Theory-Scale Auto-Formalization of Logics for Computer Science
Pith reviewed 2026-06-26 05:25 UTC · model grok-4.3
The pith
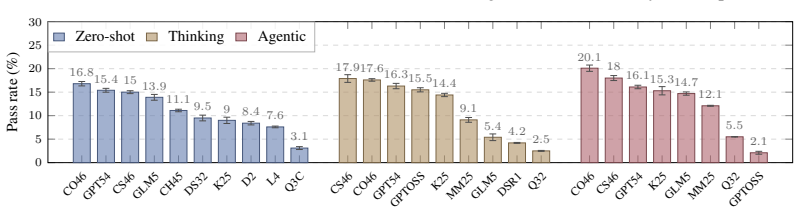
A theory-scale benchmark reveals that auto-formalization of interdependent logic statements succeeds at only 20.1 percent for current models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
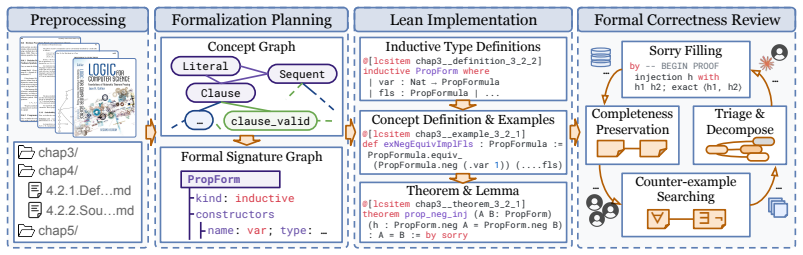
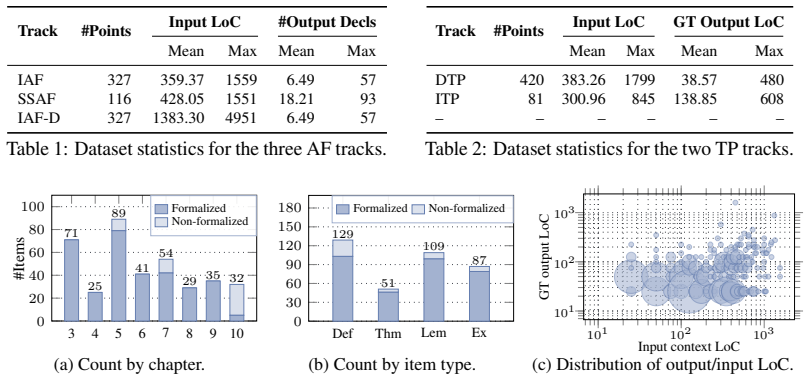
The paper establishes that a semi-automated pipeline can generate a consistent formalization of 327 textbook items comprising over 4,000 Lean declarations, and that this reveals current models achieve a maximum of 20.1% success on the auto-formalization tasks.
What carries the argument
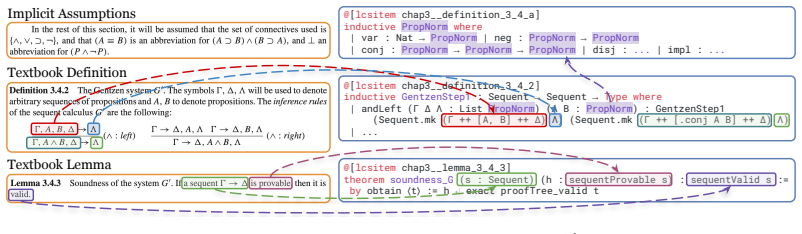
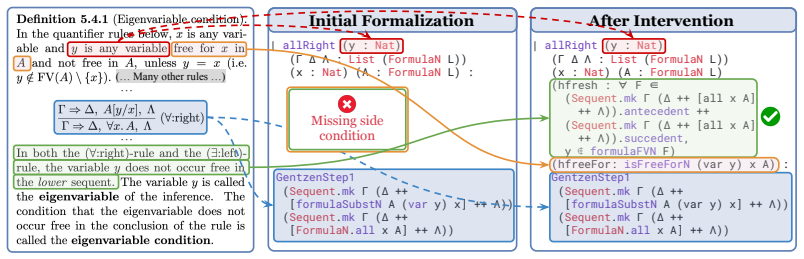
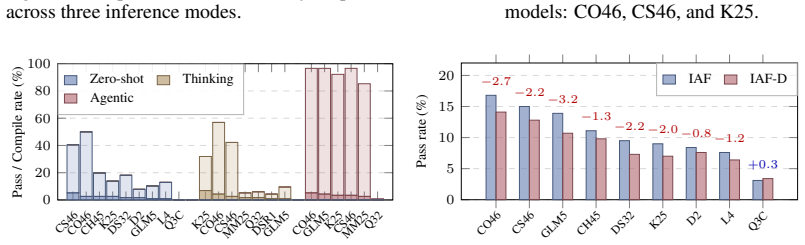
semi-automated agentic pipeline leveraging concept graphs, formal signature planning, issue tracking, sorry-filling with counter-example search, and human faithfulness review
If this is right
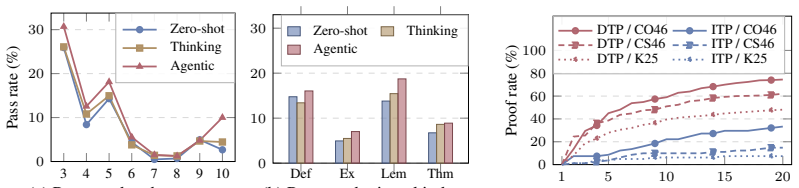
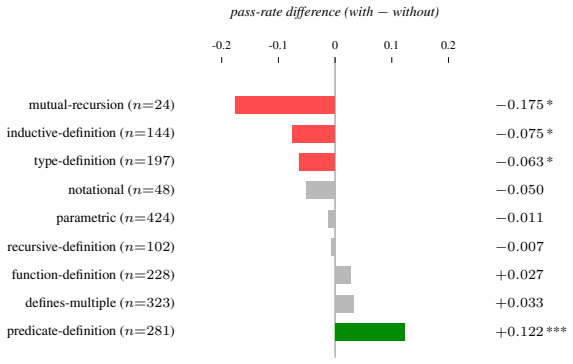
- The dataset automatically derives five tracks of evaluation benchmarks for different aspects of auto-formalization and theorem proving.
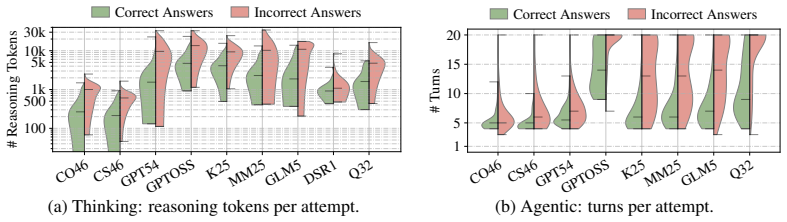
- Current models struggle specifically with maintaining coherence across interdependent statements rather than isolated ones.
- The definitional equivalence checkers enable finer-grained assessment than previous protocols.
- Analysis of the results points to specific bottlenecks in theory-scale formalization.
- The benchmark supports ongoing testing of new methods for auto-formalization.
Where Pith is reading between the lines
- If the pipeline generalizes, it could support formalization of other large mathematical texts without manual intervention for each item.
- Low performance on interdependent items suggests future models may need explicit mechanisms for tracking dependencies between statements.
- Success at this scale could reduce the manual effort required to build verified libraries for computer science applications.
- The approach might extend to domains beyond logics, such as formalizing parts of software specifications.
Load-bearing premise
The pipeline's combination of automated steps and human review produces translations that are consistent across all items and faithful to the original text without introducing errors.
What would settle it
Discovery of a systematic inconsistency across the generated Lean declarations or a model achieving over 50 percent success on the full set of interdependent items would challenge the quality and difficulty claims.
Figures



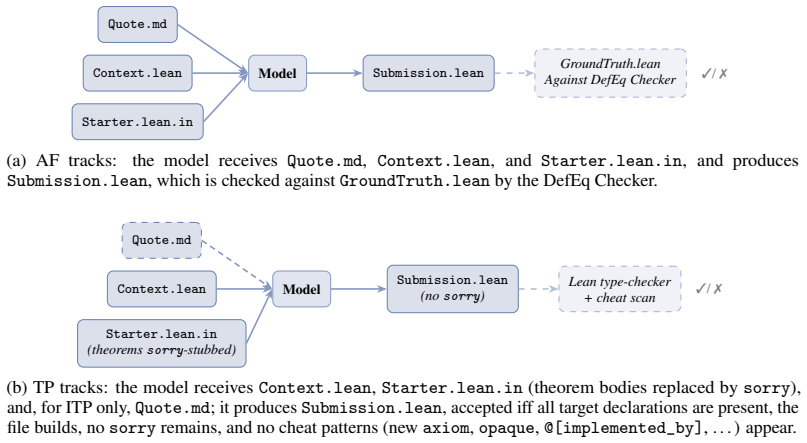
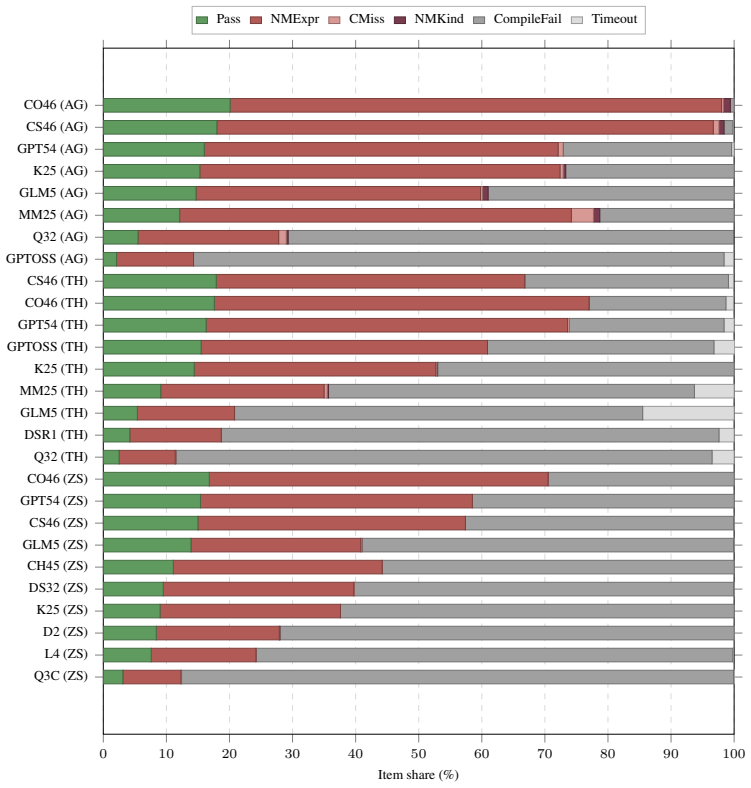
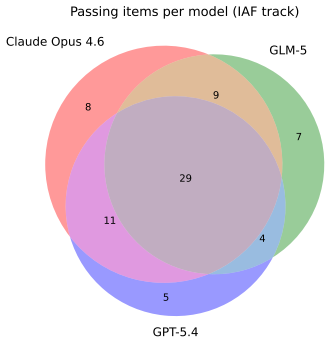
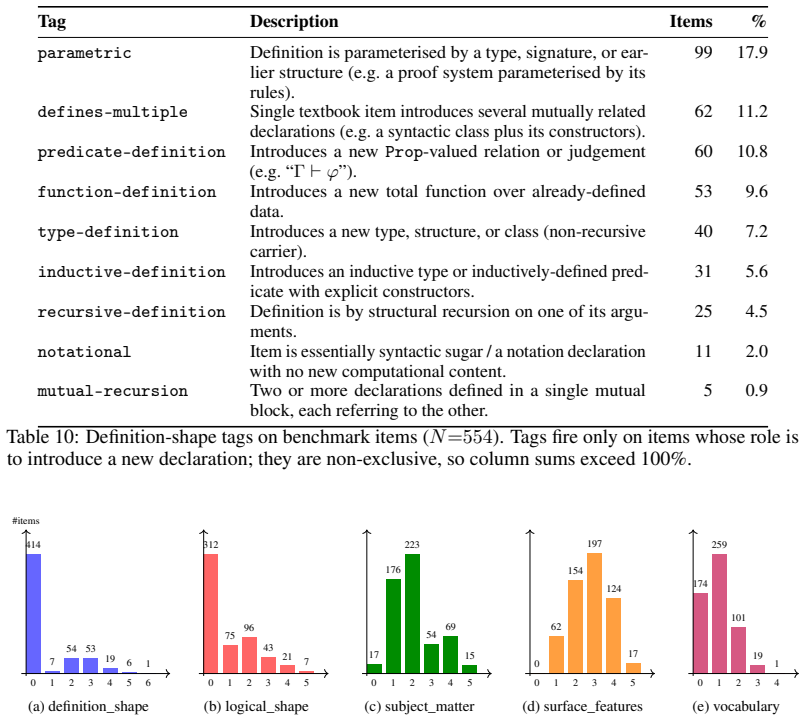
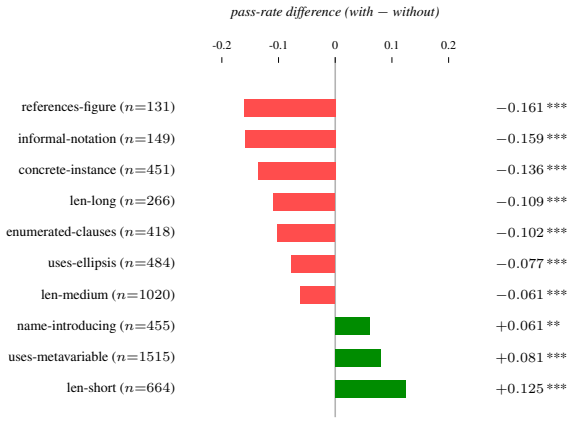
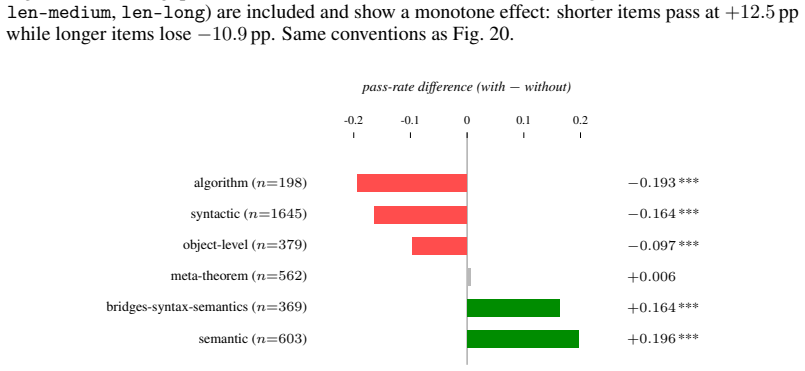
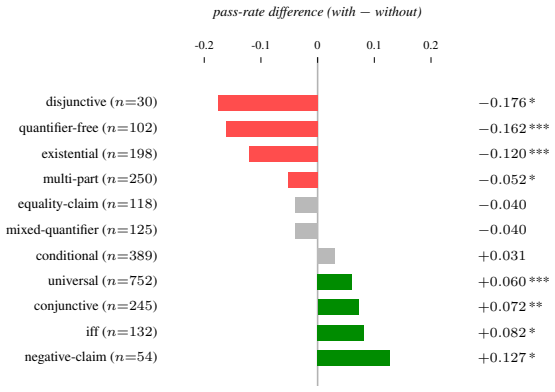
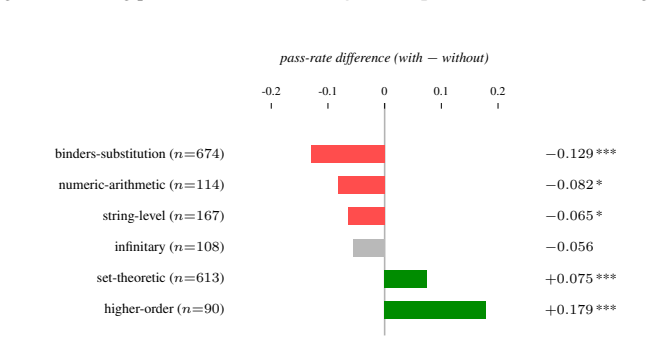
read the original abstract
Auto-formalization is critical for scalable formal verification, but existing progress largely focuses on isolated statements, while theory-scale auto-formalization, which coherently translates hundreds of interdependent definitions, lemmas, and theorems, remains open due to challenges in consistency, faithfulness, scalability, and correctness. In this paper, we introduce LCS-Bench, a stand-alone, theory-scale benchmark based on Logics for Computer Science. LCS-Bench is built through a novel semi-automated agentic pipeline that leverages concept graphs, formal signature planning, issue tracking, sorry-filling with counter-example search, complemented by faithfulness review from human experts. The resulting artifact covers 327 textbook items, over 4,076 Lean declarations, and more than 85K lines of Lean code. The dataset supports broad evaluation through a data engine that automatically derives five tracks of evaluation benchmarks, measuring different aspects of auto-formalization and theorem-proving capabilities. We also introduce a novel evaluation protocol featuring definitional equivalence checkers, enabling more fine-grained and faithful assessment. Through extensive evaluation on 14 models, we demonstrate that (1) LCS-Bench is of high quality, consistent, and faithful; (2) the benchmark is challenging, with state-of-the-art models achieving only 20.1% on auto-formalization tasks; and (3) our analysis reveals key findings regarding theory-scale auto-formalization and suggests promising directions for future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LCS-Bench, a theory-scale benchmark for auto-formalization derived from the 'Logics for Computer Science' textbook. It is constructed via a semi-automated agentic pipeline using concept graphs, formal signature planning, issue tracking, sorry-filling with counter-example search, and human faithfulness review. The artifact comprises 327 textbook items, over 4,076 Lean declarations, and more than 85K lines of code. It supports five evaluation tracks via a data engine and introduces definitional equivalence checkers for assessment. Evaluations across 14 models show state-of-the-art performance at only 20.1% on auto-formalization tasks.
Significance. If the pipeline indeed produces a consistent and faithful artifact at this scale, LCS-Bench would be a notable contribution to theory-scale auto-formalization by addressing interdependencies among definitions, lemmas, and theorems that isolated-statement benchmarks overlook. The multi-track evaluation design and definitional equivalence protocol offer a more granular assessment framework than prior work. The reported 20.1% SOTA performance underscores the difficulty of the task and could guide future model development.
major comments (2)
- [Abstract] Abstract and the description of the construction pipeline: the central claim that 'LCS-Bench is of high quality, consistent, and faithful' rests on the semi-automated pipeline plus human review, yet no quantitative metrics are supplied for faithfulness (e.g., fraction of items corrected, inter-annotator agreement) or consistency (e.g., results of definitional equivalence checks across the 327 items). This evidence gap is load-bearing for the primary contribution.
- [Pipeline description (Section 3)] The human faithfulness review step is described at a high level but lacks specifics on reviewer count, expertise, review protocol, or any error analysis; without these, it is impossible to evaluate whether systematic biases or inconsistencies were introduced in the 85K-line artifact.
minor comments (2)
- [Abstract] The 20.1% figure should be explicitly tied to a particular model, track, and evaluation protocol in the abstract for immediate clarity.
- [Evaluation section] Notation for the five evaluation tracks and the definitional equivalence checkers would benefit from a small illustrative example early in the text.
Simulated Author's Rebuttal
We thank the referee for their thorough review and for identifying key areas where additional evidence would strengthen the presentation of LCS-Bench. We address each major comment below and will revise the manuscript to supply the requested quantitative details and process specifications.
read point-by-point responses
-
Referee: [Abstract] Abstract and the description of the construction pipeline: the central claim that 'LCS-Bench is of high quality, consistent, and faithful' rests on the semi-automated pipeline plus human review, yet no quantitative metrics are supplied for faithfulness (e.g., fraction of items corrected, inter-annotator agreement) or consistency (e.g., results of definitional equivalence checks across the 327 items). This evidence gap is load-bearing for the primary contribution.
Authors: We agree that the current manuscript lacks explicit quantitative metrics supporting the quality claim. In the revision we will add a dedicated subsection (likely in Section 3 or a new Section 4) that reports: (i) the fraction of the 327 items that required corrections during the human review stage, (ii) inter-annotator agreement statistics from the faithfulness review, and (iii) aggregate results of the definitional equivalence checks performed across the full artifact. These additions will directly substantiate the claim of high quality, consistency, and faithfulness. revision: yes
-
Referee: [Pipeline description (Section 3)] The human faithfulness review step is described at a high level but lacks specifics on reviewer count, expertise, review protocol, or any error analysis; without these, it is impossible to evaluate whether systematic biases or inconsistencies were introduced in the 85K-line artifact.
Authors: We accept that the description of the human review is insufficiently detailed. The revised Section 3 will specify: the number of reviewers, their relevant expertise (Lean, formal methods, and the textbook domain), the exact review protocol (independent review followed by consensus discussion), and a concise error analysis summarizing the categories and frequencies of issues identified and resolved. We will also note how the definitional equivalence checkers were used to detect and correct inconsistencies. revision: yes
Circularity Check
No significant circularity
full rationale
The paper constructs LCS-Bench as a new artifact via an explicitly described semi-automated pipeline (concept graphs, signature planning, issue tracking, sorry-filling with counter-example search, and human faithfulness review) and then evaluates external models on it. No equations, fitted parameters, or self-citations are invoked to derive the benchmark's properties or the reported performance numbers; the scale (327 items, 4,076 declarations, 85K lines) and quality claims rest on the workflow description and external human review rather than reducing to the inputs by construction. The evaluation protocol (definitional equivalence checkers) is presented as an independent verification layer. This matches the default expectation of a self-contained artifact paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The semi-automated pipeline using concept graphs and human faithfulness review produces consistent and faithful Lean translations of interdependent textbook items.
Reference graph
Works this paper leans on
-
[1]
Jiang, Wenda Li, Markus N
Yuhuai Wu, Albert Q. Jiang, Wenda Li, Markus N. Rabe, Charles Staats, Mateja Jamnik, and Christian Szegedy. Autoformalization with large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[2]
Formal mathematical reasoning: A new frontier in AI.arXiv preprint, 2024
Kaiyu Yang, Gabriel Poesia, Jingxuan He, Wenda Li, Kristin Lauter, Swarat Chaudhuri, and Dawn Song. Formal mathematical reasoning: A new frontier in AI.arXiv preprint, 2024
2024
-
[3]
A survey on deep learning for theorem proving.arXiv preprint, 2024
Zhaoyu Li, Jialiang Sun, Logan Murphy, Qidong Su, Zenan Li, Xian Zhang, Kaiyu Yang, and Xujie Si. A survey on deep learning for theorem proving.arXiv preprint, 2024
2024
-
[4]
Autoformalization in the era of large language models: A survey.arXiv preprint, 2025
Ke Weng, Lun Du, Sirui Li, Wangyue Lu, Haozhe Sun, Hengyu Liu, and Tiancheng Zhang. Autoformalization in the era of large language models: A survey.arXiv preprint, 2025
2025
-
[5]
The mathlib Community. The lean mathematical library. InProceedings of the 9th ACM SIGPLAN International Conference on Certified Programs and Proofs, CPP 2020, pages 367– 381, New York, NY , USA, 2020. Association for Computing Machinery. ISBN 9781450370974. doi: 10.1145/3372885.3373824. URLhttps://doi.org/10.1145/3372885.3373824
-
[6]
MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics
Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[7]
Ayers, Dragomir Radev, and Jeremy Avigad
Zhangir Azerbayev, Bartosz Piotrowski, Hailey Schoelkopf, Edward W. Ayers, Dragomir Radev, and Jeremy Avigad. ProofNet: Autoformalizing and formally proving undergraduate-level mathematics.arXiv preprint, 2023
2023
-
[8]
FIMO: A challenge formal dataset for automated theorem proving.arXiv preprint, 2023
Chengwu Liu, Jianhao Shen, Huajian Xin, Zhengying Liu, Ye Yuan, Haiming Wang, Wei Ju, Chuanyang Zheng, Yichun Yin, Lin Li, Ming Zhang, and Qun Liu. FIMO: A challenge formal dataset for automated theorem proving.arXiv preprint, 2023
2023
-
[9]
FATE: A formal benchmark series for frontier algebra of multiple difficulty levels.arXiv preprint, 2025
Jiedong Jiang, Wanyi He, Yuefeng Wang, Guoxiong Gao, Yongle Hu, Jingting Wang, Nailin Guan, Peihao Wu, Chunbo Dai, Liang Xiao, and Bin Dong. FATE: A formal benchmark series for frontier algebra of multiple difficulty levels.arXiv preprint, 2025
2025
-
[10]
CombiBench: Benchmarking LLM capability for combinatorial mathematics.arXiv preprint, 2025
Junqi Liu, Xiaohan Lin, Jonas Bayer, Yaël Dillies, Weijie Jiang, Xiaodan Liang, Roman Soletskyi, Haiming Wang, Yunzhou Xie, Beibei Xiong, Zhengfeng Yang, Jujian Zhang, Lihong Zhi, Jia Li, and Zhengying Liu. CombiBench: Benchmarking LLM capability for combinatorial mathematics.arXiv preprint, 2025
2025
-
[11]
LeanCat: A benchmark suite for formal category theory in Lean (part I: 1-categories).arXiv preprint, 2025
Rongge Xu, Hui Dai, Yiming Fu, Jiedong Jiang, Tianjiao Nie, Junkai Wang, Holiverse Yang, and Zhi-Hao Zhang. LeanCat: A benchmark suite for formal category theory in Lean (part I: 1-categories).arXiv preprint, 2025
2025
-
[12]
PUTNAMBENCH: evaluating neural theorem- provers on the putnam mathematical competition
George Tsoukalas, Jasper Lee, John Jennings, Jimmy Xin, Michelle Ding, Michael Jennings, Amitayush Thakur, and Swarat Chaudhuri. PUTNAMBENCH: evaluating neural theorem- provers on the putnam mathematical competition. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2024. Curran Asso...
2024
-
[13]
Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar
Kaiyu Yang, Aidan M. Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar. LeanDojo: Theorem proving with retrieval- augmented language models. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023. 10
2023
-
[14]
miniCTX: Neural theorem proving with (long- )contexts.arXiv preprint, 2024
Jiewen Hu, Thomas Zhu, and Sean Welleck. miniCTX: Neural theorem proving with (long- )contexts.arXiv preprint, 2024
2024
-
[15]
Dover Publications, second edition, 2015
Jean Gallier.Logic for Computer Science: Foundations of Automatic Theorem Proving. Dover Publications, second edition, 2015. A corrected version of the original Wiley edition (pp. 511, 1986)
2015
-
[16]
Claude opus 4 system card
Anthropic. Claude opus 4 system card. Technical report, Anthropic, 2025. URL https: //www.anthropic.com/claude-opus-4-system-card
2025
-
[17]
GPT-5 system card
OpenAI. GPT-5 system card. Technical report, OpenAI, 2025. URL https://openai.com/ research/gpt-5-system-card
2025
-
[18]
Marker: Convert pdf to markdown, 2024
Vikas Subramanian and Datalab. Marker: Convert pdf to markdown, 2024. URL https: //github.com/datalab-to/marker
2024
-
[19]
DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025
2025
-
[20]
DeepSeek-V3 technical report, 2024
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, et al. DeepSeek-V3 technical report, 2024
2024
-
[21]
Kimi K2: Open agentic intelligence, 2025
Kimi Team, Yifan Bai, Yiping Bao, Cheng Chen, Guanduo Chen, et al. Kimi K2: Open agentic intelligence, 2025
2025
-
[22]
Jiang, Alexander H
Abhinav Rastogi, Adam Yang, Albert Q. Jiang, Alexander H. Liu, Alexandre Sablayrolles, et al. Devstral: Fine-tuning language models for coding agent applications, 2025
2025
-
[23]
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
Meta AI. The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation. https://ai.meta.com/blog/llama-4-multimodal-intelligence/ , 2025. Blog post, April 2025
2025
-
[24]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, et al. Qwen3 technical report, 2025
2025
-
[25]
Qwen2.5-Coder technical report, 2024
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. Qwen2.5-Coder technical report, 2024
2024
-
[26]
MiniMax-M1: Scaling test-time compute efficiently with lightning attention, 2025
MiniMax, Aili Chen, Aonian Li, Bangwei Gong, et al. MiniMax-M1: Scaling test-time compute efficiently with lightning attention, 2025
2025
-
[27]
ChatGLM: A family of large language models from GLM-130B to GLM-4 all tools, 2024
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Jingyu Sun, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Mingdao Liu, et al. ChatGLM: A family of large language models from GLM-130B t...
2024
-
[28]
gpt-oss-120b & gpt-oss-20b model card, 2025
OpenAI. gpt-oss-120b & gpt-oss-20b model card, 2025
2025
-
[29]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[30]
Formalml: A benchmark for evaluating formal subgoal completion in machine learning theory, 2025
Xiao-Wen Yang, Zihao Zhang, Jianuo Cao, Zhi Zhou, Zenan Li, Lan-Zhe Guo, Yuan Yao, Taolue Chen, Yu-Feng Li, and Xiaoxing Ma. Formalml: A benchmark for evaluating formal subgoal completion in machine learning theory, 2025. URL https://arxiv.org/abs/2510.02335
arXiv 2025
-
[31]
ATLAS: Autoformalizing theorems through lifting, augmentation, and synthesis of data.arXiv preprint, 2025
Xiaoyang Liu, Kangjie Bao, Jiashuo Zhang, Yunqi Liu, Yu Chen, Yuntian Liu, Yang Jiao, and Tao Luo. ATLAS: Autoformalizing theorems through lifting, augmentation, and synthesis of data.arXiv preprint, 2025
2025
-
[32]
Aria: An agent for retrieval and iterative auto-formalization via dependency graph.arXiv preprint, 2025
Hanyu Wang, Ruohan Xie, Yutong Wang, Guoxiong Gao, Xintao Yu, and Bin Dong. Aria: An agent for retrieval and iterative auto-formalization via dependency graph.arXiv preprint, 2025
2025
-
[33]
Process-driven autoformalization in Lean 4.arXiv preprint, 2024
Jianqiao Lu, Yingjia Wan, Zhengying Liu, Yinya Huang, Jing Xiong, Chengwu Liu, Jianhao Shen, Hui Jin, Jipeng Zhang, Haiming Wang, Zhicheng Yang, Jing Tang, and Zhijiang Guo. Process-driven autoformalization in Lean 4.arXiv preprint, 2024. 11
2024
-
[34]
DRIFT: Decompose, retrieve, illustrate, then formalize theorems.arXiv preprint, 2025
Meiru Zhang, Philipp Borchert, Milan Gritta, and Gerasimos Lampouras. DRIFT: Decompose, retrieve, illustrate, then formalize theorems.arXiv preprint, 2025
2025
-
[35]
Autoformalizer with tool feedback.arXiv preprint, 2025
Qi Guo, Jianing Wang, Jianfei Zhang, Deyang Kong, Xiangzhou Huang, Xiangyu Xi, Wei Wang, Jingang Wang, Xunliang Cai, Shikun Zhang, and Wei Ye. Autoformalizer with tool feedback.arXiv preprint, 2025
2025
-
[36]
Consistent autoformalization for constructing mathematical libraries
Lan Zhang, Xin Quan, and Andre Freitas. Consistent autoformalization for constructing mathematical libraries. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, page 4020–4033. Association for Computational Linguistics,
2024
-
[37]
URL http://dx.doi.org/10.18653/v1/ 2024.emnlp-main.233
doi: 10.18653/v1/2024.emnlp-main.233. URL http://dx.doi.org/10.18653/v1/ 2024.emnlp-main.233
-
[38]
Min, Yeqi Gao, Wilson Sy, Zhaoyu Li, Xujie Si, and Osbert Bastani
Marcus J. Min, Yeqi Gao, Wilson Sy, Zhaoyu Li, Xujie Si, and Osbert Bastani. Divide and abstract: Autoformalization via decomposition and abstraction learning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=NjgaeXNit3
2026
-
[39]
Formal verification of a realistic compiler.Communications of the ACM, 52(7): 107–115, 2009
Xavier Leroy. Formal verification of a realistic compiler.Communications of the ACM, 52(7): 107–115, 2009
2009
-
[40]
Jianzhou Zhao, Santosh Nagarakatte, Milo M. K. Martin, and Steve Zdancewic. Formal verification of SSA-based optimizations for LLVM. InProceedings of the ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 2013
2013
-
[41]
seL4: formal verification of an OS kernel
Gerwin Klein, Kevin Elphinstone, Gernot Heiser, June Andronick, David Cock, Philip Derrin, Dhammika Elkaduwe, Kai Engelhardt, Rafal Kolanski, Michael Norrish, Thomas Sewell, Harvey Tuch, and Simon Winwood. seL4: formal verification of an OS kernel. InProceedings of the ACM SIGOPS Symposium on Operating Systems Principles (SOSP), pages 207–220, 2009
2009
-
[42]
CertiKOS: An extensible architecture for building certified concurrent OS kernels
Ronghui Gu, Zhong Shao, Hao Chen, Xiongnan (Newman) Wu, Jieung Kim, Vilhelm Sjöberg, and David Costanzo. CertiKOS: An extensible architecture for building certified concurrent OS kernels. InUSENIX Symposium on Operating Systems Design and Implementation (OSDI), 2016
2016
-
[43]
Lorch, Bryan Parno, Michael L
Chris Hawblitzel, Jon Howell, Manos Kapritsos, Jacob R. Lorch, Bryan Parno, Michael L. Roberts, Srinath Setty, and Brian Zill. IronFleet: Proving practical distributed systems correct. InProceedings of the ACM Symposium on Operating Systems Principles (SOSP), 2015
2015
-
[44]
Wilcox, Doug Woos, Pavel Panchekha, Zachary Tatlock, Xi Wang, Michael D
James R. Wilcox, Doug Woos, Pavel Panchekha, Zachary Tatlock, Xi Wang, Michael D. Ernst, and Thomas Anderson. Verdi: A framework for implementing and formally verifying distributed systems. InProceedings of the ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 2015
2015
-
[45]
Appel, Lennart Beringer, Adam Chlipala, Greg Morrisett, Benjamin C
Andrew W. Appel, Lennart Beringer, Adam Chlipala, Greg Morrisett, Benjamin C. Pierce, et al. The DeepSpec project: The science of deep specification. NSF Expedition in Computing, 2017. https://deepspec.org/
2017
-
[46]
Appel.Program Logics for Certified Compilers
Andrew W. Appel.Program Logics for Certified Compilers. Cambridge University Press, 2014
2014
-
[47]
Pierce, Andrew W
Benjamin C. Pierce, Andrew W. Appel, Adam Chlipala, Stephanie Weirich, Chris Casinghino, Arthur Azevedo de Amorim, Lennart Beringer, Brent Yorgey, et al. Software foundations. Electronic textbook series, 2010.https://softwarefoundations.cis.upenn.edu/
2010
-
[48]
Springer, 2014
Tobias Nipkow and Gerwin Klein.Concrete Semantics with Isabelle/HOL. Springer, 2014
2014
-
[49]
MIT Press, 2013
Adam Chlipala.Certified Programming with Dependent Types. MIT Press, 2013
2013
-
[50]
SeCaV: A sequent calculus verifier in Isabelle/HOL.arXiv preprint, 2022
Asta Halkjær From, Frederik Krogsdal Jacobsen, and Jørgen Villadsen. SeCaV: A sequent calculus verifier in Isabelle/HOL.arXiv preprint, 2022
2022
-
[51]
Teaching a formalized logical calculus.arXiv preprint, 2020
Asta Halkjær From, Alexander Birch Jensen, Anders Schlichtkrull, and Jørgen Villadsen. Teaching a formalized logical calculus.arXiv preprint, 2020
2020
-
[52]
An analysis of the constructive content of Henkin’s proof of Gödel’s completeness theorem.arXiv preprint, 2024
Hugo Herbelin and Danko Ilik. An analysis of the constructive content of Henkin’s proof of Gödel’s completeness theorem.arXiv preprint, 2024
2024
-
[53]
Aydemir, Aaron Bohannon, Matthew Fairbairn, J
Brian E. Aydemir, Aaron Bohannon, Matthew Fairbairn, J. Nathan Foster, Benjamin C. Pierce, Peter Sewell, Dimitrios Vytiniotis, Geoffrey Washburn, Stephanie Weirich, and Steve Zdancewic. Mechanized metatheory for the masses: The POPLmark challenge. InInternational Conference on Theorem Proving in Higher Order Logics (TPHOLs), 2005. 12
2005
-
[54]
Ziyang Li, Jiani Huang, and Mayur Naik. Scallop: A language for neurosymbolic programming. Proceedings of the ACM on Programming Languages (PLDI), 7, 2023. doi: 10.1145/3591280
-
[55]
Scallop: From probabilistic deductive databases to scalable differentiable reasoning
Jiani Huang, Ziyang Li, Binghong Chen, Karan Samel, Mayur Naik, Le Song, and Xujie Si. Scallop: From probabilistic deductive databases to scalable differentiable reasoning. In Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[56]
Ziyang Li, Jiani Huang, Jason Liu, and Mayur Naik. Neurosymbolic programming in Scallop: Principles and practice.Foundations and Trends in Programming Languages, 2024. doi: 10.1561/2500000059
-
[57]
DeepProbLog: Neural probabilistic logic programming
Robin Manhaeve, Sebastijan Dumancic, Angelika Kimmig, Thomas Demeester, and Luc De Raedt. DeepProbLog: Neural probabilistic logic programming. InAdvances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[58]
NeurASP: Embracing neural networks into answer set programming
Zhun Yang, Adam Ishay, and Joohyung Lee. NeurASP: Embracing neural networks into answer set programming. InInternational Joint Conference on Artificial Intelligence (IJCAI), 2020
2020
-
[59]
PROC2PDDL: Open-domain planning representations from texts
Tianyi Zhang, Li Zhang, Zhaoyi Hou, Ziyu Wang, Yuling Gu, Peter Clark, Chris Callison- Burch, and Niket Tandon. PROC2PDDL: Open-domain planning representations from texts. In Workshop on Natural Language Reasoning and Structured Explanations (NLRSE) at NAACL, 2024
2024
-
[60]
On the limit of language models as planning formalizers
Cassie Huang and Li Zhang. On the limit of language models as planning formalizers. In Annual Meeting of the Association for Computational Linguistics (ACL), 2025
2025
-
[61]
Chen, Martin Jankowiak, Fritz Obermeyer, Neeraj Pradhan, Theofanis Karaletsos, Rohit Singh, Paul Szerlip, Paul Horsfall, and Noah D
Eli Bingham, Jonathan P. Chen, Martin Jankowiak, Fritz Obermeyer, Neeraj Pradhan, Theofanis Karaletsos, Rohit Singh, Paul Szerlip, Paul Horsfall, and Noah D. Goodman. Pyro: Deep universal probabilistic programming.Journal of Machine Learning Research, 2019
2019
-
[62]
Hoffman, Daniel Lee, Ben Goodrich, Michael Betancourt, Marcus A
Bob Carpenter, Andrew Gelman, Matthew D. Hoffman, Daniel Lee, Ben Goodrich, Michael Betancourt, Marcus A. Brubaker, Jiqiang Guo, Peter Li, and Allen Riddell. Stan: A probabilistic programming language.Journal of Statistical Software, 76(1), 2017
2017
-
[63]
ProbLog: A probabilistic Prolog and its application in link discovery
Luc De Raedt, Angelika Kimmig, and Hannu Toivonen. ProbLog: A probabilistic Prolog and its application in link discovery. InInternational Joint Conference on Artificial Intelligence (IJCAI), 2007
2007
-
[64]
SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=VTF8yNQM66
2024
-
[65]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. OpenHands: An open platform for AI soft...
2025
-
[66]
DeepSeek-Prover: Advancing theorem proving in LLMs through large-scale synthetic data.arXiv preprint, 2024
Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, and Xiaodan Liang. DeepSeek-Prover: Advancing theorem proving in LLMs through large-scale synthetic data.arXiv preprint, 2024
2024
-
[67]
Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, Wenjun Gao, Qihao Zhu, Dejian Yang, Zhibin Gou, Z.F
Huajian Xin, Z.Z. Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, Wenjun Gao, Qihao Zhu, Dejian Yang, Zhibin Gou, Z.F. Wu, Fuli Luo, and Chong Ruan. DeepSeek-Prover-V1.5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search.arXiv preprint, 2024
2024
-
[68]
Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, Z.F
Z.Z. Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, Z.F. Wu, Zhibin Gou, Shirong Ma, Hongxuan Tang, Yuxuan Liu, Wenjun Gao, Daya Guo, and Chong Ruan. DeepSeek-Prover-V2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition.arXiv preprint, 2025
2025
-
[69]
Goedel-Prover: A frontier model for open-source automated theorem proving.arXiv preprint, 2025
Yong Lin, Shange Tang, Bohan Lyu, Jiayun Wu, Hongzhou Lin, Kaiyu Yang, Jia Li, Mengzhou Xia, Danqi Chen, Sanjeev Arora, and Chi Jin. Goedel-Prover: A frontier model for open-source automated theorem proving.arXiv preprint, 2025. 13
2025
-
[70]
Kimina-Prover preview: Towards large formal reasoning models with reinforcement learning
Haiming Wang, Mert Unsal, Xiaohan Lin, Mantas Baksys, Junqi Liu, Marco Dos Santos, Flood Sung, Marina Vinyes, Zhenzhe Ying, Zekai Zhu, Jianqiao Lu, Hugues de Saxcé, Bolton Bailey, Chendong Song, Chenjun Xiao, Dehao Zhang, Ebony Zhang, Frederick Pu, Han Zhu, et al. Kimina-Prover preview: Towards large formal reasoning models with reinforcement learning. ar...
2025
-
[71]
Jiang, Sean Welleck, Jin Peng Zhou, Wenda Li, Jiacheng Liu, Mateja Jamnik, Timothée Lacroix, Yuhuai Wu, and Guillaume Lample
Albert Q. Jiang, Sean Welleck, Jin Peng Zhou, Wenda Li, Jiacheng Liu, Mateja Jamnik, Timothée Lacroix, Yuhuai Wu, and Guillaume Lample. Draft, sketch, and prove: Guiding formal theorem provers with informal proofs. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[72]
LEGO-Prover: Neural theorem proving with growing libraries.arXiv preprint, 2023
Haiming Wang, Huajian Xin, Chuanyang Zheng, Lin Li, Zhengying Liu, Qingxing Cao, Yinya Huang, Jing Xiong, Han Shi, Enze Xie, Jian Yin, Zhenguo Li, Heng Liao, and Xiaodan Liang. LEGO-Prover: Neural theorem proving with growing libraries.arXiv preprint, 2023
2023
-
[73]
An in-context learning agent for formal theorem-proving.arXiv preprint, 2023
Amitayush Thakur, George Tsoukalas, Yeming Wen, Jimmy Xin, and Swarat Chaudhuri. An in-context learning agent for formal theorem-proving.arXiv preprint, 2023
2023
-
[74]
HyperTree proof search for neural theorem proving.arXiv preprint, 2022
Guillaume Lample, Marie-Anne Lachaux, Thibaut Lavril, Xavier Martinet, Amaury Hayat, Gabriel Ebner, Aurélien Rodriguez, and Timothée Lacroix. HyperTree proof search for neural theorem proving.arXiv preprint, 2022
2022
-
[75]
Reliable evaluation and benchmarks for statement autoformalization
Auguste Poiroux, Gail Weiss, Viktor Kunˇcak, and Antoine Bosselut. Reliable evaluation and benchmarks for statement autoformalization. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2025
2025
-
[76]
Autoformalize mathematical statements by symbolic equivalence and semantic consistency
Zenan Li, Yifan Wu, Zhaoyu Li, Xinming Wei, Xian Zhang, Fan Yang, and Xiaoxing Ma. Autoformalize mathematical statements by symbolic equivalence and semantic consistency. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[77]
Autoformalization in the wild: Assessing LLMs on real-world mathematical definitions.arXiv preprint, 2025
Lan Zhang, Marco Valentino, and Andre Freitas. Autoformalization in the wild: Assessing LLMs on real-world mathematical definitions.arXiv preprint, 2025
2025
-
[78]
Evaluating autoformalization robustness via semantically similar paraphrasing.arXiv preprint, 2025
Hayden Moore and Asfahan Shah. Evaluating autoformalization robustness via semantically similar paraphrasing.arXiv preprint, 2025
2025
-
[79]
propositional formula
Jianqiao Lu, Yingjia Wan, Yinya Huang, Jing Xiong, Zhengying Liu, and Zhijiang Guo. FormalAlign: Automated alignment evaluation for autoformalization.arXiv preprint, 2024. A Details of the Automated Formalization Pipeline This appendix gives a detailed account of the four-stage automated pipeline summarized in Section 3. A.1 Pre-Processing The textbook PD...
2024
-
[80]
2.Build succeeds.lake env leanonˆyreturns exit code zero; warnings are permitted
Declarations present.Every target in Ty appears in ˆywith a type signature whitespace-equivalent to its ground-truth signature. 2.Build succeeds.lake env leanonˆyreturns exit code zero; warnings are permitted. 3.Nosorry.After stripping comments and string literals, nosorrykeyword remains
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.