From Shortcuts to Reasoning: Robust Post-Training of Theory of Mind with Reinforcement Learning
Pith reviewed 2026-06-27 17:40 UTC · model grok-4.3
The pith
Reinforcement fine-tuning with explicit reasoning chains raises Theory of Mind accuracy 6 percent above supervised fine-tuning on shortcut-free tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
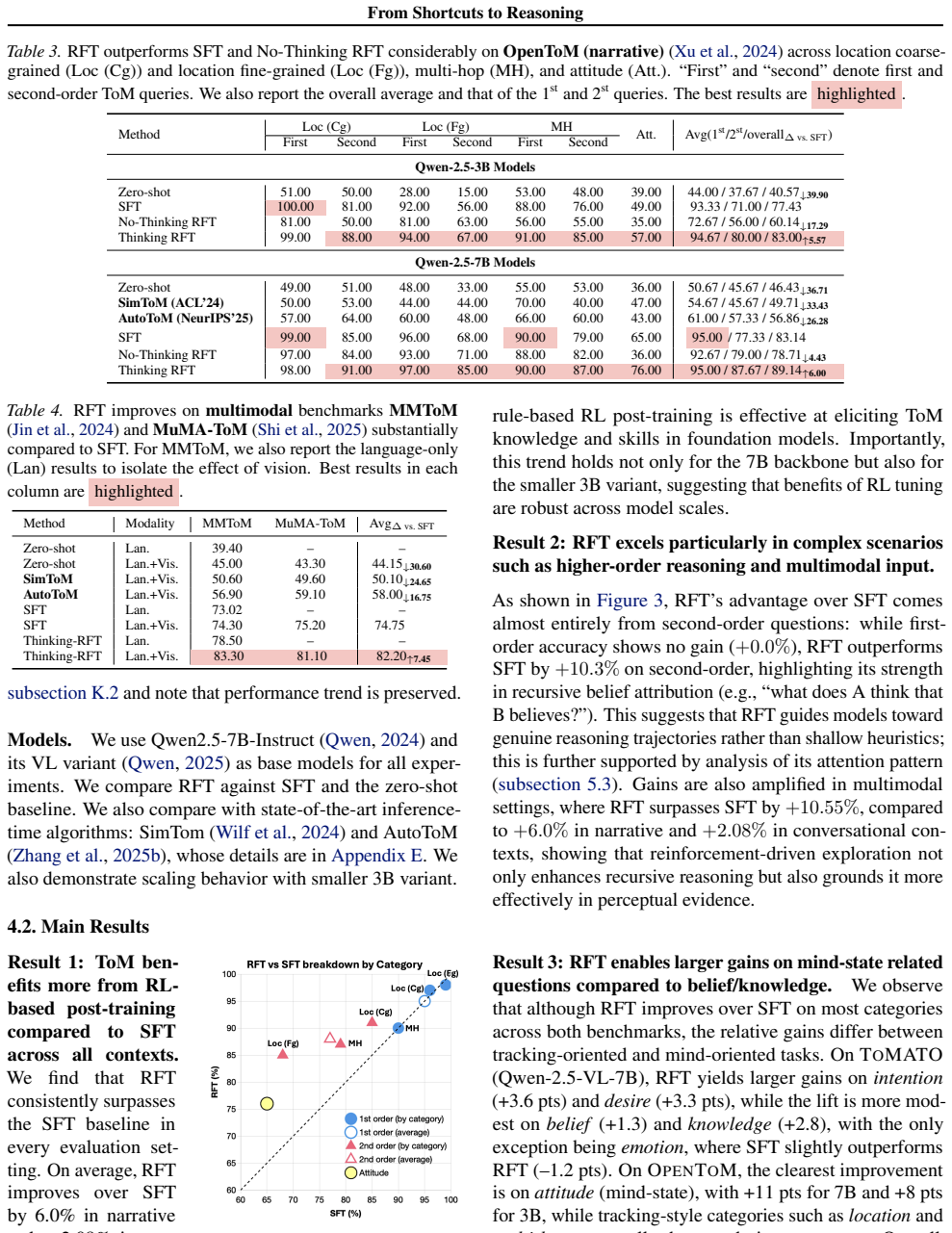
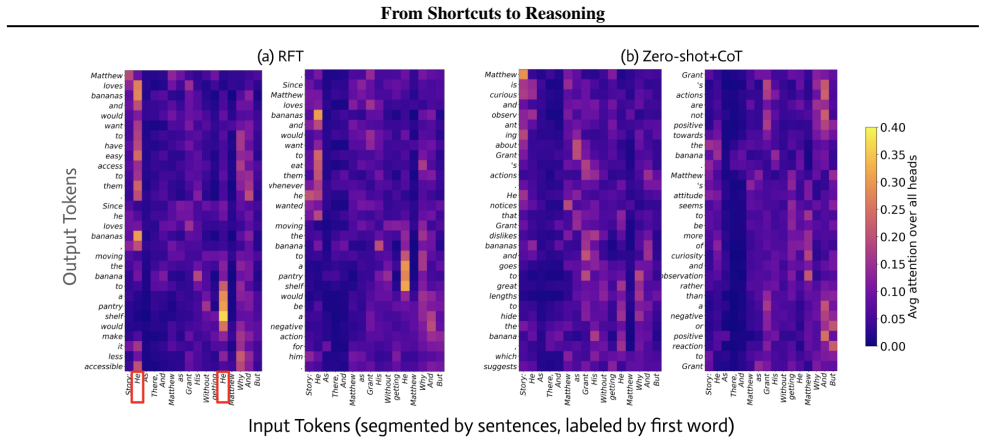
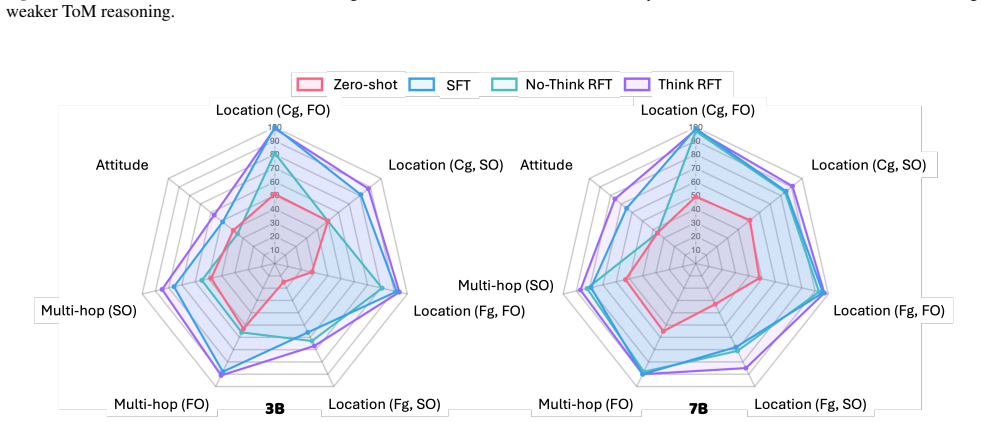
Using four shortcut-free datasets, Thinking-RFT improves ToM accuracy by 6 percent over SFT overall, 10 percent in higher-order reasoning, and 7 percent in multimodal settings. It also generalizes better to unseen domains and higher-order queries while proving more robust to counterfactuals. The gains arise specifically from the joint use of reasoning chains and reinforcement learning, which teaches the model to ground its inferences on causal anchor cues such as keywords and state changes rather than spurious patterns.
What carries the argument
Thinking-RFT: reinforcement fine-tuning that pairs verifiable rewards with explicit reasoning chains to ground inferences on causal anchor cues.
If this is right
- Higher-order ToM reasoning improves by 10 percent over SFT.
- Multimodal ToM improves by 7 percent over SFT.
- Generalization strengthens to unseen domains and higher-order queries.
- Robustness increases against counterfactual inputs.
- The benefit requires both reasoning chains and RL together.
Where Pith is reading between the lines
- The shortcut-detection framework could be applied to other reasoning benchmarks to expose similar hidden pattern-matching weaknesses.
- Emphasizing causal cue grounding during training may improve reliability in open-ended social scenarios beyond the tested contexts.
- Future cognitive-skill datasets should prioritize questions that force inference past state tracking.
Load-bearing premise
The four datasets are genuinely free of shortcuts and require inference about minds rather than pure state tracking.
What would settle it
If a new higher-order ToM task that cannot be solved by state tracking alone shows no accuracy gain for Thinking-RFT over SFT, the claim that the method elevates genuine reasoning would be falsified.
Figures


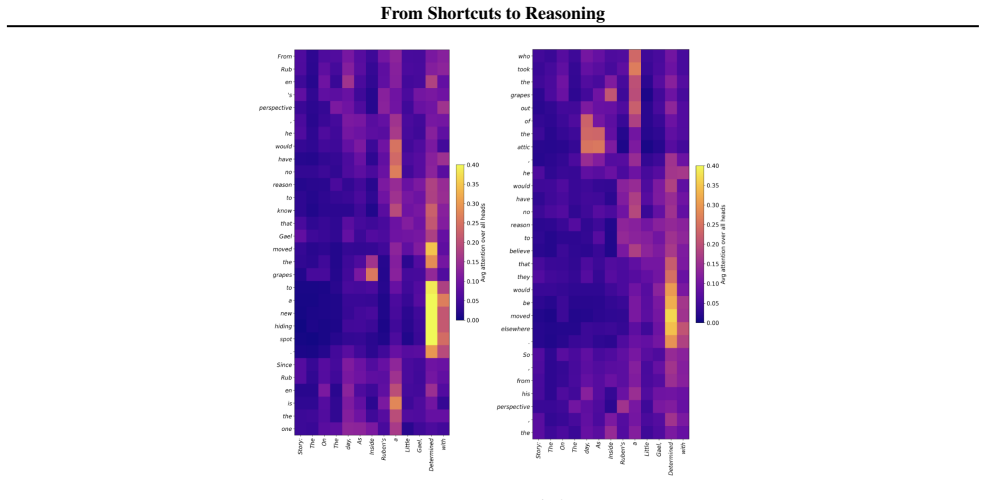
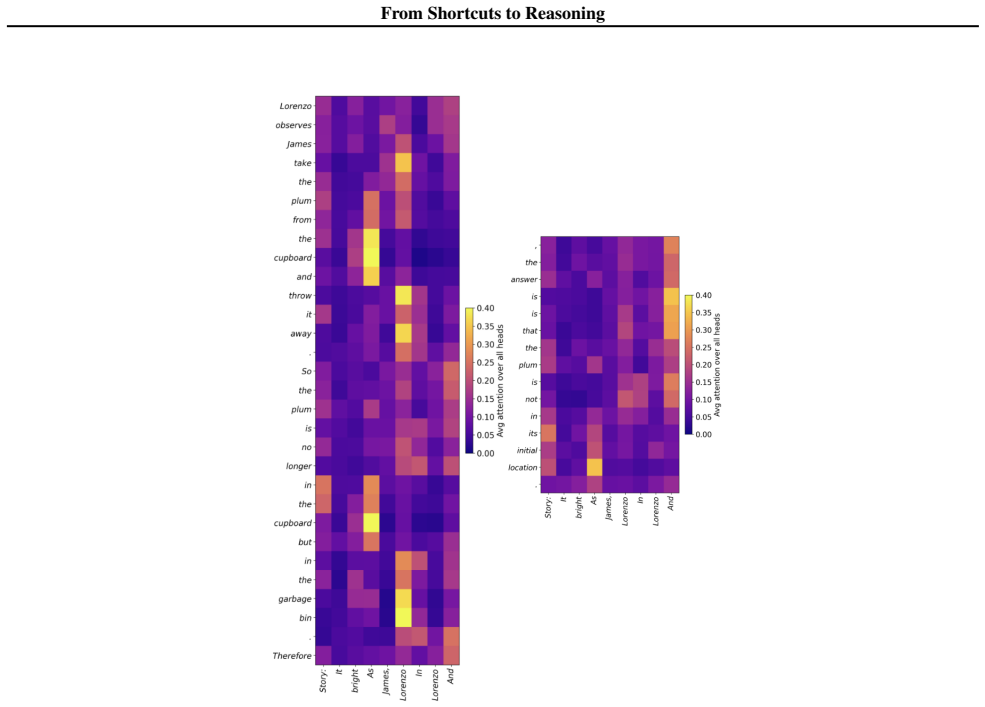
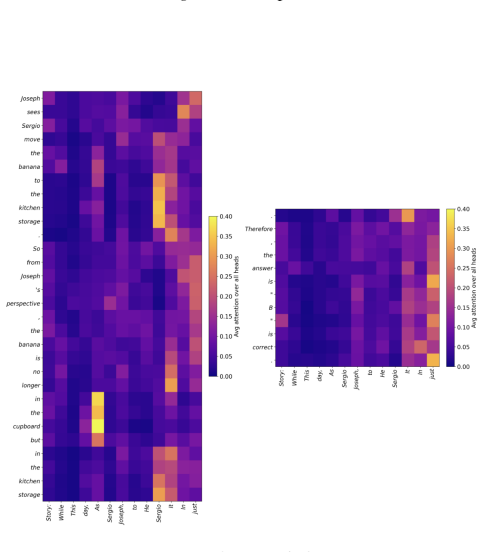
read the original abstract
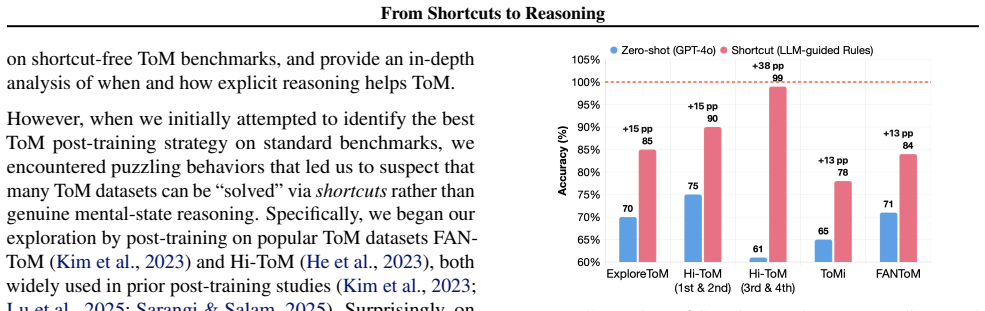
Theory of Mind (ToM) is a must-acquire skill for modern foundation model systems to operate effectively and safely in the real world. Recent works have explored honing ToM via post-training; however, we show that such progress is confounded by a pervasive "shortcut" issue: tasks can reach up to 99% accuracy by simply exploiting spurious causal correlations, leading to a false sense of ToM. Motivated by this, we first develop a framework to systematically examine ToM datasets for shortcuts and provide guidance for future development. We find that questions reducible to pure state tracking, such as "belief," are especially shortcut-prone compared to mind questions, such as "intention," where reasoning beyond tracking is required. Using four shortcut-free datasets across three ToM contexts, we then comprehensively study whether Reinforcement Fine-Tuning with verifiable rewards and explicit reasoning chains, called Thinking-RFT, elevates ToM beyond Supervised Fine-Tuning, or SFT. Our key findings are as follows. First, Thinking-RFT effectively improves ToM in all scenarios, with a 6% improvement over SFT, particularly in complex higher-order reasoning, with a 10% improvement over SFT, and multimodal cases, with a 7% improvement over SFT. It also generalizes notably better to unseen domains and higher-order queries while being more robust to counterfactuals. Second, ToM benefits specifically from the joint effect of reasoning and RL: Thinking-RFT outperforms Non-Thinking-RFT by 7% on average. Third, RFT works by learning to ground its reasoning on anchor cues, such as keywords and state changes, that correspond to causal factors. We believe our study is useful for developing effective and robust ToM post-training datasets and advancing critical ToM capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Theory of Mind (ToM) post-training is confounded by pervasive shortcuts allowing up to 99% accuracy via spurious correlations rather than reasoning. It introduces a framework to systematically detect such shortcuts in ToM datasets, identifies that belief questions are especially prone compared to intention questions, selects four shortcut-free datasets across three contexts, and shows that Thinking-RFT (reinforcement fine-tuning with verifiable rewards and explicit reasoning chains) improves ToM by 6% over SFT (10% on higher-order reasoning, 7% on multimodal), with superior generalization to unseen domains/higher-order queries and robustness to counterfactuals. It further finds that gains require the joint effect of reasoning and RL (outperforming Non-Thinking-RFT by 7%) and that RFT succeeds by grounding on causal anchor cues.
Significance. If the shortcut-freeness claims hold and gains are attributable to reasoning rather than residual correlations, the work would meaningfully advance robust ToM capabilities by providing both a detection framework/guidance for dataset construction and an RL-based post-training approach that promotes genuine causal grounding over state tracking. The comparative design against SFT and Non-Thinking-RFT baselines, plus emphasis on verifiable rewards, strengthens the case for the method's utility in ML post-training.
major comments (2)
- [§3 (Shortcut Detection Framework)] §3 (Shortcut Detection Framework): The central claim that the four selected datasets are shortcut-free—and thus that the 6%/10%/7% gains reflect reasoning improvements—rests on the asserted systematic examination framework, yet the manuscript supplies no concrete checks, examples of ruled-out state-tracking shortcuts, or quantitative verification (e.g., accuracy of a pure state-tracking baseline on the chosen datasets). This is load-bearing for attributing results to ToM rather than spurious correlations.
- [Results tables] Results tables (e.g., those reporting the 6% overall, 10% higher-order, and 7% multimodal gains): The reported improvements lack error bars, number of runs, or statistical significance tests, undermining confidence that the gains over SFT and Non-Thinking-RFT are reliable rather than variance-driven, especially given the generalization and counterfactual robustness claims.
minor comments (2)
- [Dataset description section] Clarify the precise construction and differences between the four datasets and the three ToM contexts in the main text or a dedicated table, as the abstract references them without enumeration.
- [§3] The distinction between belief (shortcut-prone) and intention (reasoning-required) questions is stated but would benefit from an explicit example of a ruled-out shortcut in each category.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We believe the comments help strengthen the paper's claims regarding shortcut detection and result reliability. Below we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [§3 (Shortcut Detection Framework)] §3 (Shortcut Detection Framework): The central claim that the four selected datasets are shortcut-free—and thus that the 6%/10%/7% gains reflect reasoning improvements—rests on the asserted systematic examination framework, yet the manuscript supplies no concrete checks, examples of ruled-out state-tracking shortcuts, or quantitative verification (e.g., accuracy of a pure state-tracking baseline on the chosen datasets). This is load-bearing for attributing results to ToM rather than spurious correlations.
Authors: We agree that providing concrete verification is important for substantiating the shortcut-free nature of the datasets. The framework in §3 outlines the systematic process for detecting shortcuts, including distinguishing belief questions (prone to state-tracking) from intention questions. To address this, in the revision we will include specific examples of shortcuts that were ruled out for each dataset and report the performance of a pure state-tracking baseline model on the four selected datasets to quantitatively confirm low accuracy indicative of shortcut absence. revision: yes
-
Referee: Results tables (e.g., those reporting the 6% overall, 10% higher-order, and 7% multimodal gains): The reported improvements lack error bars, number of runs, or statistical significance tests, undermining confidence that the gains over SFT and Non-Thinking-RFT are reliable rather than variance-driven, especially given the generalization and counterfactual robustness claims.
Authors: We acknowledge the value of reporting variability and statistical measures for robustness. The experiments were conducted with multiple random seeds, but the variance was not reported in the tables. In the revised manuscript, we will add error bars based on multiple runs, specify the number of runs, and include statistical significance tests (e.g., paired t-tests) where appropriate to support the reported gains. revision: yes
Circularity Check
No circularity: empirical comparison on examined datasets
full rationale
The paper is a comparative empirical study that develops a shortcut-examination framework, selects four datasets, and reports performance deltas (6% overall, 10% higher-order, 7% multimodal) for Thinking-RFT versus SFT and Non-Thinking-RFT baselines. No equations, fitted parameters, or derivations are shown that reduce the reported gains to inputs by construction. Dataset shortcut-freeness is asserted via the framework rather than derived from the results themselves. No self-citation chains, ansatzes, or renamings appear in the provided text. The central claims rest on external verification of the datasets and baselines, making the work self-contained against the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
arXiv preprint arXiv:2402.06044 , year=
OpenToM: A comprehensive benchmark for evaluating theory-of-mind reasoning capabilities of large language models , author=. arXiv preprint arXiv:2402.06044 , year=
-
[10]
Leibler , title =
Solomon Kullback and Richard A. Leibler , title =. The annals of mathematical statistics , year=
-
[11]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[12]
2025 , howpublished =
2025
-
[13]
Conference on Neural Information Processing Systems , year=
Think or not think: A study of explicit thinking in rule-based visual reinforcement fine-tuning , author=. Conference on Neural Information Processing Systems , year=
-
[14]
Premack, David and Woodruff, Guy , booktitle=
-
[15]
Cognition , year=
Beliefs about beliefs: representation and constraining function of wrong beliefs in young children's understanding of deception , author=. Cognition , year=
-
[16]
arXiv preprint arXiv:2507.18071 , year=
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
-
[17]
arXiv preprint arXiv:2503.14476 , year=
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
-
[18]
International Conference on Machine Learning , year =
Chunhui Zhang and Zhongyu Ouyang and Kwonjoon Lee and Nakul Agarwal and Sean Dae Houlihan and Soroush Vosoughi and Shao-Yuan Lo , title =. International Conference on Machine Learning , year =
-
[19]
Dennett , title =
Daniel C. Dennett , title =. Behavioral and Brain Sciences , year =
-
[20]
arXiv preprint arXiv:2504.13914 , year=
Seed1.5-thinking: Advancing superb reasoning models with reinforcement learning , author=. arXiv preprint arXiv:2504.13914 , year=
-
[21]
Wellman , title =
Alison Gopnik and Henry M. Wellman , title =. Psychological Bulletin , year =
-
[22]
2025 , howpublished =
OpenAI , title =. 2025 , howpublished =
2025
-
[23]
theory of mind
Does the autistic child have a "theory of mind"? , author=. Cognition , year=
-
[24]
International Conference on Machine Learning , year=
Machine Theory of Mind , author=. International Conference on Machine Learning , year=
-
[25]
Artificial Intelligence , year=
Autonomous agents modelling other agents: A comprehensive survey and open problems , author=. Artificial Intelligence , year=
-
[26]
Conference on Empirical Methods in Natural Language Processing , year=
Revisiting the Evaluation of Theory of Mind through Question Answering , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[27]
Sap, Maarten and Rashkin, Hannah and Chen, Derek and Le Bras, Ronan and Choi, Yejin , booktitle=. Social. 2019 , doi=
2019
-
[28]
Conference on Empirical Methods in Natural Language Processing , year=
Neural Theory-of-Mind? On the Limits of Social Intelligence in Large LMs , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[29]
Annual Meeting of the Association for Computational Linguistics , year=
Minding Language Models' (Lack of) Theory of Mind: A Plug-and-Play Multi-Character Belief Tracker , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[30]
arXiv preprint arXiv:2302.02083 , year=
Theory of mind may have spontaneously emerged in large language models , author=. arXiv preprint arXiv:2302.02083 , year=
-
[31]
, journal=
Bubeck, Sébastien and Chandrasekaran, Varun and Eldan, Ronen and et al. , journal=. Sparks of artificial general intelligence: Early experiments with
-
[32]
arXiv preprint arXiv:2302.08399 , year=
Large language models fail on trivial alterations to theory-of-mind tasks , author=. arXiv preprint arXiv:2302.08399 , year=
-
[33]
Conference on Neural Information Processing Systems , year=
Understanding Social Reasoning in Language Models with BigToM , author=. Conference on Neural Information Processing Systems , year=
-
[34]
Conference on Empirical Methods in Natural Language Processing , year=
FANToM: A Benchmark for Stress-testing Machine Theory of Mind in Interactions , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[35]
arXiv preprint arXiv:2405.18870 , year=
LLMs achieve adult human performance on higher-order theory of mind tasks , author=. arXiv preprint arXiv:2405.18870 , year=
-
[36]
2024 , doi=
Chen, Zhuang and Wu, Jincenzi and Zhou, Jinfeng and Wen, Bosi and Bi, Guanqun and Jiang, Gongyao and Cao, Yaru and Hu, Mengting and Lai, Yunghwei and Xiong, Zexuan and Huang, Minlie , booktitle=. 2024 , doi=
2024
-
[37]
Annual Meeting of the Association for Computational Linguistics , year=
MMToM-QA: Multimodal Theory of Mind Question Answering , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[38]
arXiv preprint arXiv:2408.14419 , year=
CHARTOM: A Visual Theory-of-Mind Benchmark for LLMs on Misleading Charts , author=. arXiv preprint arXiv:2408.14419 , year=
-
[39]
Nature Machine Intelligence , year=
Visual cognition in multimodal large language models , author=. Nature Machine Intelligence , year=
-
[40]
Annual Meeting of the Association for Computational Linguistics , year=
Think Twice: Perspective-Taking Improves Large Language Models’ Theory-of-Mind Capabilities , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[41]
International Conference on Learning Representations , year=
Explore Theory of Mind: Program-Guided Adversarial Data Generation for Theory of Mind Reasoning , author=. International Conference on Learning Representations , year=
-
[42]
Proceedings of the National Academy of Sciences , year =
Evaluating large language models in theory-of-mind tasks , author =. Proceedings of the National Academy of Sciences , year =
-
[43]
Conference on Neural Information Processing Systems , year =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Conference on Neural Information Processing Systems , year =
-
[44]
International Conference on Learning Representations , year =
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. International Conference on Learning Representations , year =
-
[45]
International Conference on Machine Learning , year=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International Conference on Machine Learning , year=
-
[46]
arXiv preprint arXiv:2412.05271 , year=
Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling , author=. arXiv preprint arXiv:2412.05271 , year=
-
[47]
arXiv preprint arXiv:1212.0402 , year=
UCF101: A dataset of 101 human actions classes from videos in the wild , author=. arXiv preprint arXiv:1212.0402 , year=
-
[48]
Conference on Neural Information Processing Systems , year=
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? , author=. Conference on Neural Information Processing Systems , year=
-
[49]
arXiv preprint arXiv:2503.07536 , year=
Lmm-r1: Empowering 3b lmms with strong reasoning abilities through two-stage rule-based rl , author=. arXiv preprint arXiv:2503.07536 , year=
-
[50]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , year=
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , year=
-
[51]
Conference on Computer Vision and Pattern Recognition , year=
Describing textures in the wild , author=. Conference on Computer Vision and Pattern Recognition , year=
-
[52]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Sun database: Large-scale scene recognition from abbey to zoo , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[53]
Conference on Neural Information Processing Systems , year=
Pytorch: An imperative style, high-performance deep learning library , author=. Conference on Neural Information Processing Systems , year=
-
[54]
International Conference on Machine Learning , year=
MME-CoT: Benchmarking Chain-of-Thought in Large Multimodal Models for Reasoning Quality, Robustness, and Efficiency , author=. International Conference on Machine Learning , year=
-
[55]
arXiv preprint arXiv:2309.16609 , year=
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
-
[56]
International Conference on Machine Learning , year=
Learning transferable visual models from natural language supervision , author=. International Conference on Machine Learning , year=
-
[57]
International Conference on Learning Representations , year=
To cot or not to cot? chain-of-thought helps mainly on math and symbolic reasoning , author=. International Conference on Learning Representations , year=
-
[58]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Lisa: Reasoning segmentation via large language model , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[59]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Generation and comprehension of unambiguous object descriptions , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[60]
European Conference on Computer Vision , year=
Modeling context in referring expressions , author=. European Conference on Computer Vision , year=
-
[61]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Imagenet: A large-scale hierarchical image database , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[62]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[63]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Cats and dogs , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[64]
IEEE/CVF International Conference on Computer Vision Workshops , year=
3d object representations for fine-grained categorization , author=. IEEE/CVF International Conference on Computer Vision Workshops , year=
-
[65]
arXiv preprint arXiv:2412.16720 , year=
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
-
[66]
arXiv preprint arXiv:2502.21321 , year=
Llm post-training: A deep dive into reasoning large language models , author=. arXiv preprint arXiv:2502.21321 , year=
-
[67]
arXiv preprint arXiv:2507.15788 , year=
Small LLMs Do Not Learn a Generalizable Theory of Mind via Reinforcement Learning , author=. arXiv preprint arXiv:2507.15788 , year=
-
[68]
arXiv preprint arXiv:2412.07755 , year=
SAT: Spatial Aptitude Training for Multimodal Language Models , author=. arXiv preprint arXiv:2412.07755 , year=
-
[69]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[70]
arXiv preprint arXiv:2503.13939 , year=
Med-r1: Reinforcement learning for generalizable medical reasoning in vision-language models , author=. arXiv preprint arXiv:2503.13939 , year=
-
[71]
Chen, Liang and Li, Lei and Zhao, Haozhe and Song, Yifan and
-
[72]
2025 , booktitle=
AutoToM: Scaling Model-based Mental Inference via Automated Agent Modeling , author=. 2025 , booktitle=
2025
-
[73]
arXiv preprint arXiv:2503.07365 , year=
MM-Eureka: Exploring Visual Aha Moment with Rule-based Large-scale Reinforcement Learning , author=. arXiv preprint arXiv:2503.07365 , year=
-
[74]
arXiv preprint arXiv:2503.06749 , year=
Vision-r1: Incentivizing reasoning capability in multimodal large language models , author=. arXiv preprint arXiv:2503.06749 , year=
-
[75]
arXiv preprint arXiv:2504.07615 , year=
Vlm-r1: A stable and generalizable r1-style large vision-language model , author=. arXiv preprint arXiv:2504.07615 , year=
-
[76]
International Conference on Computer Vision , year=
Visual-rft: Visual reinforcement fine-tuning , author=. International Conference on Computer Vision , year=
-
[77]
arXiv preprint arXiv:2409.12191 , year=
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author=. arXiv preprint arXiv:2409.12191 , year=
-
[79]
arXiv preprint arXiv:2501.17161 , year=
Sft memorizes, rl generalizes: A comparative study of foundation model post-training , author=. arXiv preprint arXiv:2501.17161 , year=
-
[80]
arXiv preprint arXiv:2403.03864 , year=
Are language models puzzle prodigies? algorithmic puzzles unveil serious challenges in multimodal reasoning , author=. arXiv preprint arXiv:2403.03864 , year=
-
[81]
arXiv preprint arXiv:2403.13315 , year=
Puzzlevqa: Diagnosing multimodal reasoning challenges of language models with abstract visual patterns , author=. arXiv preprint arXiv:2403.13315 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.