TaskNPoint: How to Teach Your Humanoid to Hit a Backhand in Minutes
Pith reviewed 2026-06-26 01:55 UTC · model grok-4.3
The pith
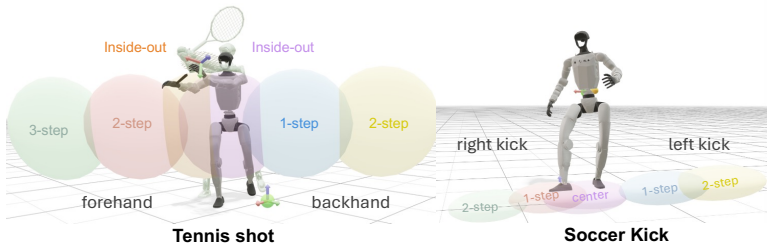
Dynamic humanoid skills reduce to mastering a few actions until a short human-identified interaction window is hit correctly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
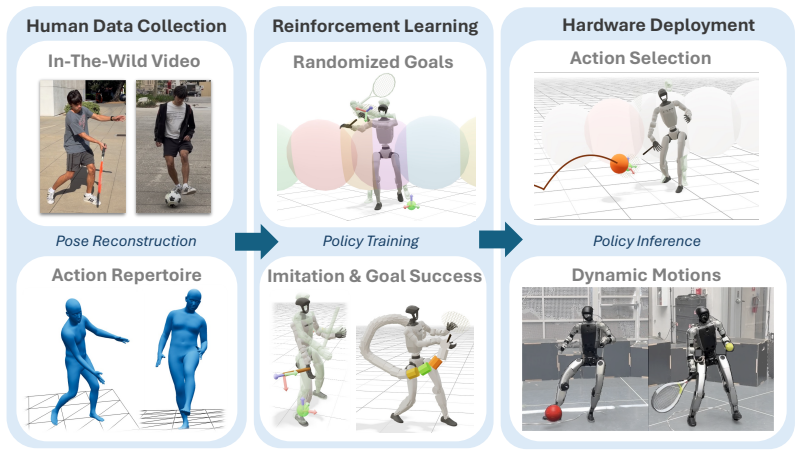
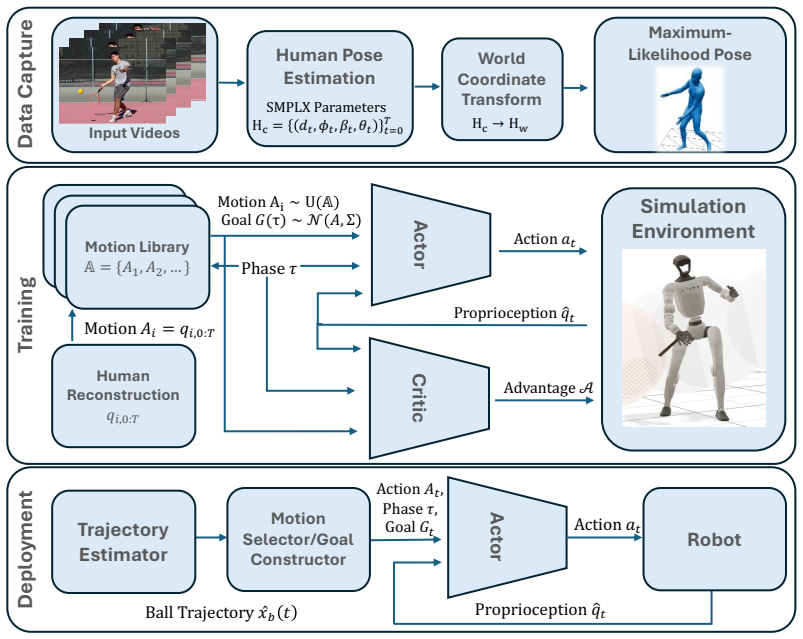
The outcome of dynamic skills is decided by a short, crucial portion of the trajectory. Learning thus reduces to mastering a handful of distinct actions and, for each, practicing until the interaction window comes out right. TaskNPoint makes the coach-learner division explicit: the human contributes a discrete set of skills, one demonstration per skill, identification of the interaction window, and the goal; learning in a physically realistic simulation environment fills in each action trajectory and provides robustness to unmodeled events, with randomized target sampling enabling zero-shot generalization to unseen goal locations.
What carries the argument
TaskNPoint training protocol, which uses the human coach's identification of the short interaction window that decides the outcome to focus simulation-based practice on coordinating the full motion so control, physics, and morphology align at that window.
If this is right
- A single human video demonstration per skill suffices when the interaction window is supplied.
- Randomized target sampling during training produces zero-shot generalization to unseen goal locations.
- No per-task reward tuning is required for successful policy learning across multiple skills.
- Policies learned this way transfer from simulation to the physical Unitree G1 for real dynamic tasks.
- The same protocol applies to other skills whose outcomes hinge on a brief interaction segment.
Where Pith is reading between the lines
- If interaction window identification can be automated from video, the method could scale to larger skill sets with less human time.
- The coach-learner split may serve as a template for efficient learning of other dynamic tasks on different robot platforms.
- Combining the protocol with stronger domain randomization could further improve robustness when simulation-reality gaps are larger.
- Success on contact-rich tasks suggests the window-focused approach could help with locomotion or other whole-body dynamic behaviors.
Load-bearing premise
The human coach can correctly identify the short interaction window that decides the outcome for each skill, and the simulation is realistic enough for the learned policies to transfer to the physical robot.
What would settle it
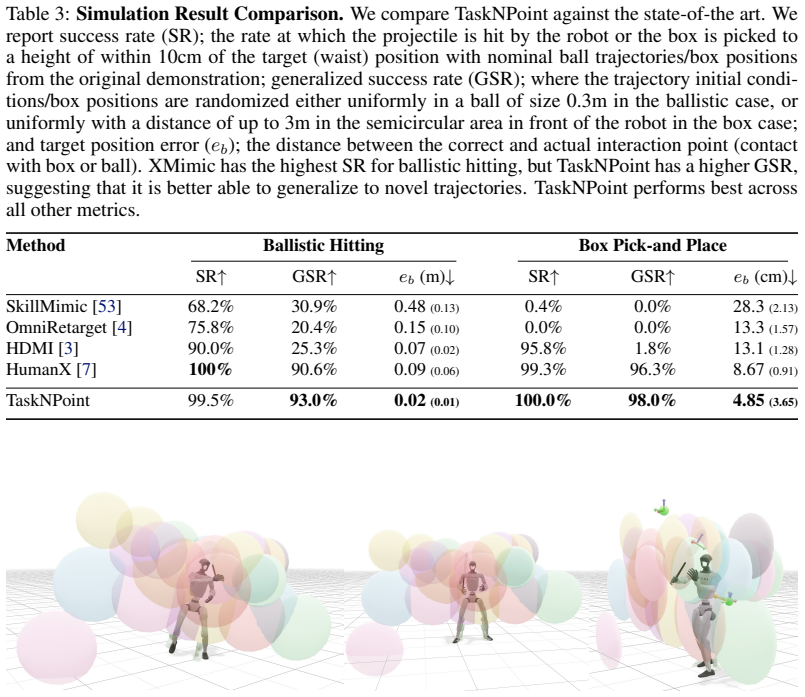
A test on the physical Unitree G1 where the robot fails to hit balls or place boxes at novel locations after the described short simulation training from one human demo per skill and the identified windows.
Figures


read the original abstract
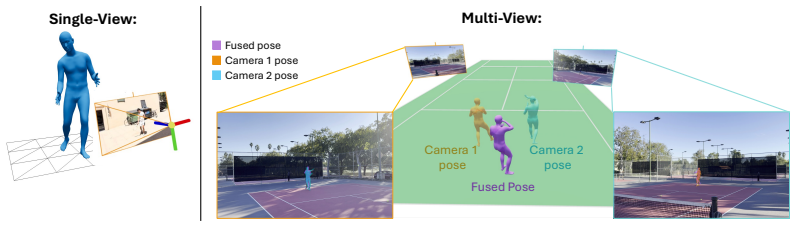
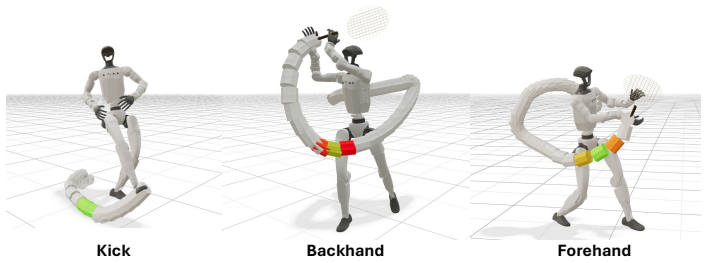
How do we learn to hit a tennis backhand? Not from a thousand hours of tennis tournaments on TV - we work with a coach and practice. We argue this is also the right recipe for teaching dynamic skills to humanoid robots. This follows from a structural property of dynamic skills: the outcome is decided by a short, crucial portion of the trajectory - for a backhand, the ~20cm of racket travel around ball contact. Getting this interaction window right requires coordinating the whole motion, so that control, physics, and morphology act in concert. Learning thus reduces to mastering a handful of distinct actions and, for each, practicing until the window comes out right. To this end, we introduce TaskNPoint, a training protocol which makes the coach-learner division of labor explicit. The human coach contributes four inputs: a discrete set of skills (e.g. different shots), one demonstration per skill, identification of the interaction window, and the goal. Learning in a physically realistic simulation environment fills in each action trajectory and provides robustness to unmodeled events. Crucially, randomized target sampling during training lets a single demonstration generalize zero-shot to unseen goal locations. We test this approach on a Unitree G1 humanoid that hits forehands and backhands against balls thrown by a human, kicks incoming soccer balls, and picks and places boxes from novel locations. We find that learning is successful from short human video demonstrations and under an hour of training on a single GPU, with no per-task reward tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that dynamic skills for humanoid robots are determined by short interaction windows (e.g., ~20 cm of racket travel at ball contact), so learning reduces to a human coach supplying a discrete skill set, one video demo per skill, window identification, and goal; simulation training with randomized target sampling then fills in trajectories and enables zero-shot generalization to novel locations. The TaskNPoint protocol is tested on a Unitree G1 for forehand/backhand tennis shots, soccer kicks, and box pick-and-place, reporting success from short human demos and <1 hour of single-GPU training with no per-task reward tuning.
Significance. If the real-robot results hold with adequate quantification, the work would be significant for lowering the barrier to dynamic skill acquisition on humanoids by replacing reward engineering with explicit human-provided structure and randomized sampling. The zero-shot generalization via target randomization is a concrete, falsifiable strength that directly supports the central claim.
major comments (2)
- [Abstract] Abstract: the claim of 'successful' real-robot tests on the Unitree G1 is load-bearing for the central claim yet supplies no quantitative success rates, trial counts, baselines, error bars, or failure-mode statistics; without these the transfer from simulation to physical robot cannot be assessed.
- [Method] Method (TaskNPoint protocol): the human coach's identification of the interaction window is presented as a key input, but no sensitivity analysis, ablation, or robustness test is reported on how mis-specified windows affect policy learning or sim-to-real transfer; this assumption is load-bearing for the 'handful of actions + practice' reduction.
minor comments (1)
- [Abstract] The abstract states 'under an hour of training on a single GPU' but does not specify the exact GPU model, batch size, or whether this includes data collection time; add these details for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'successful' real-robot tests on the Unitree G1 is load-bearing for the central claim yet supplies no quantitative success rates, trial counts, baselines, error bars, or failure-mode statistics; without these the transfer from simulation to physical robot cannot be assessed.
Authors: We agree that the abstract must include quantitative metrics to allow assessment of sim-to-real transfer. We will revise the abstract to report success rates, trial counts, and failure statistics for the Unitree G1 experiments on tennis shots, soccer kicks, and box pick-and-place. revision: yes
-
Referee: [Method] Method (TaskNPoint protocol): the human coach's identification of the interaction window is presented as a key input, but no sensitivity analysis, ablation, or robustness test is reported on how mis-specified windows affect policy learning or sim-to-real transfer; this assumption is load-bearing for the 'handful of actions + practice' reduction.
Authors: The interaction window is a load-bearing human input. We acknowledge the absence of sensitivity analysis in the submitted manuscript. We will add a dedicated discussion of robustness to window mis-specification together with an ablation study on window placement in the revised version. revision: yes
Circularity Check
No significant circularity; method defined by explicit external inputs
full rationale
The paper introduces TaskNPoint as a protocol whose inputs are four explicit human contributions (discrete skills, one demo per skill, interaction window identification, goal) plus simulation practice; the central claim that outcomes are decided by short interaction windows is presented as an observed structural property of the skills rather than derived from any fitted quantity or self-referential equation. No equations appear, no parameters are fitted to subsets and then relabeled as predictions, and no load-bearing self-citations or uniqueness theorems are invoked. The approach is therefore self-contained against external benchmarks (human video demos, GPU training, physical transfer) without any step reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The outcome of dynamic skills is decided by a short, crucial portion of the trajectory (the interaction window).
Reference graph
Works this paper leans on
-
[1]
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021
Pith/arXiv arXiv 2021
-
[2]
A. Allshire, H. Choi, J. Zhang, D. McAllister, A. Zhang, C. M. Kim, T. Darrell, P. Abbeel, J. Malik, and A. Kanazawa. Visual imitation enables contextual humanoid control.arXiv preprint arXiv:2505.03729, 2025
arXiv 2025
-
[3]
H. Weng, Y . Li, N. Sobanbabu, Z. Wang, Z. Luo, T. He, D. Ramanan, and G. Shi. Hdmi: Learning interactive humanoid whole-body control from human videos.arXiv preprint arXiv:2509.16757, 2025
arXiv 2025
-
[4]
L. Yang, X. Huang, Z. Wu, A. Kanazawa, P. Abbeel, C. Sferrazza, C. K. Liu, R. Duan, and G. Shi. Omniretarget: Interaction-preserving data generation for humanoid whole-body loco- manipulation and scene interaction.arXiv preprint arXiv:2509.26633, 2025
Pith/arXiv arXiv 2025
- [5]
-
[6]
Z. Su, B. Zhang, N. Rahmanian, Y . Gao, Q. Liao, C. Regan, K. Sreenath, and S. S. Sastry. Hitter: A humanoid table tennis robot via hierarchical planning and learning.arXiv preprint arXiv:2508.21043, 2025
arXiv 2025
-
[7]
Y . Wang, Q. Zhao, Y . F. Lau, R. Yu, H. W. Tsui, Q. Chen, J. Wang, J. Pang, and P. Tan. Humanx: Toward agile and generalizable humanoid interaction skills from human videos.arXiv preprint arXiv:2602.02473, 2026
arXiv 2026
-
[8]
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics (ToG), 40(4): 1–20, 2021
2021
-
[9]
X. B. Peng, P. Abbeel, S. Levine, and M. Van de Panne. Deepmimic: Example-guided deep re- inforcement learning of physics-based character skills.ACM Transactions On Graphics (TOG), 37(4):1–14, 2018
2018
-
[10]
Q. Liao, T. E. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion.arXiv preprint arXiv:2508.08241, 2025
Pith/arXiv arXiv 2025
-
[11]
Hwangbo, J
J. Hwangbo, J. Lee, and M. Hutter. Per-contact iteration method for solving contact dynamics. IEEE Robotics and Automation Letters, 3(2):895–902, 2018
2018
-
[12]
Rudin, D
N. Rudin, D. Hoeller, P. Reist, and M. Hutter. Learning to walk in minutes using massively parallel deep reinforcement learning. InConference on robot learning, pages 91–100. PMLR, 2022
2022
-
[13]
Haarnoja, B
T. Haarnoja, B. Moran, G. Lever, S. H. Huang, D. Tirumala, J. Humplik, M. Wulfmeier, S. Tun- yasuvunakool, N. Y . Siegel, R. Hafner, et al. Learning agile soccer skills for a bipedal robot with deep reinforcement learning.Science Robotics, 9(89):eadi8022, 2024. 13
2024
-
[14]
Y . Ma, A. Cramariuc, F. Farshidian, and M. Hutter. Learning coordinated badminton skills for legged manipulators.Science robotics, 10(102):eadu3922, 2025
2025
-
[15]
H. Wang, Z. Wang, J. Ren, Q. Ben, T. Huang, W. Zhang, and J. Pang. Beamdojo: Learning agile humanoid locomotion on sparse footholds.arXiv preprint arXiv:2502.10363, 2025
arXiv 2025
-
[16]
Z. Wu, X. Huang, L. Yang, Y . Zhang, K. Sreenath, X. Chen, P. Abbeel, R. Duan, A. Kanazawa, C. Sferrazza, et al. Perceptive humanoid parkour: Chaining dynamic human skills via motion matching.arXiv preprint arXiv:2602.15827, 2026
Pith/arXiv arXiv 2026
-
[17]
Y . Ze, S. Zhao, W. Wang, A. Kanazawa, R. Duan, P. Abbeel, G. Shi, J. Wu, and C. K. Liu. Twist2: Scalable, portable, and holistic humanoid data collection system.arXiv preprint arXiv:2511.02832, 2025
arXiv 2025
-
[18]
R. Yu, H. Park, and J. Lee. Human dynamics from monocular video with dynamic camera movements.ACM Transactions on Graphics (TOG), 40(6):1–14, 2021
2021
-
[19]
Z. Luo, J. Cao, J. Merel, A. Winkler, J. Huang, K. Kitani, and W. Xu. Universal humanoid motion representations for physics-based control. InInternational Conference on Learning Representations, volume 2024, pages 56766–56782, 2024
2024
-
[20]
S. Peng, Y . Zhang, Y . Xu, Q. Wang, Q. Shuai, H. Bao, and X. Zhou. Neural body: Implicit neu- ral representations with structured latent codes for novel view synthesis of dynamic humans. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9054–9063, 2021
2021
-
[21]
G. Moon, T. Shiratori, and S. Saito. Expressive whole-body 3d gaussian avatar. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024
2024
-
[22]
Rajasegaran, G
J. Rajasegaran, G. Pavlakos, A. Kanazawa, and J. Malik. Tracking people by predicting 3d appearance, location and pose. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2740–2749, 2022
2022
-
[23]
D. C. Luvizon, D. Picard, and H. Tabia. 2d/3d pose estimation and action recognition using multitask deep learning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5137–5146, 2018
2018
-
[24]
Rajasegaran, G
J. Rajasegaran, G. Pavlakos, A. Kanazawa, C. Feichtenhofer, and J. Malik. On the benefits of 3d pose and tracking for human action recognition. InProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, pages 640–649, 2023
2023
-
[25]
H. Choi, G. Moon, J. Y . Chang, and K. M. Lee. Beyond static features for temporally consistent 3d human pose and shape from a video, 2021. URLhttps://arxiv.org/abs/2011.08627
arXiv 2021
-
[26]
Kanazawa, J
A. Kanazawa, J. Y . Zhang, P. Felsen, and J. Malik. Learning 3d human dynamics from video,
-
[27]
URLhttps://arxiv.org/abs/1812.01601
-
[28]
Y . Wang, Y . Sun, P. Patel, K. Daniilidis, M. J. Black, and M. Kocabas. Prompthmr: Promptable human mesh recovery, 2025. URLhttps://arxiv.org/abs/2504.06397
arXiv 2025
-
[29]
Y . Wang, Z. Wang, L. Liu, and K. Daniilidis. Tram: Global trajectory and motion of 3d humans from in-the-wild videos, 2024. URLhttps://arxiv.org/abs/2403.17346
arXiv 2024
-
[30]
Z. Shen, H. Pi, Y . Xia, Z. Cen, S. Peng, Z. Hu, H. Bao, R. Hu, and X. Zhou. World-grounded human motion recovery via gravity-view coordinates. InSIGGRAPH Asia 2024 Conference Papers, SA ’24, page 1–11. ACM, Dec. 2024. doi:10.1145/3680528.3687565. URLhttp: //dx.doi.org/10.1145/3680528.3687565
-
[31]
J. Li, J. Cao, H. Zhang, D. Rempe, J. Kautz, U. Iqbal, and Y . Yuan. Genmo: A generalist model for human motion, 2025. URLhttps://arxiv.org/abs/2505.01425. 14
arXiv 2025
-
[32]
Yuan, S.-E
Y . Yuan, S.-E. Wei, T. Simon, K. Kitani, and J. Saragih. Simpoe: Simulated character control for 3d human pose estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7159–7169, 2021
2021
-
[33]
Y . Yuan, V . Makoviychuk, Y . Guo, S. Fidler, X. Peng, and K. Fatahalian. Learning physically simulated tennis skills from broadcast videos.ACM Trans. Graph, 42(4):66, 2023
2023
-
[34]
Ugrinovic, B
N. Ugrinovic, B. Pan, G. Pavlakos, D. Paschalidou, B. Shen, J. Sanchez-Riera, F. Moreno- Noguer, and L. Guibas. Multiphys: Multi-person physics-aware 3d motion estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2331–2340, 2024
2024
-
[35]
Zhang, Y
S. Zhang, Y . Zhang, F. Bogo, M. Pollefeys, and S. Tang. Learning motion priors for 4d human body capture in 3d scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11343–11353, 2021
2021
-
[36]
J. Li, S. Bian, C. Xu, G. Liu, G. Yu, and C. Lu. D &d: Learning human dynamics from dynamic camera. InEuropean Conference on Computer Vision, pages 479–496. Springer, 2022
2022
-
[37]
Q. Wang, M. Zhu, R. Hou, K. Gillespie, A. Zhu, S. Wang, Y . Wang, G. I. Fernandez, Y . Liu, C. Togashi, et al. A hierarchical, model-based system for high-performance humanoid soccer. arXiv preprint arXiv:2512.09431, 2025
arXiv 2025
-
[38]
J. Ren, J. Long, T. Huang, H. Wang, Z. Wang, F. Jia, W. Zhang, J. Wang, P. Luo, and J. Pang. Humanoid goalkeeper: Learning from position conditioned task-motion constraints.arXiv preprint arXiv:2510.18002, 2025
arXiv 2025
-
[39]
Z. Luo, J. Wang, K. Liu, H. Zhang, C. Tessler, J. Wang, Y . Yuan, J. Cao, Z. Lin, F. Wang, et al. Smplolympics: Sports environments for physically simulated humanoids.arXiv preprint arXiv:2407.00187, 2024
arXiv 2024
-
[40]
Liu and J
L. Liu and J. Hodgins. Learning basketball dribbling skills using trajectory optimization and deep reinforcement learning.Acm transactions on graphics (tog), 37(4):1–14, 2018
2018
-
[41]
C. Liu, L. Jiang, Y . Wang, K. Yao, J. Fu, and X. Ren. Humanoid whole-body badminton via multi-stage reinforcement learning.arXiv preprint arXiv:2511.11218, 2025
Pith/arXiv arXiv 2025
-
[42]
M. Kim, E. Jung, and Y . Lee. Physicsfc: Learning user-controlled skills for a physics-based football player controller.ACM Transactions on Graphics (TOG), 44(4):1–21, 2025
2025
-
[43]
Y . Chen, S. Dong, X. Ji, J. Sun, Z. Luo, L. Zhao, J. Zhang, W. Li, J. Ma, B. Xu, et al. Learning human-like badminton skills for humanoid robots.arXiv preprint arXiv:2602.08370, 2026
arXiv 2026
-
[44]
S. Calinon and A. G. Billard. What is the teacher’s role in robot programming by demonstra- tion? – toward benchmarks for improved learning.Interaction Studies, 8(3):441–464, 2007. doi:10.1075/is.8.3.08cal
-
[45]
C. L. Nehaniv and K. Dautenhahn. The correspondence problem. In K. Dautenhahn and C. L. Nehaniv, editors,Imitation in Animals and Artifacts, pages 41–61. MIT Press, Cambridge, MA, 2002. ISBN 9780262042031
2002
-
[46]
G. Pavlakos, V . Choutas, N. Ghorbani, T. Bolkart, A. A. A. Osman, D. Tzionas, and M. J. Black. Expressive body capture: 3d hands, face, and body from a single image, 2019. URL https://arxiv.org/abs/1904.05866
Pith/arXiv arXiv 2019
- [47]
-
[48]
I. Demler, X. Xie, B. Werner, A. Szczuka, and P. Perona. Caltennis: Large multi-view tennis video dataset and benchmark of monocular-to-3d pose estimation, 2026. URLhttps:// arxiv.org/abs/2606.20542
Pith/arXiv arXiv 2026
-
[49]
J. P. Araujo, Y . Ze, P. Xu, J. Wu, and C. K. Liu. Retargeting matters: General motion retargeting for humanoid motion tracking.arXiv preprint arXiv:2510.02252, 2025
arXiv 2025
-
[50]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[51]
A. Bronars, Y . Park, and P. Agrawal. Tune to learn: How controller gains shape robot policy learning.arXiv preprint arXiv:2604.02523, 2026
Pith/arXiv arXiv 2026
-
[52]
Welch, G
G. Welch, G. Bishop, et al. An introduction to the kalman filter. 1995
1995
-
[53]
Nguyen, K
D. Nguyen, K. D. Cancio, and S. Kim. High speed robotic table tennis swinging using lightweight hardware with model predictive control. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15278–15284. IEEE, 2025
2025
-
[54]
Y . Wang, Q. Zhao, R. Yu, H. W. Tsui, A. Zeng, J. Lin, Z. Luo, J. Yu, X. Li, Q. Chen, et al. Skillmimic: Learning basketball interaction skills from demonstrations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17540–17549, 2025
2025
-
[55]
Y . Xu, J. Zhang, Q. Zhang, and D. Tao. Vitpose: Simple vision transformer baselines for human pose estimation, 2022. URLhttps://arxiv.org/abs/2204.12484
arXiv 2022
-
[56]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V . Alwala, N. Carion, C.-Y . Wu, R. Girshick, P. Doll ´ar, and C. Feichtenhofer. Sam 2: Segment anything in images and videos, 2024. URLhttps: //arxiv.org/abs/2408.00714
Pith/arXiv arXiv 2024
-
[57]
Teed and J
Z. Teed and J. Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras,
-
[58]
URLhttps://arxiv.org/abs/2108.10869
-
[59]
S. F. Bhat, R. Birkl, D. Wofk, P. Wonka, and M. M ¨uller. Zoedepth: Zero-shot transfer by combining relative and metric depth, 2023. URLhttps://arxiv.org/abs/2302.12288
Pith/arXiv arXiv 2023
-
[60]
K. Zakka, Q. Liao, B. Yi, L. L. Lay, K. Sreenath, and P. Abbeel. mjlab: A lightweight frame- work for gpu-accelerated robot learning.arXiv preprint arXiv:2601.22074, 2026. 16 A Notation Table Table 4: Notation and Definitions Variable Definition Video capture and camera calibration NNumber of cameras capturing the scene ci Thei-th camera V i Video collect...
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.