A Stitch in Time Saves Nine: Preserving Policy Compatibility Under Perception Updates in End-to-End Autonomous Driving
Pith reviewed 2026-06-26 14:23 UTC · model grok-4.3
The pith
Lightweight stitching aligns updated perception outputs to frozen driving policies without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
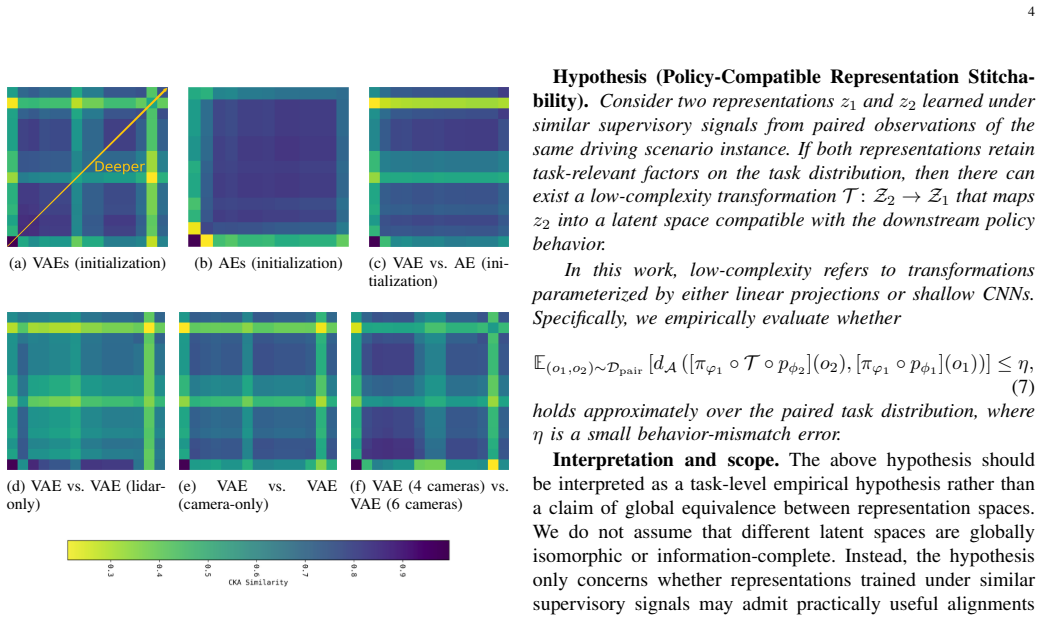
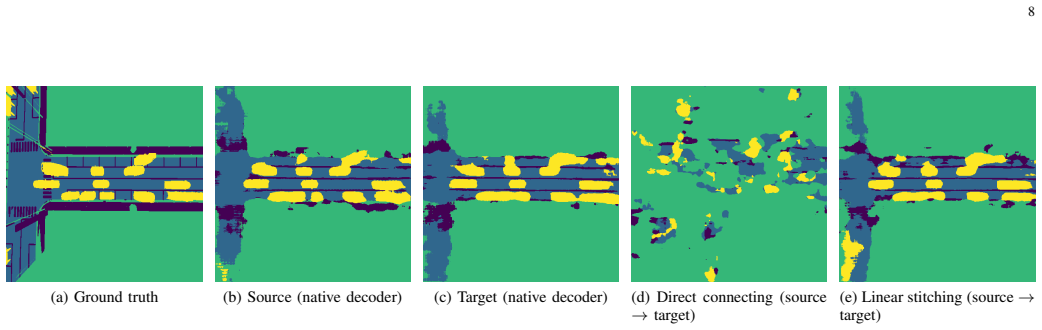
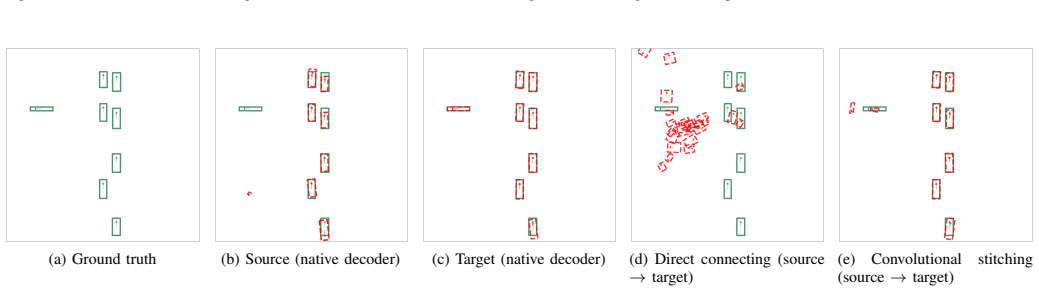
The paper claims that low-complexity latent-space stitchers can restore compatibility between updated perception modules and unchanged downstream policies, providing an efficient alternative to retraining for maintaining end-to-end autonomous driving systems under perception updates.
What carries the argument
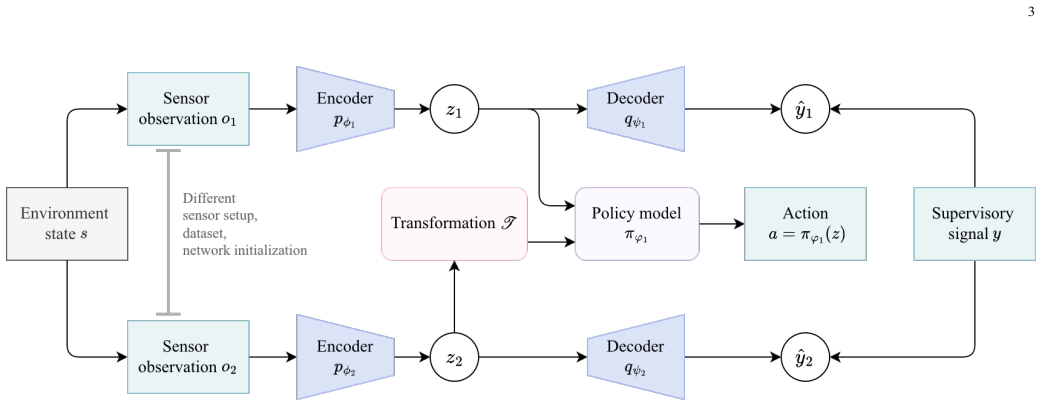
Low-complexity model stitchers (linear and convolutional) that map latent representations from an updated perception module onto the input distribution expected by the original policy.
If this is right
- A driving policy can remain frozen while its perception module is replaced or retrained on new data.
- Adaptation cost drops from full policy retraining to training only a small stitcher network.
- The same stitching approach works for changes in random initialization, sensor configuration, and training domain.
- Convolutional stitchers recover higher driving scores than linear ones when the domain shift is large.
Where Pith is reading between the lines
- The method could apply to any modular pipeline where one stage is updated more frequently than the others.
- Deployed vehicles might receive perception updates through small stitcher downloads rather than full system flashes.
- Stitcher training could be performed on a small held-out set collected after the perception change rather than requiring new full-scale data collection.
Load-bearing premise
Latent features produced by an updated perception module remain close enough to the original features that a simple linear or convolutional mapping can recover the information the fixed policy needs for driving decisions.
What would settle it
A side-by-side closed-loop driving test in which the stitched system produces a route-completion or collision-avoidance score more than 10 percent lower than the unshifted baseline under the same cross-domain perception change.
Figures

read the original abstract
End-to-end autonomous driving systems tightly couple perception and decision-making through latent representations. Consequently, updates to perception models can alter these representations and degrade the performance of downstream policies that remain fixed. Existing solutions typically rely on policy retraining or architectural decoupling, both of which incur substantial computation and validation costs. In this paper, we formulate the model stitching problem for end-to-end autonomous driving and test the hypothesis that policy compatibility can be preserved through lightweight latent-space alignment. We study low-complexity model stitching methods, including linear and convolutional stitchers, for restoring compatibility between updated perception modules and frozen downstream policy modules. Experiments demonstrate that stitching effectively preserves downstream driving behavior under diverse perception updates, including changes in random initialization, sensor configuration, and training domain. In the most challenging cross-domain setting from nuScenes to CARLA, convolutional stitching retains over 91\% of the no-shift driving score while reducing adaptation time from \SI{22.18}{h} to \SI{0.91}{h}. These results suggest that model stitching provides an effective and computationally efficient alternative to retraining or fine-tuning for maintaining end-to-end autonomous driving systems. The model will be open-sourced upon paper acceptance at https://github.com/SCP-CN-001/model-stitching to support further research and development in autonomous driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates model stitching for end-to-end autonomous driving to preserve compatibility between updated perception modules and frozen downstream policies via lightweight latent-space alignment. It evaluates low-complexity linear and convolutional stitchers under perception changes including random initialization, sensor configuration, and training domain shifts. In the nuScenes-to-CARLA cross-domain case, convolutional stitching is reported to retain over 91% of the no-shift driving score while cutting adaptation time from 22.18 h to 0.91 h, positioning stitching as an efficient alternative to policy retraining.
Significance. If the empirical results hold under the stated conditions, the approach would provide a low-overhead mechanism for updating perception components without full policy retraining, which is practically significant for long-term maintenance of end-to-end driving systems. The commitment to open-source the model upon acceptance strengthens reproducibility.
major comments (2)
- [cross-domain experiment description (abstract and §4)] The central efficiency claim (0.91 h adaptation in the nuScenes-to-CARLA setting) depends on the data regime used to train the stitchers. The manuscript does not specify whether stitcher training requires paired old/new perception outputs on the same target-domain scenes; if paired target data is needed, the reported time saving no longer represents a zero-cost compatibility patch and the comparison to full retraining becomes unclear.
- [§3 and experimental results] The assumption that low-complexity (linear or convolutional) stitchers can align updated perception latents to the policy's expected input distribution without loss of safety-critical information is load-bearing for the 91% retention result, yet no quantitative analysis of information loss or failure modes under distribution shift is provided.
minor comments (2)
- [§3] Notation for the stitcher mapping (e.g., definition of the latent alignment objective) should be introduced with an equation in §3 for clarity.
- [abstract] The abstract states that the model will be open-sourced; the camera-ready version should include the exact GitHub link and a reproducibility checklist.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below with clarifications and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [cross-domain experiment description (abstract and §4)] The central efficiency claim (0.91 h adaptation in the nuScenes-to-CARLA setting) depends on the data regime used to train the stitchers. The manuscript does not specify whether stitcher training requires paired old/new perception outputs on the same target-domain scenes; if paired target data is needed, the reported time saving no longer represents a zero-cost compatibility patch and the comparison to full retraining becomes unclear.
Authors: We appreciate this request for clarification on the data regime. In the reported experiments, stitcher training does use paired outputs from the original and updated perception modules collected on identical target-domain (CARLA) scenes to supervise the latent alignment. This is not a zero-cost patch in terms of data access, but the overall procedure remains substantially more efficient than policy retraining because only the lightweight stitcher is optimized while the policy stays frozen. The 0.91 h figure already incorporates target-domain data collection and stitcher training. We will revise §4 and the abstract to explicitly describe this paired-data requirement and provide a more precise efficiency comparison that acknowledges the data cost while retaining the claim of major computational savings relative to the 22.18 h baseline. revision: yes
-
Referee: [§3 and experimental results] The assumption that low-complexity (linear or convolutional) stitchers can align updated perception latents to the policy's expected input distribution without loss of safety-critical information is load-bearing for the 91% retention result, yet no quantitative analysis of information loss or failure modes under distribution shift is provided.
Authors: We agree that direct quantitative support for information preservation would strengthen the paper. The >91% retention of the no-shift driving score (which includes collision rate, route completion, and other safety-sensitive metrics) provides indirect evidence that critical information is retained, but we will add explicit analysis in the revision. This will include metrics such as maximum mean discrepancy between original and stitched latent distributions, as well as a discussion of observed failure modes when stitching is applied under stronger distribution shifts. These additions will appear in the revised §3 and experimental results. revision: yes
Circularity Check
No circularity: results rest on empirical experiments, not derivations reducing to inputs
full rationale
The paper presents an empirical study of model stitching for preserving policy compatibility in end-to-end driving under perception updates. It formulates the stitching problem, applies linear and convolutional stitchers, and reports measured outcomes such as retained driving scores and reduced adaptation times across settings including nuScenes-to-CARLA transfer. No derivation chain, equations, or first-principles predictions are claimed; the central results are obtained from direct experimentation rather than any fitted parameter renamed as a prediction or any self-citation chain that collapses the claim. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Latent representations from perception modules can be aligned using simple linear or convolutional transformations to restore compatibility with fixed policies.
Reference graph
Works this paper leans on
-
[1]
Global ev outlook 2026,
International Energy Agency, “Global ev outlook 2026,” 2026, accessed: 2026-06-17. [Online]. Available: https://www.iea.org/reports/global-ev-outlook-2026
2026
-
[2]
A survey of end-to-end driving: Archi- tectures and training methods,
A. Tampuu, T. Matiisen, M. Semikin, D. Fishman, and N. Muhammad, “A survey of end-to-end driving: Archi- tectures and training methods,”IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 4, pp. 1364–1384, 2020. 10
2020
-
[3]
End-to-end autonomous driving: Challenges and frontiers,
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, “End-to-end autonomous driving: Challenges and frontiers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 10 164–10 183, 2024
2024
-
[4]
Driving policy transfer via modularity and abstraction,
M. M ¨uller, A. Dosovitskiy, B. Ghanem, and V . Koltun, “Driving policy transfer via modularity and abstraction,” arXiv preprint arXiv:1804.09364, 2018
Pith/arXiv arXiv 2018
-
[5]
Fine-tuning can distort pretrained features and underperform out-of-distribution,
A. Kumar, A. Raghunathan, R. Jones, T. Ma, and P. Liang, “Fine-tuning can distort pretrained features and underperform out-of-distribution,”arXiv preprint arXiv:2202.10054, 2022
arXiv 2022
-
[6]
Deep transfer learning for intelligent vehicle perception: A survey,
X. Liu, J. Li, J. Ma, H. Sun, Z. Xu, T. Zhang, and H. Yu, “Deep transfer learning for intelligent vehicle perception: A survey,”Green Energy and Intelligent Transportation, vol. 2, no. 5, p. 100125, 2023
2023
-
[7]
Curse of rarity for autonomous vehicles,
H. X. Liu and S. Feng, “Curse of rarity for autonomous vehicles,”nature communications, vol. 15, no. 1, p. 4808, 2024
2024
-
[8]
Effective adaptation in multi-task co-training for unified autonomous driving,
X. Liang, Y . Wu, J. Han, H. Xu, C. Xu, and X. Liang, “Effective adaptation in multi-task co-training for unified autonomous driving,”Advances in Neural Information Processing Systems, vol. 35, pp. 19 645–19 658, 2022
2022
-
[9]
Parameter-efficient transfer learning for nlp,
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Mor- rone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for nlp,” inInternational conference on machine learning. PMLR, 2019, pp. 2790–2799
2019
-
[10]
Adapterhub: A framework for adapting transformers,
J. Pfeiffer, A. R ¨uckl´e, C. Poth, A. Kamath, I. Vuli ´c, S. Ruder, K. Cho, and I. Gurevych, “Adapterhub: A framework for adapting transformers,” inProceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, 2020, pp. 46–54
2020
-
[11]
Broad feature alignment for robotic ground classifica- tion in dynamic environment,
S. Liu, Y . Wu, W. Lv, J. Chang, Z. Li, and W. Zhang, “Broad feature alignment for robotic ground classifica- tion in dynamic environment,”IEEE Transactions on Industrial Electronics, vol. 69, no. 3, pp. 2697–2707, 2021
2021
-
[12]
Vad: Vectorized scene representation for efficient autonomous driving,
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Vad: Vectorized scene representation for efficient autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8340–8350
2023
-
[13]
A knowledge-driven, generalizable decision- making framework for autonomous driving via cognitive representation alignment,
H. Lu, J. Yang, M. Zhu, C. Lu, X. Chen, X. Zheng, and H. Yang, “A knowledge-driven, generalizable decision- making framework for autonomous driving via cognitive representation alignment,”Transportation Research Part C: Emerging Technologies, vol. 172, p. 105030, 2025
2025
-
[14]
Driveadapter: Breaking the coupling barrier of percep- tion and planning in end-to-end autonomous driving,
X. Jia, Y . Gao, L. Chen, J. Yan, P. L. Liu, and H. Li, “Driveadapter: Breaking the coupling barrier of percep- tion and planning in end-to-end autonomous driving,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 7953–7963
2023
-
[15]
Learning by cheating,
D. Chen, B. Zhou, V . Koltun, and P. Kr ¨ahenb¨uhl, “Learning by cheating,” inConference on robot learning. PMLR, 2020, pp. 66–75
2020
-
[16]
Worl- drft: Latent world model planning with reinforcement fine-tuning for autonomous driving,
P. Yang, B. Lu, Z. Xia, C. Han, Y . Gao, T. Zhang, K. Zhan, X. Lang, Y . Zheng, and Q. Zhang, “Worl- drft: Latent world model planning with reinforcement fine-tuning for autonomous driving,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 14, 2026, pp. 11 649–11 657
2026
-
[17]
Understanding image represen- tations by measuring their equivariance and equivalence,
K. Lenc and A. Vedaldi, “Understanding image represen- tations by measuring their equivariance and equivalence,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 991–999
2015
-
[18]
Revisiting model stitching to compare neural representations,
Y . Bansal, P. Nakkiran, and B. Barak, “Revisiting model stitching to compare neural representations,”Advances in neural information processing systems, vol. 34, pp. 225–236, 2021
2021
-
[19]
D. Hu, C. Huang, J. Wu, and H. Gao, “Pre-trained transformer-enabled strategies with human-guided fine- tuning for end-to-end navigation of autonomous vehi- cles,”arXiv preprint arXiv:2402.12666, 2024
arXiv 2024
-
[20]
Reinforced refinement with self-aware expansion for end-to-end autonomous driving,
H. Liu, T. Li, H. Yang, L. Chen, C. Wang, K. Guo, H. Tian, H. Li, H. Li, and C. Lv, “Reinforced refinement with self-aware expansion for end-to-end autonomous driving,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[21]
Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability,
M. Raghu, J. Gilmer, J. Yosinski, and J. Sohl-Dickstein, “Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[22]
Insights on repre- sentational similarity in neural networks with canonical correlation,
A. Morcos, M. Raghu, and S. Bengio, “Insights on repre- sentational similarity in neural networks with canonical correlation,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[23]
Sim- ilarity of neural network representations revisited,
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton, “Sim- ilarity of neural network representations revisited,” in International conference on machine learning. PMlR, 2019, pp. 3519–3529
2019
-
[24]
How not to stitch represen- tations to measure similarity: Task loss matching versus direct matching,
A. Balogh and M. Jelasity, “How not to stitch represen- tations to measure similarity: Task loss matching versus direct matching,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 15, 2025, pp. 15 472–15 480
2025
-
[25]
Functional alignment can mislead: Examining model stitching,
D. Smith, H. Mannering, and A. Marcu, “Functional alignment can mislead: Examining model stitching,” inForty-second International Conference on Machine Learning, 2025
2025
-
[26]
Similarity and matching of neural net- work representations,
A. Csisz ´arik, P. K˝or¨osi-Szab´o, A. Matszangosz, G. Papp, and D. Varga, “Similarity and matching of neural net- work representations,”Advances in Neural Information Processing Systems, vol. 34, pp. 5656–5668, 2021
2021
-
[27]
Cores: Compatible representations via stationarity,
N. Biondi, F. Pernici, M. Bruni, and A. Del Bimbo, “Cores: Compatible representations via stationarity,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 8, pp. 9567–9582, 2023
2023
-
[28]
Connecting neural models latent ge- ometries with relative geodesic representations,
H. Yu, B. Inal, G. Arvanitidis, S. Hauberg, F. Locatello, and M. Fumero, “Connecting neural models latent ge- ometries with relative geodesic representations,”arXiv preprint arXiv:2506.01599, 2025
arXiv 2025
-
[29]
Cross-model semantics in representation learning,
S. Nikooroo and T. Engel, “Cross-model semantics in representation learning,”arXiv preprint arXiv:2508.03649, 2025. 11
arXiv 2025
-
[30]
Latent space translation via semantic alignment,
V . Maiorca, L. Moschella, A. Norelli, M. Fumero, F. Lo- catello, and E. Rodol `a, “Latent space translation via semantic alignment,”Advances in Neural Information Processing Systems, vol. 36, pp. 55 394–55 414, 2023
2023
-
[31]
Stitchnet: Composing neural networks from pre-trained fragments,
S. Teerapittayanon, M. Comiter, B. McDanel, and H. Kung, “Stitchnet: Composing neural networks from pre-trained fragments,” in2023 International Conference on Machine Learning and Applications (ICMLA). IEEE, 2023, pp. 61–68
2023
-
[32]
Self-stitching: Widely applicable and efficient trans- fer learning using stitching layer,
T. Anakewat, Y . Mukuta, T. Westfechtel, and T. Harada, “Self-stitching: Widely applicable and efficient trans- fer learning using stitching layer,” inNeurIPS 2024 Workshop on Fine-Tuning in Modern Machine Learning: Principles and Scalability, 2024
2024
-
[33]
Relative representations enable zero-shot latent space communication,
L. Moschella, V . Maiorca, M. Fumero, A. Norelli, F. Lo- catello, and E. Rodol `a, “Relative representations enable zero-shot latent space communication,”arXiv preprint arXiv:2209.15430, 2022
arXiv 2022
-
[34]
Bootstrapping parallel anchors for relative representations,
I. Cannistraci, L. Moschella, V . Maiorca, M. Fumero, A. Norelli, and E. Rodol `a, “Bootstrapping parallel anchors for relative representations,”arXiv preprint arXiv:2303.00721, 2023
arXiv 2023
-
[35]
From bricks to bridges: Product of in- variances to enhance latent space communication,
I. Cannistraci, L. Moschella, M. Fumero, V . Maiorca, and E. Rodol `a, “From bricks to bridges: Product of in- variances to enhance latent space communication,”arXiv preprint arXiv:2310.01211, 2023
arXiv 2023
-
[36]
Latent space translation via inverse relative projection,
V . Maiorca, L. Moschella, M. Fumero, F. Locatello, and E. Rodol `a, “Latent space translation via inverse relative projection,”arXiv preprint arXiv:2406.15057, 2024
arXiv 2024
-
[37]
End-to-end interpretable neural motion planner,
W. Zeng, W. Luo, S. Suo, A. Sadat, B. Yang, S. Casas, and R. Urtasun, “End-to-end interpretable neural motion planner,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 8660– 8669
2019
-
[38]
Representation learning: A review and new perspectives,
Y . Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,”IEEE trans- actions on pattern analysis and machine intelligence, vol. 35, no. 8, pp. 1798–1828, 2013
2013
-
[39]
Planning-oriented autonomous driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wanget al., “Planning-oriented autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 853–17 862
2023
-
[40]
St-p3: End-to-end vision-based autonomous driving via spatial- temporal feature learning,
S. Hu, L. Chen, P. Wu, H. Li, J. Yan, and D. Tao, “St-p3: End-to-end vision-based autonomous driving via spatial- temporal feature learning,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 533–549
2022
-
[41]
Carla: An open urban driving simulator,
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun, “Carla: An open urban driving simulator,” in Conference on robot learning. PMLR, 2017, pp. 1–16
2017
-
[42]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Bei- jbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631
2020
-
[43]
From imitation to exploration: End-to-end au- tonomous driving based on world model,
Y . Li, M. Jiang, S. Zhang, W. Yuan, C. Wang, and M. Yang, “From imitation to exploration: End-to-end au- tonomous driving based on world model,”arXiv preprint arXiv:2410.02253, 2024
arXiv 2024
-
[44]
Bevfusion: A simple and robust lidar-camera fusion framework,
T. Liang, H. Xie, K. Yu, Z. Xia, Z. Lin, Y . Wang, T. Tang, B. Wang, and Z. Tang, “Bevfusion: A simple and robust lidar-camera fusion framework,”Advances in Neural Information Processing Systems, vol. 35, pp. 10 421–10 434, 2022. Yueyuan LIreceived a Bachelor’s degree in Electri- cal and Computer Engineering from the University of Michigan-Shanghai Jiao T...
2022
-
[45]
His main research interests include representation learning and reinforcement learning
He is currently pursuing the Master’s degree in Automation from Shanghai Jiao Tong University. His main research interests include representation learning and reinforcement learning. Mingyang JIANGreceived a Bachelor’s degree in engineering from Shanghai Jiao Tong University in 2023, and a Master’s degree in Control Science and Engineering from Shanghai J...
2023
-
[46]
Xiang ZUOreceived a Bachelor’s degree in mathe- matics from Shanghai Jiao Tong University in 2025
His main research interests are end-to-end planning, driving decision-making, and reinforce- ment learning for autonomous vehicles. Xiang ZUOreceived a Bachelor’s degree in mathe- matics from Shanghai Jiao Tong University in 2025. He is currently pursuing the Ph.D. degree in mechan- ical engineering with Shanghai Jiao Tong University. His research interes...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.