Cultural Value Alignment Via Latent Activation Steering in Large Language Models
Pith reviewed 2026-06-29 21:13 UTC · model grok-4.3
The pith
Cultural values in LLMs are encoded as coupled structures limiting precise alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
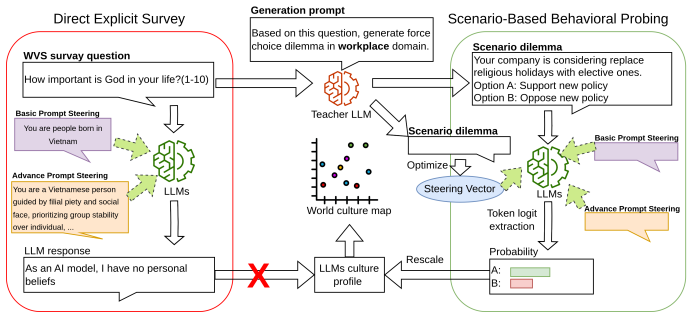
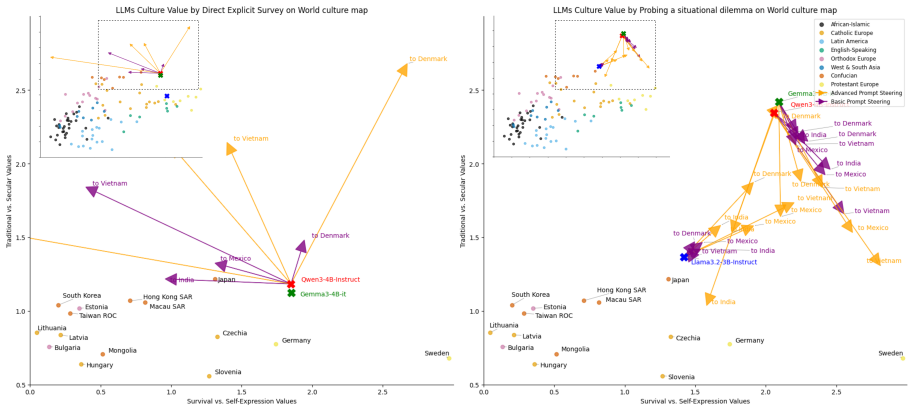
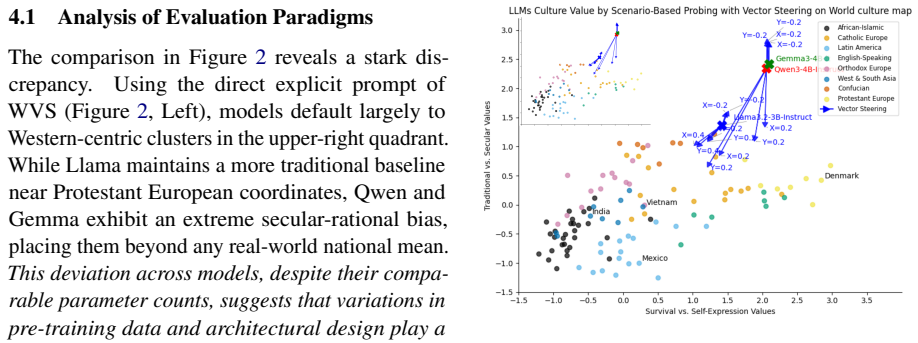
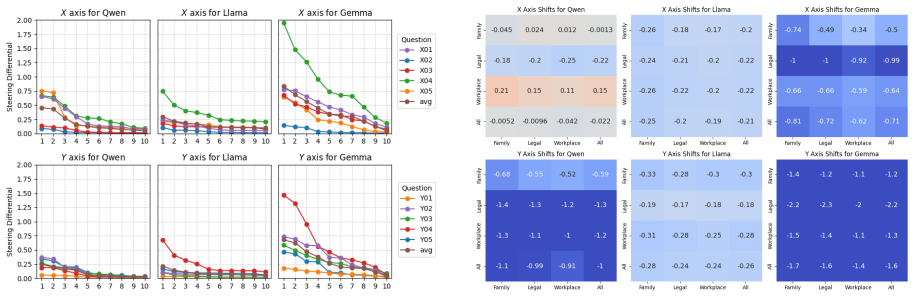
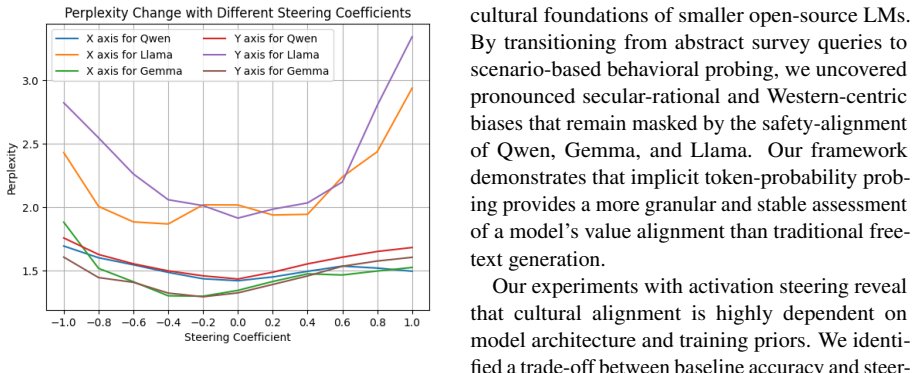
We propose a framework that transitions from abstract queries to scenario-based behavioral probing, extracting implicit token probabilities across 300 situational dilemmas to map the latent cultural coordinates of LLMs. Activation steering is then applied to shift these internal alignments during the forward pass. Across multiple LLMs we observe substantial variation in adaptability and uncover a consistent phenomenon of latent entanglement, where interventions along one cultural dimension induce shifts along another. These results suggest that cultural values are encoded as coupled structures, limiting precise alignment.
What carries the argument
Activation steering applied during the forward pass to cultural value dimensions extracted from implicit token probabilities on situational dilemmas.
If this is right
- LLMs display different degrees of adaptability when their cultural values are steered.
- Steering one cultural dimension consistently produces shifts in others.
- The method supplies a computationally efficient way to evaluate and modify cultural alignments without retraining.
- Cultural values in these models exist as coupled structures that complicate isolated changes.
Where Pith is reading between the lines
- The observed coupling could mean that alignment efforts must target multiple dimensions at once to achieve intended outcomes.
- Models that show lower adaptability might require different base training approaches to become more steerable.
- The same entanglement pattern might appear in other value domains such as ethics or safety preferences.
Load-bearing premise
That the token probabilities collected across the 300 situational dilemmas give an accurate map of the model's internal cultural values rather than surface refusals or prompt artifacts.
What would settle it
A controlled test in which steering one cultural dimension produces no measurable change in any other dimension would falsify the coupling claim.
Figures

read the original abstract
Large Language Models (LLMs) often exhibit homogenized cultural perspectives. While the World Values Survey (WVS) provides a gold standard for mapping human values, traditional direct prompting of LLMs on WVS often fails to access the model's latent cultural depth, leading to safety-aligned refusals or neutral responses. Here, we propose a generalizable framework for cultural evaluation and intervention that transitions from abstract queries to scenario-based behavioral probing. By extracting implicit token probabilities across 300 situational dilemmas, we bypass surface-level alignment to map the latent coordinates of LLMs cultural value. We further introduce activation steering to shift these internal alignments during the forward pass without retraining. Across multiple LLMs, we find substantial variation in adaptability and uncover a consistent phenomenon of latent entanglement, where interventions along one cultural dimension induce shifts along another. These results suggest that cultural values are encoded as coupled structures, limiting precise alignment. This work establishes a computationally efficient framework for cultural steering, highlighting the structural complexities when navigating global value with LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that direct WVS prompting of LLMs fails due to safety refusals, so a scenario-based probing method using implicit token probabilities from 300 situational dilemmas can map latent cultural value coordinates. Activation steering is then applied during the forward pass to shift these values; experiments across multiple LLMs reveal variation in adaptability and a consistent 'latent entanglement' effect in which steering one cultural dimension induces shifts along others, implying that values are encoded as coupled structures that limit precise alignment.
Significance. If the 300-dilemma probe is shown to recover internal coordinates rather than surface artifacts and the entanglement result is reproducible with controls, the work would be significant for demonstrating structural constraints on cultural steering and for supplying a training-free intervention technique. It would also supply a concrete, falsifiable test of whether value dimensions can be manipulated independently.
major comments (1)
- [Abstract / Probing Method] The central claim that cultural values form coupled latent structures (and therefore limit precise alignment) rests on the extracted token probabilities across the 300 dilemmas constituting a valid map of internal coordinates. No validation of this mapping—such as correlation with established WVS items, ablation of dilemma selection, or controls for safety-tuned refusal patterns—is described. If the dilemmas primarily elicit correlated surface-level responses, the reported cross-dimensional steering effects would be consistent with probing artifacts rather than entanglement in the model's activations.
minor comments (1)
- The abstract states results 'across multiple LLMs' but does not name the models, report sample sizes, or provide quantitative metrics (effect sizes, statistical tests) for the entanglement phenomenon.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to validate the probing method. We address this point directly below and commit to revisions that strengthen the evidential basis for interpreting the entanglement results.
read point-by-point responses
-
Referee: [Abstract / Probing Method] The central claim that cultural values form coupled latent structures (and therefore limit precise alignment) rests on the extracted token probabilities across the 300 dilemmas constituting a valid map of internal coordinates. No validation of this mapping—such as correlation with established WVS items, ablation of dilemma selection, or controls for safety-tuned refusal patterns—is described. If the dilemmas primarily elicit correlated surface-level responses, the reported cross-dimensional steering effects would be consistent with probing artifacts rather than entanglement in the model's activations.
Authors: We agree that the absence of explicit validation leaves the interpretation of latent entanglement open to the alternative explanation of surface-level artifacts, and this constitutes a genuine limitation of the submitted manuscript. The 300 dilemmas were selected to operationalize WVS dimensions through concrete scenarios precisely to circumvent the refusals observed with direct WVS prompting, yet we did not report correlations between the resulting coordinates and WVS items, ablations of dilemma subsets, or systematic controls isolating safety-tuning effects. In the revised version we will add: (i) correlation analyses between the extracted token-probability coordinates and any non-refusal direct WVS responses obtainable from the same models, (ii) ablation experiments that systematically remove dilemma clusters and re-compute both the value maps and the steering-induced shifts, and (iii) comparisons of refusal rates and probability distributions against base (pre-alignment) model checkpoints where available. These additions will allow readers to assess whether the observed cross-dimensional steering effects persist under stricter controls and thereby support or qualify the claim of coupled latent structures. revision: yes
Circularity Check
No significant circularity; empirical mapping and observation of entanglement
full rationale
The paper describes an empirical pipeline: extracting implicit token probabilities from 300 situational dilemmas to map latent cultural coordinates, followed by activation steering to observe cross-dimensional shifts. No equations, fitted parameters, self-citations, or ansatzes are referenced in the provided text that would reduce the central claim of coupled structures to a definitional or fitted input by construction. The entanglement finding is presented as an experimental observation rather than a tautological renaming or self-referential derivation. The approach remains self-contained against external benchmarks like WVS without load-bearing internal reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Break the checkbox: Challenging closed-style evaluations of cultural alignment in LLMs. InPro- ceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing, pages 24–51, Suzhou, China. Association for Computational Lin- guistics. Sarah Masud, Mohammad Aflah Khan, Vikram Goyal, Md Shad Akhtar, and Tanmoy Chakraborty. 2024a. Probing...
-
[2]
Forced Choice
Should LLMs be WEIRD? Exploring WEIRD- ness and human rights in large language models. In Proceedings of the Eighth AAAI/ACM Conference on AI, Ethics, and Society, volume 8 ofAIES ’25, pages 2808–2820. AAAI Press. Appendix A Experimental Setup Experiments were conducted on NVIDIA T4 GPUs via Kaggle, totaling approximately 18 GPU hours. All models were loa...
-
[3]
Each scenario must present a realistic conflict (workplace, family, or legal) where a character must choose between the Low Value and the High Value
-
[4]
Provide exactly two options (A and B)
-
[5]
wvs_id":
Randomize whether Option A or B represents the Low or High Value. ### Output Format: Return ONLY a valid JSON list of objects. Use this structure: [ { "wvs_id": "ID_HERE", "dimension": "...", "domain": "...", "scenario_text": "...", "options": {"A": "...", "B": "..."}, "mapping": {"Dimension 1": "A or B", "Dimension 2": "A or B"} } ] C Culture Steering Te...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.