GRACE-RAG: Governed Retrieval Architecture for Canonical Evidence Synthesis, Enabling Lightweight Deployment in Closed-Domain Institutional Settings
Pith reviewed 2026-07-02 23:37 UTC · model grok-4.3
The pith
A graph-augmented retrieval layer externalizes structural reasoning from generation, enabling lightweight models to improve evidence quality in closed-domain institutional settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
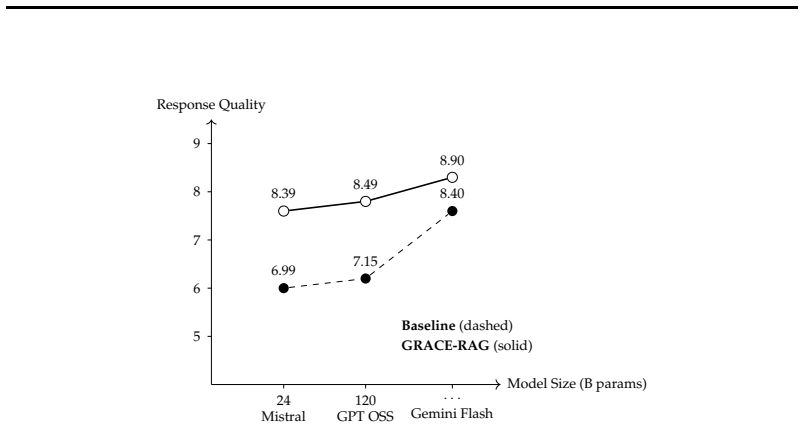
GRACE-RAG is a retrieval-governed, graph-augmented RAG architecture that externalizes structural reasoning from the generative stage to a structured retrieval layer, resolving structural ambiguity offline and enabling deployment on self-hosted lightweight models calibrated to closed-domain institutional vocabulary, with experiments showing consistent improvements in completeness, depth, and anticipatory coverage plus quality gains of up to 20 percent under mid-scale models.
What carries the argument
The graph-augmented retrieval layer that resolves structural ambiguity offline before passing evidence to generation.
If this is right
- Quality gains of up to 20 percent with mid-scale models such as Mistral 24B.
- Consistent improvements in completeness, depth, and anticipatory coverage across tested model capacities.
- Reduced computational and latency footprint compared with reliance on larger models.
- Deployment possible on self-hosted models without proprietary systems.
- Enables lightweight operation in closed-domain institutional settings.
Where Pith is reading between the lines
- The offline structural layer may reduce the need for prompt engineering or post-generation correction in similar synthesis tasks.
- Institutions could apply the same retrieval governance pattern to other heterogeneous document collections without retraining base models.
- Direct ablation of the graph component versus vector-only baselines on new domain data would test whether the quality lift holds beyond the reported experiments.
- The approach opens a path to parameter-free scaling of evidence synthesis by investing in retrieval structure rather than model size.
Load-bearing premise
The graph-augmented retrieval layer can resolve structural ambiguity offline for entity-dense domains with heterogeneous documents.
What would settle it
A side-by-side test on the same institutional document collection and models where adding the graph-augmented layer produces no gain or a drop in measured completeness and depth relative to plain vector retrieval.
Figures
read the original abstract
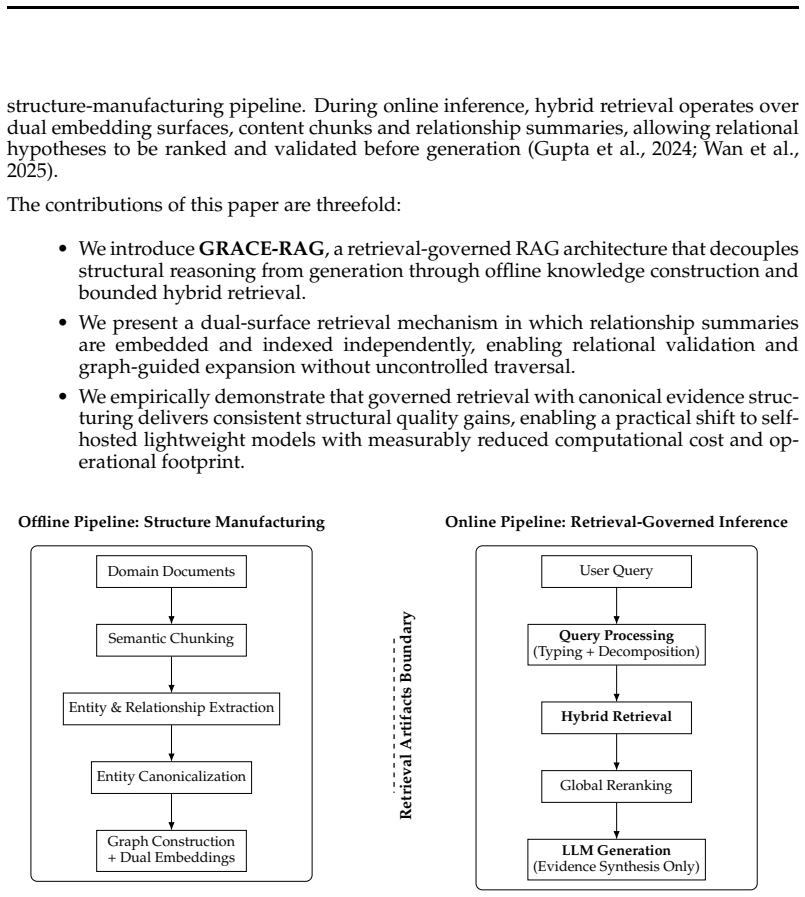
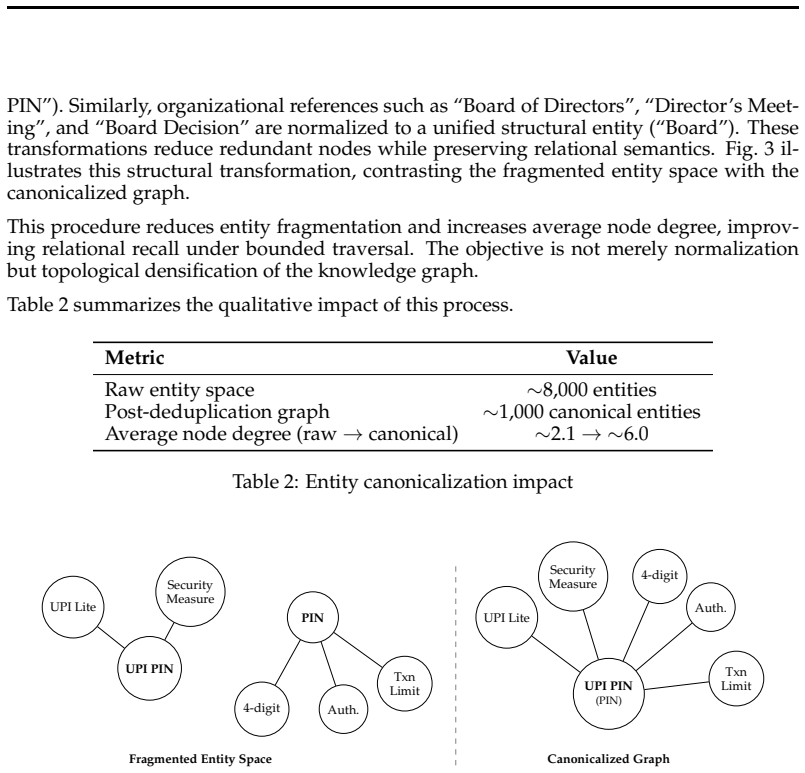
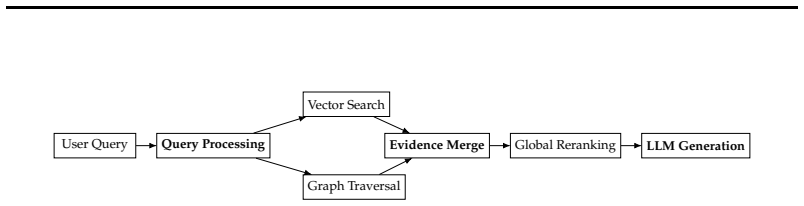
Retrieval-Augmented Generation (RAG) systems are widely used in institutional question answering settings where responses must be grounded in authoritative documentation (Gao et al., 2023). In entity-dense domains where relevant information is distributed across heterogeneous documents, vector-only retrieval often produces fragmented evidence and increases dependence on inference-time reasoning (Zhao et al., 2024). This paper introduces GRACE-RAG, a retrieval-governed, graph-augmented RAG architecture that externalizes structural reasoning from the generative stage to a structured retrieval layer, resolving structural ambiguity offline, enabling deployment on self-hosted lightweight models calibrated to closed-domain institutional vocabulary. Experiments across three model capacities: Mistral 24B, GPT OSS 120B, and Gemini 2.5 Flash show consistent improvements in completeness, depth, and anticipatory coverage, with overall quality gains of up to 20% under mid-scale models, indicating that retrieval architecture governs structural quality over model scale, reducing computational and latency footprint without dependence on proprietary systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GRACE-RAG, a retrieval-governed graph-augmented RAG architecture for closed-domain institutional QA in entity-dense settings. It claims that externalizing structural reasoning to a structured retrieval layer resolves ambiguity offline, enabling effective use of lightweight self-hosted models. Experiments on Mistral 24B, GPT OSS 120B, and Gemini 2.5 Flash are said to show consistent gains in completeness, depth, and anticipatory coverage (up to 20% overall quality improvement, strongest under mid-scale models), supporting the conclusion that retrieval architecture governs structural quality over model scale and reduces dependence on proprietary systems.
Significance. If the experimental claims are substantiated with proper controls, the result would be significant for institutional deployments: it offers a path to high-quality grounded QA on resource-constrained hardware without reliance on large proprietary models, directly addressing latency and cost barriers in regulated or closed-domain environments.
major comments (2)
- [Abstract] Abstract: The central claim that 'retrieval architecture governs structural quality over model scale' rests on reported 'up to 20% quality gains' and 'consistent improvements,' yet the text supplies no metrics, evaluation protocol, baselines (standard vector RAG on the same models), or ablation removing the graph component. This absence prevents isolation of the architecture's contribution from model capacity, domain tuning, or the closed-domain setting.
- [Abstract] Abstract: No results are presented for the larger models (GPT OSS 120B, Gemini 2.5 Flash) under standard vector retrieval, nor any quantitative measure of 'offline resolution of structural ambiguity.' Without these controls the reported gains cannot be attributed to the proposed graph-augmented layer.
minor comments (1)
- [Abstract] Abstract: The citations (Gao et al., 2023; Zhao et al., 2024) are relevant but the specific connection between 'fragmented evidence' and vector-only retrieval could be stated more precisely to strengthen the problem motivation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the need for explicit experimental controls and metrics. We agree that the current abstract does not sufficiently detail the evaluation protocol, baselines, or ablations, and we will revise the manuscript to address these points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'retrieval architecture governs structural quality over model scale' rests on reported 'up to 20% quality gains' and 'consistent improvements,' yet the text supplies no metrics, evaluation protocol, baselines (standard vector RAG on the same models), or ablation removing the graph component. This absence prevents isolation of the architecture's contribution from model capacity, domain tuning, or the closed-domain setting.
Authors: We agree that the abstract lacks these specifics and that this weakens the ability to isolate the architecture's contribution. In the revised manuscript we will expand the abstract to report the evaluation metrics (completeness, depth, anticipatory coverage), describe the protocol, explicitly reference the standard vector RAG baselines run on the identical model set, and note the graph-component ablation results. These additions will be drawn from the experiments section and will allow readers to assess the claimed gains independently of model scale or domain effects. revision: yes
-
Referee: [Abstract] Abstract: No results are presented for the larger models (GPT OSS 120B, Gemini 2.5 Flash) under standard vector retrieval, nor any quantitative measure of 'offline resolution of structural ambiguity.' Without these controls the reported gains cannot be attributed to the proposed graph-augmented layer.
Authors: We acknowledge that the abstract does not present vector-retrieval results for the larger models or a quantitative measure of offline ambiguity resolution. The revised abstract will include a concise statement of the vector-retrieval performance for GPT OSS 120B and Gemini 2.5 Flash, together with a quantitative indicator of structural ambiguity resolved at retrieval time. This will make the attribution to the graph-augmented layer explicit and will be supported by the corresponding tables and analysis in the full experiments section. revision: yes
Circularity Check
No circularity; architecture and empirical claims are self-contained without self-referential definitions or fitted predictions
full rationale
The paper presents GRACE-RAG as a graph-augmented retrieval architecture and reports experimental quality gains across model scales. No equations, parameter-fitting steps, or self-citations appear in the provided abstract or description. The central claim (retrieval architecture governs structural quality) is framed as an empirical outcome from experiments rather than a derivation that reduces to its own inputs by construction. No load-bearing self-citation chains, ansatzes smuggled via prior work, or renamings of known results are present. This is the expected non-finding for an empirical systems paper without mathematical derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Large Language Models: A Survey
Retrieval-augmented generation for large language models: A survey , author=. arXiv preprint arXiv:2312.10997 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Retrieval-augmented generation for
Zhao, Penghao and Zhang, Hailin and Yu, Qiang and Wang, Zhe and Geng, Yi and Fu, Fei and Cui, Bo , journal=. Retrieval-augmented generation for
-
[3]
arXiv preprint arXiv:2307.11019 , year=
Investigating the factual knowledge boundary of large language models with retrieval augmentation , author=. arXiv preprint arXiv:2307.11019 , year=
-
[4]
Graph retrieval-augmented generation: A survey
Graph retrieval-augmented generation: A survey , author=. arXiv preprint arXiv:2408.08921 , year=
-
[5]
arXiv preprint arXiv:2504.10499 , year=
Graph-based approaches and functionalities in retrieval-augmented generation: A comprehensive survey , author=. arXiv preprint arXiv:2504.10499 , year=
-
[6]
Retrieval-augmented generation for knowledge-intensive
Lewis, Patrick and Oguz, Barlas and Rinott, Ruty and Edunov, Sergey and Kocisky, Tomas and Zettlemoyer, Luke , booktitle=. Retrieval-augmented generation for knowledge-intensive
-
[7]
A survey on
Arslan, Mehmet , journal=. A survey on
-
[8]
arXiv preprint arXiv:2503.10677 , year=
A survey on knowledge-oriented retrieval-augmented generation , author=. arXiv preprint arXiv:2503.10677 , year=
-
[9]
ACM Transactions on Information Systems , volume=
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions , author=. ACM Transactions on Information Systems , volume=
-
[10]
Empowering
Wan, Yulong and others , journal=. Empowering
-
[11]
Pipitone, Nicholas and Houir Alami, Ghita , journal=
-
[12]
arXiv preprint arXiv:2410.12837 , year=
A comprehensive survey of retrieval-augmented generation: Evolution, current landscape and future directions , author=. arXiv preprint arXiv:2410.12837 , year=
-
[13]
Retrieval-augmented generation with knowledge graphs for customer service
Xu, Zhentao and others , booktitle=. Retrieval-augmented generation with knowledge graphs for customer service
-
[14]
arXiv preprint arXiv:2502.06864 , year=
Knowledge graph-guided retrieval augmented generation , author=. arXiv preprint arXiv:2502.06864 , year=
-
[15]
Han, Yuntong and others , journal=
-
[16]
Document
Knollmeyer, Simon and others , journal=. Document
-
[17]
Applied Intelligence , year=
Knowledge graph-extended retrieval-augmented generation with chain-of-thought , author=. Applied Intelligence , year=
-
[18]
Information , volume=
A systematic evaluation of large language models with retrieval-augmented generation for question answering , author=. Information , volume=
-
[19]
arXiv preprint arXiv:2501.06796 , year=
Prospects and challenges of retrieval-augmented generation in institutional contexts , author=. arXiv preprint arXiv:2501.06796 , year=
-
[20]
Mavromatis, Costas and others , booktitle=
-
[21]
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and others , booktitle=. Judging
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.