State commitment learning: training language models to distinguish computation from memory
Pith reviewed 2026-06-30 15:19 UTC · model grok-4.3
The pith
Counterfactual erasure rewards train language models to keep answers correct after hidden thoughts are removed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
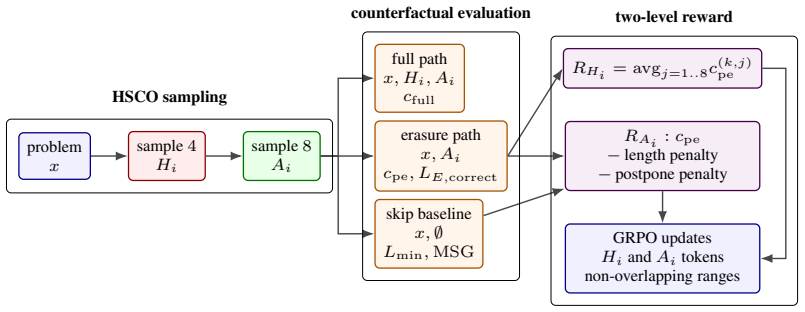
By evaluating both a keep-hidden-thoughts path and an erase-hidden-thoughts path under identical prefixes and assigning reward exclusively to the erase path when it remains correct, CERL produces models whose final answers satisfy persistent-state sufficiency, thereby reducing measurable dependence on uncommitted scratch work without loss of task performance.
What carries the argument
Counterfactual Erasure RL (CERL) paired with the Erasure Dependence Protocol: CERL compares keep and erase trajectories and rewards only when the erase trajectory succeeds; the protocol quantifies how much final answers change when hidden thoughts are removed.
If this is right
- Models can safely discard intermediate reasoning tokens from context without invalidating downstream predictions.
- Error propagation from failed attempts or dead-end explorations is reduced in multi-step tasks.
- Multi-turn tool-use interactions become less sensitive to private scratch work carried across turns.
- Training objectives can be extended to other forms of state commitment beyond erasure, such as selective summarization of prior steps.
Where Pith is reading between the lines
- The same erasure-reward structure could be applied to non-text modalities where intermediate activations should not influence later outputs.
- If persistent-state sufficiency holds, it may become feasible to audit or compress model traces by removing non-committed segments without re-running the full task.
- The protocol offers a quantitative handle on how much of a model's 'thinking' is actually required for the answer versus disposable.
Load-bearing premise
That it is possible to define and measure a counterfactual erasure path such that rewarding success on that path reliably produces answers whose correctness does not depend on the erased content.
What would settle it
After CERL training, remove the hidden thoughts from a set of model generations and check whether accuracy on the original tasks drops by more than a few percent or whether the answers change substantively.
Figures

read the original abstract
Reasoning language models do not distinguish tokens used for computation from tokens that constitute persistent state: once generated, all hidden thoughts remain in context and influence future predictions. As a result, downstream reasoning may depend on failed attempts, dead ends, and private scratch work that should not be safely relied on later. We recast this phenomenon as a new training objective, state commitment learning: training models to explicitly distinguish information that should be committed as persistent state from temporary computation that can be discarded. We define a counterfactual criterion, persistent-state sufficiency, which makes it trainable and measurable whether an answer remains usable after hidden thoughts are erased. We then propose Counterfactual Erasure RL (CERL), which evaluates, under the same prefix, both a path that keeps hidden thoughts and a path that erases them, and gives reward only when the erasure path remains correct. We also introduce the Erasure Dependence Protocol and show across mathematics, long-chain logic, scientific QA, and multi-turn tool-use evaluation that CERL substantially reduces answer dependence on hidden thoughts without sacrificing accuracy, consistently outperforming correctness-only RL and long-answer SFT baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces state commitment learning as a training objective for reasoning language models to distinguish temporary computation tokens from persistent state that should be committed. It defines a counterfactual persistent-state sufficiency criterion and proposes Counterfactual Erasure RL (CERL), which rewards erasure paths that remain correct under the same prefix. The Erasure Dependence Protocol is presented, with claims of substantial reductions in answer dependence on hidden thoughts across mathematics, long-chain logic, scientific QA, and multi-turn tool-use tasks, without accuracy loss and outperforming correctness-only RL and long-answer SFT baselines.
Significance. If the empirical claims hold under the described protocol, the work provides a concrete, trainable mechanism to mitigate reliance on scratch work or failed attempts in CoT reasoning. This could improve reliability and interpretability of reasoning models. The counterfactual framing and multi-domain evaluation protocol are strengths that, if reproducible, would support broader adoption in safety-critical applications.
major comments (2)
- The abstract claims consistent outperformance and reduced dependence, but without access to the full experimental details (e.g., exact reward formulation in CERL, how erasure is implemented without prefix confounds, or statistical significance of the Erasure Dependence Protocol results), the load-bearing claim that the counterfactual criterion produces usable answers post-erasure cannot be verified.
- The weakest assumption noted—that persistent-state sufficiency can be reliably defined and measured—requires explicit validation in the methods section; if the erasure path introduces new artifacts (e.g., altered token distributions), the reward signal may not isolate the intended distinction.
minor comments (2)
- Clarify the precise definition of 'erasure' in the protocol (e.g., token removal vs. masking) and how it interacts with model context windows.
- Provide baseline details for long-answer SFT to ensure fair comparison of answer length and content.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental details and the validation of core assumptions. We respond to each major comment below.
read point-by-point responses
-
Referee: The abstract claims consistent outperformance and reduced dependence, but without access to the full experimental details (e.g., exact reward formulation in CERL, how erasure is implemented without prefix confounds, or statistical significance of the Erasure Dependence Protocol results), the load-bearing claim that the counterfactual criterion produces usable answers post-erasure cannot be verified.
Authors: The manuscript details the CERL reward formulation in Section 3.2 (Equation 3), erasure implementation in Section 4.1 (ensuring identical prefixes for both paths to avoid confounds), and statistical significance in Appendix B (including p-values from paired tests and confidence intervals on the Erasure Dependence Protocol). These support the post-erasure usability claim across the reported domains. We will add pseudocode for the full CERL procedure to the methods for greater clarity. revision: partial
-
Referee: The weakest assumption noted—that persistent-state sufficiency can be reliably defined and measured—requires explicit validation in the methods section; if the erasure path introduces new artifacts (e.g., altered token distributions), the reward signal may not isolate the intended distinction.
Authors: We agree that explicit validation belongs in the methods. A new subsection (3.4) will be added with controlled experiments that measure token distribution shifts after erasure and confirm the reward isolates the persistent-state sufficiency criterion. Ablations in the revised Appendix C show that any artifacts do not materially affect the distinction. revision: yes
Circularity Check
No significant circularity
full rationale
The paper defines a new objective (state commitment learning) via a counterfactual criterion (persistent-state sufficiency) and implements it as CERL, which rewards only when the erasure path remains correct. The abstract and description present this as an explicit training signal with an accompanying Erasure Dependence Protocol for measurement. No equations, self-citations, or derivations are supplied that reduce the claimed outperformance or the criterion itself to the inputs by construction. The reported results on mathematics, logic, QA, and tool-use evaluations are treated as independent empirical tests rather than forced by the definition of the reward. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Persistent-state sufficiency is a well-defined, measurable counterfactual property that can serve as a training signal.
invented entities (3)
-
State commitment learning
no independent evidence
-
Counterfactual Erasure RL (CERL)
no independent evidence
-
Erasure Dependence Protocol
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Think clearly: Improving reasoning via redundant token pruning
Daewon Choi, Jimin Lee, Jihoon Tack, Woomin Song, Saket Dingliwal, Sai Muralidhar Jayanthi, Bhavana Ganesh, Jinwoo Shin, Aram Galstyan, and Sravan Babu Bodapati. Think clearly: Improving reasoning via redundant token pruning. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Findings of the Association for Computa...
-
[2]
Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines, 2014. URL https://arxiv.org/abs/1410.5401
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[3]
Hybrid computing using a neural network with dynamic external memory
Alex Graves, Greg Wayne, Malcolm Reynolds, Tim Harley, Ivo Danihelka, Agnieszka Grabska-Barwińska, Sergio Gómez Colmenarejo, Edward Grefenstette, Tiago Ramalho, John Agapiou, Adrià Puigdomènech Badia, Karl Moritz Hermann, Yori Zwols, Georg Ostrovski, Adam Cain, Helen King, Christopher Summerfield, Phil Blunsom, Koray Kavukcuoglu, and Demis Hassabis. Hybri...
-
[4]
Michael Hassid, Gabriel Synnaeve, Yossi Adi, and Roy Schwartz. Don't overthink it. preferring shorter thinking chains for improved llm reasoning, 2026. URL https://arxiv.org/abs/2505.17813
-
[5]
Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning, 2025. URL https://arxiv.org/abs/2504.11456
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Kava: Latent reasoning via compressed KV -cache distillation
Anna Kuzina, Maciej Pi \'o ro, and Babak Ehteshami Bejnordi. Kava: Latent reasoning via compressed KV -cache distillation. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=ePrhcLbtGv
2026
-
[7]
Snapkv: Llm knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Advances in Neural Information Processing Systems, volume 37, pages 229...
-
[8]
Limited reasoning space: The cage of long-horizon reasoning in llms, 2026
Zhenyu Li, Guanlin Wu, Cheems Wang, and Yongqiang Zhao. Limited reasoning space: The cage of long-horizon reasoning in llms, 2026. URL https://arxiv.org/abs/2602.19281
-
[9]
Z ebra L ogic: On the scaling limits of LLM s for logical reasoning
Bill Yuchen Lin, Ronan Le Bras, Kyle Richardson, Ashish Sabharwal, Radha Poovendran, Peter Clark, and Yejin Choi. Z ebra L ogic: On the scaling limits of LLM s for logical reasoning. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors, Proceedings of the 42nd International ...
2025
-
[10]
Through the valley: Path to effective long C o T training for small language models
Renjie Luo, Jiaxi Li, Chen Huang, and Wei Lu. Through the valley: Path to effective long C o T training for small language models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 4972--4992, Suzhou, China, November 2025...
-
[11]
Learning to compress prompts with gist tokens
Jesse Mu, Xiang Li, and Noah Goodman. Learning to compress prompts with gist tokens. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 19327--19352. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/3d77c6dcc7f143a...
2023
-
[12]
Gonzalez
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard ( BFCL ): From tool use to agentic evaluation of large language models. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, e...
2025
-
[13]
Thin KV : Thought-adaptive KV cache compression for efficient reasoning models
Akshat Ramachandran, Marina Neseem, Charbel Sakr, Rangharajan Venkatesan, Brucek Khailany, and Tushar Krishna. Thin KV : Thought-adaptive KV cache compression for efficient reasoning models. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=M3CeHnZKNC
2026
-
[14]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA : A graduate-level google-proof q&a benchmark. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=Ti67584b98
2024
-
[15]
When more is less: Understanding chain-of-thought length in LLM s
Yuyang Wu, Yifei Wang, Ziyu Ye, Tianqi Du, Stefanie Jegelka, and Yisen Wang. When more is less: Understanding chain-of-thought length in LLM s. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=6QDFsYxtI1
2026
-
[16]
T oken S kip: Controllable chain-of-thought compression in LLM s
Heming Xia, Chak Tou Leong, Wenjie Wang, Yongqi Li, and Wenjie Li. T oken S kip: Controllable chain-of-thought compression in LLM s. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 3351--3363, Suzhou, China, November 20...
-
[17]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Haoyue Zhang, Hualei Zhang, Xiaosong Ma, Jie Zhang, and Song Guo. Lazyeviction: Lagged kv eviction with attention pattern observation for efficient long reasoning, 2025 a . URL https://arxiv.org/abs/2506.15969
-
[19]
L ight T hinker: Thinking step-by-step compression
Jintian Zhang, Yuqi Zhu, Mengshu Sun, Yujie Luo, Shuofei Qiao, Lun Du, Da Zheng, Huajun Chen, and Ningyu Zhang. L ight T hinker: Thinking step-by-step compression. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 13307--...
-
[20]
H2o: Heavy-hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher R\\' e , Clark Barrett, Zhangyang "Atlas" Wang, and Beidi Chen. H2o: Heavy-hitter oracle for efficient generative inference of large language models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances...
2023
-
[21]
The curse of cot: On the limitations of chain-of-thought in in-context learning
Tianshi Zheng, Yixiang Chen, Chengxi Li, Chunyang Li, Qing Zong, Haochen Shi, Baixuan Xu, Yangqiu Song, Ginny Wong, and Simon See. The curse of cot: On the limitations of chain-of-thought in in-context learning. Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https://openreview.net/forum?id=7SIrvcYNYj
2025
-
[22]
Qin Zhu, Fei Huang, Runyu Peng, Keming Lu, Bowen Yu, Qinyuan Cheng, Xipeng Qiu, Xuanjing Huang, and Junyang Lin. Autologi: Automated generation of logic puzzles for evaluating reasoning abilities of large language models, 2025. URL https://arxiv.org/abs/2502.16906
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.