DEFENGRAPH: Knowledge Graph-Enhanced LLMs for Blue Team Cyber Defense
Pith reviewed 2026-06-26 14:09 UTC · model grok-4.3
The pith
A dual-layer static-dynamic knowledge graph grounds LLMs to raise accuracy in cyber defense reasoning and actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
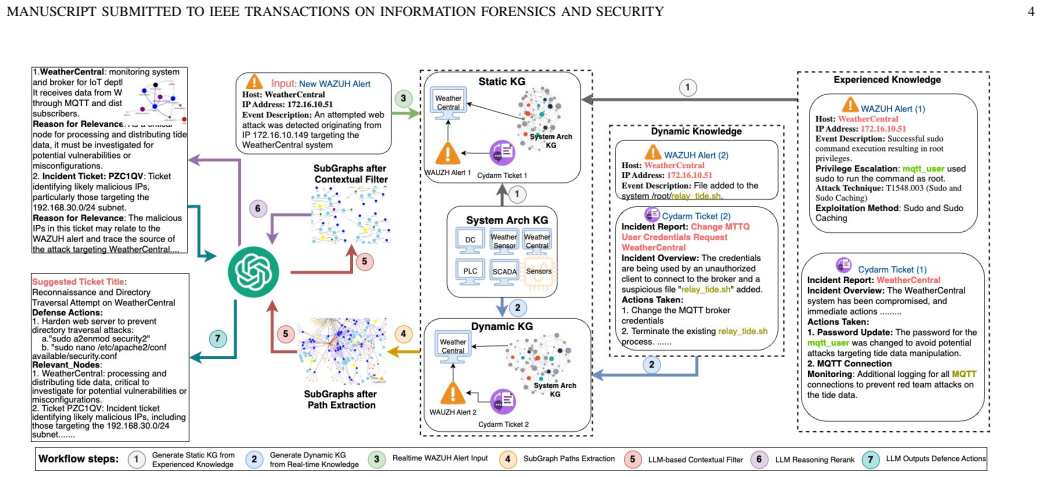
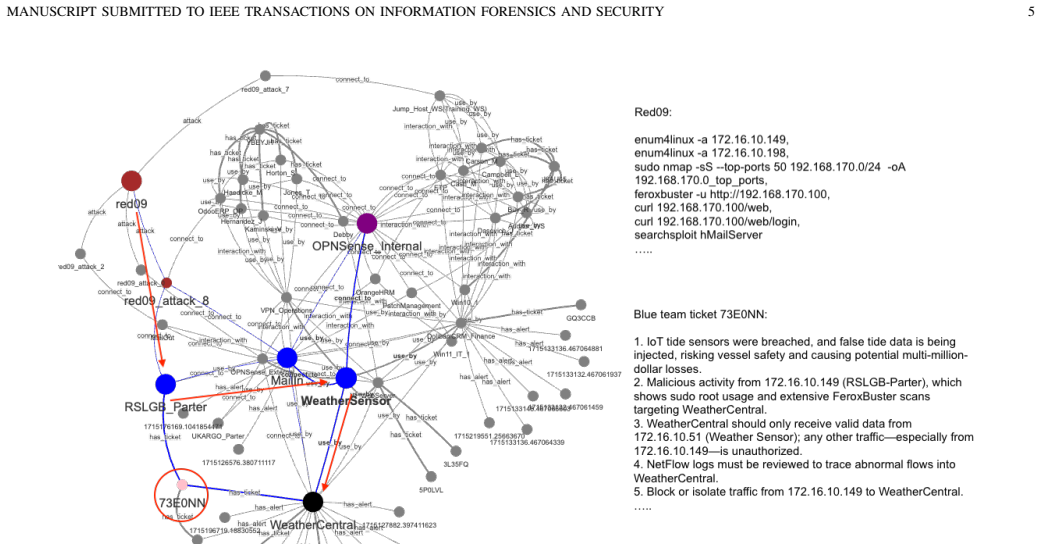
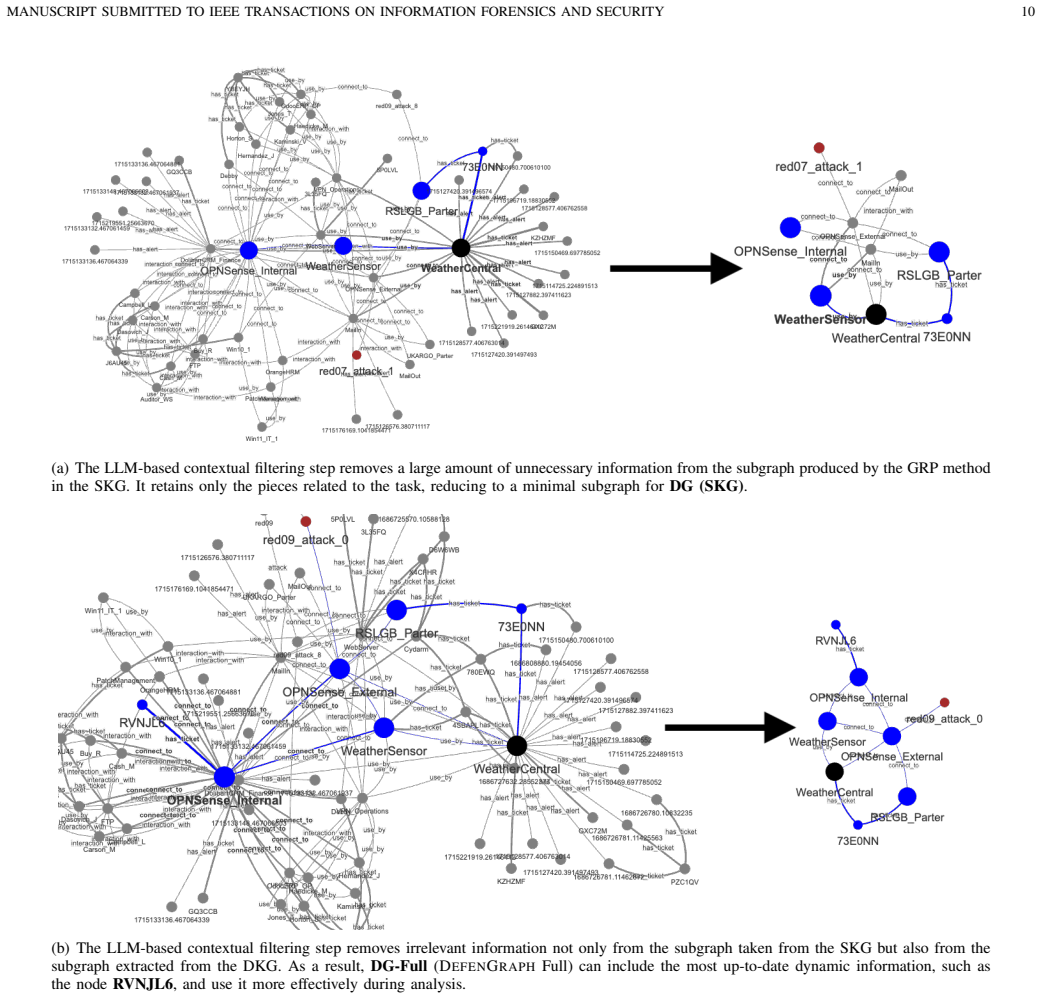
DEFENGRAPH integrates a dual-layer Static-Dynamic Knowledge Graph with graph-based path retrieval, LLM-driven contextual filtering, and reasoning-based re-ranking to ground LLM outputs in both long-term domain knowledge and evolving event context from heterogeneous security artifacts, enabling faithful and temporally aware decision support as measured by improved recall metrics on realistic noisy datasets from cyber range exercises.
What carries the argument
Dual-layer Static-Dynamic Knowledge Graph together with graph-based path retrieval, LLM-driven contextual filtering, and reasoning-based re-ranking.
If this is right
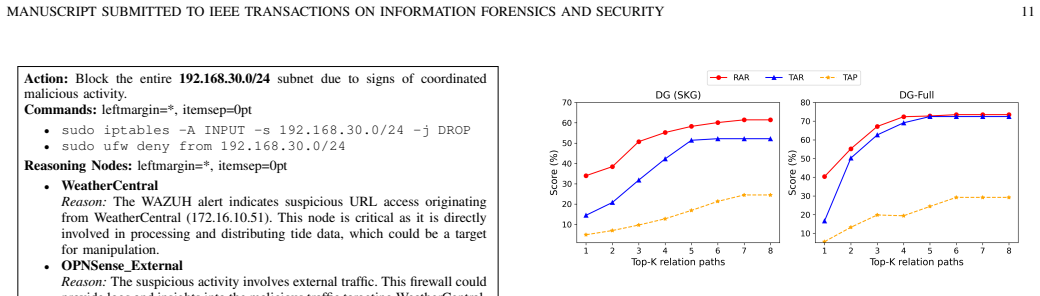
- Reasoning-recall rises from 61.45% to 73.49% on GPT-4o.
- Ticket-action recall rises from 52.17% to 72.46% on GPT-4o with precision moving from 24.49% to 29.24%.
- Up to 50 correct defense actions surface versus 36 for the next best baseline.
- Comparable recall gains appear on LLaMA-3, DeepSeek-R1, and QWen-3.
- Fault rates remain steady across the tested models.
Where Pith is reading between the lines
- The same grounding pattern could apply to other high-stakes domains that require tracking evolving states, such as network operations or industrial control.
- Structured external memory may allow smaller or less specialized models to reach performance levels otherwise needing larger ones.
- Maintaining an accurate dynamic layer in live environments would require automated update mechanisms not tested in the exercises.
Load-bearing premise
Knowledge graphs built from SIEM alerts, system topology, attacker behaviors, and prior defensive actions faithfully represent both long-term domain knowledge and evolving event context in a manner that directly enables the observed improvements.
What would settle it
Replacing the constructed knowledge graphs with random connections or incomplete security data and checking whether the recall gains on reasoning and actions disappear would settle whether the graph integration drives the results.
Figures







read the original abstract
Large Language Models (LLMs) show promise for supporting decision-making in cybersecurity, but their reliability in high-stakes, time-evolving environments remains limited due to hallucinations, poor temporal reasoning, and shallow grounding in system context. We introduce DEFENGRAPH, an LLM-driven assistant designed to support human defenders during cybersecurity incidents. DEFENGRAPH improves contextual reasoning by integrating a dual-layer Static-Dynamic Knowledge Graph (KG) with graph-based path retrieval, LLM-driven contextual filtering, and reasoning-based re-ranking. The framework grounds LLM outputs in both long-term domain knowledge and evolving event context, enabling faithful and temporally aware decision support. We evaluate DEFENGRAPH in a cyber defense setting using knowledge graphs constructed from heterogeneous security artifacts, including SIEM alerts, system topology, attacker behaviors, and prior defensive actions. The evaluation uses data collected during live Red vs. Blue team cyber range exercises simulating attacks on critical infrastructure, which generate realistic and noisy datasets reflecting real-world defender workflows and system dynamics. Evaluations across four prevalent LLMs show that DEFENGRAPH sets a new state-of-the-art: on GPT-4o it boosts reasoning-recall from 61.45\% to 73.49\% and ticket-action recall from 52.17% to 72.46% (precision 24.49\% to 29.24\%), with similar gains on LLaMA-3 (46.99\% to 61.45\%), DeepSeek-R1 (45.78\% to 56.63\%) and QWen-3 (51.81\% to 59.04\%), while surfacing up to 50 correct defense actions versus 36 for the next best baseline and holding fault rates steady.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DEFENGRAPH, an LLM-driven assistant for blue-team cyber defense that augments models via a dual-layer Static-Dynamic Knowledge Graph (KG) built from SIEM alerts, system topology, attacker behaviors, and prior actions. Graph path retrieval, LLM contextual filtering, and reasoning-based re-ranking are used to ground outputs in long-term knowledge and evolving context. On data from live Red-vs-Blue cyber-range exercises, the system is reported to raise reasoning-recall from 61.45% to 73.49% and ticket-action recall from 52.17% to 72.46% (precision 24.49% to 29.24%) on GPT-4o, with analogous gains on LLaMA-3, DeepSeek-R1 and QWen-3, while surfacing up to 50 correct actions versus 36 for the next baseline and keeping fault rates steady.
Significance. If the empirical claims are substantiated with full methodological detail, the work would offer a concrete demonstration that dual-layer KGs can measurably improve LLM reliability for time-sensitive defensive decision support on realistic, noisy security data. The multi-model evaluation and use of live exercise traces are strengths that increase external validity relative to purely synthetic benchmarks.
major comments (3)
- [Abstract and Evaluation section] Abstract and Evaluation section: the concrete lifts (reasoning-recall 61.45%→73.49%, ticket-action recall 52.17%→72.46% on GPT-4o) are stated without definitions of the recall/precision metrics, descriptions of baseline implementations, statistical significance tests, or data-exclusion rules applied to the cyber-range dataset. These omissions are load-bearing for any claim that the gains are attributable to the proposed mechanisms rather than confounds or metric choices.
- [Methodology / KG construction section] Methodology / KG construction section: the central attribution of performance gains to the Static-Dynamic KG plus path retrieval, filtering, and re-ranking rests on the unverified assumption that the constructed graphs faithfully encode both long-term domain knowledge and evolving event context. No coverage metrics, expert validation of completeness, or ablation isolating graph structure from raw-text augmentation are supplied, leaving open the possibility that improvements arise simply from additional structured context.
- [Results table] Results table (action-surfacing numbers): the claim of surfacing up to 50 correct defense actions versus 36 for the next baseline is presented without variance estimates, per-exercise breakdowns, or confirmation that the same set of ground-truth actions was used for all systems, undermining the cross-baseline comparison.
minor comments (2)
- [Figure 1 / §3] The notation distinguishing static versus dynamic layers in the KG could be made more explicit, ideally with an accompanying diagram that labels edge types and temporal scopes.
- [Related Work] A small number of recent KG-augmented LLM papers in the security domain are not referenced in the related-work section.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commitments to revisions that strengthen the manuscript's transparency without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: the concrete lifts (reasoning-recall 61.45%→73.49%, ticket-action recall 52.17%→72.46% on GPT-4o) are stated without definitions of the recall/precision metrics, descriptions of baseline implementations, statistical significance tests, or data-exclusion rules applied to the cyber-range dataset. These omissions are load-bearing for any claim that the gains are attributable to the proposed mechanisms rather than confounds or metric choices.
Authors: We agree these details are essential for rigorous interpretation. The revised manuscript will add explicit definitions of reasoning-recall and ticket-action recall (including how ground-truth positives are identified from the annotated cyber-range traces), full descriptions of baseline implementations, results from statistical significance tests such as McNemar's test, and a statement of any data-exclusion rules. These additions will be placed in a new subsection of the Evaluation section. revision: yes
-
Referee: [Methodology / KG construction section] Methodology / KG construction section: the central attribution of performance gains to the Static-Dynamic KG plus path retrieval, filtering, and re-ranking rests on the unverified assumption that the constructed graphs faithfully encode both long-term domain knowledge and evolving event context. No coverage metrics, expert validation of completeness, or ablation isolating graph structure from raw-text augmentation are supplied, leaving open the possibility that improvements arise simply from additional structured context.
Authors: The manuscript details KG construction from SIEM alerts, topology, attacker behaviors, and prior actions, with consistent gains across four LLMs supporting the value of the structured dual-layer approach. We will add quantitative coverage metrics for both Static and Dynamic layers. Formal expert validation of completeness was not performed in the original study; we will note this limitation explicitly. A full ablation isolating graph structure from raw-text context was not conducted; we will either add a targeted ablation where feasible or discuss it as future work while maintaining that path retrieval and re-ranking provide benefits beyond unstructured augmentation. revision: partial
-
Referee: [Results table] Results table (action-surfacing numbers): the claim of surfacing up to 50 correct defense actions versus 36 for the next baseline is presented without variance estimates, per-exercise breakdowns, or confirmation that the same set of ground-truth actions was used for all systems, undermining the cross-baseline comparison.
Authors: The 50 versus 36 figures represent the maximum correct actions surfaced across the set of exercises. The revision will include variance estimates (standard deviation across exercises), per-exercise breakdowns in an appendix, and an explicit statement of the evaluation protocol confirming that identical ground-truth action sets—derived from the same annotated traces—were used for every system and baseline. revision: yes
Circularity Check
No circularity: empirical evaluation rests on external baselines and data
full rationale
The paper describes an empirical system (DEFENGRAPH) that constructs dual-layer KGs from SIEM alerts, topology, attacker behaviors and prior actions collected during cyber-range exercises, then measures LLM recall/precision gains against external baselines on the same held-out exercise data. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or described methodology. The reported lifts (e.g., GPT-4o reasoning-recall 61.45% → 73.49%) are presented as direct experimental outcomes, not derived quantities that reduce to the input construction by definition. The framework is therefore self-contained against the external benchmarks it reports.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Heterogeneous security artifacts (SIEM alerts, topology, attacker behaviors, prior actions) can be assembled into static and dynamic knowledge graphs that faithfully capture both long-term domain knowledge and evolving event context.
Reference graph
Works this paper leans on
-
[1]
Stop overthinking: A survey on efficient reasoning for large language models,
Y . Sui, Y .-N. Chuang, G. Wang, J. Zhang, T. Zhang, J. Yuan, H. Liu, A. Wen, S. Zhong, H. Chen, and X. Hu, “Stop overthinking: A survey on efficient reasoning for large language models,” 2025. [Online]. Available: https://arxiv.org/abs/2503.16419
Pith/arXiv arXiv 2025
-
[2]
Sok: Semantic privacy in large language models,
B. Ma, Y . Jiang, X. Wang, G. Yu, Q. Wang, C. Sun, C. Li, X. Qi, Y . He, W. Ni, and R. P. Liu, “Sok: Semantic privacy in large language models,” 2025. [Online]. Available: https://arxiv.org/abs/2506.23603
arXiv 2025
-
[3]
When llms meet cybersecurity: a systematic literature review,
J. Zhang, H. Bu, H. Wen, Y . Liu, H. Fei, R. Xi, L. Li, Y . Yang, H. Zhu, and D. Meng, “When llms meet cybersecurity: a systematic literature review,”Cybersecurity, vol. 8, no. 1, p. 55, Feb 2025. [Online]. Available: https://doi.org/10.1186/s42400-025-00361-w
-
[4]
H. Xu, S. Wang, N. Li, K. Wang, Y . Zhao, K. Chen, T. Yu, Y . Liu, and H. Wang, “Large language models for cyber security: A systematic literature review,”ACM Trans. Softw. Eng. Methodol., Sep. 2025, just Accepted. [Online]. Available: https://doi.org/10.1145/3769676
-
[5]
Accountability and reliability in 6g o-ran: Who is responsible when it fails?
Y . He, G. Yu, X. Wang, Q. Wang, Z. Niu, W. Ni, and R. P. Liu, “Accountability and reliability in 6g o-ran: Who is responsible when it fails?”IEEE Wireless Communications, vol. 32, no. 2, pp. 52–59, 2025
2025
-
[6]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, and T. Liu, “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,”ACM Trans. Inf. Syst., vol. 43, no. 2, Jan. 2025. [Online]. Available: https://doi.org/10.1145/3703155
-
[7]
Intellbot: Retrieval augmented llm chatbot for cyber threat knowledge delivery,
D. R. Arikkat, A. M., N. Binu, P. M., N. Biju, K. S. Arunima, V . P., R. R. K. A., and M. Conti, “Intellbot: Retrieval augmented llm chatbot for cyber threat knowledge delivery,” 2024. [Online]. Available: https://arxiv.org/abs/2411.05442
arXiv 2024
-
[8]
Security and threat detection through cloud-based wazuh deployment,
S. Moiz, A. Majid, A. Basit, M. Ebrahim, A. A. Abro, and M. Naeem, “Security and threat detection through cloud-based wazuh deployment,” in2024 IEEE 1st Karachi Section Humanitarian Technology Conference (KHI-HTC), 2024, pp. 1–5
2024
-
[9]
Enhancing security operations center: Wazuh security event response with retrieval-augmented-generation- driven copilot,
Ismail, R. Kurnia, F. Widyatama, I. M. Wibawa, Z. A. Brata, Ukasyah, G. A. Nelistiani, and H. Kim, “Enhancing security operations center: Wazuh security event response with retrieval-augmented-generation- driven copilot,”Sensors, vol. 25, no. 3, 2025. [Online]. Available: https://www.mdpi.com/1424-8220/25/3/870
2025
-
[10]
Dense passage retrieval for open-domain question answering,
V . Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W.-t. Yih, “Dense passage retrieval for open-domain question answering,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), B. Webber, T. Cohn, Y . He, and Y . Liu, Eds. Online: Association for Computational Linguistics, Nov. 2020, pp. 6...
2020
-
[11]
A survey on RAG meeting LLMs: Towards retrieval-augmented large language models,
W. Fan, Y . Ding, L. Ning, S. Wang, H. Li, D. Yin, T.-S. Chua, and Q. Li, “A survey on RAG meeting LLMs: Towards retrieval-augmented large language models,” inACM SIGKDD Conference on Knowledge Discovery and Data Mining (SIGKDD), 2024
2024
-
[12]
Context- aware prompting for llm-based program repair,
Y . Li, M. Cai, J. Chen, Y . Xu, L. Huang, and J. Li, “Context- aware prompting for llm-based program repair,”Automated Software Engineering (ASE), 2025
2025
-
[13]
Make your LLM fully utilize the context,
S. An, Z. Ma, Z. Lin, N. Zheng, J.-G. Lou, and W. Chen, “Make your LLM fully utilize the context,”Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[14]
Machine learning on knowledge graphs for context-aware security monitoring,
J. S. Garrido, D. Dold, and J. Frank, “Machine learning on knowledge graphs for context-aware security monitoring,” inIEEE International Conference on Cyber Security and Resilience (CSR), 2021
2021
-
[15]
From local to global: A graph rag approach to query-focused summarization,
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, D. Metropolitansky, R. O. Ness, and J. Larson, “From local to global: A graph rag approach to query-focused summarization,”arXiv preprint arXiv:2404.16130, 2024
Pith/arXiv arXiv 2024
-
[16]
Sub- graph retrieval enhanced model for multi-hop knowledge base question answering,
J. Zhang, X. Zhang, J. Yu, J. Tang, J. Tang, C. Li, and H. Chen, “Sub- graph retrieval enhanced model for multi-hop knowledge base question answering,” inAnnual Meeting of the Association for Computational Linguistics (ACL), 2022
2022
-
[17]
OpenAI, “GPT-4 technical report,”CoRR, vol. abs/2303.08774, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[18]
A. Grattafiori, A. Dubey, A. Jauhriet al., “The llama 3 herd of models,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
Pith/arXiv arXiv 2024
-
[19]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,
DeepSeek-AI, “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,” 2025. [Online]. Available: https: //arxiv.org/abs/2501.12948
Pith/arXiv arXiv 2025
-
[20]
A. Yang, A. Li, B. Yang,et al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[21]
A hybrid RAG system with comprehensive enhancement on complex reasoning,
Y . Yuan, C. Liu, J. Yuan, G. Sun, S. Li, and M. Zhang, “A hybrid RAG system with comprehensive enhancement on complex reasoning,”arXiv preprint arXiv:2408.05141, 2024
arXiv 2024
-
[22]
spaCy: Industrial-strength Natural Language Processing in Python,
M. Honnibal, I. Montani, S. Van Landeghem, and A. Boyd, “spaCy: Industrial-strength Natural Language Processing in Python,”https:// spacy.io/, 2020
2020
-
[23]
Direct evaluation of chain-of-thought in multi-hop reasoning with knowledge graphs,
T. Nguyen, L. Luo, F. Shiri, D. Phung, Y .-F. Li, T. Vu, and G. Haffari, “Direct evaluation of chain-of-thought in multi-hop reasoning with knowledge graphs,” inAssociation for Computational Linguistics (ACL), 2024
2024
-
[24]
Simple is effective: The roles of graphs and large language models in knowledge-graph-based retrieval-augmented generation,
M. Li, S. Miao, and P. Li, “Simple is effective: The roles of graphs and large language models in knowledge-graph-based retrieval-augmented generation,” inInternational Conference on Learning Representations, 2025
2025
-
[25]
Improving multi-hop knowledge base question answering by learning intermediate supervision signals,
G. He, Y . Lan, J. Jiang, W. X. Zhao, and J.-R. Wen, “Improving multi-hop knowledge base question answering by learning intermediate supervision signals,”ACM International Conference on Web Search and Data Mining (WSDM), 2021
2021
-
[26]
Large language models enhanced collaborative filtering,
Z. Sun, Z. Si, X. Zang, K. Zheng, Y . Song, X. Zhang, and J. Xu, “Large language models enhanced collaborative filtering,” inACM International Conference on Information and Knowledge Management (CIKM), 2024
2024
-
[27]
Think-then- react: Towards unconstrained human action-to-reaction generation,
W. Tan, B. Li, C. Jin, W. Huang, X. Wang, and R. Song, “Think-then- react: Towards unconstrained human action-to-reaction generation,”
-
[28]
Available: https://arxiv.org/abs/2503.16451
[Online]. Available: https://arxiv.org/abs/2503.16451
-
[29]
Cyberq: Generat- ing questions and answers for cybersecurity education using knowledge graph-augmented LLMs,
G. Agrawal, K. Pal, Y . Deng, H. Liu, and Y .-C. Chen, “Cyberq: Generat- ing questions and answers for cybersecurity education using knowledge graph-augmented LLMs,” inProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2024
2024
-
[30]
Cyber security knowledge graph based cyber attack attribution framework for space-ground in- tegration information network,
Z. Zhu, R. Jiang, Y . Jia, J. Xu, and A. Li, “Cyber security knowledge graph based cyber attack attribution framework for space-ground in- tegration information network,” inIEEE International Conference on Communication Technology (ICCT), 2018
2018
-
[31]
Cskg4apt: A cy- bersecurity knowledge graph for advanced persistent threat organization attribution,
Y . Ren, Y . Xiao, Y . Zhou, Z. Zhang, and Z. Tian, “Cskg4apt: A cy- bersecurity knowledge graph for advanced persistent threat organization attribution,”IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 6, pp. 5695–5709, 2023
2023
-
[32]
Y . Cheng, O. Bajaber, S. A. Tsegai, D. Song, and P. Gao, “Ctinexus: Automatic cyber threat intelligence knowledge graph construction using large language models,” 2025. [Online]. Available: https://arxiv.org/abs/2410.21060
arXiv 2025
-
[33]
Attackg+: Boosting attack graph construction with large language models,
Y . Zhang, T. Du, Y . Ma, X. Wang, Y . Xie, G. Yang, Y . Lu, and E.-C. Chang, “Attackg+: Boosting attack graph construction with large language models,”Computers & Security, vol. 150, p. 104220, 2025. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0167404824005261
2025
-
[34]
Actionable cyber threat in- telligence using knowledge graphs and large language models,
R. Fieblinger, M. T. Alam, and N. Rastogi, “Actionable cyber threat in- telligence using knowledge graphs and large language models,” inIEEE European symposium on security and privacy workshops (EuroS&PW), 2024
2024
-
[35]
Kg-ibl: Knowledge graph driven incremental broad learning for few-shot specific emitter identification,
M. Hua, Y . Zhang, Q. Zhang, H. Tang, L. Guo, Y . Lin, H. Sari, and G. Gui, “Kg-ibl: Knowledge graph driven incremental broad learning for few-shot specific emitter identification,”IEEE Transactions on Information Forensics and Security, vol. 19, pp. 10 016–10 028, 2024
2024
-
[36]
Wrongdoing monitor: A graph-based behavioral anomaly detection in cyber security,
C. Wang and H. Zhu, “Wrongdoing monitor: A graph-based behavioral anomaly detection in cyber security,”IEEE Transactions on Information Forensics and Security, vol. 17, pp. 2703–2718, 2022
2022
-
[37]
K-getnid: Knowledge-guided graphs for early and transferable network intrusion detection,
M. Wang, N. Yang, and N. Weng, “K-getnid: Knowledge-guided graphs for early and transferable network intrusion detection,”IEEE Transactions on Information Forensics and Security, vol. 19, p. 7147–7160, Jan. 2024. [Online]. Available: https://doi.org/10.1109/ TIFS.2024.3431932
arXiv 2024
-
[38]
Knowledge graph reasoning for cyber attack detection,
E. Gilliard, J. Liu, and A. A. Aliyu, “Knowledge graph reasoning for cyber attack detection,”IET Communications, vol. 18, no. 4, p. 297–308, Feb. 2024. [Online]. Available: https://doi.org/10.1049/cmu2.12736
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.