Reliability-Prioritized Fine-Grained Generation in Multimodal Large
Pith reviewed 2026-06-30 07:11 UTC · model grok-4.3
The pith
Fine-grained generation in multimodal models is more error-prone than coarse-grained, so models should produce only the finest reliable level of detail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
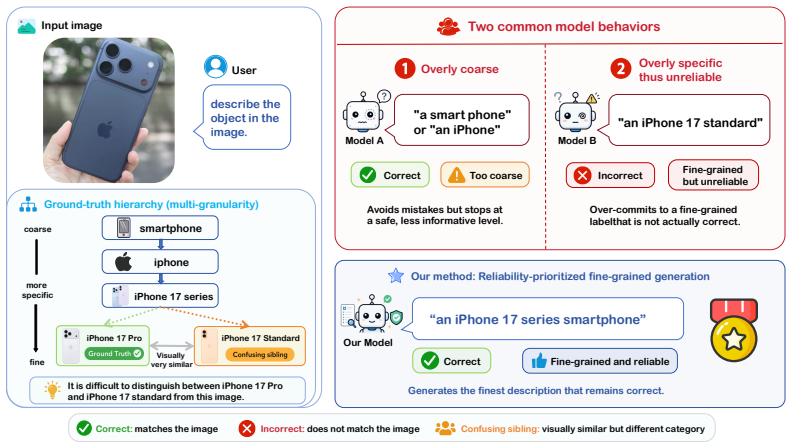
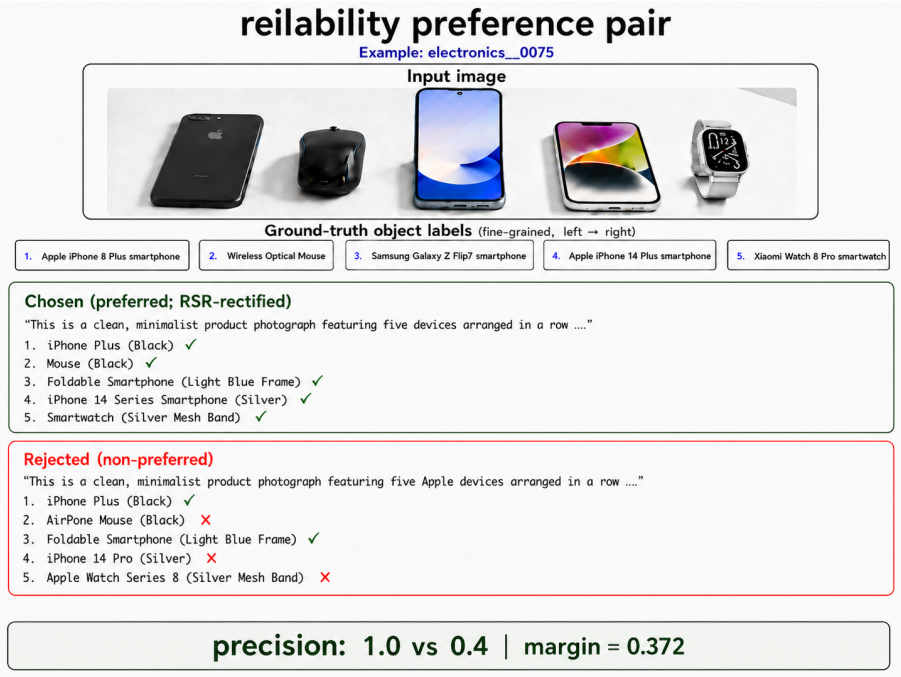
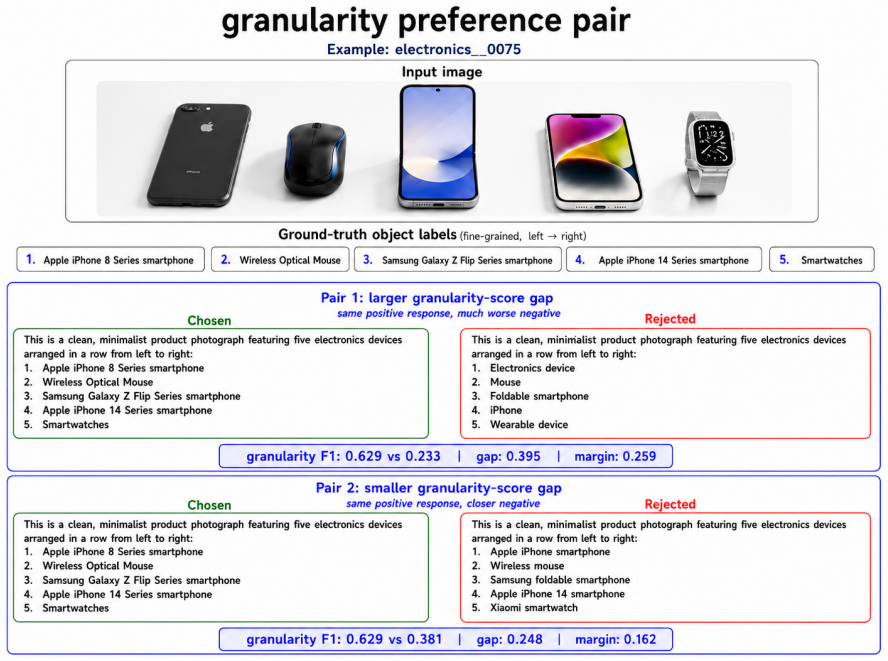
Generating fine-grained responses poses a reliability challenge: fine-grained generation is more error-prone than coarse-grained generation. Models should therefore generate the finest description that remains reliable rather than simply produce more specific outputs. This is operationalized through the GranFact benchmark, a hierarchy-aware evaluation algorithm, and a reliability-prioritized preference optimization method that penalizes unreliable fine-grained claims while rewarding reliable specificity.
What carries the argument
Reliability-prioritized preference optimization based on Direct Preference Optimization, which penalizes unreliable fine-grained claims while rewarding reliable specificity.
If this is right
- The method improves fine-grained generation performance while preserving overall reliability on the GranFact benchmark.
- Hierarchy-aware evaluation can distinguish correct but overly coarse answers from correct and appropriately specific ones.
- Preference optimization can be used to trade off specificity against error rate in multimodal generation tasks.
Where Pith is reading between the lines
- The same reliability-first principle could be tested on tasks such as video captioning or chart description where granularity also varies.
- If the preference optimization generalizes, it might reduce hallucination rates in other detail-heavy multimodal applications without explicit benchmarks.
Load-bearing premise
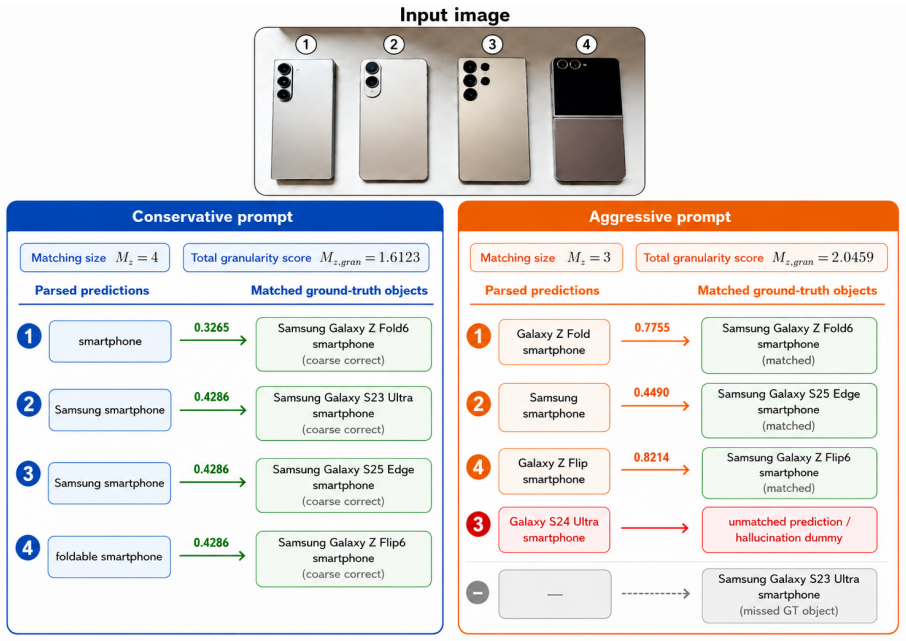
The hierarchy-aware evaluation algorithm correctly measures both visual correctness and specificity level without introducing its own biases.
What would settle it
An experiment showing that the optimized model produces a higher rate of incorrect fine-grained claims than the baseline on the expert-verified GranFact images.
Figures










read the original abstract
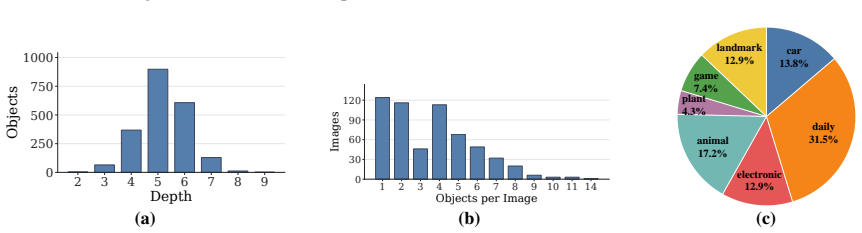
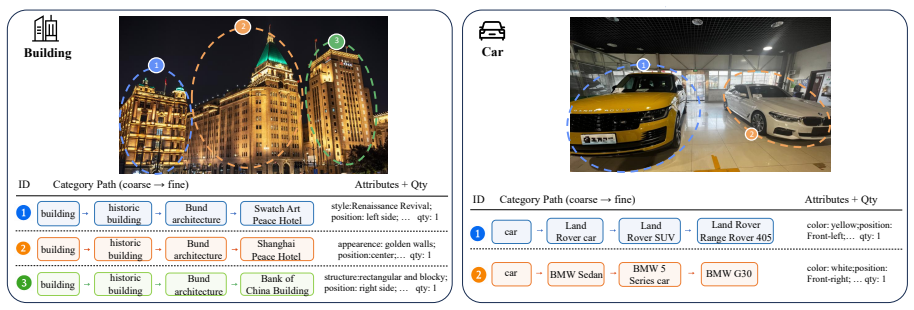
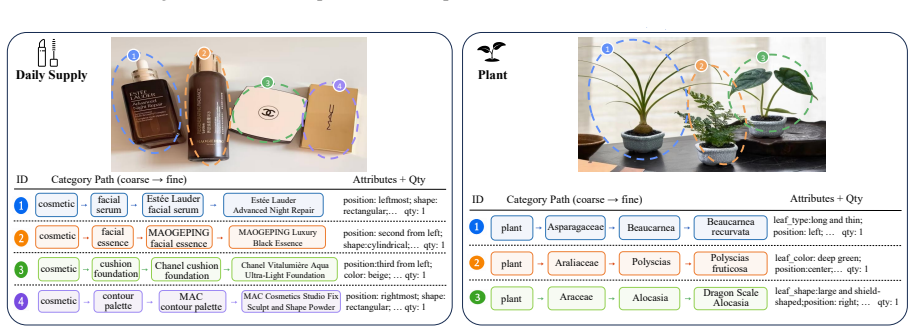
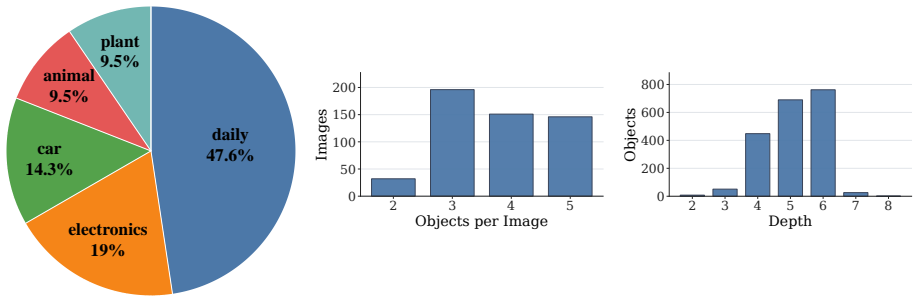
Multimodal large language models (MLLMs) are increasingly expected to generate fine-grained descriptions of visual content. However, we observe and theoretically show that generating fine-grained responses poses a reliability challenge, \textit{i.e.}, fine-grained generation is more error-prone than coarse-grained generation. This phenomenon suggests that models should generate the finest description that remains reliable rather than simply produce more specific outputs. To investigate this problem, we develop \textsc{GranFact}, a granularity-aware benchmark consisting of expert-verified multi-object images with coarse-to-fine category annotations. Then, we design a hierarchy-aware evaluation algorithm, which assesses both whether model predictions are visually correct and how specific the correct predictions are. We also propose a reliability-prioritized preference optimization method based on Direct Preference Optimization, which penalizes unreliable fine-grained claims while rewarding reliable specificity. Experiments on \textsc{GranFact} show that our method improves fine-grained generation while preserving reliability. Code and data are available \href{https://github.com/WeiWu2025/GranFact}{here}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fine-grained generation in multimodal large language models (MLLMs) is inherently more error-prone than coarse-grained generation, as shown theoretically and observed empirically. It introduces GranFact, a benchmark of expert-verified multi-object images with coarse-to-fine category annotations, along with a hierarchy-aware evaluation algorithm that jointly assesses visual correctness and specificity level. A reliability-prioritized preference optimization method extending Direct Preference Optimization (DPO) is proposed to penalize unreliable fine-grained claims while rewarding reliable specificity, with experiments on GranFact demonstrating improved fine-grained generation without sacrificing reliability. Code and data are released.
Significance. If the central claims hold, the work identifies and mitigates a practically important reliability-specificity trade-off in MLLM visual description tasks. The open release of code, data, and the benchmark constitutes a concrete contribution to reproducibility and future work on granularity-aware evaluation.
major comments (2)
- [hierarchy-aware evaluation algorithm section] The hierarchy-aware evaluation algorithm (described after the GranFact benchmark construction) is load-bearing for both the benchmark labels and the DPO preference pairs, yet the manuscript supplies no pseudocode, edge-case rules, or quantitative validation (e.g., agreement with expert annotations on granularity mapping and correctness thresholds). Without these, it is impossible to rule out systematic bias in the reported reliability gap.
- [theoretical demonstration paragraph] The theoretical demonstration that fine-grained responses are more error-prone is invoked to motivate the entire approach, but the specific assumptions, model of error accumulation, or derivation steps are not stated with sufficient formality to allow independent verification or falsification.
minor comments (2)
- [evaluation section] Notation for granularity levels and correctness scores should be defined once in a table or equation block rather than re-introduced inline.
- [experiments section] The experimental tables would benefit from explicit reporting of the number of preference pairs used in the DPO stage and the exact weighting between reliability and specificity terms.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where additional detail will strengthen the manuscript. We address each major comment below and commit to revisions that improve clarity and verifiability without altering the core claims.
read point-by-point responses
-
Referee: [hierarchy-aware evaluation algorithm section] The hierarchy-aware evaluation algorithm (described after the GranFact benchmark construction) is load-bearing for both the benchmark labels and the DPO preference pairs, yet the manuscript supplies no pseudocode, edge-case rules, or quantitative validation (e.g., agreement with expert annotations on granularity mapping and correctness thresholds). Without these, it is impossible to rule out systematic bias in the reported reliability gap.
Authors: We agree that the hierarchy-aware evaluation algorithm requires more explicit documentation to enable independent verification. In the revised version we will add (i) pseudocode for the full algorithm, (ii) explicit rules for all identified edge cases (e.g., partial overlaps, ambiguous granularity boundaries), and (iii) quantitative validation results including agreement statistics between the algorithm and expert annotations on both correctness and granularity mapping. These additions will be placed in a dedicated subsection immediately following the benchmark description. revision: yes
-
Referee: [theoretical demonstration paragraph] The theoretical demonstration that fine-grained responses are more error-prone is invoked to motivate the entire approach, but the specific assumptions, model of error accumulation, or derivation steps are not stated with sufficient formality to allow independent verification or falsification.
Authors: We acknowledge that the current theoretical paragraph is presented at a high level. In revision we will expand this section to (a) list all modeling assumptions explicitly, (b) define the error-accumulation model with precise notation, and (c) provide the key derivation steps in a self-contained formal argument. If space permits we will also include a short proof sketch in the main text or an appendix. revision: yes
Circularity Check
No circularity; derivation self-contained against external benchmarks
full rationale
The abstract and provided context introduce GranFact as an expert-annotated benchmark and a hierarchy-aware evaluation algorithm as a measurement tool, then apply standard DPO-style optimization to penalize unreliable fine claims. No quoted equations, self-citations, or fitted parameters reduce the central observation (fine-grained generation being more error-prone) or the reported improvements to a definitional identity or input fit by construction. The evaluation algorithm is invoked to score outputs but does not redefine the reliability phenomenon itself; experiments are presented as external validation on the new benchmark. This is the normal case of an independent empirical claim.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InEuropean Confer- ence on Computer Vision, pages 370–387
Sharegpt4v: Improving large multi-modal models with better captions. InEuropean Confer- ence on Computer Vision, pages 370–387. Springer. Wei Chen, Xin Yan, Bin Wen, Fan Yang, Tingting Gao, Di Zhang, and Long Chen. 2025. Decoupling con- trastive decoding: Robust hallucination mitigation in multimodal large language models.Advances in Neural Information Pr...
-
[2]
Fine-Grained Visual Classification of Aircraft
Mitigating object hallucinations in large vision- language models through visual contrastive decod- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872–13882. Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023a. Blip-2: Bootstrapping language-image pre- training with frozen image encoders and larg...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Ab- delrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M Anwer, Eric Xing, Ming-Hsuan Yang, and Fahad S Khan. 2024. Glamm: Pixel grounding large multimodal model. I...
-
[4]
Protect: Prompt tuning for taxonomic open set classification. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 16531–16540. Wei Wu, Xiaomeng Fan, Yuwei Wu, Zhi Gao, Pengx- iang Li, Yunde Jia, and Mehrtash Harandi. 2026. Modality alignment across trees on heterogeneous hyperbolic manifolds. InInternational Confer...
-
[5]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans? InInternational Conference on Learning Representations, volume 2025, pages 89655–89701. Yiyang Zhou, Chenhang Cui, Jaehong Yoon, Linjun Zhang, Zhun Deng, Chelsea Finn, Mohit Bansal, and Huaxiu Yao. 2024a. Analyzing and mitigating object h...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
The word “SAMSUNG” is visible near the bottom
Second phone:A light-colored device with a vertical camera module containing two lenses and a flash. The word “SAMSUNG” is visible near the bottom
-
[7]
P” shape. The word “SAMSUNG
Third phone:A light-colored device with a camera array consisting of five circular elements arranged in a “P” shape. The word “SAMSUNG” is faintly visible near the bottom
-
[8]
It has a dark upper section containing two camera lenses and a flash, and a light-colored lower section
Fourth phone:A foldable device shown in its closed state. It has a dark upper section containing two camera lenses and a flash, and a light-colored lower section. Gemini-3.1-Flash under the aggressive prompt This high-angle, eye-level shot displays four Samsung smartphones arranged in a row on a plain, light-colored surface. The phones are positioned vert...
-
[9]
It has a matte, light-gray finish
First Phone:This is a tall, narrow device, likely a Galaxy Z Fold model. It has a matte, light-gray finish. On the left side, there is a vertical camera module containing three circular lenses stacked one above the other
-
[10]
It features a vertical camera housing on the top left with two large, prominent circular lenses and a small flash below them
Second Phone:This device has a smooth, metallic, champagne-gold finish. It features a vertical camera housing on the top left with two large, prominent circular lenses and a small flash below them. The “SAMSUNG” logo is faintly visible in the lower center of the back panel
-
[11]
It has a similar champagne-gold, matte finish
Third Phone:This appears to be a Galaxy S24 Ultra or similar model. It has a similar champagne-gold, matte finish. The camera array is distinct, featuring five circular elements: three large lenses arranged vertically on the left, and two smaller circular components, a lens and a flash/sensor, to their right. The “SAMSUNG” logo is subtly embossed near the bottom
-
[12]
The top half of the back is a glossy black panel containing two circular camera lenses and a small flash
Fourth Phone:This is a foldable device, likely a Galaxy Z Flip model, shown in its closed state. The top half of the back is a glossy black panel containing two circular camera lenses and a small flash. The bottom half is a matte, muted-brown or taupe-colored panel. The phone has a metallic frame visible along the edges. The lighting is even and soft, cas...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.