Labeling Training Data for Entity Matching Using Large Language Models
Pith reviewed 2026-06-30 09:53 UTC · model grok-4.3
The pith
LLM-labeled training sets let student entity matchers perform within two F1 points of models trained on human-labeled benchmark data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
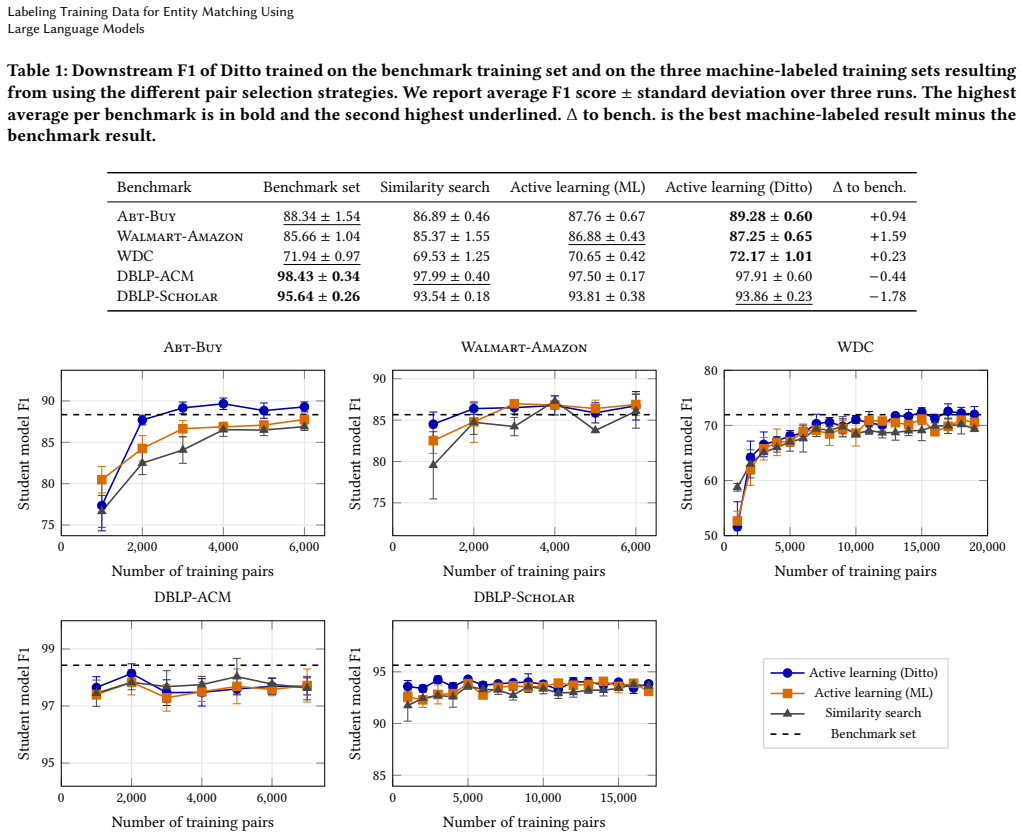
An LLM teacher labels candidate pairs chosen by a selection strategy; after post-processing the labels, the resulting training sets allow small language models to reach F1 scores within two points of the same models trained on the benchmark training sets across Abt-Buy, Walmart-Amazon, WDC Products, DBLP-ACM, and DBLP-Scholar. Labeling all five sets with GPT-5.2 costs between $28.31 and $40.88, versus an estimated 470 hours of manual work, while the trained students run between 41.5 and 534 times faster than direct LLM inference.
What carries the argument
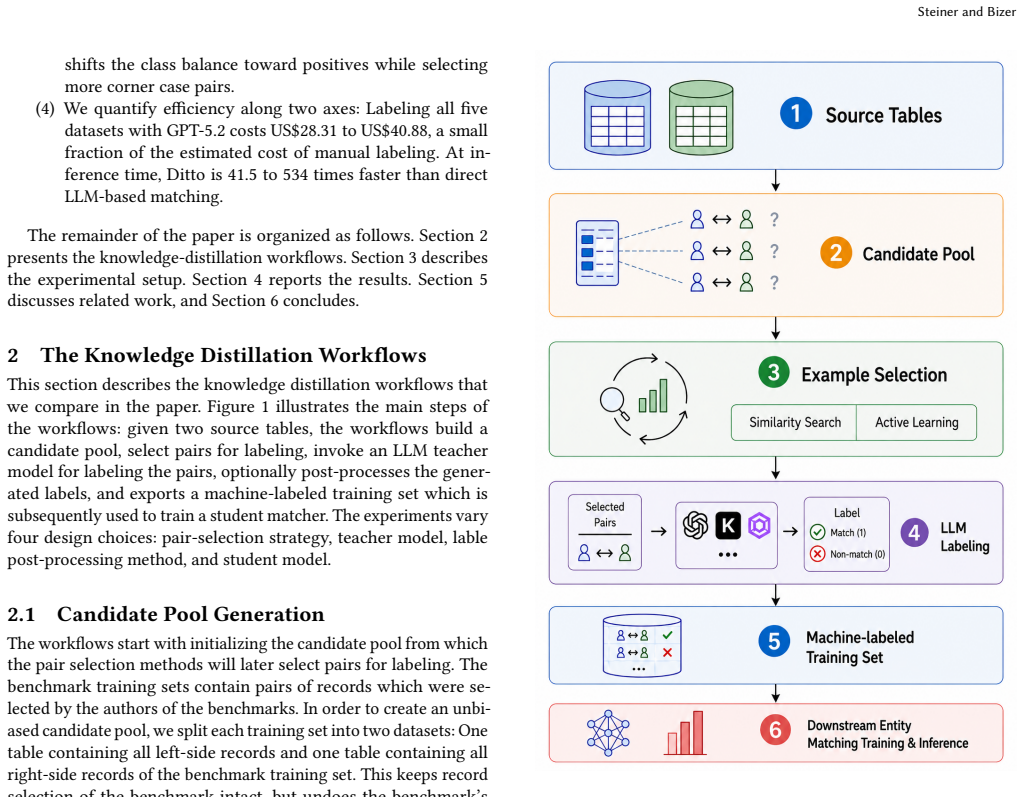
Knowledge-distillation workflow that uses an LLM to label pairs selected by a dedicated strategy, followed by label post-processing, to create training data for a smaller student model.
If this is right
- Manual labeling effort for task-specific entity-matching data can be substantially reduced or eliminated.
- Inference speed improves by one to two orders of magnitude compared with direct LLM use.
- The same workflow produces usable training sets for all five evaluated benchmarks with only small performance gaps.
Where Pith is reading between the lines
- If the pair-selection method generalizes beyond the tested benchmarks, the approach could apply to other supervised matching or classification tasks that currently require hand-labeled data.
- Stronger future LLMs could shrink the remaining sub-two-point gaps without changes to the rest of the pipeline.
- The cost reduction may make entity matching practical in narrow domains that lack budget for manual annotation.
Load-bearing premise
The combination of pair-selection strategy and label post-processing yields training sets whose label distribution and coverage let the student model generalize comparably to human-labeled data.
What would settle it
A new benchmark in which the F1 difference between the student model trained on the machine-labeled set and the same model trained on the human-labeled set exceeds two points in either direction.
Figures


read the original abstract
Recent large language models (LLMs) achieve strong performance on entity matching without requiring task-specific training data. However, applying these models to large sets of candidate pairs remains slow and costly. In contrast, entity matchers using traditional machine learning methods or small language models (SLMs), such as RoBERTa, offer much faster inference but require task-specific training data. This paper investigates whether the need to provide task-specific training data can be avoided by using knowledge-distillation workflows, in which an LLM serves as a teacher model to label training pairs that are subsequently used to train a smaller student model. We investigate knowledge distillation for entity matching along the following dimensions: pair-selection strategy, teacher model, label post-processing method, and student model. We evaluate the workflows using the Abt-Buy, Walmart-Amazon, WDC Products, DBLP-ACM, and DBLP-Scholar benchmarks, and compare the performance of student models trained with machine-labeled data to the performance of the same models trained using the benchmark training sets. Our experiments show that student models trained using the machine-labeled sets perform approximately on par with models trained on the benchmark training sets, with the remaining differences in both directions staying below two F1 points. Using GPT-5.2 to label the training sets for all five benchmarks costs US\$28.31 to US\$40.88, whereas manually labeling the same training sets is estimated to require 470 hours of work. At inference time, Ditto is 41.5 to 534 times faster than directly using an LLM to perform the matching tasks. These results indicate that current LLMs, when combined with a suitable pair-selection method, can substantially reduce or even eliminate the manual effort required to label use case-specific training data for entity matching.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates knowledge-distillation workflows for entity matching in which LLMs act as teachers to label training pairs that are then used to train smaller student models (e.g., RoBERTa, Ditto). Across the Abt-Buy, Walmart-Amazon, WDC Products, DBLP-ACM, and DBLP-Scholar benchmarks, it reports that student models trained on the machine-labeled sets achieve F1 scores within 2 points of the same models trained on the human-labeled benchmark training sets. It further quantifies labeling cost (US$28–41 with GPT-5.2 versus an estimated 470 human hours) and inference speedup (41–534× for Ditto versus direct LLM use).
Significance. If the performance parity holds under representative labeling, the approach would materially lower the barrier to deploying task-specific entity matchers by replacing manual training-set construction with LLM labeling, while retaining the efficiency advantages of SLMs at inference time.
major comments (2)
- [Experiments section (evaluation on the five benchmarks)] Experiments section (evaluation on the five benchmarks): the claim that machine-labeled training sets yield student models “approximately on par” (differences <2 F1) is load-bearing for the central contribution, yet the manuscript provides no LLM–human label agreement statistics (precision/recall/F1 on the labeled pairs) nor any comparison of positive/negative balance, difficulty distribution, or attribute coverage between the selected machine-labeled pairs and the benchmark training sets. Without these diagnostics, it remains possible that parity arises from the student fitting a non-representative but easier subset rather than learning the underlying matching task.
- [Abstract and results tables] Abstract and results tables: concrete F1 differences below 2 points are stated without error bars, standard deviations across runs, or statistical significance tests. This omission directly affects the reliability of the “remaining differences in both directions staying below two F1 points” assertion.
minor comments (2)
- [Methods] The pair-selection strategy and label post-processing method are listed as investigated dimensions but receive only high-level description; explicit pseudocode or parameter settings would improve reproducibility.
- [Abstract] The 470-hour manual-labeling estimate should state the underlying assumptions (pairs per hour, number of pairs per benchmark) so readers can assess its sensitivity.
Simulated Author's Rebuttal
Thank you for the referee's constructive comments on our manuscript. We respond point-by-point to the major comments below. Where the suggestions identify gaps in the current presentation, we will revise the manuscript to incorporate additional analysis.
read point-by-point responses
-
Referee: Experiments section (evaluation on the five benchmarks): the claim that machine-labeled training sets yield student models “approximately on par” (differences <2 F1) is load-bearing for the central contribution, yet the manuscript provides no LLM–human label agreement statistics (precision/recall/F1 on the labeled pairs) nor any comparison of positive/negative balance, difficulty distribution, or attribute coverage between the selected machine-labeled pairs and the benchmark training sets. Without these diagnostics, it remains possible that parity arises from the student fitting a non-representative but easier subset rather than learning the underlying matching task.
Authors: We agree that label-agreement statistics and distributional comparisons would strengthen the presentation. At the same time, the evaluation protocol measures every student model on the human-annotated test sets of the five benchmarks; these test sets embody the ground-truth matching criteria defined by human experts. Achieving F1 scores within 2 points of the human-trained baselines on these held-out sets indicates that the student models have internalized the underlying task rather than merely fitting artifacts of the LLM labels. In the revised version we will add (i) precision/recall/F1 agreement between LLM and human labels on a sampled subset of pairs and (ii) side-by-side comparisons of class balance, attribute coverage, and a simple difficulty proxy (e.g., token overlap) between the machine-labeled and benchmark training sets. revision: yes
-
Referee: Abstract and results tables: concrete F1 differences below 2 points are stated without error bars, standard deviations across runs, or statistical significance tests. This omission directly affects the reliability of the “remaining differences in both directions staying below two F1 points” assertion.
Authors: We accept that variability measures and significance tests would improve the reliability of the reported differences. The present results are single-run point estimates, yet the pattern of sub-2-point gaps is consistent across five benchmarks that differ in domain, size, and positive-class ratio. In the revision we will report standard deviations obtained from at least five random seeds per configuration and will include paired statistical tests (e.g., McNemar’s test on the test-set predictions) to support the claim that differences remain below two F1 points. revision: yes
Circularity Check
No circularity: empirical parity shown via external benchmark comparison
full rationale
The paper's central result is an empirical observation that student models (e.g., RoBERTa, Ditto) trained on LLM-labeled pairs achieve F1 scores within <2 points of the same models trained on the provided human-labeled benchmark training sets across five standard datasets. This comparison relies on external, pre-existing benchmark splits rather than any fitted parameter, self-referential quantity, or derivation that reduces to the paper's own inputs. No equations, ansatzes, uniqueness theorems, or self-citations are invoked as load-bearing steps; the workflow is a standard knowledge-distillation pipeline evaluated against independent human-labeled references. The representativeness concern raised in the skeptic note affects external validity but does not create a circular reduction within the reported derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Nils Barlaug and Jon Atle Gulla. 2021. Neural Networks for Entity Matching: A Survey.ACM Transactions on Knowledge Discovery from Data15, 3 (2021), 52:1–52:37
2021
-
[3]
Ursin Brunner and Kurt Stockinger. 2020. Entity Matching with Transformer Architectures - A Step Forward in Data Integration. InProceedings of the 23rd International Conference on Extending Database Technology. OpenProceedings.org, Konstanz, Germany, 463–473
2020
-
[4]
2012.Data Matching: Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection
Peter Christen. 2012.Data Matching: Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection. Springer, Berlin, Heidelberg. 12 Labeling Training Data for Entity Matching Using Large Language Models
2012
-
[5]
Vassilis Christophides, Vasilis Efthymiou, Themis Palpanas, George Papadakis, and Kostas Stefanidis. 2020. An Overview of End-to-End Entity Resolution for Big Data.Comput. Surveys53, 6 (2020), 127:1–127:42. doi:10.1145/3418896
-
[6]
2015.Entity Resolution in the Web of Data
Vassilis Christophides, Vasilis Efthymiou, and Kostas Stefanidis. 2015.Entity Resolution in the Web of Data. Morgan & Claypool, San Rafael, CA, USA
2015
-
[7]
Elmagarmid, Panagiotis G
Ahmed K. Elmagarmid, Panagiotis G. Ipeirotis, and Vassilios S. Verykios. 2007. Duplicate Record Detection: A Survey.IEEE Transactions on Knowledge and Data Engineering19, 1 (2007), 1–16
2007
-
[8]
Luyang Fang, Xiaowei Yu, Jiazhang Cai, Yongkai Chen, Shushan Wu, et al. 2026. Knowledge distillation and dataset distillation of large language models: Emerg- ing trends, challenges, and future directions.Artificial Intelligence Review59, 1 (2026), 17. doi:10.1007/s10462-025-11423-3
-
[9]
Fellegi and Alan B
Ivan P. Fellegi and Alan B. Sunter. 1969. A Theory for Record Linkage.J. Amer. Statist. Assoc.64, 328 (1969), 1183–1210
1969
-
[10]
Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli. 2023. ChatGPT Outperforms Crowd Workers for Text-Annotation Tasks.Proceedings of the National Academy of Sciences120, 30 (2023), e2305016120. doi:10.1073/pnas.2305016120
-
[11]
Robert Isele and Christian Bizer. 2012. Learning Expressive Linkage Rules using Genetic Programming.Proceedings of the VLDB Endowment5, 11 (2012), 1638– 1649
2012
-
[12]
C., AnHai Doan, Adel Ardalan, et al
Pradap Konda, Sanjib Das, Paul Suganthan G. C., AnHai Doan, Adel Ardalan, et al. 2016. Magellan: Toward Building Entity Matching Management Systems. Proceedings of the VLDB Endowment9, 12 (2016), 1197–1208
2016
-
[13]
Ross Deans Kristensen-McLachlan, Miceal Canavan, Marton Kárdos, Mia Jacob- sen, and Lene Aarøe. 2025. Are Chatbots Reliable Text Annotators? Sometimes. PNAS Nexus4, 4 (2025), pgaf069. doi:10.1093/pnasnexus/pgaf069
-
[14]
Minzhi Li, Taiwei Shi, Caleb Ziems, Min-Yen Kan, Nancy Chen, et al . 2023. CoAnnotating: Uncertainty-Guided Work Allocation between Human and Large Language Models for Data Annotation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore, 1487–1505. doi:10.18653/v1/2...
-
[15]
Yuliang Li, Jinfeng Li, Yoshihiko Suhara, AnHai Doan, and Wang-Chiew Tan
-
[16]
Deep Entity Matching with Pre-Trained Language Models.Proceedings of the VLDB Endowment14, 1 (2020), 50–60
2020
-
[17]
Yi Liu, Yuan Tian, Jianxun Lian, Xinlong Wang, Yanan Cao, Fang Fang, Wen Zhang, Haizhen Huang, Weiwei Deng, and Qi Zhang. 2023. Towards Better Entity Linking with Multi-View Enhanced Distillation. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Anna Rogers, Jordan Boyd-Graber, and Naoaki O...
-
[18]
Sedir Mohammed, Lukas Budach, Moritz Feuerpfeil, Nina Ihde, Andrea Nathansen, et al . 2025. The Effects of Data Quality on Machine Learn- ing Performance on Tabular Data.Information Systems132 (2025), 102549. doi:10.1016/j.is.2025.102549
-
[19]
Sidharth Mudgal, Han Li, Theodoros Rekatsinas, AnHai Doan, Youngchoon Park, et al. 2018. Deep Learning for Entity Matching: A Design Space Exploration. In Proceedings of the 2018 International Conference on Management of Data (SIGMOD ’18). Association for Computing Machinery, New York, NY, USA, 19–34
2018
-
[20]
Ralph Peeters, Reng Chiz Der, and Christian Bizer. 2024. WDC Products: A Multi- Dimensional Entity Matching Benchmark. InProceedings of the 27th International Conference on Extending Database Technology (EDBT 2024). OpenProceedings.org, Konstanz, Germany, 22–33. doi:10.48786/edbt.2024.03
-
[21]
Ralph Peeters, Aaron Steiner, and Christian Bizer. 2025. Entity Matching using Large Language Models. InProceedings of the 28th International Conference on Extending Database Technology (EDBT 2025). OpenProceedings.org, Konstanz, Germany, 529–541. doi:10.48786/edbt.2025.42
-
[22]
Anna Primpeli and Christian Bizer. 2021. Graph-boosted active learning for multi- source entity resolution. InInternational Semantic Web Conference. Springer, Cham, 182–199
2021
-
[23]
Anna Primpeli, Christian Bizer, and Margret Keuper. 2020. Unsupervised boot- strapping of active learning for entity resolution. InEuropean Semantic Web Conference. Springer, Cham, 215–231
2020
-
[24]
Aaron Steiner, Ralph Peeters, and Christian Bizer. 2025. Fine-Tuning Large Language Models for Entity Matching. In2025 IEEE 41st International Conference on Data Engineering Workshops (ICDEW 2025). IEEE Computer Society, Los Alamitos, CA, USA, 9–17. doi:10.1109/ICDEW67478.2025.00006
-
[25]
Somin Wadhwa, Adit Krishnan, Runhui Wang, Byron C. Wallace, and Luyang Kong. 2024. Learning from Natural Language Explanations for Generalizable Entity Matching. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Miami, FL, USA, 6114–6129. doi:10.18653/v1/2024.emnlp-main.352
-
[26]
Xiaohan Xu, Ming Li, Chongyang Tao, Tao Shen, Reynold Cheng, et al
-
[27]
A Survey on Knowledge Distillation of Large Language Models
A Survey on Knowledge Distillation of Large Language Models. arXiv:2402.13116 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Chuanpeng Yang, Yao Zhu, Wang Lu, Yidong Wang, Qian Chen, et al. 2025. Survey on Knowledge Distillation for Large Language Models: Methods, Evaluation, and Application.ACM Transactions on Intelligent Systems and Technology16, 6 (2025), 1–27. doi:10.1145/3699518
- [29]
-
[30]
Yuhong Zhang, Hangchi Song, Xiaolong Zhu, Chenyang Bu, and Kui Yu. 2025. An Robust Entity Alignment Method based on Knowledge Distillation with Noisy Aligned Pairs. InProceedings of the 34th ACM International Conference on Information and Knowledge Management(Seoul, Republic of Korea)(CIKM ’25). Association for Computing Machinery, New York, NY, USA, 5510...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.