Efficient and Trainable Language Model Test-Time Scaling via Local Branch Routing
Pith reviewed 2026-06-25 21:27 UTC · model grok-4.3
The pith
Local Branch Routing improves language-model reasoning by routing among short lookahead branches using their hidden states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
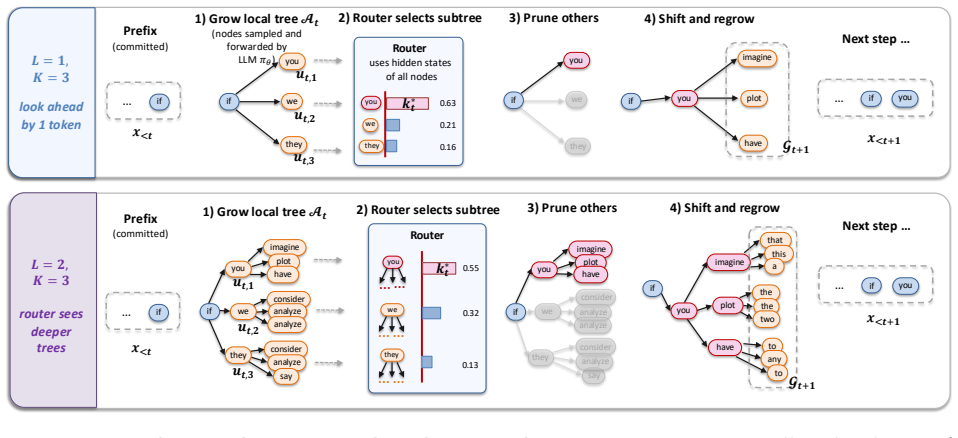
Local Branch Routing expands a small local lookahead tree, forwards every sampled branch through the language model, and uses a router over the hidden states of those local futures to choose which depth-1 subtree to commit; the resulting discrete trajectory admits an explicit likelihood that supports joint reinforcement learning of the base model and router under the likelihood-ratio principle.
What carries the argument
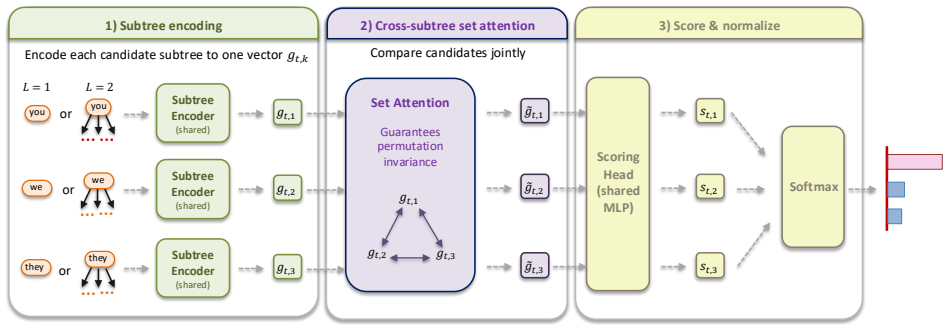
Local Branch Routing (LBR): a router that selects the next depth-1 subtree by inspecting hidden states of candidate local futures rather than only the root next-token distribution.
If this is right
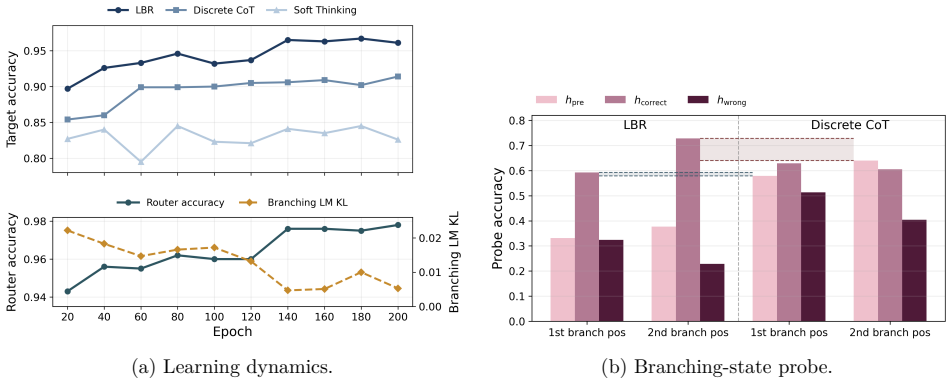
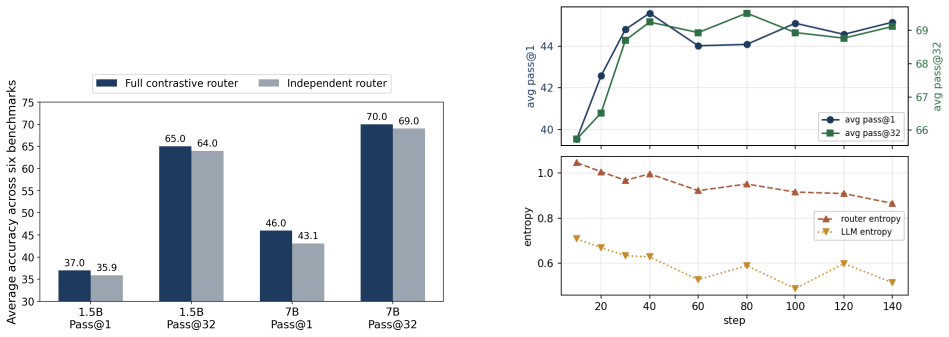
- LBR raises both Pass@1 and Pass@32 on mathematical reasoning benchmarks over discrete chain-of-thought, vanilla discrete-token RLVR, and RL-compatible soft-token branching baselines.
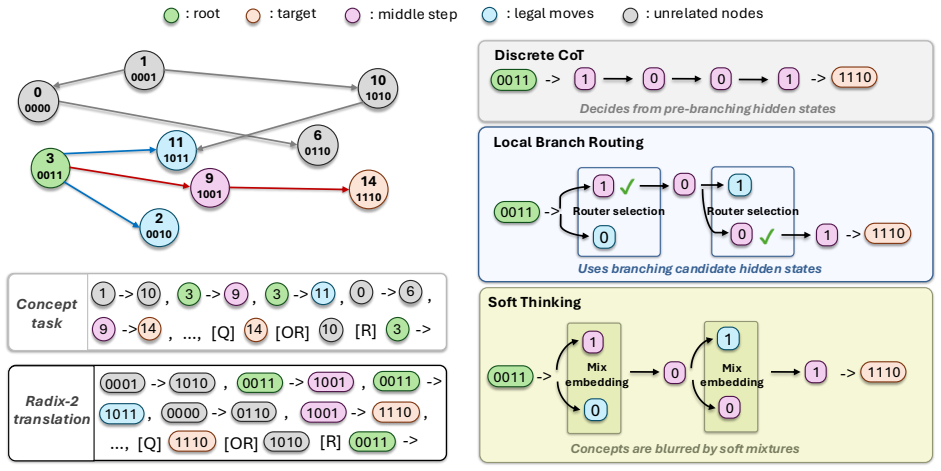
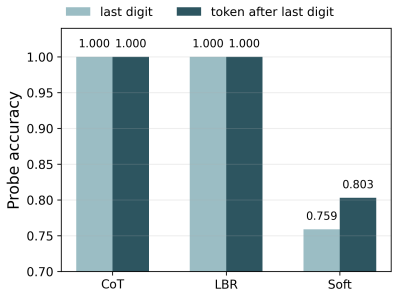
- Post-candidate hidden states supply measurable routing evidence on synthetic hierarchical-planning tasks.
- The prune-shift-grow process preserves discrete branch identities and yields a tractable tree-trajectory likelihood for end-to-end RL.
- The framework jointly optimizes the base model and router under the same likelihood-ratio principle used for discrete-token RLVR.
Where Pith is reading between the lines
- If the local-hidden-state signal generalizes, the same router could be attached to non-math reasoning domains that already use short lookahead.
- Increasing the local tree depth beyond one might trade additional compute for further accuracy gains while still avoiding full-solution search.
- Because branches remain discrete, LBR trajectories could be combined with external verifiers without changing the likelihood definition.
- The method's efficiency may allow repeated test-time application inside an outer search loop that the paper itself does not explore.
Load-bearing premise
Routing decisions based on the hidden states of candidate local futures supply useful evidence beyond the root next-token distribution and permit reliable selection of the depth-1 subtree to commit.
What would settle it
An ablation in which the router is replaced by a decision that uses only the root next-token distribution and yields statistically identical Pass@1 and Pass@32 scores on the same mathematical reasoning benchmarks.
Figures
read the original abstract
Test-time scaling improves language-model reasoning, but existing approaches often face a difficult trade-off: long chain-of-thought sampling remains single-threaded, while sentence- or solution-level search can be computationally expensive and hard to train end-to-end. We introduce Local Branch Routing (LBR), a token-level test-time scaling framework that expands a small local lookahead tree, forwards all sampled branches through the language model, and uses a lightweight router to select the depth-1 subtree to commit. By routing over the hidden states of candidate local futures, LBR allows each token decision to use evidence beyond the root next-token distribution while avoiding full solution-level search. The resulting prune-shift-grow decoding process preserves discrete branch identities and defines a tractable tree-trajectory likelihood: newly grown nodes are counted when first sampled, and router decisions are assigned explicit probabilities. This enables end-to-end reinforcement learning with verifiable rewards, jointly optimizing the base model and router under the same likelihood-ratio principle as discrete-token RLVR. On synthetic hierarchical-planning tasks, LBR shows that post-candidate hidden states provide useful routing evidence. On mathematical reasoning benchmarks, LBR improves both Pass@1 and Pass@32 over discrete chain-of-thought, vanilla discrete-token RLVR, and RL-compatible soft-token branching baselines. These results suggest that lightweight local branching offers an efficient, trainable, and discrete form of language-model test-time scaling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Local Branch Routing (LBR), a token-level test-time scaling framework for language models. At each step it expands a small local lookahead tree, forwards all branches through the model, and employs a lightweight router over the hidden states of the candidate depth-1 futures to select which subtree to commit. The resulting prune-shift-grow process preserves discrete branch identities and yields a tractable tree-trajectory likelihood (newly grown nodes counted on first sampling, router decisions given explicit probabilities), enabling end-to-end RL with verifiable rewards that jointly optimizes the base model and router. The paper reports that hidden-state routing supplies useful evidence on synthetic hierarchical-planning tasks and that LBR improves both Pass@1 and Pass@32 on mathematical reasoning benchmarks relative to discrete chain-of-thought, vanilla discrete-token RLVR, and RL-compatible soft-token branching baselines.
Significance. If the empirical claims hold, LBR supplies an efficient, trainable, and discrete alternative to full solution-level search while still allowing each token decision to condition on evidence beyond the immediate next-token distribution. The explicit, tractable likelihood definition that supports joint RL optimization of model and router is a clear methodological strength that could be reused in other test-time scaling settings.
major comments (2)
- [Abstract (results paragraph) and experimental results section] The central claim that routing decisions based on hidden states of candidate local futures supply useful evidence beyond the root next-token distribution is load-bearing for attributing the reported Pass@1/Pass@32 gains to LBR rather than to the prune-shift-grow structure or the joint RL objective alone. The abstract states that this utility is demonstrated on synthetic hierarchical-planning tasks, yet no corresponding ablation, analysis, or comparison against a router that receives only the root hidden state is provided for the mathematical reasoning benchmarks where the headline improvements are claimed.
- [Method section on likelihood and RL objective] The definition of the tree-trajectory likelihood (newly grown nodes counted when first sampled, router decisions assigned explicit probabilities) is presented as enabling standard likelihood-ratio RL. Without the explicit equations or pseudocode that show how the likelihood is normalized across the local tree and how the router probability is folded into the trajectory probability, it is impossible to confirm that the RL objective remains unbiased with respect to the discrete branch identities.
minor comments (2)
- [Abstract] The abstract asserts performance gains without any numerical values, dataset names, or error bars; the experimental section should include these details together with the exact number of runs used for the reported Pass@1 and Pass@32 figures.
- [Method] Notation for the router input (post-candidate hidden states) should be introduced once with a clear equation or diagram rather than relying on prose descriptions that appear in multiple places.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that both major comments identify areas where the manuscript can be strengthened for clarity and attribution of results. We will revise the paper accordingly to address these points.
read point-by-point responses
-
Referee: [Abstract (results paragraph) and experimental results section] The central claim that routing decisions based on hidden states of candidate local futures supply useful evidence beyond the root next-token distribution is load-bearing for attributing the reported Pass@1/Pass@32 gains to LBR rather than to the prune-shift-grow structure or the joint RL objective alone. The abstract states that this utility is demonstrated on synthetic hierarchical-planning tasks, yet no corresponding ablation, analysis, or comparison against a router that receives only the root hidden state is provided for the mathematical reasoning benchmarks where the headline improvements are claimed.
Authors: We agree that the manuscript would be strengthened by providing evidence of the hidden-state router's utility specifically on the mathematical reasoning benchmarks. The current version demonstrates this on synthetic hierarchical-planning tasks to isolate the routing mechanism, while reporting overall Pass@1/Pass@32 gains on math benchmarks. In the revised manuscript, we will add an ablation or analysis in the experimental results section comparing the full LBR router against a root-hidden-state-only variant on the math tasks to better attribute the gains. revision: yes
-
Referee: [Method section on likelihood and RL objective] The definition of the tree-trajectory likelihood (newly grown nodes counted when first sampled, router decisions assigned explicit probabilities) is presented as enabling standard likelihood-ratio RL. Without the explicit equations or pseudocode that show how the likelihood is normalized across the local tree and how the router probability is folded into the trajectory probability, it is impossible to confirm that the RL objective remains unbiased with respect to the discrete branch identities.
Authors: We acknowledge that the method section would benefit from greater explicitness. The current description outlines the counting of newly grown nodes and assignment of router probabilities, but does not include the full normalization equations or pseudocode. In the revision, we will add the complete mathematical formulation of the tree-trajectory likelihood, including normalization across the local tree and how router probabilities are incorporated into the trajectory probability, to confirm unbiasedness under the likelihood-ratio RL objective. revision: yes
Circularity Check
No significant circularity; derivation self-contained via explicit definitions
full rationale
The paper's central construction explicitly defines a tractable tree-trajectory likelihood by counting newly grown nodes at first sampling and assigning explicit probabilities to router decisions, then applies standard likelihood-ratio RL under the same principle as discrete-token RLVR. This is presented as an enabling mechanism rather than a reduction of results to fitted inputs or prior self-citations by construction. Benchmark gains and synthetic-task validation of hidden-state routing evidence are reported as empirical outcomes of the defined process, with no load-bearing step shown to equate to its inputs via self-definition, fitted prediction, or imported uniqueness. The derivation therefore remains independent of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644, 2016
Pith/arXiv arXiv 2016
-
[2]
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it’s lying. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, Singapore, December 2023. As- sociation for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.68. URL https://aclantholog...
-
[3]
Probing Classifiers: Promises, Shortcomings, and Advances
Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances.Computa- tional Linguistics, 48(1):207–219, March 2022. doi: 10.1162/coli_a_00422. URL https: //aclanthology.org/2022.cl-1.7/
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[4]
Soft tokens, hard truths.arXiv preprint arXiv:2509.19170, 2025
Natasha Butt, Ariel Kwiatkowski, Ismail Labiad, Julia Kempe, and Yann Ollivier. Soft tokens, hard truths.arXiv preprint arXiv:2509.19170, 2025
arXiv 2025
-
[5]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318, 2023. 12
Pith/arXiv arXiv 2023
-
[6]
Yichao Fu, Peter Bailis, Ion Stoica, and Hao Zhang. Break the sequential dependency of llm inference using lookahead decoding.arXiv preprint arXiv:2402.02057, 2024
arXiv 2024
-
[7]
Scaling speculative decoding with lookahead reasoning.arXiv preprint arXiv:2506.19830, 2025
Yichao Fu, Rui Ge, Zelei Shao, Zhijie Deng, and Hao Zhang. Scaling speculative decoding with lookahead reasoning.arXiv preprint arXiv:2506.19830, 2025
arXiv 2025
-
[8]
Halil Alperen Gozeten, M Emrullah Ildiz, Xuechen Zhang, Hrayr Harutyunyan, Ankit Singh Rawat, and Samet Oymak. Continuous chain of thought enables parallel exploration and reasoning.arXiv preprint arXiv:2505.23648, 2025
arXiv 2025
-
[9]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[10]
Reasoning with language model is planning with world model
Shibo Hao, Yi Gu, Haodi Ma, Joshua Hong, Zhen Wang, Daisy Wang, and Zhiting Hu. Reasoning with language model is planning with world model. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 8154–8173, 2023
2023
-
[11]
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024
Pith/arXiv arXiv 2024
-
[12]
Designing and interpreting probes with control tasks
John Hewitt and Percy Liang. Designing and interpreting probes with control tasks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2733–2743, Hong Kong, Chi...
-
[13]
Treerl: Llm reinforcement learning with on-policy tree search
Zhenyu Hou, Ziniu Hu, Yujiang Li, Rui Lu, Jie Tang, and Yuxiao Dong. Treerl: Llm reinforcement learning with on-policy tree search. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12355–12369, 2025
2025
-
[14]
Yuichi Inoue, Kou Misaki, Yuki Imajuku, So Kuroki, Taishi Nakamura, and Takuya Akiba. Wider or deeper? scaling llm inference-time compute with adaptive branching tree search.arXiv preprint arXiv:2503.04412, 2025
arXiv 2025
-
[15]
Mingyu Jin, Qinkai Yu, Jingyuan Huang, Qingcheng Zeng, Zhenting Wang, Wenyue Hua, Haiyan Zhao, Kai Mei, Yanda Meng, Kaize Ding, Fan Yang, Mengnan Du, and Yongfeng Zhang. Exploring concept depth: How large language models acquire knowledge and concept at different layers? In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio,...
2025
-
[16]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR, 2023
2023
-
[17]
Policy guided tree search for enhanced llm reasoning.arXiv preprint arXiv:2502.06813, 2025
Yang Li. Policy guided tree search for enhanced llm reasoning.arXiv preprint arXiv:2502.06813, 2025. 13
arXiv 2025
-
[18]
Yizhi Li, Qingshui Gu, Zhoufutu Wen, Ziniu Li, Tianshun Xing, Shuyue Guo, Tianyu Zheng, Xin Zhou, Xingwei Qu, Wangchunshu Zhou, et al. Treepo: Bridging the gap of policy optimiza- tion and efficacy and inference efficiency with heuristic tree-based modeling.arXiv preprint arXiv:2508.17445, 2025
arXiv 2025
-
[19]
Reward-guided speculative decoding for efficient llm reasoning.arXiv preprint arXiv:2501.19324, 2025
Baohao Liao, Yuhui Xu, Hanze Dong, Junnan Li, Christof Monz, Silvio Savarese, Doyen Sahoo, and Caiming Xiong. Reward-guided speculative decoding for efficient llm reasoning.arXiv preprint arXiv:2501.19324, 2025
arXiv 2025
-
[20]
Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Li Erran Li, Raluca Ada Popa, and Ion Stoica
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y. Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Li Erran Li, Raluca Ada Popa, and Ion Stoica. Deepscaler: Surpass- ing o1-preview with a 1.5b model by scaling rl.https://pretty-radio-b75.notion.site/ DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2 ,
-
[21]
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, et al. Specinfer: Accelerating generative large language model serving with tree-based speculative inference and verification.arXiv preprint arXiv:2305.09781, 2023
arXiv 2023
-
[22]
s1: Simple test-time scaling
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20286–20332, 2025
2025
-
[23]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[24]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
Pith/arXiv arXiv 2024
-
[25]
Multiplex thinking: Reasoning via token-wise branch-and-merge.arXiv preprint arXiv:2601.08808, 2026
Yao Tang, Li Dong, Yaru Hao, Qingxiu Dong, Furu Wei, and Jiatao Gu. Multiplex thinking: Reasoning via token-wise branch-and-merge.arXiv preprint arXiv:2601.08808, 2026
arXiv 2026
-
[26]
Jikai Wang, Juntao Li, Jianye Hou, Bowen Yan, Lijun Wu, and Min Zhang. Efficient reasoning for llms through speculative chain-of-thought.arXiv preprint arXiv:2504.19095, 2025
arXiv 2025
-
[27]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
Pith/arXiv arXiv 2022
-
[28]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[29]
Fang Wu, Weihao Xuan, Heli Qi, Ximing Lu, Aaron Tu, Li Erran Li, and Yejin Choi. Deepsearch: Overcome the bottleneck of reinforcement learning with verifiable rewards via monte carlo tree search.arXiv preprint arXiv:2509.25454, 2025. 14
Pith/arXiv arXiv 2025
-
[30]
Junhong Wu, Jinliang Lu, Zixuan Ren, Gangqiang Hu, Zhi Wu, Dai Dai, and Hua Wu. Llms are single-threaded reasoners: Demystifying the working mechanism of soft thinking.arXiv preprint arXiv:2508.03440, 2025
arXiv 2025
-
[31]
Monte carlo tree search boosts reasoning via iterative preference learning
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P Lillicrap, Kenji Kawaguchi, and Michael Shieh. Monte carlo tree search boosts reasoning via iterative preference learning. arXiv preprint arXiv:2405.00451, 2024
arXiv 2024
-
[32]
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822, 2023
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822, 2023
2023
-
[33]
Zhen Zhang, Xuehai He, Weixiang Yan, Ao Shen, Chenyang Zhao, Shuohang Wang, Yelong Shen, and Xin Eric Wang. Soft thinking: Unlocking the reasoning potential of llms in continuous concept space.arXiv preprint arXiv:2505.15778, 2025
arXiv 2025
-
[34]
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Language agent tree search unifies reasoning acting and planning in language models.arXiv preprint arXiv:2310.04406, 2023
Pith/arXiv arXiv 2023
-
[35]
Hanlin Zhu, Shibo Hao, Zhiting Hu, Jiantao Jiao, Stuart Russell, and Yuandong Tian. Reasoning by superposition: A theoretical perspective on chain of continuous thought.arXiv preprint arXiv:2505.12514, 2025. 15 A Complete Decoding Framework A.1 Rolling Local Lookahead Tree Let x<t denote the committed prefix before decoding positiont. Standard autoregress...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.