
[15]
A Cluster-based Personalized Federated Learning Strategy for End-to-End ASR of Dementia Patients,
W.-T. Hsu, C.-P. Chen, Y .-S. Lin, and C.-C. Lee, “A Cluster-based Personalized Federated Learning Strategy for End-to-End ASR of Dementia Patients,” inINTERSPEECH, 2024
2024
-
[16]
Phone-purity Guided Discrete Tokens for Dysarthric Speech Recognition,
H. Wang, X. Xie, M. Geng, S. Hu, H. Xu, Y . Chen, Z. Li, J. Deng, and X. Liu, “Phone-purity Guided Discrete Tokens for Dysarthric Speech Recognition,”arXiv preprint arXiv:2501.04379, 2025
-
[17]
Personalized Adversarial Data Augmentation for Dysarthric and Elderly Speech Recognition,
Z. Jin, M. Geng, J. Deng, T. Wang, S. Hu, G. Li, and X. Liu, “Personalized Adversarial Data Augmentation for Dysarthric and Elderly Speech Recognition,”IEEE/ACM T-ASLP, 2023
2023
-
[18]
Enhancing Pre-trained ASR System Fine-tuning for Dysarthric Speech Recognition using Adversarial Data Augmen- tation,
H. Wang, Z. Jin, M. Geng, S. Hu, G. Li, T. Wang, H. Xu, and X. Liu, “Enhancing Pre-trained ASR System Fine-tuning for Dysarthric Speech Recognition using Adversarial Data Augmen- tation,” inICASSP, 2024
2024
-
[19]
Balancing privacy and progress: a review of privacy challenges, systemic oversight, and patient perceptions in AI-driven healthcare,
S. M. Williamson and V . Prybutok, “Balancing privacy and progress: a review of privacy challenges, systemic oversight, and patient perceptions in AI-driven healthcare,”Applied Sciences, 2024
2024
-
[20]
Communication-Efficient Learning of Deep Networks from Decentralized Data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Ar- cas, “Communication-Efficient Learning of Deep Networks from Decentralized Data,” inAISTATS, 2017
2017
-
[21]
Federated learning for keyword spotting,
D. Leroy, A. Coucke, T. Lavril, T. Gisselbrecht, and J. Dureau, “Federated learning for keyword spotting,” inICASSP, 2019
2019
-
[22]
Training keyword spot- ting models on non-iid data with federated learning,
A. Hard, K. Partridge, C. Nguyen, N. Subrahmanya, A. Shah, P. Zhu, I. L. Moreno, and R. Mathews, “Training keyword spot- ting models on non-iid data with federated learning,” inINTER- SPEECH, 2020
2020
-
[23]
Improving on-device speaker verification using feder- ated learning with privacy,
F. Granqvist, M. Seigel, R. van Dalen, ´Aine Cahill, S. Shum, and M. Paulik, “Improving on-device speaker verification using feder- ated learning with privacy,” inINTERSPEECH, 2020
2020
-
[24]
Stealthy back- door attack towards federated automatic speaker verification,
L. Zhang, L. Liu, D. Meng, J. Wang, and S. Hu, “Stealthy back- door attack towards federated automatic speaker verification,” in ICASSP, 2024
2024
-
[25]
Federated learning for speech emotion recognition applications,
S. Latif, S. Khalifa, R. Rana, and R. Jurdak, “Federated learning for speech emotion recognition applications,” inIPSN, 2020
2020
-
[26]
Semi-fedSER: Semi-supervised learning for speech emotion recognition on federated learning us- ing multiview pseudo-labeling,
T. Feng and S. Narayanan, “Semi-fedSER: Semi-supervised learning for speech emotion recognition on federated learning us- ing multiview pseudo-labeling,” inINTERSPEECH, 2022
2022
-
[27]
A federated approach in training acoustic mod- els
D. Dimitriadis, R. G. Ken’ichi Kumatani, R. Gmyr, Y . Gaur, and S. E. Eskimez, “A federated approach in training acoustic mod- els.” inINTERSPEECH, 2020
2020
-
[28]
Training speech recogni- tion models with federated learning: A quality/cost framework,
D. Guliani, F. Beaufays, and G. Motta, “Training speech recogni- tion models with federated learning: A quality/cost framework,” inICASSP, 2021
2021
-
[29]
Federated learning in ASR: Not as easy as you think,
W. Yu, J. Freiwald, S. Tewes, F. Huennemeyer, and D. Kolossa, “Federated learning in ASR: Not as easy as you think,” inITG SpeechCom, 2021
2021
-
[30]
Federated acoustic modeling for automatic speech recognition,
X. Cui, S. Lu, and B. Kingsbury, “Federated acoustic modeling for automatic speech recognition,” inICASSP, 2021
2021
-
[31]
Cross-silo federated train- ing in the cloud with diversity scaling and semi-supervised learn- ing,
K. Nandury, A. Mohan, and F. Weber, “Cross-silo federated train- ing in the cloud with diversity scaling and semi-supervised learn- ing,” inICASSP, 2021
2021
-
[32]
End-to-end speech recognition from federated acoustic models,
Y . Gao, T. Parcollet, S. Zaiem, J. Fernandez-Marques, P. P. de Gusmao, D. J. Beutel, and N. D. Lane, “End-to-end speech recognition from federated acoustic models,” inICASSP, 2022
2022
-
[33]
Importance of Smoothness Induced by Optimizers in FL4ASR: Towards Un- derstanding Federated Learning for End-to-End ASR,
S. S. Azam, T. Likhomanenko, M. Pelikanet al., “Importance of Smoothness Induced by Optimizers in FL4ASR: Towards Un- derstanding Federated Learning for End-to-End ASR,” inASRU, 2023
2023
-
[34]
Federated Learning for Speech Recog- nition: Revisiting Current Trends Towards Large-Scale ASR,
S. S. Azam, M. Pelikan, V . Feldman, K. Talwar, J. Silovsky, and T. Likhomanenko, “Federated Learning for Speech Recog- nition: Revisiting Current Trends Towards Large-Scale ASR,” in NeurIPS, 2023
2023
-
[35]
Communication-Efficient Personalized Federated Learning for Speech-to-Text Tasks,
Y . Du, Z. Zhang, L. Yue, X. Huang, Y . Zhang, T. Xu, L. Xu, and E. Chen, “Communication-Efficient Personalized Federated Learning for Speech-to-Text Tasks,” inICASSP, 2024
2024
-
[36]
Fair and Privacy-Preserving Alzheimer’s Disease Diagnosis Based on Spontaneous Speech Analysis via Federated Learning,
S. I. A. Meerza, Z. Li, L. Liu, J. Zhang, and J. Liu, “Fair and Privacy-Preserving Alzheimer’s Disease Diagnosis Based on Spontaneous Speech Analysis via Federated Learning,” inEMBC, 2022
2022
-
[37]
Federated learning for se- cure development of AI models for Parkinson’s disease detection using speech from different languages,
S. T. Arasteh, C. D. Rios-Urrego, E. Noeth, A. Maier, S. H. Yang, J. Rusz, and J. R. Orozco-Arroyave, “Federated learning for se- cure development of AI models for Parkinson’s disease detection using speech from different languages,” inINTERSPEECH, 2023
2023
-
[38]
Regularized Federated Learning for Privacy-Preserving Dysarthric and Elderly Speech Recognition,
T. Zhong, M. Geng, S. Hu, G. Li, and X. Liu, “Regularized Federated Learning for Privacy-Preserving Dysarthric and Elderly Speech Recognition,” inINTERSPEECH, 2025
2025
-
[39]
Toward a person- alized clustered federated learning: A speech recognition case study,
B. Farahani, S. Tabibian, and H. Ebrahimi, “Toward a person- alized clustered federated learning: A speech recognition case study,”IEEE Internet of Things Journal, pp. 18 553–18 562, 2023
2023
-
[40]
Joint federated learning and personalization for on- device asr,
J. Jia, K. Li, M. Malek, K. Malik, J. Mahadeokar, O. Kalinli, and F. Seide, “Joint federated learning and personalization for on- device asr,” inASRU, 2023
2023
-
[41]
Dysarthric speech database for universal access research
H. Kim, M. Hasegawa-Johnson, A. Perlman, J. R. Gunderson, T. S. Huang, K. L. Watkin, and S. Frame, “Dysarthric speech database for universal access research.” inINTERSPEECH, 2008
2008
-
[42]
The TORGO database of acoustic and articulatory speech from speakers with dysarthria,
F. Rudzicz, A. K. Namasivayam, and T. Wolff, “The TORGO database of acoustic and articulatory speech from speakers with dysarthria,”Language resources and evaluation, 2012
2012
-
[43]
Personalized feder- ated learning with theoretical guarantees: A model-agnostic meta- learning approach,
A. Fallah, A. Mokhtari, and A. Ozdaglar, “Personalized feder- ated learning with theoretical guarantees: A model-agnostic meta- learning approach,” inNeurIPS, 2020
2020
-
[44]
A survey on distributed machine learning,
J. Verbraeken, M. Wolting, J. Katzy, J. Kloppenburg, T. Verbelen, and J. S. Rellermeyer, “A survey on distributed machine learning,” CSUR, 2020
2020
-
[45]
Privacy amplification by subsampling: Tight analyses via couplings and divergences,
B. Balle, G. Barthe, and M. Gaboardi, “Privacy amplification by subsampling: Tight analyses via couplings and divergences,” in NeurIPS, 2018
2018
-
[46]
HuBERT: Self-Supervised Speech Rep- resentation Learning by Masked Prediction of Hidden Units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdi- nov, and A. Mohamed, “HuBERT: Self-Supervised Speech Rep- resentation Learning by Masked Prediction of Hidden Units,” IEEE/ACM T-ASLP, 2021
2021
-
[47]
Lib- rispeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: An ASR corpus based on public domain audio books,” inICASSP, 2015
2015
-
[48]
Con- nectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks,
A. Graves, S. Fern ´andez, F. Gomez, and J. Schmidhuber, “Con- nectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks,” inICML, 2006
2006
-
[49]
Bootstrap estimates for confidence inter- vals in asr performance evaluation,
M. Bisani and H. Ney, “Bootstrap estimates for confidence inter- vals in asr performance evaluation,” inICASSP, 2004
2004
-
[50]
Federated Optimization in Heterogeneous Networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated Optimization in Heterogeneous Networks,” inMLSys, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.