Quantum Mutant Equivalence via Transpilation
Pith reviewed 2026-06-26 04:37 UTC · model grok-4.3
The pith
Transpiling quantum circuits under identical settings and comparing OpenQASM identifies equivalent mutants at 100% precision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
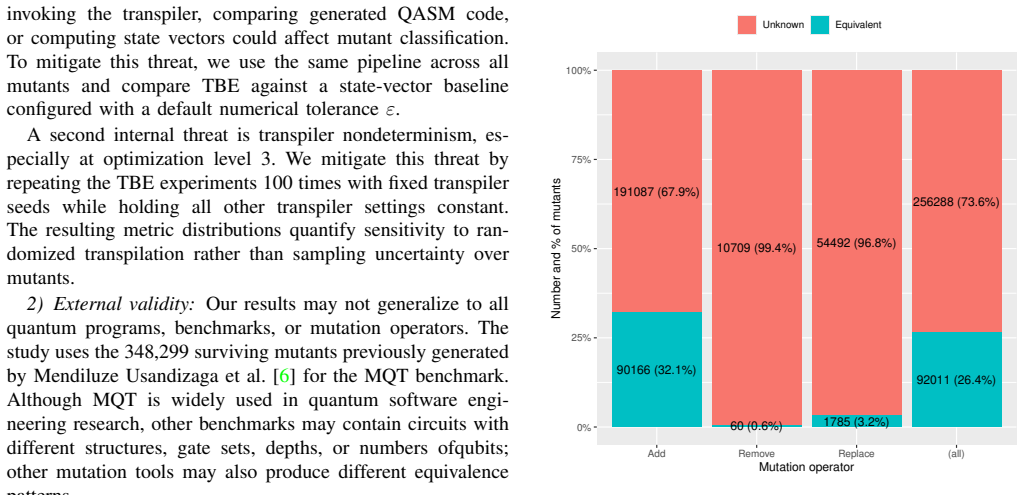
Transpiler-Based Equivalence identifies equivalent quantum mutants by transpiling the original and mutated circuits under the same configuration and comparing the resulting OpenQASM code. Evaluated on 348299 surviving mutants including 92011 equivalents, the method detects 29536 equivalents at 100% precision and 82% accuracy.
What carries the argument
Transpiler-Based Equivalence (TBE), which detects semantic equivalence by identical-configuration transpilation followed by direct OpenQASM comparison.
If this is right
- 32.1% of the 92011 known equivalent mutants can be removed from consideration before test execution.
- Mutation scores become more accurate once these unkillable mutants are excluded.
- The approach processes hundreds of thousands of mutants without introducing false positives.
- Surviving mutants that pass TBE can be prioritized for further manual or automated analysis.
Where Pith is reading between the lines
- The method could be combined with other equivalence detectors to raise recall beyond the reported 32%.
- The same transpilation-comparison idea might apply directly to classical mutation testing in languages that have stable compilers.
- Accuracy figures rest on the independence of the 92011 ground-truth labels from the TBE procedure itself.
Load-bearing premise
Transpiling the original and mutant circuits under the exact same configuration and comparing the resulting OpenQASM code is sufficient to detect semantic equivalence.
What would settle it
A pair of circuits known to be semantically distinct that nevertheless produce identical OpenQASM output after transpilation under the configuration used in the evaluation.
Figures

read the original abstract
Mutation testing evaluates test suite quality by introducing artificial faults (mutants) and checking whether tests detect (kill) them. A central challenge is the equivalent mutant problem: some mutants are syntactically different from the original program but semantically identical to it and therefore cannot be killed by any test. If left unidentified, such mutants waste testing effort and distort mutation scores. In quantum software, mutation testing is increasingly used, but the equivalent mutant problem remains unsolved. A recent study generated more than 700,000 quantum circuit mutants and found that roughly half survived the available tests, making it unclear whether these survivors reflect weak tests or semantic equivalence. We propose Transpiler-Based Equivalence (TBE), a lightweight approach that identifies equivalent quantum mutants by transpiling original and mutated circuits under the same configuration and comparing their resulting OpenQASM code. We evaluate TBE on 348,299 surviving mutants, 92,011 of which are equivalent; TBE identifies 29,536 of them (32.1%) as equivalent while achieving 100% precision and 82% accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Transpiler-Based Equivalence (TBE) to identify equivalent mutants in quantum circuits: original and mutated circuits are transpiled under identical configurations and their OpenQASM outputs compared for syntactic identity. On a set of 348,299 surviving mutants (92,011 labeled equivalent), TBE flags 29,536 as equivalent, reporting 100% precision and 82% accuracy.
Significance. If the ground-truth labels prove independent, TBE supplies a lightweight, scalable filter that could reduce wasted effort on equivalent mutants in quantum mutation testing. The evaluation scale (hundreds of thousands of mutants) is a concrete strength.
major comments (2)
- [Abstract / §4] Abstract and §4 (Evaluation): the headline metrics (100% precision, 82% accuracy on 29,536/92,011 equivalents) rest on the assumption that the 92,011 ground-truth labels were produced by a procedure independent of TBE, of the same transpilation configuration, and of the 'surviving tests' criterion. No description of the prior study's labeling method is supplied, so the reported precision cannot yet be treated as an independent validation.
- [§4] §4: the accuracy figure of 82% is reported without error bars, without breakdown by circuit family or depth, and without analysis of false-negative cases (equivalent mutants missed by TBE). These omissions make it impossible to assess whether the 32.1% detection rate is robust or sensitive to the chosen transpiler settings.
minor comments (2)
- [Abstract] Abstract: state the exact transpiler (Qiskit version, optimization level, basis gates) used for the comparison; this detail is required for reproducibility.
- [§3] §3: clarify whether TBE treats two circuits as equivalent only when their OpenQASM strings match exactly, or whether it normalizes for trivial differences (e.g., qubit ordering, gate decomposition).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the evaluation scale as a strength. We address each major comment below with proposed revisions to enhance clarity.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and §4 (Evaluation): the headline metrics (100% precision, 82% accuracy on 29,536/92,011 equivalents) rest on the assumption that the 92,011 ground-truth labels were produced by a procedure independent of TBE, of the same transpilation configuration, and of the 'surviving tests' criterion. No description of the prior study's labeling method is supplied, so the reported precision cannot yet be treated as an independent validation.
Authors: We agree that a description of the prior study's labeling procedure is required to substantiate independence. The 92,011 equivalent labels derive from the referenced prior work, which determined equivalence via exhaustive simulation-based semantic checking independent of transpilation. In the revised manuscript we will add a concise summary of this method to §4, allowing the precision claim to be evaluated as an independent validation. revision: yes
-
Referee: [§4] §4: the accuracy figure of 82% is reported without error bars, without breakdown by circuit family or depth, and without analysis of false-negative cases (equivalent mutants missed by TBE). These omissions make it impossible to assess whether the 32.1% detection rate is robust or sensitive to the chosen transpiler settings.
Authors: We acknowledge the benefit of additional robustness analysis. Error bars are not applicable, as TBE performs deterministic syntactic comparison with no stochastic component. We will incorporate a breakdown by circuit family and depth into the revised §4, together with an explicit discussion of the false-negative cases (the 62,475 equivalent mutants not flagged by TBE) and their relation to the fixed transpiler configuration chosen to match the prior study. This will allow readers to assess sensitivity of the 32.1% detection rate. revision: yes
Circularity Check
No circularity: empirical method evaluated against externally labeled data
full rationale
The paper introduces TBE as a practical heuristic (transpile both circuits identically then compare OpenQASM text) and reports its precision/accuracy on a set of 92,011 mutants already labeled equivalent by a prior study. No equations, no fitted parameters, no derivation chain, and no claim that the labels were produced by TBE itself. The evaluation is therefore a standard external-benchmark comparison; the 100 % precision figure is not forced by construction. Minor self-citation of the prior mutant-generation work, if present, is not load-bearing for the reported metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Two quantum circuits that produce identical OpenQASM output after transpilation under the same configuration are semantically equivalent.
Reference graph
Works this paper leans on
-
[1]
Mutation Testing in Practice: Insights From Open-Source Software Developers
A. B. S ´anchez, J. A. Parejo, S. Segura, A. Dur ´an, and M. Papadakis. “Mutation Testing in Practice: Insights From Open-Source Software Developers”. In:IEEE Transactions on Software Engineering50.5 (2024), pp. 1130–1143.DOI: 10.1109/TSE.2024.3377378
-
[2]
Mutation Testing of Quantum Programs: A Case Study With Qiskit
D. Fortunato, J. Campos, and R. Abreu. “Mutation Testing of Quantum Programs: A Case Study With Qiskit”. In:IEEE Transactions on Quantum Engineering3 (2022), pp. 1–17.DOI: 10.1109/TQE.2022. 3195061
-
[3]
Thinking like a developer? comparing the attention of humans with neural models of code,
E. Mendiluze, S. Ali, P. Arcaini, and T. Yue. “Muskit: A Mutation Analysis Tool for Quantum Software Testing”. In:IEEE/ACM Inter- national Conference on Automated Software Engineering (ASE). 2021, pp. 1266–1270.DOI: 10.1109/ASE51524.2021.9678563
-
[4]
Two notions of correctness and their relation to testing
T. A. Budd and D. Angluin. “Two notions of correctness and their relation to testing”. In:Acta Inf.18.1 (Mar. 1982), 31–45.ISSN: 0001- 5903.DOI: 10 . 1007 / BF00625279.URL: https : / / doi . org / 10 . 1007 / BF00625279
1982
-
[5]
M. Papadakis, Y . Jia, M. Harman, and Y . Le Traon. “Trivial Compiler Equivalence: A Large Scale Empirical Study of a Simple, Fast and Ef- fective Equivalent Mutant Detection Technique”. In:2015 IEEE/ACM 37th IEEE International Conference on Software Engineering. V ol. 1. 2015, pp. 936–946.DOI: 10.1109/ICSE.2015.103
-
[7]
MQT Bench: Bench- marking Software and Design Automation Tools for Quantum Com- puting
N. Quetschlich, L. Burgholzer, and R. Wille. “MQT Bench: Bench- marking Software and Design Automation Tools for Quantum Com- puting”. In:Quantum7 (2023), p. 1062.DOI: 10.22331/q-2023-07- 20-1062
-
[8]
A. Javadi-Abhari et al.Quantum computing with Qiskit. 2024.DOI: 10.48550/arXiv.2405.08810. arXiv: 2405.08810
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.08810 2024
-
[9]
A. Miranskyy, J. Campos, A. Mjeda, L. Zhang, and I. G. R. de Guzm ´an. On the Feasibility of Quantum Unit Testing. 2025. arXiv: 2507.17235 [cs.SE].URL: https://arxiv.org/abs/2507.17235
arXiv 2025
-
[10]
M. D. Stefano, D. D. Nucci, F. Palomba, and A. D. Lucia. “An empirical study into the effects of transpilation on quantum circuit smells”. In:Empirical Softw. Engg.29.3 (May 2024).ISSN: 1382- 3256.DOI: 10.1007/s10664- 024- 10461- 9.URL: https://doi.org/10. 1007/s10664-024-10461-9
-
[11]
Q. Chen, R. C ˆamara, J. Campos, A. Souto, and I. Ahmed. “The Smelly Eight: An Empirical Study on the Prevalence of Code Smells in Quantum Computing”. In:2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). 2023, pp. 358–370.DOI: 10.1109/ICSE48619.2023.00041
-
[12]
J. Yao and M. Shepperd. “The impact of using biased performance metrics on software defect prediction research”. In:Information and Software Technology139 (2021), p. 106664.DOI: 10.1016/j.infsof. 2021.106664
-
[13]
Mutation-based test generation for quantum programs with multi-objective search
X. Wang, T. Yu, P. Arcaini, T. Yue, and S. Ali. “Mutation-based test generation for quantum programs with multi-objective search”. In: Proceedings of the Genetic and Evolutionary Computation Conference. GECCO ’22. 2022, 1345–1353.DOI: 10.1145/3512290.3528869
-
[14]
A. Kumar, P. Kwatra, and S. Garhwal. “Development of a Tool for Finding Equivalent Mutants in Quantum Program: A Perspective to Measure the Quality of Quantum Software”. In: (2023).DOI: 10.21203/ rs.3.rs-2250025/v2.URL: https://doi.org/10.21203/rs.3.rs-2250025/v2
-
[15]
QGMR: A New Quantum Mutation Testing Operator
S. Shah, S. Godboley, and P. R. Krishna. “QGMR: A New Quantum Mutation Testing Operator”. In:2026 IEEE International Conference on Software Analysis, Evolution and Reengineering - Companion (SANER-C). 2026, pp. 373–376.DOI: 10.1109/SANER-C67878.2026. 00056
-
[16]
E. Andrews and P. Mishra.Efficient Mutation Testing of Quantum Machine Learning Models. 2026. arXiv: 2605.00107[quant-ph]. URL: https://arxiv.org/abs/2605.00107
Pith/arXiv arXiv 2026
-
[17]
Robust Mutation Analysis of Quantum Programs Under Noise
S. Fortz, E. M. Usandizaga, S. Ali, P. Arcaini, and M. R. Mousavi. “Robust Mutation Analysis of Quantum Programs Under Noise”. In: (2026). arXiv: 2605.13279[cs.SE].URL: https://arxiv.org/abs/2605. 13279
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.