PromptGNN-sim: Deep Fusion and Alignment of GNN and LLMs for Text-Attributed Graph Learning
Pith reviewed 2026-06-30 06:03 UTC · model grok-4.3
The pith
PromptGNN-sim fuses GNNs and LLMs bidirectionally through structure-aware prompts and cross-modal alignment to improve text-attributed graph learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
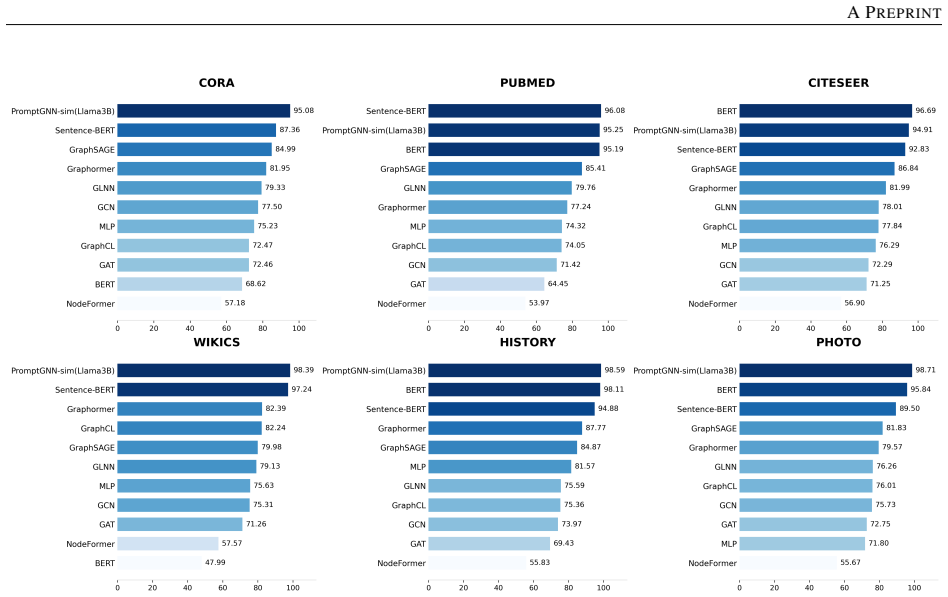
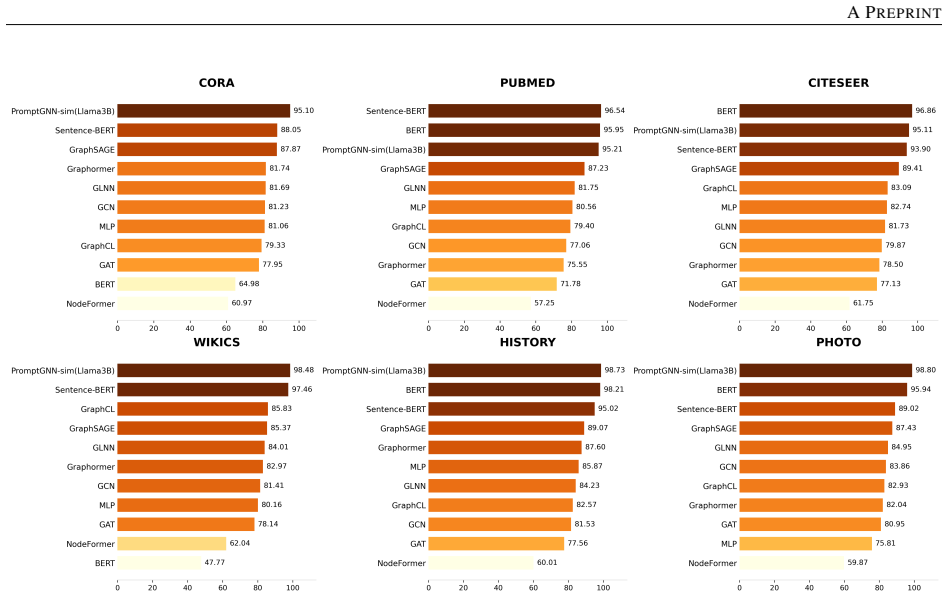
PromptGNN-sim performs bi-directional structure-semantic fusion by using a GAT for semantically aware neighborhood selection that combines structural attention with textual similarity, generating structure-aware prompts for an LLM that include the target node summary, label categories, and keywords from similar neighbors, and applying bi-directional cross-modal contrastive learning with cross-attention to jointly optimize the GNN and LLM components, which produces outperformance over classical GNNs, LLMs, and recent fusion methods on six public datasets while improving generalization and robustness under sparse perturbations and cross-dataset settings.
What carries the argument
GAT-based neighborhood selection that feeds structure-aware prompts into an LLM, combined with bi-directional cross-modal contrastive learning and cross-attention to align and optimize the two models jointly.
If this is right
- Better accuracy on text-attributed graph tasks than classical GNNs, LLMs, or prior fusion methods.
- Improved performance when graph connectivity is sparse.
- Stronger generalization across tasks and across different datasets.
- Evidence that interactive rather than one-way collaboration between structure and semantics is effective.
Where Pith is reading between the lines
- The prompting strategy might transfer to other graph tasks that combine nodes with rich attributes beyond text.
- The bi-directional alignment could reduce reliance on large amounts of labeled data in graph settings.
- Similar cross-modal mechanisms might apply to graphs paired with other modalities such as images or sequences.
- The approach points toward hybrid systems that alternate between local structure updates and global semantic prompts.
Load-bearing premise
The bi-directional cross-modal contrastive learning, cross-attention, and GAT neighborhood selection are what produce the claimed gains in performance, generalization, and robustness.
What would settle it
A controlled replication on the same six datasets or a new sparse text-attributed graph dataset in which PromptGNN-sim shows no accuracy or robustness advantage over strong GNN-only and LLM-only baselines would falsify the central claim.
Figures

read the original abstract
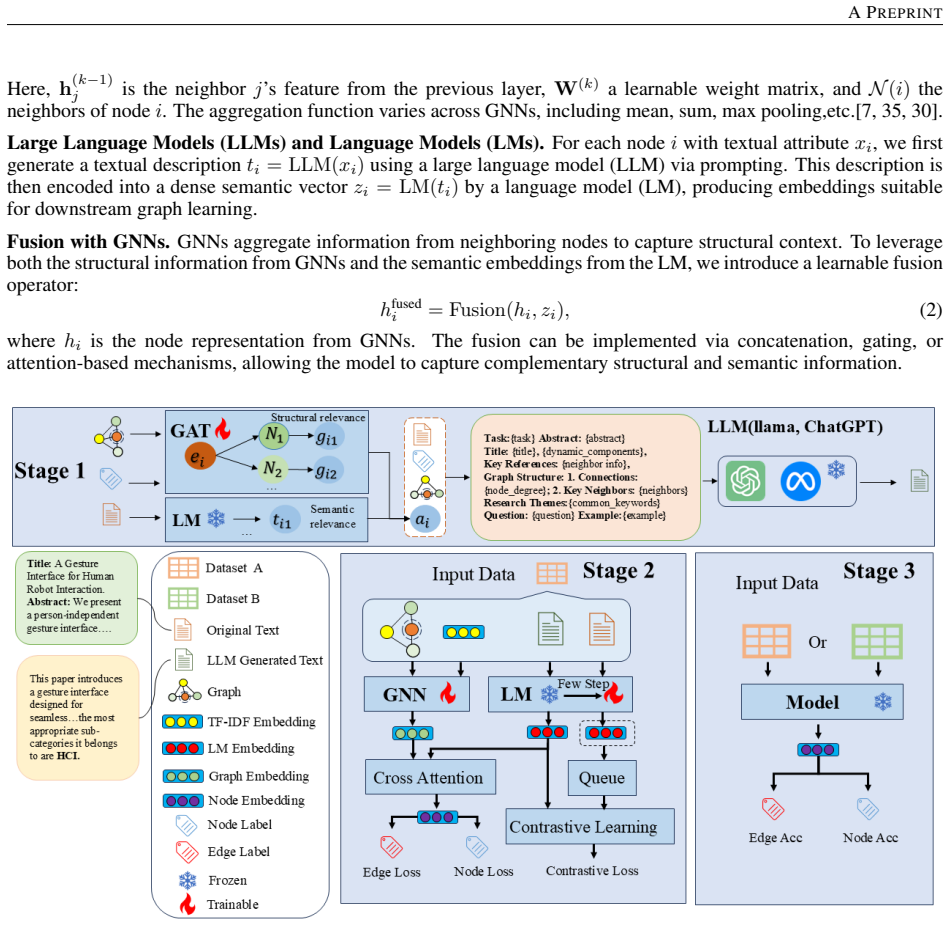
Text-Attributed Graphs (TAGs) combine textual semantics with graph structure and are central to many graph learning tasks. However, existing fusion methods often treat text and structure as separate inputs in a shallow, one-way pipeline, which limits deep interaction between modalities and weakens performance under sparse connectivity or cross-graph generalisation. To address this issue, we propose PromptGNN-sim, a bi-directional structure-semantic fusion framework for collaborative GNN-LLM learning. PromptGNN-sim uses a Graph Attention Network (GAT) for semantically aware neighborhood selection by combining structural attention with textual similarity. The selected structural context is then used to generate structure-aware prompts for an LLM, including the target node summary, label categories, and representative keywords from similar neighbors. During training, bi-directional cross-modal contrastive learning and cross-attention are introduced to jointly optimize the GNN and LLM components. Experiments on six public datasets, including Cora, Pubmed, and WikiCS, evaluate accuracy, generalisation, and robustness under cross-task transfer, cross-dataset generalisation, and sparse perturbations. Results show that PromptGNN-sim outperforms classical GNNs, LLMs, and recent GNN-LLM fusion methods, demonstrating the effectiveness of interactive structure-semantic collaboration for text-attributed graph learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PromptGNN-sim, a bi-directional structure-semantic fusion framework for text-attributed graph (TAG) learning that combines GNNs and LLMs. It uses a GAT to perform semantically aware neighborhood selection by fusing structural attention with textual similarity, generates structure-aware prompts (including target node summary, label categories, and neighbor keywords) for the LLM, and introduces bi-directional cross-modal contrastive learning plus cross-attention to jointly optimize the GNN and LLM components. Experiments on six datasets (Cora, Pubmed, WikiCS and others) report superior accuracy, cross-task/cross-dataset generalization, and robustness under sparse perturbations compared to classical GNNs, standalone LLMs, and prior GNN-LLM fusion methods.
Significance. If the reported gains can be causally attributed to the interactive fusion components rather than unablated factors, the work would advance TAG learning by demonstrating a concrete mechanism for deep, bidirectional structure-semantic collaboration, with implications for node classification and related tasks under sparse or shifting graph conditions.
major comments (3)
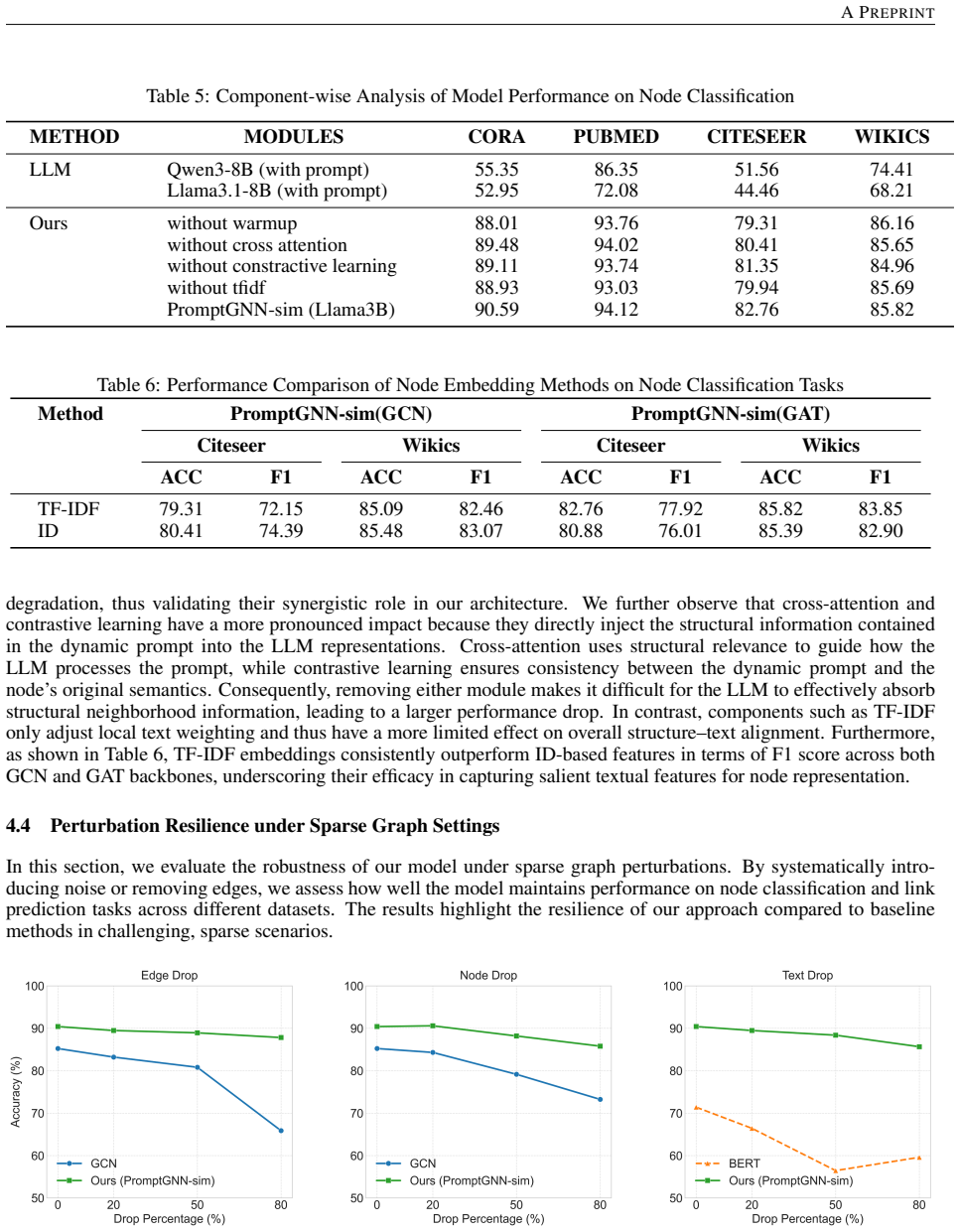
- [Experiments] Experiments section: the central claim that outperformance stems from GAT-based neighborhood selection plus bi-directional cross-modal contrastive learning and cross-attention is not supported by any ablation or component-removal experiments. Without quantitative isolation of each mechanism's contribution (e.g., performance drop when contrastive loss or cross-attention is removed), the attribution to the proposed interactive fusion remains unsecured.
- [Method] Method section (description of bi-directional contrastive learning): the loss formulation, alignment objectives, and temperature hyperparameters are not specified, nor is it shown how the contrastive terms reduce to quantities derived from the fitted GNN/LLM parameters; this prevents verification that the claimed joint optimization is parameter-free or well-defined.
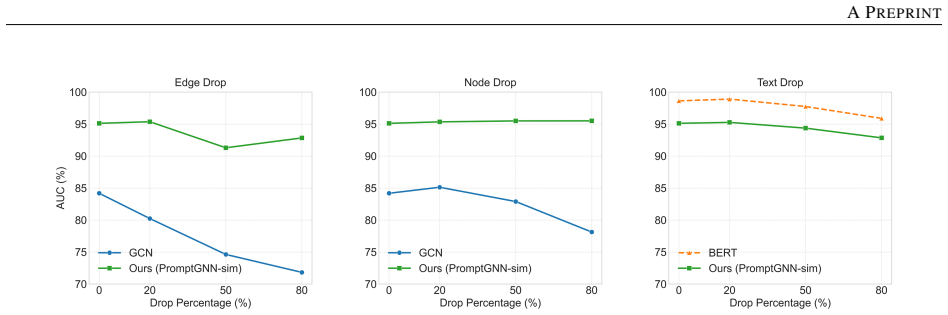
- [Experiments] Experiments section (robustness and generalization tables): no statistical significance tests, variance across runs, or data-exclusion rules are reported, so it is impossible to confirm that the claimed gains under sparse perturbations and cross-dataset transfer are reliable rather than artifacts of a single split or implementation detail.
minor comments (2)
- [Abstract] Abstract: only three of the six datasets are named; listing all datasets and the precise evaluation metrics used would improve clarity.
- Notation for cross-attention and prompt generation is introduced without explicit equations or pseudocode, making the pipeline harder to follow.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below. Where the manuscript is missing required details or experiments, we will revise accordingly to strengthen the claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that outperformance stems from GAT-based neighborhood selection plus bi-directional cross-modal contrastive learning and cross-attention is not supported by any ablation or component-removal experiments. Without quantitative isolation of each mechanism's contribution (e.g., performance drop when contrastive loss or cross-attention is removed), the attribution to the proposed interactive fusion remains unsecured.
Authors: We acknowledge that the current version does not include component-removal ablations. The reported gains are shown only via comparisons to external baselines. We will add a dedicated ablation study in the revised Experiments section that removes the GAT semantic fusion, the contrastive loss, and the cross-attention module individually, reporting the resulting accuracy drops on the six datasets. This will provide direct quantitative support for the contribution of each interactive fusion component. revision: yes
-
Referee: [Method] Method section (description of bi-directional contrastive learning): the loss formulation, alignment objectives, and temperature hyperparameters are not specified, nor is it shown how the contrastive terms reduce to quantities derived from the fitted GNN/LLM parameters; this prevents verification that the claimed joint optimization is parameter-free or well-defined.
Authors: The manuscript indeed omits the explicit equations and hyperparameter values for the bi-directional contrastive loss. We will insert a new subsection in the Method section that defines the InfoNCE-style objectives for both directions, specifies the temperature, and shows how the loss terms are computed from the GNN and LLM embeddings. This will make the joint optimization fully verifiable. revision: yes
-
Referee: [Experiments] Experiments section (robustness and generalization tables): no statistical significance tests, variance across runs, or data-exclusion rules are reported, so it is impossible to confirm that the claimed gains under sparse perturbations and cross-dataset transfer are reliable rather than artifacts of a single split or implementation detail.
Authors: We agree that the absence of variance, multiple-run statistics, and significance testing weakens the reliability claims. We will rerun all experiments with at least five random seeds, report mean and standard deviation, apply paired t-tests or Wilcoxon tests for the reported improvements, and state the data-exclusion criteria. These additions will be included in the revised tables and text. revision: yes
Circularity Check
No significant circularity; method introduces independent fusion components
full rationale
The paper proposes PromptGNN-sim as a new bi-directional fusion framework using GAT-based neighborhood selection, structure-aware LLM prompts, cross-modal contrastive learning, and cross-attention. No equations, fitted parameters, or self-citations are presented in the abstract or description that reduce any claimed prediction or result to the inputs by construction. The central claims rest on empirical outperformance across datasets rather than a closed derivation loop. This is a standard empirical proposal of novel mechanisms without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LLaGA: Large language and graph assistant
Runjin Chen, Tong Zhao, Ajay Jaiswal, Neil Shah, and Zhangyang Wang. Llaga: Large language and graph assistant.arXiv preprint arXiv:2402.08170, 2024
-
[2]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
2020
-
[3]
Adversarial attack on graph structured data
Hanjun Dai, Hui Li, Tian Tian, Xin Huang, Lin Wang, Jun Zhu, and Le Song. Adversarial attack on graph structured data. InInternational conference on machine learning, pages 1115–1124. PMLR, 2018
2018
-
[4]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[5]
Gaugllm: Improving graph contrastive learning for text-attributed graphs with large language models
Yi Fang, Dongzhe Fan, Daochen Zha, and Qiaoyu Tan. Gaugllm: Improving graph contrastive learning for text-attributed graphs with large language models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 747–758, 2024
2024
-
[6]
Citeseer: An automatic citation indexing system
C Lee Giles, Kurt D Bollacker, and Steve Lawrence. Citeseer: An automatic citation indexing system. In Proceedings of the third ACM conference on Digital libraries, pages 89–98, 1998
1998
-
[7]
Inductive representation learning on large graphs.Advances in neural information processing systems, 30, 2017
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs.Advances in neural information processing systems, 30, 2017
2017
-
[8]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
2020
-
[9]
Zhongmou He, Jing Zhu, Shengyi Qian, Joyce Chai, and Danai Koutra. Linkgpt: Teaching large language models to predict missing links.arXiv preprint arXiv:2406.04640, 2024
-
[10]
Open graph benchmark: Datasets for machine learning on graphs.Advances in neural information processing systems, 33:22118–22133, 2020
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs.Advances in neural information processing systems, 33:22118–22133, 2020
2020
-
[11]
Gnns as adapters for llms on text-attributed graphs
Xuanwen Huang, Kaiqiao Han, Yang Yang, Dezheng Bao, Quanjin Tao, Ziwei Chai, and Qi Zhu. Gnns as adapters for llms on text-attributed graphs. InThe Web Conference 2024, 2024
2024
-
[12]
Large language models on graphs: A comprehensive survey.IEEE Transactions on Knowledge and Data Engineering, 2024
Bowen Jin, Gang Liu, Chi Han, Meng Jiang, Heng Ji, and Jiawei Han. Large language models on graphs: A comprehensive survey.IEEE Transactions on Knowledge and Data Engineering, 2024
2024
-
[13]
Graphit: Efficient node classification on text-attributed graphs with prompt optimized llms
Shima Khoshraftar, Niaz Abedini, and Amir Hajian. Graphit: Efficient node classification on text-attributed graphs with prompt optimized llms. InCompanion Proceedings of the ACM on Web Conference 2025, pages 1824–1829, 2025
2025
-
[14]
Semi-Supervised Classification with Graph Convolutional Networks
TN Kipf. Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[15]
Runlin Lei, Jiarui Ji, Haipeng Ding, Lu Yi, Zhewei Wei, Yongchao Liu, and Chuntao Hong. Exploring the poten- tial of large language models as predictors in dynamic text-attributed graphs.arXiv preprint arXiv:2503.03258, 2025
-
[16]
Similarity-based neighbor selection for graph llms.arXiv preprint arXiv:2402.03720, 2024
Rui Li, Jiwei Li, Jiawei Han, and Guoyin Wang. Similarity-based neighbor selection for graph llms.arXiv preprint arXiv:2402.03720, 2024
-
[17]
Zerog: Investigating cross-dataset zero-shot transferability in graphs
Yuhan Li, Peisong Wang, Zhixun Li, Jeffrey Xu Yu, and Jia Li. Zerog: Investigating cross-dataset zero-shot transferability in graphs. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 1725–1735, 2024
2024
-
[18]
Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, and Muhan Zhang. One for all: Towards training one graph model for all classification tasks.arXiv preprint arXiv:2310.00149, 2023
-
[19]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[20]
Can we soft prompt llms for graph learning tasks? InCompanion Proceedings of the ACM Web Conference 2024, pages 481–484, 2024
Zheyuan Liu, Xiaoxin He, Yijun Tian, and Nitesh V Chawla. Can we soft prompt llms for graph learning tasks? InCompanion Proceedings of the ACM Web Conference 2024, pages 481–484, 2024. 10 A PREPRINT
2024
-
[21]
Automating the construction of internet portals with machine learning.Information Retrieval, 3(2):127–163, 2000
Andrew Kachites McCallum, Kamal Nigam, Jason Rennie, and Kristie Seymore. Automating the construction of internet portals with machine learning.Information Retrieval, 3(2):127–163, 2000
2000
-
[22]
Wiki-cs: A wikipedia-based benchmark for graph neural networks.arXiv preprint arXiv:2007.02901, 2020
Péter Mernyei and C ˘at˘alina Cangea. Wiki-cs: A wikipedia-based benchmark for graph neural networks.arXiv preprint arXiv:2007.02901, 2020
-
[23]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Evolvegcn: Evolving graph convolutional networks for dynamic graphs
Aldo Pareja, Giacomo Domeniconi, Jie Chen, Tengfei Ma, Toyotaro Suzumura, Hiroki Kanezashi, Tim Kaler, Tao Schardl, and Charles Leiserson. Evolvegcn: Evolving graph convolutional networks for dynamic graphs. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 5363–5370, 2020
2020
-
[25]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks.arXiv preprint arXiv:1908.10084, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[26]
Temporal Graph Networks for Deep Learning on Dynamic Graphs
Emanuele Rossi, Ben Chamberlain, Fabrizio Frasca, Davide Eynard, Federico Monti, and Michael Bronstein. Temporal graph networks for deep learning on dynamic graphs.arXiv preprint arXiv:2006.10637, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[27]
Amit Roy, Ning Yan, and Masood Mortazavi. Llm-driven knowledge distillation for dynamic text-attributed graphs.arXiv preprint arXiv:2502.10914, 2025
-
[28]
Learning representations by back-propagating errors.nature, 323(6088):533–536, 1986
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors.nature, 323(6088):533–536, 1986
1986
-
[29]
Collective classification in network data.AI magazine, 29(3):93–93, 2008
Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data.AI magazine, 29(3):93–93, 2008
2008
-
[30]
Petar Veli ˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks.arXiv preprint arXiv:1710.10903, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Haoyu Wang, Shikun Liu, Rongzhe Wei, and Pan Li. Model generalization on text attribute graphs: Principles with large language models.arXiv preprint arXiv:2502.11836, 2025
-
[32]
Yuxiang Wang, Xinnan Dai, Wenqi Fan, and Yao Ma. Exploring graph tasks with pure llms: A comprehensive benchmark and investigation.arXiv preprint arXiv:2502.18771, 2025
-
[33]
Nodeformer: A scalable graph structure learning transformer for node classification.Advances in Neural Information Processing Systems, 35:27387– 27401, 2022
Qitian Wu, Wentao Zhao, Zenan Li, David P Wipf, and Junchi Yan. Nodeformer: A scalable graph structure learning transformer for node classification.Advances in Neural Information Processing Systems, 35:27387– 27401, 2022
2022
-
[34]
A comprehensive survey on graph neural networks.IEEE transactions on neural networks and learning systems, 32(1):4–24, 2020
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S Yu. A comprehensive survey on graph neural networks.IEEE transactions on neural networks and learning systems, 32(1):4–24, 2020
2020
-
[35]
How Powerful are Graph Neural Networks?
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks?arXiv preprint arXiv:1810.00826, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
A comprehensive study on text-attributed graphs: Benchmarking and rethinking
Hao Yan, Chaozhuo Li, Ruosong Long, Chao Yan, Jianan Zhao, Wenwen Zhuang, Jun Yin, Peiyan Zhang, Weihao Han, Hao Sun, et al. A comprehensive study on text-attributed graphs: Benchmarking and rethinking. Advances in Neural Information Processing Systems, 36:17238–17264, 2023
2023
-
[37]
Do transformers really perform badly for graph representation?Advances in neural information processing systems, 34:28877–28888, 2021
Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, and Tie-Yan Liu. Do transformers really perform badly for graph representation?Advances in neural information processing systems, 34:28877–28888, 2021
2021
-
[38]
Graph contrastive learning with augmentations.Advances in neural information processing systems, 33:5812–5823, 2020
Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. Graph contrastive learning with augmentations.Advances in neural information processing systems, 33:5812–5823, 2020
2020
-
[39]
Graph2text or graph2token: A perspective of large language models for graph learning
Shuo Yu, Yingbo Wang, Ruolin Li, Guchun Liu, Yanming Shen, Shaoxiong Ji, Bowen Li, Fengling Han, Xiuzhen Zhang, and Feng Xia. Graph2text or graph2token: A perspective of large language models for graph learning. arXiv preprint arXiv:2501.01124, 2025
-
[40]
Shichang Zhang, Yozen Liu, Yizhou Sun, and Neil Shah. Graph-less neural networks: Teaching old mlps new tricks via distillation.arXiv preprint arXiv:2110.08727, 2021
-
[41]
Toward General and Robust LLM-enhanced Text-attributed Graph Learning
Zihao Zhang, Xunkai Li, Rong-Hua Li, Bing Zhou, Zhenjun Li, and Guoren Wang. Toward general and robust llm-enhanced text-attributed graph learning.arXiv preprint arXiv:2504.02343, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
A survey of dynamic graph neural networks.Frontiers of Computer Science, 19(6):196323, 2025
Yanping Zheng, Lu Yi, and Zhewei Wei. A survey of dynamic graph neural networks.Frontiers of Computer Science, 19(6):196323, 2025
2025
-
[43]
Graph neural networks: A review of methods and applications.AI open, 1:57–81, 2020
Jie Zhou, Ganqu Cui, Shengding Hu, Zhengyan Zhang, Cheng Yang, Zhiyuan Liu, Lifeng Wang, Changcheng Li, and Maosong Sun. Graph neural networks: A review of methods and applications.AI open, 1:57–81, 2020. 11 A PREPRINT
2020
-
[44]
Xi Zhu, Haochen Xue, Ziwei Zhao, Wujiang Xu, Jingyuan Huang, Minghao Guo, Qifan Wang, Kaixiong Zhou, and Yongfeng Zhang. Llm as gnn: Graph vocabulary learning for text-attributed graph foundation models.arXiv preprint arXiv:2503.03313, 2025
-
[45]
Yun Zhu, Yaoke Wang, Haizhou Shi, and Siliang Tang. Efficient tuning and inference for large language models on textual graphs.arXiv preprint arXiv:2401.15569, 2024. 12 A PREPRINT A Related Work LLM-based Approaches for Text-Attributed Graphs.Large Language Models (LLMs) have recently demonstrated strong capabilities in reasoning over graph-structured dat...
-
[46]
Connections: {node degree}
-
[47]
Key Neighbors Common Research Themes: {common keywords} Question: Which of the following sub-categories does this paper belong to: {label}? 82.76 77.92 Table 9 compares node classification performance on Citeseer using different prompt designs with Llama 3.1-8B and GPT-4o. Our comprehensive prompt, which incorporates textual content alongside graph struct...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.