ParseFixer: An Agentic Framework for Document Parsing via Selective Multimodal Correction
Pith reviewed 2026-06-27 09:56 UTC · model grok-4.3
The pith
Selective multimodal correction after a stable backbone parser improves recovery of key document elements without rewriting reliable predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
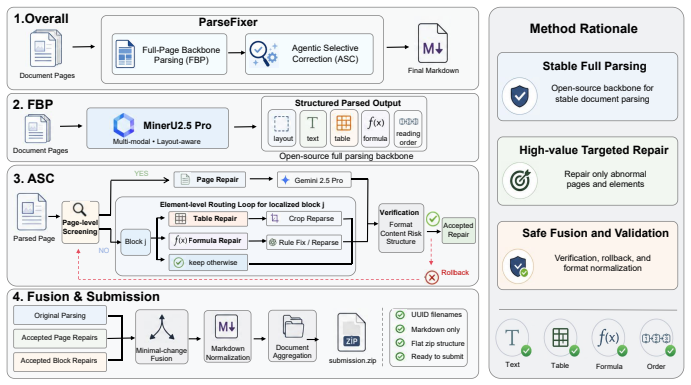
ParseFixer consists of Full-Page Backbone Parsing that produces initial Markdown outputs and Agentic Selective Correction that detects high-value parsing failures and repairs them through a verify-and-rollback correction process, thereby improving the recovery of key document elements without rewriting reliable backbone predictions.
What carries the argument
The Agentic Selective Correction module, which identifies important parsing failures in the backbone output and executes targeted multimodal repairs with rollback to avoid introducing new errors.
If this is right
- Initial backbone outputs remain stable because only selected failures are addressed rather than the entire page.
- Recovery of key document elements increases because corrections focus on high-value issues identified by the agentic process.
- Reliable predictions from the backbone are preserved because the correction includes a rollback mechanism.
- The overall output quality improves when the verify-and-rollback steps succeed on the chosen failures.
Where Pith is reading between the lines
- The selective approach could reduce the computational cost of full re-parsing by limiting multimodal calls to only problematic regions.
- Similar selective correction patterns might apply to other image-to-structure tasks where some output parts are already accurate.
- If the failure detection generalizes, the framework could be tested on documents with tables or figures that the backbone typically mishandles.
Load-bearing premise
The agentic module can reliably spot which parsing failures are worth fixing and correct them without creating new mistakes in the process.
What would settle it
A controlled comparison on the same test images showing that the selective correction step produces the same or lower overall quality scores than the backbone parser alone, or that corrected sections contain more errors than the original backbone output.
Figures



read the original abstract
In this report, we present our third-place solution for the DataMFM Challenge Track 1: Document Parsing. This track requires models to recover structured Markdown documents from document page images while preserving textual content and document structure. To address the complementary requirements of accurate content recovery and faithful structure reconstruction, we propose ParseFixer, an agentic framework for backbone parsing and selective correction. ParseFixer consists of two key modules: Full-Page Backbone Parsing (FBP) and Agentic Selective Correction (ASC). FBP produces stable initial Markdown outputs with MinerU2.5 Pro, while ASC detects high-value parsing failures and repairs them through a verify-and-rollback correction process. By placing selective multimodal correction after open-source backbone parsing, ParseFixer improves the recovery of key document elements without rewriting reliable backbone predictions. On the test set, our final system achieves an overall score of 61.78 and ranks third in Track 1, demonstrating its effectiveness for accurate document parsing. Our code will be released at: https://github.com/iLearn-Lab/CVPRW26-ParseFixer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ParseFixer as the authors' third-place entry in the DataMFM Challenge Track 1 on document parsing. The system comprises two modules: Full-Page Backbone Parsing (FBP) that generates initial Markdown from page images using MinerU2.5 Pro, and Agentic Selective Correction (ASC) that identifies high-value failures and applies verify-and-rollback multimodal repairs. The central claim is that selective correction after backbone parsing improves recovery of key elements without rewriting reliable predictions; the final test-set overall score is reported as 61.78.
Significance. If the selective-correction benefit can be quantified, the framework would illustrate a practical way to augment open-source parsers by targeting only high-value errors. The explicit commitment to release code at the cited GitHub repository is a clear strength for reproducibility.
major comments (2)
- [Abstract] Abstract: The claim that ASC 'improves the recovery of key document elements without rewriting reliable backbone predictions' is unsupported by any reported comparison to the MinerU2.5 Pro baseline score on the same test set or by ablation results that isolate the ASC contribution to the 61.78 score.
- [Abstract] Abstract: No definition of the 'overall score,' per-element error breakdown, rollback statistics, or analysis showing that ASC repairs failures without introducing new errors is supplied, leaving the weakest assumption (reliable identification and net-positive repair) unverified.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly stated the competition metric used for the 61.78 score.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and agree that the manuscript requires additional evidence to support the claims made in the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that ASC 'improves the recovery of key document elements without rewriting reliable backbone predictions' is unsupported by any reported comparison to the MinerU2.5 Pro baseline score on the same test set or by ablation results that isolate the ASC contribution to the 61.78 score.
Authors: We agree that the current manuscript does not include a direct comparison to the MinerU2.5 Pro baseline or ablations isolating the ASC contribution. The reported 61.78 is the challenge test-set score for the full system. In the revised manuscript we will add the baseline score on the same test set and an ablation study quantifying the selective correction benefit. revision: yes
-
Referee: [Abstract] Abstract: No definition of the 'overall score,' per-element error breakdown, rollback statistics, or analysis showing that ASC repairs failures without introducing new errors is supplied, leaving the weakest assumption (reliable identification and net-positive repair) unverified.
Authors: We will explicitly define the overall score according to the DataMFM Challenge metric in the revision. We will also add per-element error breakdowns, rollback statistics, and analysis of the verify-and-rollback process demonstrating that repairs are net-positive and do not introduce new errors. revision: yes
Circularity Check
No circularity detected; empirical system report with external competition score
full rationale
The paper describes an engineering system (FBP using MinerU2.5 Pro + ASC module) and reports its third-place result on an external competition test set (score 61.78). No equations, parameters, or derivations are present. No self-citations, fitted inputs renamed as predictions, or self-definitional steps exist. The central claim rests on the reported competition outcome rather than any internal reduction to the paper's own inputs. This is the expected non-finding for a competition report lacking mathematical content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 4, 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
PaddleOCR 3.0 Technical Report
Cheng Cui, Ting Sun, Manhui Lin, Tingquan Gao, Yubo Zhang, Jiaxuan Liu, Xueqing Wang, Zelun Zhang, Changda Zhou, Hongen Liu, et al. Paddleocr 3.0 technical report. arXiv preprint arXiv:2507.05595, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
PaddleOCR-VL-1.5: Towards a Multi-Task 0.9B VLM for Robust In-the-Wild Document Parsing
Cheng Cui, Ting Sun, Suyin Liang, Tingquan Gao, Zelun Zhang, Jiaxuan Liu, Xueqing Wang, Changda Zhou, Hongen Liu, Manhui Lin, et al. Paddleocr-vl-1.5: Towards a multi- task 0.9 b vlm for robust in-the-wild document parsing.arXiv preprint arXiv:2601.21957, 2026. 1, 6
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Doc-researcher: A unified system for multi- modal document parsing and deep research
Kuicai Dong, Shurui Huang, Fangda Ye, Wei Han, Zhi Zhang, Dexun Li, Wenjun Li, Qu Yang, Gang Wang, Yichao Wang, et al. Doc-researcher: A unified system for multi- modal document parsing and deep research. InProceedings of the ACM Web Conference 2026, pages 2349–2360, 2026. 1
2026
-
[5]
Glm-ocr technical report.arXiv preprint arXiv:2603.10910, 2026
Shuaiqi Duan, Yadong Xue, Weihan Wang, Zhe Su, Huan Liu, Sheng Yang, Guobing Gan, Guo Wang, Zihan Wang, Shengdong Yan, et al. Glm-ocr technical report.arXiv preprint arXiv:2603.10910, 2026. 1
-
[6]
Video moment localization via deep cross-modal hash- ing.IEEE Transactions on Image Processing, 30:4667– 4677, 2021
Yupeng Hu, Meng Liu, Xiaobin Su, Zan Gao, and Liqiang Nie. Video moment localization via deep cross-modal hash- ing.IEEE Transactions on Image Processing, 30:4667– 4677, 2021. 1
2021
-
[7]
Coarse-to-fine semantic align- ment for cross-modal moment localization.IEEE Transac- tions on Image Processing, 30:5933–5943, 2021
Yupeng Hu, Liqiang Nie, Meng Liu, Kun Wang, Yinglong Wang, and Xian-Sheng Hua. Coarse-to-fine semantic align- ment for cross-modal moment localization.IEEE Transac- tions on Image Processing, 30:5933–5943, 2021
2021
-
[8]
Semantic collaborative learning for cross-modal mo- ment localization.ACM Transactions on Information Sys- tems, 42(2):1–26, 2023
Yupeng Hu, Kun Wang, Meng Liu, Haoyu Tang, and Liqiang Nie. Semantic collaborative learning for cross-modal mo- ment localization.ACM Transactions on Information Sys- tems, 42(2):1–26, 2023. 1
2023
-
[9]
Visual self-paced iterative learning for un- supervised temporal action localization.ACM Transactions on Multimedia Computing, Communications and Applica- tions, 2026
Yupeng Hu, Han Jiang, Hao Liu, Kun Wang, Haoyu Tang, and Liqiang Nie. Visual self-paced iterative learning for un- supervised temporal action localization.ACM Transactions on Multimedia Computing, Communications and Applica- tions, 2026. 1
2026
-
[10]
From a glance to a boundary: Uncertainty- aware distillation for glance-supervised video moment local- ization.IEEE Transactions on Multimedia, 2026
Yupeng Hu, Hao Liu, Kun Wang, Ruping Cao, Yinwei Wei, and Liqiang Nie. From a glance to a boundary: Uncertainty- aware distillation for glance-supervised video moment local- ization.IEEE Transactions on Multimedia, 2026. 1
2026
-
[11]
Chartnet: A million-scale, high-quality multimodal dataset for robust chart understanding
Jovana Kondic, Pengyuan Li, Dhiraj Joshi, Isaac Sanchez, Ben Wiesel, Shafiq Abedin, Amit Alfassy, Eli Schwartz, Daniel Caraballo, Yagmur Gizem Cinar, et al. Chartnet: A million-scale, high-quality multimodal dataset for robust chart understanding. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 15922–15932, 2026. 1
2026
-
[12]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInterna- tional conference on machine learning, pages 12888–12900. PMLR, 2022. 1
2022
-
[13]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 1
2023
-
[14]
Dcount: Decoupled spatial perception and attribute discrimination for referring expression counting
Ming Li, Yupeng Hu, Yinwei Wei, Hao Liu, Haocong Wang, and Weili Guan. Dcount: Decoupled spatial perception and attribute discrimination for referring expression counting. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 5306–5315, 2025. 1
2025
-
[15]
Mist: Towards multi-dimensional implicit bias and stereotype evaluation of llms via theory of mind.arXiv e- prints, pages arXiv–2506, 2025
Yanlin Li, Hao Liu, Huimin Liu, Yinwei Wei, and Yupeng Hu. Mist: Towards multi-dimensional implicit bias and stereotype evaluation of llms via theory of mind.arXiv e- prints, pages arXiv–2506, 2025. 1
2025
-
[16]
Unim: A unified any-to- any interleaved multimodal benchmark
Yanlin Li, Minghui Guo, Kaiwen Zhang, Shize Zhang, Yiran Zhao, Haodong Li, Congyue Zhou, Weijie Zheng, Yushen Yan, Shengqiong Wu, et al. Unim: A unified any-to- any interleaved multimodal benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15902–15911, 2026. 1
2026
-
[17]
Gaming for boundary: Elastic localization for frame- supervised video moment retrieval
Hao Liu, Yupeng Hu, Kun Wang, Yinwei Wei, and Liqiang Nie. Gaming for boundary: Elastic localization for frame- supervised video moment retrieval. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 917–926,
-
[18]
Curmim: Curricu- lum masked image modeling
Hao Liu, Kun Wang, Yudong Han, Haocong Wang, Yupeng Hu, Chunxiao Wang, and Liqiang Nie. Curmim: Curricu- lum masked image modeling. InICASSP 2025-2025 IEEE International Conference on Acoustics, page 2041, 2025. 1
2025
-
[19]
ChartLens: A Dual-Branch Framework for Chart Data Correction and Factual Summary Refinement
Hao Liu, Ruping Cao, Kun Wang, Zhiran Li, Fan Liu, Yu- peng Hu, and Liqiang Nie. Chartlens: A dual-branch frame- work for chart data correction and factual summary refine- ment.arXiv preprint arXiv:2606.10640, 2026. 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
GPT-5.5 System Card.https://openai
OpenAI. GPT-5.5 System Card.https://openai. com/index/gpt- 5- 5- system- card/, 2026. Ac- cessed: 2026-06-06. 4, 5, 6, 7
2026
-
[21]
Omnidocbench: Benchmarking di- verse pdf document parsing with comprehensive annotations
Linke Ouyang, Yuan Qu, Hongbin Zhou, Jiawei Zhu, Rui Zhang, Qunshu Lin, Bin Wang, Zhiyuan Zhao, Man Jiang, Xiaomeng Zhao, et al. Omnidocbench: Benchmarking di- verse pdf document parsing with comprehensive annotations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24838–24848, 2025. 1, 5
2025
-
[22]
Bin Wang, Tianyao He, Linke Ouyang, Fan Wu, Zhiyuan Zhao, Tao Chu, Yuan Qu, Zhenjiang Jin, Weijun Zeng, Ziyang Miao, et al. Mineru2. 5-pro: Pushing the limits of data-centric document parsing at scale.arXiv preprint arXiv:2604.04771, 2026. 2, 5, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Explicit granularity and implicit scale corre- spondence learning for point-supervised video moment lo- calization
Kun Wang, Hao Liu, Lirong Jie, Zixu Li, Yupeng Hu, and Liqiang Nie. Explicit granularity and implicit scale corre- spondence learning for point-supervised video moment lo- calization. InProceedings of the 32nd ACM International Conference on Multimedia, pages 9214–9223, 2024. 1
2024
-
[24]
Redundancy mitigation: Towards accurate and efficient image-text retrieval.IEEE Transactions on Circuits and Sys- tems for Video Technology, 2025
Kun Wang, Yupeng Hu, Hao Liu, Lirong Jie, and Liqiang Nie. Redundancy mitigation: Towards accurate and efficient image-text retrieval.IEEE Transactions on Circuits and Sys- tems for Video Technology, 2025. 1
2025
-
[25]
Cross-modal representation shift refinement for point- supervised video moment retrieval.ACM Transactions on Information Systems, 44(3):1–30, 2026
Kun Wang, Yupeng Hu, Hao Liu, Jiang Shao, and Liqiang Nie. Cross-modal representation shift refinement for point- supervised video moment retrieval.ACM Transactions on Information Systems, 44(3):1–30, 2026. 1
2026
-
[26]
Dkdm: Data-free knowledge dis- tillation for diffusion models with any architecture
Qianlong Xiang, Miao Zhang, Yuzhang Shang, Jianlong Wu, Yan Yan, and Liqiang Nie. Dkdm: Data-free knowledge dis- tillation for diffusion models with any architecture. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2955–2965, 2025. 1
2025
-
[27]
Tina: Text-free inversion at- tack for unlearned text-to-image diffusion models
Qianlong Xiang, Miao Zhang, Haoyu Zhang, Kun Wang, Junhui Hou, and Liqiang Nie. Tina: Text-free inversion at- tack for unlearned text-to-image diffusion models. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 30076–30086, 2026. 1
2026
-
[28]
Wenwen Yu, Zhibo Yang, Jianqiang Wan, Sibo Song, Jun Tang, Wenqing Cheng, Yuliang Liu, and Xiang Bai. Om- niparser v2: Structured-points-of-thought for unified visual text parsing and its generality to multimodal large language models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026. 1
2026
-
[29]
Cogcn: co-occurring item- aware gcn for recommendation.Neural computing and ap- plications, 35(36):25107–25120, 2023
Xinxiao Zhao, Fan Liu, Hao Liu, Mingzhu Xu, Haoyu Tang, Xueqing Li, and Yupeng Hu. Cogcn: co-occurring item- aware gcn for recommendation.Neural computing and ap- plications, 35(36):25107–25120, 2023. 1 ParseFixer: An Agentic Framework for Document Parsing via Selective Multimodal Correction Supplementary Material
2023
-
[30]
Prompt Details This supplementary material provides the prompt templates used in ParseFixer for DataMFM Challenge Track 1: Docu- ment Parsing.All prompts follow the same principle: output Markdown or the required element format only, preserve visible document content, avoid explanations or summaries, and reject unsupported additions through verification a...
-
[31]
- Do not output explanations
Output Markdown only. - Do not output explanations. - Do not output analysis. - Do not wrap the answer in ‘‘‘markdown or any code fence. - Do not include metadata such as filename, page number, or confidence unless it is visibly part of the document content
-
[32]
- Paragraphs must be separated by a blank line
Text: - Use standard Markdown syntax. - Paragraphs must be separated by a blank line. - Preserve the original text as faithfully as possible. - Do not invent missing or unreadable content
-
[33]
- Display/block formulas must be wrapped with $$...$$
Formulas: - Use LaTeX syntax. - Display/block formulas must be wrapped with $$...$$. - Inline formulas must be wrapped with $ ...$. - Do not use \\[...\\] or \\(...\\) delimiters
-
[34]
- Standard Markdown pipe tables are also acceptable for simple tables
Tables: - Prefer HTML <table> format, especially for complex tables or merged cells. - Standard Markdown pipe tables are also acceptable for simple tables. - Preserve row/column structure as accurately as possible. - Use rowspan/colspan in HTML tables when cell merging is visible
-
[35]
- For multi-column pages, read each column in the correct order
Reading order: - Arrange all elements in natural reading order. - For multi-column pages, read each column in the correct order. - Keep captions close to their corresponding figures/tables when visible
-
[36]
# ". - Use
Headings: - If a line is visually a title, section heading, chapter heading, category heading, or subsection heading, prefix it with "# ". - Use "# " for all heading lines, not "##" or "###". - Do not add "# " to normal body paragraphs
-
[37]
Lists: - Use Markdown bullet or numbered lists when the document visibly contains lists
-
[38]
- Do not invent a description for a figure if no caption or relevant text is visible
Figures and captions: - Transcribe visible captions. - Do not invent a description for a figure if no caption or relevant text is visible
-
[39]
Headers, footers, and page numbers: - Omit repeated decorative headers, footers, and page numbers unless they are meaningful document content
-
[40]
Unreadable text: - If text is too blurry or unreadable, omit it rather than guessing
-
[41]
No text found
Empty / non-document image: - If the image contains no readable document text, table, formula, caption, or meaningful document content, output an empty Markdown file. - Do not write explanations such as "No text found", "No readable content", or "The image contains no text". """ USER_PROMPT = """Convert this document page image into Markdown. Remember: - ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.