When Does Language Matter? Multilingual Instructions Reveal Step-wise Language Sensitivity in Vision-Language-Action Models
Pith reviewed 2026-06-27 09:37 UTC · model grok-4.3
The pith
Language robustness in vision-language-action models reduces to handling sensitivity at particular steps in a task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
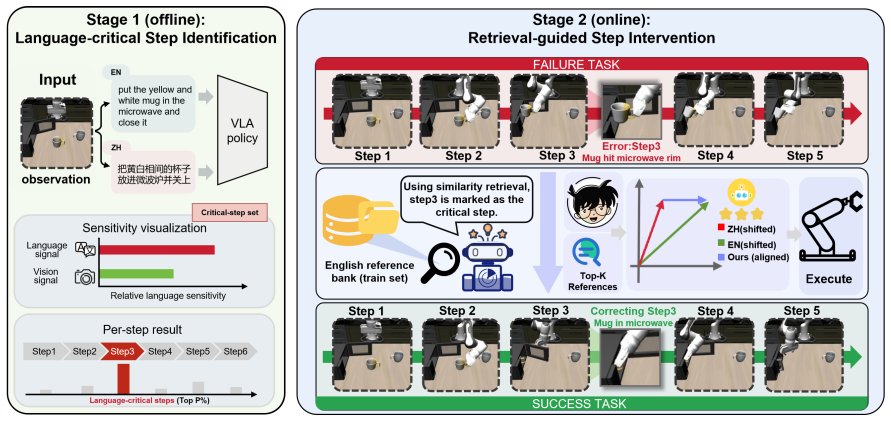
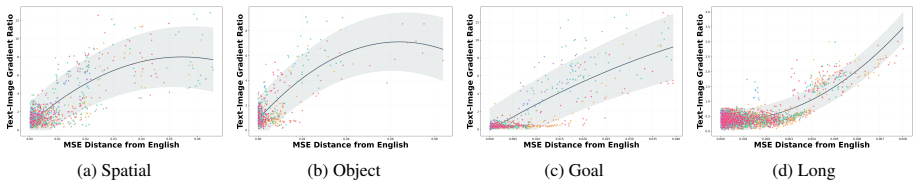
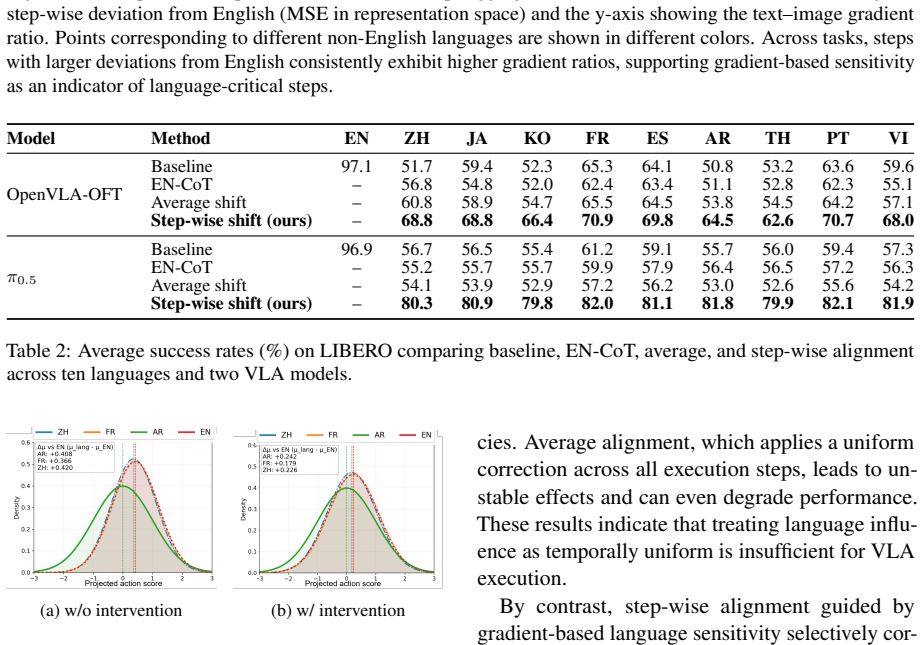
Multilingual evaluation of VLA models on the translated LIBERO benchmark shows 30-50% drops in success rates for non-English instructions. Step-wise analysis of task executions demonstrates that language influence is highly non-uniform, with certain steps exhibiting strong language dependence that dominate overall task failure, while others are language-agnostic. A step-wise inference-time intervention that aligns representations according to step language sensitivity substantially improves performance, establishing that language robustness in VLA models is fundamentally a step-wise control problem.
What carries the argument
step-wise inference-time intervention that aligns representations according to step language sensitivity
If this is right
- Targeted fixes at language-sensitive steps can restore performance without changing the entire model.
- Tasks should be analyzed for which steps require language input and which do not.
- Temporally structured analysis is necessary for reliable embodied agents under linguistic variation.
- Overall task failure is often driven by a small number of critical steps rather than distributed errors.
Where Pith is reading between the lines
- Models could be made more efficient by skipping language processing in language-agnostic steps.
- The approach might extend to other variations such as noisy instructions or different instruction styles.
- Designing benchmarks that isolate step sensitivities could accelerate progress in robust VLA systems.
Load-bearing premise
The observed performance drops and step-wise patterns result from the model's response to linguistic variation rather than from translation errors or other uncontrolled factors in the benchmark.
What would settle it
Finding that success rate drops remain the same even when using professional human translations of instructions, or that the pattern of sensitive steps changes inconsistently across different translation methods, would challenge the attribution to language sensitivity.
Figures



read the original abstract
Vision-Language-Action (VLA) models have shown strong performance in language-conditioned robotic manipulation, yet their robustness to linguistic variation remains poorly understood. In this work, we present the first systematic multilingual evaluation of VLA models by translating the LIBERO benchmark into ten languages, revealing severe performance degradation under non-English instructions, with success rates dropping by 30-50%. Through fine-grained analysis of task executions, we find that language influence is highly non-uniform across steps: certain steps exhibit strong language dependence and dominate overall task failure, while others are largely language-agnostic. Based on this insight, we propose a step-wise inference-time intervention that aligns representations according to step language sensitivity, substantially improving performance under linguistic variation. Our results indicate that language robustness in VLA models is fundamentally a step-wise control problem, highlighting the importance of temporally structured analysis for reliable embodied agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts the first systematic multilingual evaluation of Vision-Language-Action (VLA) models by machine-translating the LIBERO benchmark instructions into ten languages. It reports 30-50% drops in success rates under non-English instructions, identifies highly non-uniform language sensitivity across individual task steps (with some steps dominating failures), and proposes a step-wise inference-time intervention that aligns representations according to per-step language sensitivity. The central claim is that language robustness in VLA models is fundamentally a step-wise control problem.
Significance. If the empirical patterns hold after ruling out translation artifacts, the work would establish that language effects in embodied agents are temporally localized rather than global, motivating targeted rather than uniform multilingual training or alignment methods. The step-wise intervention provides a concrete, inference-time mitigation that could be practically useful; the absence of machine-checked proofs, parameter-free derivations, or open reproducible code is noted but does not diminish the empirical contribution if the core measurements are validated.
major comments (2)
- [Abstract] Abstract: The claim that performance drops of 30-50% and non-uniform step sensitivity reflect genuine language dependence in the VLA models (rather than artifacts) is load-bearing for the 'step-wise control problem' conclusion, yet the manuscript provides no reported validation of the machine-translated instructions (human fidelity ratings, back-translation checks, or error analysis).
- [Abstract] Abstract: The identification of 'language-dependent' steps that 'dominate overall task failure' presupposes that the observed step-wise patterns arise from model behavior rather than uncontrolled factors such as translation-induced semantic shifts or varying task difficulty; no statistical tests, controls, or error analysis are described to support this attribution.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating the machine translations and providing statistical support for attributing step-wise patterns to language sensitivity. We address both points below and will incorporate the necessary additions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that performance drops of 30-50% and non-uniform step sensitivity reflect genuine language dependence in the VLA models (rather than artifacts) is load-bearing for the 'step-wise control problem' conclusion, yet the manuscript provides no reported validation of the machine-translated instructions (human fidelity ratings, back-translation checks, or error analysis).
Authors: We agree that explicit validation of the translations is required to support the core claims. The current manuscript relies on standard machine translation without additional checks. In the revision, we will add back-translation verification for all ten languages, human fidelity ratings on a stratified sample of instructions (reporting inter-rater agreement), and a brief error analysis of any detected semantic shifts. revision: yes
-
Referee: [Abstract] Abstract: The identification of 'language-dependent' steps that 'dominate overall task failure' presupposes that the observed step-wise patterns arise from model behavior rather than uncontrolled factors such as translation-induced semantic shifts or varying task difficulty; no statistical tests, controls, or error analysis are described to support this attribution.
Authors: The manuscript currently presents the step-wise patterns through direct observation of execution traces but does not include formal statistical tests or explicit controls. We will revise to add (1) per-step success rate comparisons with English as baseline, (2) statistical tests (e.g., paired t-tests or permutation tests) assessing whether language sensitivity differs significantly across steps, and (3) controls that normalize for inherent step difficulty using the English-language results. These will be reported in a new subsection on robustness of the step-wise findings. revision: yes
Circularity Check
No circularity; empirical results on external benchmark
full rationale
The paper's claims rest on direct empirical evaluation of existing VLA models against the translated LIBERO benchmark. Performance drops, step-wise sensitivity patterns, and the proposed intervention are derived from observed task execution data rather than any equations, fitted parameters, or self-referential definitions. No self-citation chains, uniqueness theorems, or ansatzes are load-bearing. The derivation is self-contained against an external benchmark with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Machine translations of LIBERO instructions preserve intended task semantics across the ten languages
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Proceedings of The 8th Conference on Robot Learning , pages =
OpenVLA: An Open-Source Vision-Language-Action Model , author =. Proceedings of The 8th Conference on Robot Learning , pages =. 2025 , editor =
2025
-
[9]
2023 , eprint=
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control , author=. 2023 , eprint=
2023
-
[10]
2024 , eprint=
_0 : A Vision-Language-Action Flow Model for General Robot Control , author=. 2024 , eprint=
2024
-
[11]
2024 , eprint=
LLARVA: Vision-Action Instruction Tuning Enhances Robot Learning , author=. 2024 , eprint=
2024
-
[12]
2025 , eprint=
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success , author=. 2025 , eprint=
2025
-
[13]
2025 , eprint=
On Robustness of Vision-Language-Action Model against Multi-Modal Perturbations , author=. 2025 , eprint=
2025
-
[14]
2025 , eprint=
Eva-VLA: Evaluating Vision-Language-Action Models' Robustness Under Real-World Physical Variations , author=. 2025 , eprint=
2025
-
[15]
ArXiv , year=
TowerVision: Understanding and Improving Multilinguality in Vision-Language Models , author=. ArXiv , year=
-
[16]
ArXiv , year=
Multilingual Vision-Language Models, A Survey , author=. ArXiv , year=
-
[17]
2024 , eprint=
PALO: A Polyglot Large Multimodal Model for 5B People , author=. 2024 , eprint=
2024
-
[18]
Ye, Zekai and Li, Qiming and Feng, Xiaocheng and Qin, Libo and Huang, Yichong and Li, Baohang and Jiang, Kui and Xiang, Yang and Zhang, Zhirui and Lu, Yunfei and Tang, Duyu and Tu, Dandan and Qin, Bing. CLAIM : Mitigating Multilingual Object Hallucination in Large Vision-Language Models with Cross-Lingual Attention Intervention. Proceedings of the 63rd An...
-
[19]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and ichter, brian and Xia, Fei and Chi, Ed and Le, Quoc V and Zhou, Denny , booktitle =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
-
[20]
The Eleventh International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[21]
2023 , eprint=
RT-1: Robotics Transformer for Real-World Control at Scale , author=. 2023 , eprint=
2023
-
[22]
2024 , eprint=
Octo: An Open-Source Generalist Robot Policy , author=. 2024 , eprint=
2024
-
[23]
2023 , eprint=
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning , author=. 2023 , eprint=
2023
-
[24]
2025 , eprint=
Exploring the Limits of Vision-Language-Action Manipulations in Cross-task Generalization , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
Improving Pre-Trained Vision-Language-Action Policies with Model-Based Search , author=. 2025 , eprint=
2025
-
[26]
2023 , eprint=
PaLI-X: On Scaling up a Multilingual Vision and Language Model , author=. 2023 , eprint=
2023
-
[27]
2025 , eprint=
Language-Specific Layer Matters: Efficient Multilingual Enhancement for Large Vision-Language Models , author=. 2025 , eprint=
2025
-
[28]
Cross-lingual Prompting: Improving Zero-shot Chain-of-Thought Reasoning across Languages
Qin, Libo and Chen, Qiguang and Wei, Fuxuan and Huang, Shijue and Che, Wanxiang. Cross-lingual Prompting: Improving Zero-shot Chain-of-Thought Reasoning across Languages. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.163
-
[29]
ArXiv , year=
A Comprehensive Evaluation of Multilingual Chain-of-Thought Reasoning: Performance, Consistency, and Faithfulness Across Languages , author=. ArXiv , year=
-
[30]
2025 , eprint=
Unlocking Multilingual Reasoning Capability of LLMs and LVLMs through Representation Engineering , author=. 2025 , eprint=
2025
-
[31]
Physical Intelligence and Kevin Black and Noah Brown and James Darpinian and Karan Dhabalia and Danny Driess and Adnan Esmail and Michael Equi and Chelsea Finn and Niccolo Fusai and Manuel Y. Galliker and Dibya Ghosh and Lachy Groom and Karol Hausman and Brian Ichter and Szymon Jakubczak and Tim Jones and Liyiming Ke and Devin LeBlanc and Sergey Levine an...
-
[32]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[33]
2021 , eprint=
Multilingual LAMA: Investigating Knowledge in Multilingual Pretrained Language Models , author=. 2021 , eprint=
2021
-
[34]
Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
Liu, Chaoqun and Zhang, Wenxuan and Zhao, Yiran and Luu, Anh Tuan and Bing, Lidong. Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.