PragReST: Self-Reinforcing Counterfactual Reasoning for Pragmatic Language Understanding
Pith reviewed 2026-06-26 21:07 UTC · model grok-4.3
The pith
PragReST lets language models improve at pragmatic inference by training on self-generated counterfactual reasoning traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
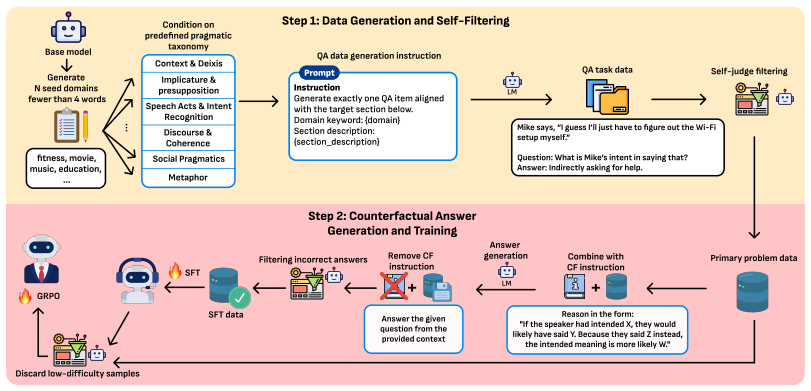
PragReST constructs pragmatic QA data, generates counterfactual reasoning traces that contrast observed utterances with plausible alternatives, and trains models through supervised fine-tuning and reinforcement learning to internalize those traces, yielding higher accuracy on pragmatic benchmarks without human-labeled data or distillation from stronger models.
What carries the argument
Counterfactual reasoning traces that explicitly contrast an observed utterance against plausible alternative utterances, serving as the training signal for pragmatic inference.
If this is right
- Pragmatic accuracy rises on benchmarks such as PragMega, Ludwig, MetoQA, and AltPrag compared with the base instruct models and with non-counterfactual versions of the same pipeline.
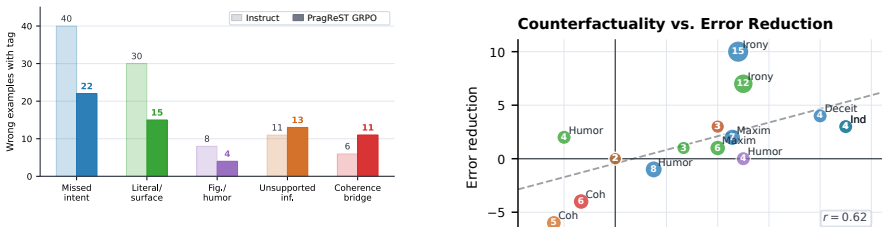
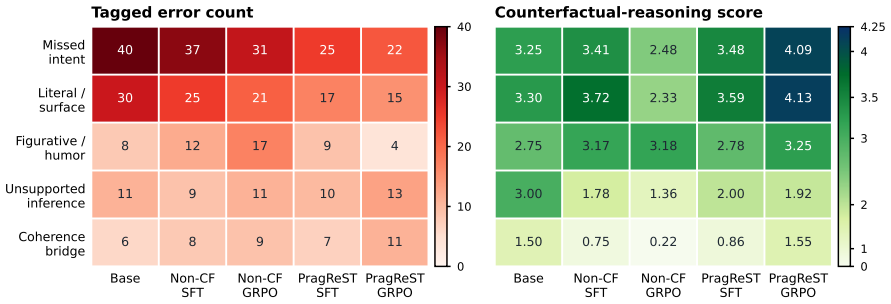
- Most of the error reduction occurs in cases where the model previously failed to consider plausible alternatives to the given utterance.
- Performance on out-of-domain general-knowledge and mathematical reasoning tasks stays stable after training.
- The same training procedure produces gains for both the 8B and 14B versions of the Qwen3 backbone.
Where Pith is reading between the lines
- Pragmatic reasoning may be bootstrapable through repeated self-generated contrast rather than requiring external supervision.
- The same self-reinforcement loop could be tested on other tasks that hinge on distinguishing literal from intended meaning, such as negotiation or sarcasm detection.
- If the generated traces contain systematic errors, the method might reinforce those errors; human verification of a sample of traces would be a direct way to check.
Load-bearing premise
The automatically generated counterfactual reasoning traces are accurate enough and free enough of bias to act as reliable training targets.
What would settle it
Replace the model's self-generated counterfactual traces with human-written ones of verified quality and measure whether the accuracy gains on pragmatic benchmarks remain, shrink, or disappear.
Figures


read the original abstract
Natural language understanding often depends on meanings that are implied rather than explicitly stated, requiring pragmatic reasoning. Despite strong performance on math and logical reasoning, large language models (LLMs) still struggle with making pragmatic inferences, often choosing literal interpretations. To improve LLM pragmatic reasoning, we introduce PragReST, a self-supervised framework that constructs pragmatic QA data, generates counterfactual reasoning traces, and trains models to internalize them through supervised fine-tuning and reinforcement learning, without human-labeled training data or distillation from a stronger teacher. Across four pragmatic benchmarks (PragMega, Ludwig, MetoQA, and AltPrag), PragReST improves over backbone models, task-specific pragmatic tuning baselines, and non-counterfactual variants of the same pipeline. On accuracy-based benchmarks, PragReST improves over the instruct backbone by 5.37 and 5.50% (absolute) for Qwen3-8B and Qwen3-14B, respectively. Our error analysis and ablations underscore the importance of counterfactual reasoning: PragReST primarily reduces errors caused by failures to contrast observed utterances with plausible alternatives, and removing counterfactual reasoning substantially reduces performance. Moreover, our training preserves out-of-domain performance on general-knowledge and mathematical reasoning benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PragReST, a self-supervised framework that constructs pragmatic QA data, generates counterfactual reasoning traces, and trains LLMs via supervised fine-tuning and reinforcement learning without human labels or teacher distillation. It reports absolute accuracy gains of 5.37% (Qwen3-8B) and 5.50% (Qwen3-14B) over instruct backbones on PragMega, Ludwig, MetoQA, and AltPrag, with ablations and error analysis attributing improvements to counterfactual reasoning and claiming preservation of out-of-domain performance on general and math benchmarks.
Significance. If the generated traces are shown to be reliable targets, the approach could meaningfully advance self-supervised methods for pragmatic inference, offering a scalable alternative to human annotation or distillation while addressing literal biases in LLMs.
major comments (2)
- [Experiments / Ablations] Experiments section (ablations and error analysis): the central claim that counterfactual reasoning drives the 5.37–5.50% gains rests on the assumption that self-generated traces are accurate and unbiased targets, yet no human ratings, expert annotations, or comparison against gold pragmatic inferences are reported to validate trace quality; without this, the ablation result (counterfactual removal hurts) and error analysis could reflect reinforcement of internal model biases rather than genuine pragmatic improvement.
- [Methods] Methods section (trace generation): the framework relies on automatically generated counterfactual reasoning traces as SFT/RL targets, but provides no protocol for assessing their consistency or fidelity to pragmatic contrasts; this internal-validity gap directly undermines the interpretation of benchmark gains as evidence of improved inference.
minor comments (2)
- [Abstract] Abstract: the reported percentage gains lack accompanying statistical tests, confidence intervals, or per-benchmark breakdowns, making it difficult to assess robustness.
- [Experiments] The out-of-domain preservation claim is stated but would benefit from explicit tables comparing pre- and post-training scores on the cited general-knowledge and math benchmarks.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments both concern the lack of direct validation for the quality of self-generated counterfactual traces. We address each below and indicate where partial revisions will be made to clarify limitations and strengthen the discussion of evidence.
read point-by-point responses
-
Referee: [Experiments / Ablations] Experiments section (ablations and error analysis): the central claim that counterfactual reasoning drives the 5.37–5.50% gains rests on the assumption that self-generated traces are accurate and unbiased targets, yet no human ratings, expert annotations, or comparison against gold pragmatic inferences are reported to validate trace quality; without this, the ablation result (counterfactual removal hurts) and error analysis could reflect reinforcement of internal model biases rather than genuine pragmatic improvement.
Authors: We acknowledge that the manuscript does not include human ratings or direct comparison of generated traces to gold pragmatic inferences. Because PragReST is designed as a fully self-supervised method that avoids human labels, such annotations were not collected. The primary evidence remains the consistent accuracy gains on four pragmatic benchmarks, the ablation showing that removing the counterfactual component reduces performance, and the error analysis linking gains to fewer failures to consider alternatives. Preservation of out-of-domain performance on general-knowledge and math benchmarks provides additional indication that the changes are not simply amplifying existing literal biases. We will revise the discussion section to explicitly note the absence of direct trace validation as a limitation and to clarify that benchmark results constitute indirect evidence. revision: partial
-
Referee: [Methods] Methods section (trace generation): the framework relies on automatically generated counterfactual reasoning traces as SFT/RL targets, but provides no protocol for assessing their consistency or fidelity to pragmatic contrasts; this internal-validity gap directly undermines the interpretation of benchmark gains as evidence of improved inference.
Authors: The manuscript does not describe an explicit protocol (e.g., consistency checks or fidelity metrics) for the automatically generated traces. Trace quality is evaluated only indirectly via downstream task accuracy, ablations, and error categorization. We agree this leaves an internal-validity gap. In revision we will add a short subsection or paragraph in the methods or limitations section describing the self-reinforcing RL procedure and acknowledging that direct fidelity assessment to gold contrasts is not performed, while reiterating that the pragmatic benchmarks serve as the external test of whether the overall pipeline improves inference. revision: partial
Circularity Check
No significant circularity; external benchmarks and self-supervised training remain independent
full rationale
The paper presents an empirical self-supervised pipeline that generates its own pragmatic QA data and counterfactual traces for SFT/RL training, then measures accuracy gains on four held-out external benchmarks (PragMega, Ludwig, MetoQA, AltPrag). No equation or claim reduces a reported performance number to a quantity defined by the training targets themselves; ablations compare variants of the same pipeline against the same external test sets. No self-citation load-bearing step, uniqueness theorem, or fitted-input-renamed-as-prediction is present. The central result (absolute gains of 5.37–5.50 %) is therefore not equivalent to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InFindings of the As- sociation for Computational Linguistics: ACL 2025, pages 5880–5895, Vienna, Austria
An Empirical Study of LLM-as-a-Judge for LLM Evaluation: Fine-tuned Judge Model is not a General Substitute for GPT-4. InFindings of the As- sociation for Computational Linguistics: ACL 2025, pages 5880–5895, Vienna, Austria. Association for Computational Linguistics. Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun,...
2025
-
[2]
Self-Training Meets Consistency: Improving LLMs’ Reasoning with Consistency-Driven Ratio- nale Evaluation. InProceedings of the 2025 Confer- ence of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 10519–10539, Albuquerque, New Mexico. As- sociation for Computa...
2025
-
[3]
InThe Twelfth Inter- national Conference on Learning Representations
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. TruthfulQA: Measuring how models mimic human falsehoods. InProceedings of the 60th Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214–3252, Dublin, Ireland. ...
Pith/arXiv arXiv 2022
-
[4]
On Synthesizing Data for Context Attribu- tion in Question Answering. InProceedings of the 63rd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 16929–16950, Vienna, Austria. Association for Com- putational Linguistics. Vyas Raina, Adian Liusie, and Mark Gales. 2024. Is LLM-as-a-Judge Robust? Investigating U...
Pith/arXiv arXiv 2024
-
[5]
InFindings of the Association for Computational Lin- guistics: ACL 2024, pages 12075–12097, Bangkok, Thailand
PUB: A Pragmatics Understanding Bench- mark for Assessing LLMs’ Pragmatics Capabilities. InFindings of the Association for Computational Lin- guistics: ACL 2024, pages 12075–12097, Bangkok, Thailand. Association for Computational Linguistics. Settaluri Lakshmi Sravanthi, Kishan Maharaj, Sravani Gunnu, Abhijit Mishra, and Pushpak Bhattacharyya
2024
-
[6]
Understand the Implication: Learning to Think for Pragmatic Understanding. InFindings of the As- sociation for Computational Linguistics: ACL 2025, pages 23778–23790, Vienna, Austria. Association for Computational Linguistics. Gaurav Srivastava, Zhenyu Bi, Meng Lu, and Xuan Wang. 2025. Debate, train, evolve: Self-evolution of language model reasoning. InP...
Pith/arXiv arXiv 2025
-
[7]
Identify the literal meaning of the utterance
-
[8]
Use the context and shared background to determine what the speaker is likely trying to communicate
-
[9]
Consider why the speaker chose this utterance instead of other plausible alternatives
-
[10]
Assume the speaker is trying to provide relevant information in context, but may not say more than is needed
-
[11]
Use the speaker’s likely knowledge and the shared context to infer what the listener is expected to understand
-
[12]
If the speaker had intended X, they would likely have said Y. Because they said Z instead, the intended meaning is more likely W
Choose the answer that best explains the utterance as a rational, informative, and contextually relevant choice. When possible, justify your interpretation contrastively until you reach one clear interpretation: - state one more direct, stronger, or more literal alternative the speaker could have said, - explain what that alternative would have implied, -...
2024
-
[13]
I want to wear that blue shirt, but it is very creased
The intended meaning is non-literal: Mary implies that the town is dirty or polluted. PRAGMEGA Scenario: Paul has to go to an interview and he is running late. While cleaning his shoes, he says to his wife Jane: “I want to wear that blue shirt, but it is very creased.” What might he be trying to convey? Options: 1) He wants his wife to iron his shirt. 2) ...
-
[14]
He’s as gentle as a lamb
Paul is making an indirect request for Jane to iron the shirt. LUDWIG Question: Is Marci grumpy? Response: “He’s as gentle as a lamb.” No. LUDWIGQuestion: You... live here? Response: “Long time. Long, long time.” Yes. METOQA Context: She is attracted to blue jacket. Question: What does “blue jacket” refer to? Options: 1) Colour 2) Jacket 3) Sailor 4) Sea
-
[15]
METOQA Context: His lovely voice caught my ear
Sailor. METOQA Context: His lovely voice caught my ear. Question: What does the sentence refer to? Options: 1) Giving attention 2) Noise 3) Whispering to the person 4) None
-
[16]
You have too much on your plate
Giving attention. ALTPRAG Context: A teacher is speaking with Sam about his assignments and commitments, noting that Sam might be overwhelmed. Root: “You have too much on your plate.” Candidate 1: “I appreciate your concern, but I think I can manage everything just fine.” Candidate 2: “It’s just how I like it; wouldn’t have it any other way.” Candidate 1 ...
-
[17]
if the speaker meant X, they would/could have said Y,
Explicit counterfactual. Assign 1 if the trace explicitly reasons about a counterfactual pragmatic or communicative alternative, e.g., “if the speaker meant X, they would/could have said Y,” “had she intended X,” or “if this were literal, we would expect . . . ”. Do not count generic uncertainty, ordinary causal hypotheses, or narrative-coherence alternat...
-
[18]
Assign 1 if the trace identifies an alternative wording, action, answer, or response that would be expected under a different intended meaning
Alternative utterance or action. Assign 1 if the trace identifies an alternative wording, action, answer, or response that would be expected under a different intended meaning
-
[19]
Mismatch or contrast. Assign 1 if the trace explicitly notes a mismatch or contrast between the literal/surface reading and contextual/pragmatic cues, or between an option and what the speaker or situation would normally imply
-
[20]
Assign 1 if the trace reasons about speaker/listener intent, social goal, politeness, deception, irony, indirectness, communicative purpose, or pragmatic meaning
Speaker intent or pragmatic goal. Assign 1 if the trace reasons about speaker/listener intent, social goal, politeness, deception, irony, indirectness, communicative purpose, or pragmatic meaning
-
[21]
pragmatic contrast
Literal vs. pragmatic contrast. Assign 1 if the trace explicitly contrasts literal meaning or face-value reading with intended, pragmatic, figurative, indirect, ironic, or non-literal meaning. Compute cf_score as the sum of the five binary fields, from 0 to 5. Question prompt: {FULL_PROMPT} Model reasoning trace: {REASONING} E Artifact Licenses Artifact /...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.