GRAB: A Risk Taxonomy--Grounded Benchmark for Unsupervised Topic Discovery in Financial Disclosures
Pith reviewed 2026-05-21 21:31 UTC · model grok-4.3
The pith
GRAB creates a benchmark with automatic labels for evaluating unsupervised topic models on financial risk disclosures in 10-K filings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GRAB unifies evaluation with fixed dataset splits and robust metrics for unsupervised topic models on financial disclosures, using span-grounded sentence labels produced without manual annotation by combining FinBERT token attention, YAKE keyphrase signals, and taxonomy-aware collocation matching anchored in a risk taxonomy mapping 193 terms to 21 fine-grained types nested under five macro classes.
What carries the argument
The GRAB benchmark, which anchors labels in a risk taxonomy to enable weak supervision and macro-level evaluation of topic models using automatic label generation from FinBERT and YAKE.
Load-bearing premise
The automatic labeling pipeline combining FinBERT attention, YAKE signals, and taxonomy matching produces sufficiently accurate ground-truth labels for reliable macro-level evaluation of topic models, without requiring human validation or correction of the generated labels.
What would settle it
A study that manually annotates a representative sample of the sentences and finds substantial disagreement with the automatic labels would indicate that the benchmark's ground truth is not reliable.
Figures



read the original abstract
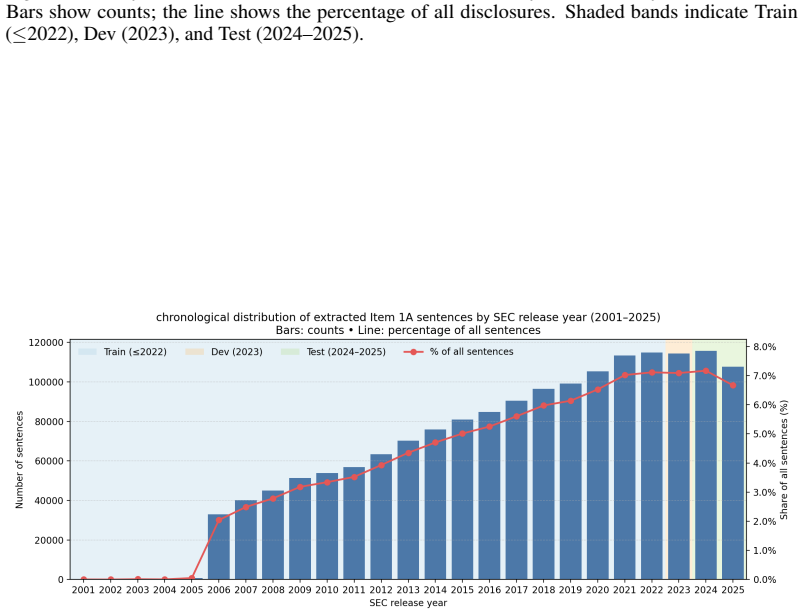
Risk categorization in 10-K risk disclosures matters for oversight and investment, yet no public benchmark evaluates unsupervised topic models for this task. We present GRAB, a finance-specific benchmark with 1.61M sentences from 8,247 filings and span-grounded sentence labels produced without manual annotation by combining FinBERT token attention, YAKE keyphrase signals, and taxonomy-aware collocation matching. Labels are anchored in a risk taxonomy mapping 193 terms to 21 fine-grained types nested under five macro classes; the 21 types guide weak supervision, while evaluation is reported at the macro level. GRAB unifies evaluation with fixed dataset splits and robust metrics--Accuracy, Macro-F1, Topic BERTScore, and the entropy-based Effective Number of Topics. The dataset, labels, and code enable reproducible, standardized comparison across classical, embedding-based, neural, and hybrid topic models on financial disclosures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents GRAB, a finance-specific benchmark for evaluating unsupervised topic models on risk disclosures in 10-K filings. It comprises 1.61M sentences from 8,247 filings with span-grounded sentence labels generated automatically (without manual annotation) via a pipeline combining FinBERT token attention, YAKE keyphrase signals, and taxonomy-aware collocation matching. Labels are anchored in a risk taxonomy (193 terms to 21 fine-grained types nested under five macro classes), with evaluation at the macro level using fixed dataset splits and metrics including Accuracy, Macro-F1, Topic BERTScore, and Effective Number of Topics. The work enables reproducible comparisons across classical, embedding-based, neural, and hybrid topic models.
Significance. If the automatic labels are shown to be reliable, GRAB would fill a clear gap by supplying the first public, standardized benchmark for topic discovery in financial risk disclosures, supporting oversight and investment applications. The fixed splits, open release of data/labels/code, and use of multiple robust metrics (including entropy-based Effective Number of Topics) are explicit strengths that promote reproducibility and fair model comparison.
major comments (1)
- [Abstract] Abstract and label-generation description: the central claim that the automatic pipeline (FinBERT attention + YAKE + taxonomy collocation matching over 193 terms) produces sufficiently accurate span-grounded labels to serve as ground truth for macro-level (5-class) evaluation is load-bearing for all downstream results. No human validation, inter-annotator agreement, precision/recall against expert labels, or error analysis is reported for the 1.61M sentences; potential systematic biases (e.g., attention-score over-reliance or collocation false positives) could therefore distort Accuracy, Macro-F1, Topic BERTScore, and Effective Number of Topics rankings and undermine the advertised fixed-split reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential value of GRAB as a standardized benchmark. We address the central concern regarding validation of the automatic labels below and commit to revisions that directly strengthen the manuscript on this point.
read point-by-point responses
-
Referee: [Abstract] Abstract and label-generation description: the central claim that the automatic pipeline (FinBERT attention + YAKE + taxonomy collocation matching over 193 terms) produces sufficiently accurate span-grounded labels to serve as ground truth for macro-level (5-class) evaluation is load-bearing for all downstream results. No human validation, inter-annotator agreement, precision/recall against expert labels, or error analysis is reported for the 1.61M sentences; potential systematic biases (e.g., attention-score over-reliance or collocation false positives) could therefore distort Accuracy, Macro-F1, Topic BERTScore, and Effective Number of Topics rankings and undermine the advertised fixed-split reproducibility.
Authors: We agree that the reliability of the automatically generated labels is foundational to the benchmark and that the initial submission did not include human validation or error analysis. The label-generation pipeline combines FinBERT token attention, YAKE keyphrase signals, and taxonomy-aware collocation matching over the 193 terms to produce span-grounded weak labels at scale; evaluation is deliberately reported only at the 5-class macro level to reduce sensitivity to fine-grained noise. Nevertheless, the absence of reported precision/recall against expert labels or systematic error analysis leaves open the possibility of biases affecting model rankings. In the revised manuscript we will add a dedicated subsection on label quality that includes: (i) manual annotation of a stratified random sample of 1,000 sentences by two domain experts, with reported inter-annotator agreement and precision/recall of the automatic pipeline against these expert labels; (ii) qualitative error analysis highlighting common failure modes such as attention-score over-reliance and collocation false positives; and (iii) an explicit discussion of how these findings affect interpretation of the reported metrics. The dataset splits and evaluation protocol will remain unchanged, but the new analysis will be used to qualify the strength of the reproducibility claims. revision: yes
Circularity Check
No significant circularity: benchmark constructed from public filings and external taxonomy with independent label generation
full rationale
The paper presents GRAB as an external benchmark resource: 1.61M sentences extracted from public 10-K filings, with span-grounded labels generated via a fixed pipeline (FinBERT token attention + YAKE keyphrases + taxonomy-aware collocation matching) anchored in a pre-existing risk taxonomy that maps 193 terms to 21 fine-grained types. These labels function as ground truth for macro-level evaluation of separate unsupervised topic models using fixed dataset splits and metrics (Accuracy, Macro-F1, Topic BERTScore, Effective Number of Topics). No equation or derivation reduces a claimed prediction to the evaluation inputs by construction, no fitted parameter is renamed as a prediction, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The automatic labeling pipeline is an explicit methodological choice whose accuracy is an external assumption rather than a tautology internal to the reported results. The work is therefore self-contained against external benchmarks and public data sources.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The risk taxonomy of 193 terms mapped to 21 fine-grained types under five macro classes accurately captures relevant risk categories in 10-K disclosures.
- domain assumption Combining FinBERT token attention, YAKE keyphrase signals, and taxonomy-aware collocation matching produces span-grounded labels that are sufficiently reliable for benchmarking topic models.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Labels are anchored in a risk taxonomy mapping 193 terms to 21 fine-grained types nested under five macro classes; the 21 types guide weak supervision, while evaluation is reported at the macro level.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Simultaneously discovering and quantifying risk types from textual risk disclosures
Yang Bao and Anindya Datta. Simultaneously discovering and quantifying risk types from textual risk disclosures. Management Science, 60 0 (6): 0 1371--1391, 2014. URL http://www.jstor.org/stable/42919610
-
[2]
Micha Bender, Sven Panz, and Dietmar Hofeditz. A general framework for the identification and categorization of risks: An application to the context of financial markets. SSRN Electronic Journal, 2016. URL https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3738273. SSRN: 3738273
work page 2016
-
[3]
Pre-training is a hot topic: Contextualized document embeddings improve topic coherence
Federico Bianchi, Silvia Terragni, and Dirk Hovy. Pre-training is a hot topic: Contextualized document embeddings improve topic coherence. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pages 759--766, Online, 20...
-
[4]
David M Blei, Andrew Y Ng, and Michael I Jordan. Latent dirichlet allocation. Journal of machine Learning research, 3 0 (Jan): 0 993--1022, 2003
work page 2003
-
[5]
The information content of mandatory risk factor disclosures in corporate filings
John L Campbell, Hsinchun Chen, Dan S Dhaliwal, Hsin-min Lu, and Logan B Steele. The information content of mandatory risk factor disclosures in corporate filings. Review of Accounting Studies, 19 0 (1): 0 396--455, 2014
work page 2014
-
[6]
Yake! keyword extraction from single documents using multiple local features
Ricardo Campos, V \' tor Mangaravite, Arian Pasquali, Al \' pio Jorge, C \'e lia Nunes, and Adam Jatowt. Yake! keyword extraction from single documents using multiple local features. Information Sciences, 509: 0 257--289, 2020
work page 2020
-
[7]
Sentencelda: Discriminative and robust document representation with sentence level topic model
Taehun Cha and Donghun Lee. Sentencelda: Discriminative and robust document representation with sentence level topic model. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 521--538, St. Julian's, Malta, 2024. Association for Computational Linguistics. doi:10.1865...
-
[8]
G aussian LDA for topic models with word embeddings
Rajarshi Das, Manzil Zaheer, and Chris Dyer. G aussian LDA for topic models with word embeddings. In Chengqing Zong and Michael Strube, editors, Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 795--804, Beijing, ...
-
[9]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure
Maarten Grootendorst. Bertopic: Neural topic modeling with a class-based tf-idf procedure, 2022. URL https://arxiv.org/abs/2203.05794
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Mark O. Hill. Diversity and evenness: A unifying notation and its consequences. Ecology, 54 0 (2): 0 427--432, 1973. doi:10.2307/1934352
-
[11]
Finbert: A large language model for extracting information from financial text
Allen H Huang, Hui Wang, and Yi Yang. Finbert: A large language model for extracting information from financial text. Contemporary Accounting Research, 40 0 (2): 0 806--841, 2023
work page 2023
-
[12]
A multilabel text classification algorithm for labeling risk factors in sec form 10-k
Ke-Wei Huang and Zhuolun Li. A multilabel text classification algorithm for labeling risk factors in sec form 10-k. ACM Transactions on Management Information Systems (TMIS), 2 0 (3): 0 1--19, 2011
work page 2011
-
[13]
M ulti F in: A dataset for multilingual financial NLP
Rasmus J rgensen, Oliver Brandt, Mareike Hartmann, Xiang Dai, Christian Igel, and Desmond Elliott. M ulti F in: A dataset for multilingual financial NLP . In Andreas Vlachos and Isabelle Augenstein, editors, Findings of the Association for Computational Linguistics: EACL 2023, pages 894--909, Dubrovnik, Croatia, May 2023. Association for Computational Lin...
-
[14]
Efficient Estimation of Word Representations in Vector Space
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space, 2013. URL https://arxiv.org/abs/1301.3781
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[15]
Risk disclosure in SEC corporate filings
Yuka Mirakur. Risk disclosure in SEC corporate filings. Working paper, University of Pennsylvania, 2011. URL http://repository.upenn.edu/wharton_research_scholars/85. Accessed October 1, 2013
work page 2011
-
[16]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[17]
Topic modeling with fine-tuning llms and bag of sentences, 2024
Johannes Schneider. Topic modeling with fine-tuning llms and bag of sentences, 2024. URL https://arxiv.org/abs/2408.03099
-
[18]
Claude E. Shannon. A mathematical theory of communication. The Bell System Technical Journal, 27 0 (3): 0 379--423, 1948
work page 1948
-
[19]
Autoencoding variational inference for topic models
Akash Srivastava and Charles Sutton. Autoencoding variational inference for topic models. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017. URL https://openreview.net/forum?id=H1TMjf9xx
work page 2017
-
[20]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert. In International Conference on Learning Representations, 2020
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.